基于MMSeg分词的多部主题词表联合标注研究与实现
2015-06-07陈晓燕
陈晓燕
(绍兴职业技术学院,浙江 绍兴312000)
基于MMSeg分词的多部主题词表联合标注研究与实现
陈晓燕
(绍兴职业技术学院,浙江 绍兴312000)
为了解决多部主题词表联合标注中标注词条数量大、子串较多等问题,本文提出了基于MMSeg分词的标注方法.采用MMSeg分词算法将待标注文本先切分形成词串再进行标注,并改进了分词词典从而支持子串的标注,保证了较高的召回率.还就相关内容进行了研究并给出了具体实现.运行结果表明基于MMSeg分词的多部主题词表联合标注在标注速度、召回率和精确率方面均达到了实用要求.
分词词典;MMSeg算法;标注;消歧;主题词表
基于主题词表的标注研究中,闫莹莹[1]等利用汉语科技词系统对文献自动赋词标引进行了应用研究,其将人工标引的文献主题词作为训练集,采用贝叶斯分类算法,将符合人工标引结果作为正集,不符合的作为反集,形成训练模型,对新文献计算候选词权值作为人工标引的辅助.李鹏[2]等提出了叙词表多表联合标注系统的设计方案,采用自动标注与手工标注相结合的方式进行标注,并以皮肤病领域为例进行总结了多表联合标注可能的应用场景.
利用多部主题词表进行联合标注,存在以下几个难点:(1)词表多,词表之间词条的包含关系较常见.最大匹配存在问题,在词表内部可以最大匹配,但多个词条之间有词条之间的包含关系.(2)系统基于BS结构,存在多个用户,每个用户存在多个词表.多用户多词表出现词条数量大、效率要求高.笔者测试对当词条达到30万条时,对单篇200字的文档,耗时约46秒,严重影响用户体验.(3)词条中存在一些特殊符号.例如医学类,连接符,数字等比较常见.本文就以上问题进行了研究.
1 基于MMSeg分词的多部主题词表联合标注研究
1.1 MMSeg分词算法
MMseg分词算法[3]是利于词典进行分词基于正向最大匹配的算法,是将待切分词组从词典中找到最长的字符串的一种匹配算法,其又可以分为简单最大匹配和复杂最大匹配两种方法.若S1,S2,…Sn代表一个字符串中的汉字,其基本算法是:(1)从字符串的第一个字符开始,判断S1是否为词典中的单词,(2)如果是,继续判断S1S2来看是否为词典中的词组,(3)直至S1S2…Sn+1字典中无法匹配时,则S1S2…Sn

相应的算法规则如下,优先秩序分别为:规则1>规则2>规则3>规则4,从而选择最合理的分词组合.
规则1:优先取最大匹配的词长词组;
规则2:取Ax最大的词长词组;
规则3:取Sx最小的词长词组;
规则4:取Dx最大的词长词组.
1.2 分词词典的改进
MMseg的分词效果与词典关系较大,专业领域等细分词典能够实现更好的分词效果[4].主题词表具有典型的专业领域特色,因此非常适合使用MMseg等词典分词算法.将计算机专业主题词表、医学专业主题词表以及各种定制专业主题词表,转化为相应的专业词典来进行分词,能够产生较高的分词效果.
利用多部主题词条进行联合标注时,由于涉及多部主题词表,而且标注的主题词表一般涉及交叉领域,因此存在词条重复或者包含关系等问题,导致普通的MMseg的分词算法难以胜任.因此,必须对MM-seg进行相关的改进.本文相应的改进包括特殊词条处理以及词典文件更新等.本文使用jcseg中文分词器对应的词典文件说明词典文件的更新.jcseg是使用Java开发的一款基于MMseg算法的开源的中文分词器.
原分词词典内容比较简单,一个词条对应的词典内容主要包括词条名称、词性、汉词拼音,以及备注等信息.改进的分词词典,在原有的内容基础上,增加了每个词条对应的主题词表、包含子词条等信息.原词典文件与改进后的词典如图1所示.就是最可能的单词,也是最长的匹配.(4)取这个单词,待切分词组去掉相关词条,依据同样的方法,直至待切分词条为0,即所有单词都被切分完成.
最大匹配算法不涉及语法和语义知识,其优势是切分速度快,不足之处在于无法解决切分歧义的问题,因此切分精度不够.歧义的产生,是因为可能产生多种不同的切分结果,每一种切分结果对应不同的理解,但是根据待处理文本所在的上下语境只有一种符合作者要阐述的意思.歧义消解就是要寻找最符合原文阐述的切分方法.MMseg在基本算法的基础上,充分考虑了平均长度,标准差以及自由语素度三个因素,并对应形成四个规则.规则1考虑的基本算法的最大匹配长度;规则2考虑的因素为平均长度;规则3考虑的因素为标准差;规则4考虑的因素为自由语素度.四个规则的应用,较好地解决了歧义切分的问题.
假设单词条集合为L,对应的词频为fx,令L为待切分词组字数,Ix为词组中各词的长度和,则可计算平均长度Ax,标准差Sx,以及自由语素度Dx.相应计算公式如下:

图1 原分词词典与改进后的分词词典
其中kos代表系统使用的知识组织系统代码,3对应相应的主题词表ID,100对应的词表中词条ID.示例中词条“中华人民共和国”包含了“中华”“人民”两个子词条,而“中华民国”,只包含了“中华”一个字词条.在词典文件中添加词表ID目的是分词后,可根据需要标注的文档库的词表进行过滤,不是当前文档典设置的标注词表,直接在结果中删除.在词典文件中添加词条ID目的是分词后,可以直接根据数字类型为整型的词条ID到数据库中查询对应的信息,从而增加处理速度.
原处理方式的弊端:长词条覆盖短词条.只能标注长词条,不能标注单独出现的长词条所包含的短词条.词表A中有:中华人民共和国、人民.词表B中有:中华、共和国.用户选择A、B两个词表标注“我们是中华人民共和国的国民”.只能分出“中华人民共和国”,“中华”分不出来.改进后的词典,能够按照系统的需要,将各主题词表中的词条均标注出来.
改进后的分词词典,处理了每个词条对应的子词条信息,因此维护词条之间的关系表是一项非常重要的工作.
1.3 特殊词条处理
特殊词条分为两类,一种是存在一些特殊符号如医学类,连接符,数字等比较常见的词条,另一种是超长词条.对于特殊词条,采用直接采用字符串匹配查找文档中是否存在.
在根据词条进行分词时,受分词算法中词典的限制,词条中不能包含特殊字符,如果包含特殊字符,则分词算法在加载词典时失败.标注系统可能出现的一些特殊符号如表1所示.这些符号禁止出现在词典文件中.

表1 特殊符号列表
具体来说,本文基于MMSeg分词的多部主题词表联合标注流程如图2所示.
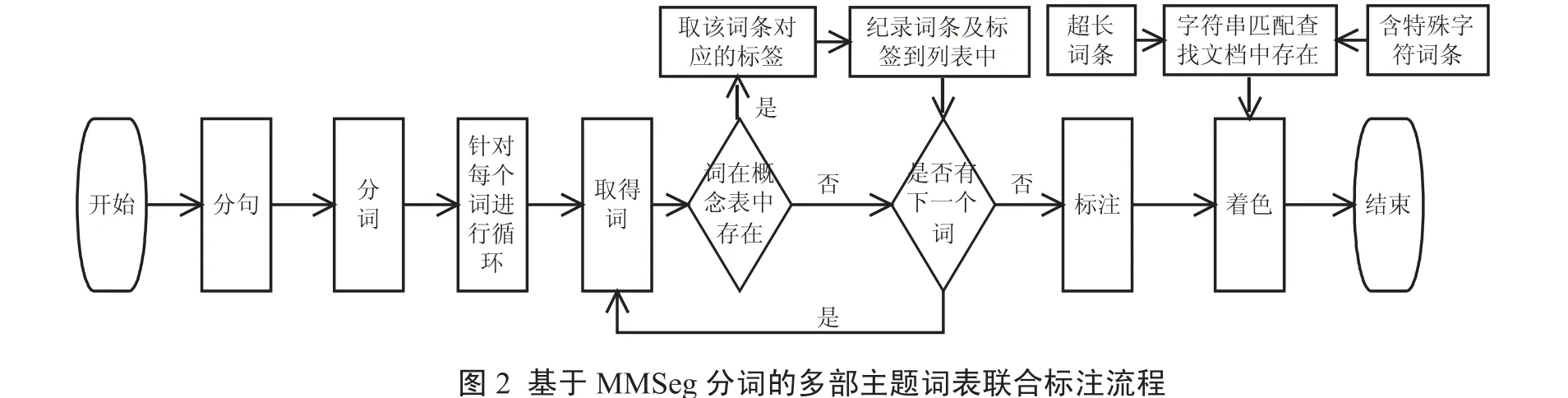
1.4 标注
基于多部主题词表进行联合标注的目的是尽可能将主题词表中出现的词条在待标注文本中标引出来,即尽可能标全.标注为一项基本工作,为其后的知识库的建立和词条及其关系的挖掘提供基础.基于多部主题词表联合进行标注时,由于词典中词条数目较大,采用逐条取词表中的所有词条一一与原文匹配看是否存在原文中的方式,耗时太长.因此,本文采用从待标注文本入手先分词形成词串,然后去数据库中匹配该词串是否在所属词表的词条中,这样匹配的速度更快,能够大幅度节省时间.由于只需要对切分词表中存在的词,因此分词速度大大提高.利用词典分词有利于自动标注,能够实现大批量与自动化标注,是手工标注的前提和工程化应用的基础.基于MMseg分词的多表联合标注包含三个步骤:分词、标注及着色.对文献进行标注时,要判断文献内容是否包含词典中的词条.标注功能需要考虑的因素如下:
(1)支持多次标注,不影响以前的标注.
(2)每次标注后,用户选择的文本及位置信息记录在数据库中.
1.5 着色
要实现对标注文本的着色,需要知道标注文本对应在全文中的位置,着色能够让用户看到标注的效果.可以使用不同的颜色,分别对应不同的主题词表.由于标注时,已经在数据库中存储了标注文本对应的位置信息,因此着色相对比较简单.着色可以直接在待标注文本前添加IE等浏览器支持的标签,实现在浏览器中显示相关的颜色.为将原文中标签同标注的标签区分开,同时为了网页上显示效果,着色代码均遵照特定的格式:
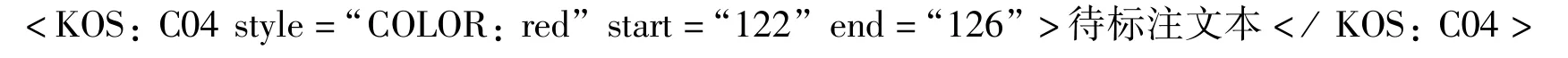
2 基于MMSeg分词的多部主题词表联合标注实现
2.1 数据预处理
数据预处理工作的目的主要是将原主题词表的词条转换成词典文件,为将来的词条切分做好准备工作.利用词典分词的方式,需要建立用户自己的词典.但是,当出现用户词典时,多用户多纯种服务器压力较大,因此,建立统一的词典进行分词.
数据预处理的另外一项内容是主题词表中如果出现词典文件避免的特殊字符时,应该将其标志设为特殊词条,方便标注时专门按特殊词条处理方式进行处理.
2.2 建立词条关系表
词条关系表是为了维护词条之间的包含关系而建立的表.
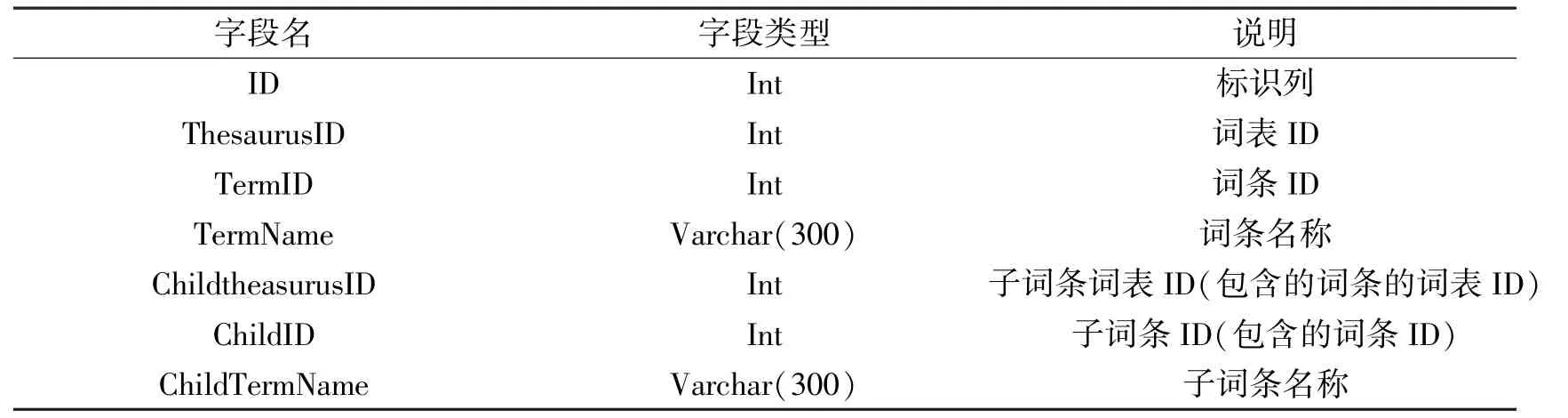
表2 词条关系表s_Relation
计算一个词条的关系时步骤:查找本词条包含的词条信息,写入关系表.一个词条可能包括多个词条.如“人民共和国”可能包括的词条有“人民”“共和国”.如一个词条不包含任何子词条,则需在关系表中添加一条数据(其中:ChildtheasurusID,ChildID,ChildTermName等列为空).
#-是否词库更新自动加载(1开启,0关闭)
lexicon.autoload=1
#-词库更新轮询时间(单位:秒)
lexicon.polltime=120
建立词条关系表后,定时将关系表数据按照固定格式写入词典文件中.
2.3 建立词典文件
为保证词表中词条信息同词典中词条信息保持一致,每天晚上重新生成词库文件.根据测试30万条数据写入词库文件需要8min.
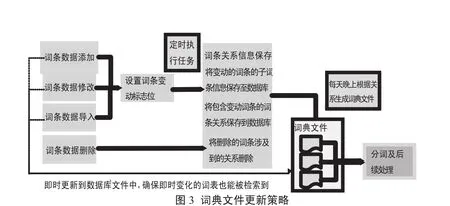
2.4 词条的更新
为保证词典文件的准确性,需在词条内容发生变更后记录词条的变动信息,以便及时更新词典文件.引起词条内容变动的原因包括:新增词条、修改词条、导入词条、删除词条.词典文件更新策略如图3所示.在删除一个词条时,需要将本词条包含的词条关系删除,还需将包含本词条的词条关系删除.例如删除词表ID为2,词条ID为300的词条,删除关系语句为:
Delete from Relation
Where(ThesaurusID=2 and Term ID=300)or(ChildtheasurusID=2 and Child ID=300)
3 运行结果
基于MMSeg分词的多部主题词表联合标注系统较好地达到了系统预计的要求,本文从标注速度、标注召回率、标注准确率三个指标进行了评价和验证.
分词速度对于分词系统是一项重要指标,通常分词系统对于分词速度要求十分严格[5].准确性作为核心指标,是指在进行分词处理后分得的正确的词或者短语的个数与分得的所有的词的个数之间的比值,分词系统的准确率应用达到99.9%以上才能基本满足其他领域的使用要求.分词准确率与分词速度两者相矛盾,在设计系统时要充分考虑两者的关系.召回率是检索出的相关文档数和文档库中所有的相关文档数的比率,衡量的是检索系统的查全率.
标注速度=文本长度/分词时间∗100%(单位:字/秒)
标注准确率=正确切分词数/文本总词数∗100%
标注召回率R=标注的词条/应该标注的全部词条
使用MMSeg分词后再进行标注,标注的性能达到了质的变化,前后两者对比如表3所示.运行硬件环境:CPU:AMD 3.2G;内存4G.

表3 标注速度对比表
标注的准确率,未分词标注时,直接采用待切分词条去数据库中匹配该词条是否出现在主题词表中,因此准确率为100%,采用分词标注后,由于涉及部分特殊字符,准确率稍有下降,但仍然完全满足系统的需要.表4为标注的准确率对比.

表4 标注准确率对比表
标注的召回率,由于改进了分词词典,相当于牺牲了部分分词的效率,保证了标注的召回率.标注召回率取得了大幅度的提升.标注的召回率对比如表5所示.

表5 标注召回率对比表
4 结束语
多部主题词表词条较多,同时由于存在交叉领域,因此词条之间存在包含或者重复等较复杂的关系,但是尽可能地标全是系统作为一项基础研究的条件,因此给实际工作带来了困难.本文将MMSeg分词引入到标注中,实现基于多部主题词表的联合标注,能够大大提高标注的速度和精度.但是由于MMSeg分词无法解决召回率的问题,本文改进了分词词典,将词表及其词条和子词条关系引入至词典中,从而保证了标注的召回率.多部主题词表联合标注作为一项基础性工作,使其后的专业知识库的构建以及深度数据挖掘成为可能.
[1]闫莹莹,许德山.汉语科技词系统在文献自动赋词标引中的应用研究[J].数字图书馆论坛,2013, (11):2-8.
[2]李鹏,朱礼军.叙词表多表联合标注系统设计与实现[J].数字图书馆论坛,2013,(11):21-26.
[3]MMSEG:AWord Identification System for Mandarin Chinese Text Based on Two Variants of the Maximum Matching Algorithm[EB/OL].(2000-03-12)[2014-12-08],http://technology.chtsai.org/mmseg/.
[4]蒋建洪,赵嵩正,罗玫.词典与统计方法结合的中文分词模型研究及应用[J].计算机工程与设计, 2012,33(1):387-391.
[5]刘延吉.基于词典的中文分词歧义算法研究[D].吉林:东北师范大学,2009.
Research and Implementation of Multi-Thesaurus Joint Labeling System Based on MMSeg Algorithm
Chen Xiaoyan
(Shaoxing Vocational and Technical College,Shaoxing,Zhejiang 312000)
In order to solve the problems that there are a greatnumber of terms and substrings in the Multi-Thesaurus joint labeling system,this paper presents the annotation method based on the MMSeg algorithm.The paper proposes adopting the MMSeg segmentation algorithm to cut text strings for annotating and improve the dictionary for substring annotation,thus ensuring a higher recall rate.The specific implementation of the relevant content and the operation result show that the Multi-Thesaurus joint labeling system based on the MMSeg segmentation algorithm meets the practical requirements in terms of the annotation speed,recall rate and precision rate.
dictionary;annotation;MMSeg algorithm;ambiguity processing;thesaurus
TP393
A
1008-293X(2015)07-0039-06
0 引言
表,又称叙词表,由词与词之间用代属分参等关系组成,是文献与情报检索中用以标引主题的一种检索工具.主题词表作为一种结构化的概念集合,在信息资源的描述、组织和检索中发挥重要的作用.利用主题词表进行标注工作,尤其是利用多部主题词表进行联合标注,能够进一步描述和组织信息资源,从多视角,多角度地揭示文章的内容,将非结构化文本进行结构化,为信息抽取、深度检索、智能推理,以及知识库的建立提供了基础.
(责任编辑 鲁越青)
10.16169/j.issn.1008-293x.k.2015.07.09
2015-02-06
陈晓燕(1973-),女,浙江温州人,讲师,主要研究方向:信息处理.
