一种基于重用本体的语义标注系统
2015-06-07吴国芳余玉霞
吴国芳 余玉霞
(绍兴职业技术学院 信息工程学院,浙江 绍兴312000)
一种基于重用本体的语义标注系统
吴国芳 余玉霞
(绍兴职业技术学院 信息工程学院,浙江 绍兴312000)
本体的模块化是解决本体重用的有效技术手段.针对本体的数量越来越多、内容越来越丰富带来的本体应用障碍,提出建立本体重用机制,将符合规范的本体引入到系统,实现多个本体驱动的语义标注.文章还介绍了标注过程中的冲突检测、标注结果可视化展示和导出等功能.实践表明系统提供了极大的灵活性和本体可重用性.
本体;模块化;语义标注;自动标注;手工标注
0 引言
语义标注是把HTML或者XML中描述资源的元数据与资源建立关联的过程[1],是使用“语义标签(semantic tags)”揭示资源语义的有效手段.语义标注能够建立联系从隐式语义到语义揭示的桥梁,使计算机理解Web信息资源语义成为可能,也为信息抽取、本体构建、知识表示和智能推理提供了条件.本体技术在语义标注中显示出巨大的生命力,可以通过一个预先创建的本体指导和引导标注过程(即本体驱动的语义标注).如何实现Web页面的自动标注和本体的自动化构造,是摆在语义Web和Web智能研究者面前的一项艰巨任务[2].而且,语义标注也是目前本体应用的瓶颈问题[3].
本体模块化的类型有模块化本体设计、模块化现有本体和模块化本体组合3种.模块化本体组合是从大规模复杂的多个本体中抽取相关的模块以满足当前任务需要.对于大型本体,如UMLS(United Medical Language System)集成了约90万个概念所对应的200多万个名称和1200多万个关系,用户往往只需要其中很小的一部分内容;因此,要重用和整合给定本体的一部分,需要确定本体中的相关部分和在满足它们语义定义的情况下重用他们.
基于本体的语义标注方面,国内外相关研究主要有:张功杰[4]等提出了基于本体语义标引模型的语义标引方法.魏墨济[5]等基于结构将本体分割成具有较高语义独立性的片断,实现语义网中无结构专业文档的自动标注.米杨[6]等以顶级本体统控领域本体进行本体整合的方法标注电子病历信息资源.张泽宇[7]等结合本体知识库和WordNet的语义知识构建并利用字典库,实现文档的语义标注.
基于本体模块化研究方面,郭文丽[8]等将粒度计算方法与分面分类理论相结合定义本体的粒度属性,提出建立基于粒度的本体模块描述方法,帮助用户从现有的大型本体中抽取出所需模块.王润梅[9]等通过建立本体依赖图的拉普拉斯矩阵抽取本体模块,提出一种基于模块抽取的大本体分块映射方法.张维一[10]等将本体组织成多个本体模块集成的形式,构建了汽车驾驶培训领域本体,实现本体模块间的通信.冯兰萍[11]等提出一种通过本体模块的裂变、重组、重用实现模块化本体的构建方法.刘紫玉[12]等提出了一种子领域本体协同进化方法,并设计了协同进化算法.综合来看,基于本体的标注和本体的模块化均有一些研究,但是如何利用本体的重用机制实现通用化的语义标注却鲜有研究.
1 系统设计需求分析
作为一个语义标注系统,本体决定了用户待标注的内容,而每个用户使用的本体各不相同.随着本体研究的深入,本体的数量越来越多,本体的内容也越来越丰富,不可能也没必要专门针对每个用户设计其标注的本体.作为一个标注系统,系统中的标注方案并不是固定的,而是会逐渐增加的.因此,本项目的标注系统要求能够实现本体的重用,能够适应变化的语义标注系统.基于重用本体的语义标注系统,一方面要考虑本体的重用性,多种本体能够进入本系统,利用顶层本体设计保证对多种本体的通用性;另一方面能够利用系统中的本体进行语义标注.具体来说,本系统必须满足以下设计需求:
(1)设计顶层本体,实现多种格式的本体能够进入系统,进行解析,实现本体的重用.系统必须制定统一的规范,符合该规范的本体能够进入本系统.本体的重用,并不需要将其所有概念、关系和实例均纳入本系统,而是有所取舍,保证系统的精简性与效率.
(2)支持多个本体的重用.用来标注的本体,并不只是一个本体,而是能够支持多本体的联合语义标注.因此,系统应该设计一些通用的类和属性能够高度概括原本体,并重用各个本体的相关概念和实例等信息;支持用户将各种本体导入系统的要求,且能使用这些本体进行语义标注.
(3)支持标签管理.系统支持自动标注,但也要支持手动标注,自动标注与手动标注可联合起来应用.标签管理保证了本体的重用性,能进一步实现本体的自定义扩展.
(4)支持标注的冲突检测.多个本体多次标注可能存在标签冲突等问题,因此,适当的冲突检测机制必不可少.
(5)支持标注结果的展示与导出.标注结果的展示应尽可能使用户显性化,能够通过颜色来区分不同的本体.另外,系统应支持对标注结果的导出,并说明标注中用到的本体信息.
2 系统总体结构
根据上述系统需求分析,基于重用本体的语义标注系统能够实现网络环境下多个用户对各自文档(文档集)利用重用后的本体进行标注,满足多用户多文档的标注与管理,以及用户管理、权限管理和日志管理等基础服务功能.系统由基础服务子系统、本体管理子系统、文档库管理子系统、文档语义标注子系统以及标注结果管理子系统等5个子系统组成,每个子系统包含若干功能模块.
语义标注是系统核心功能,本体管理是语义标注的基础,文档管理、基础服务为其提供支持,结果管理模块为语义标注提供展示等.具体来说,本系统主要包括5部分,分别为:(1)基础服务功能,包括数据清洗、用户管理、日志管理以及相关的权限管理;(2)用于标注的本体管理功能,主要基于本体的创建、本体所属类别的创建、类别所属词条的创建等管理和统计功能,通过对本体的管理完善标注的本体;(3)待标注的文档库管理相关的功能,包括文档库的创建、修改,以及每个文档库包含的文档的浏览、导入、导出和统计汇总等;(4)文档语义标注功能,包括待标注文档库的设置、用来标注的本体设置,以及自动标注和手工标注等;(5)标注结果管理功能,包括标注效果预览、标注结果导出、报表导出以及标注标签的统计等.系统整体功能与流程结构如图1所示.
3 具体实现
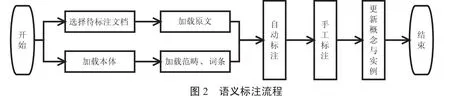
基于重用本体的语义标注系统实现的关键在于重用本体的构建,以及标注流程的设计.重用本体的构建原则为快速构建、支持增加的词条与实例、保证标注的可维护可扩展性.在标注流程上,系统采用先自动标注后手工标注的混合标注方式.标注详细流程如图2所示.手工标注能够更新本体的词条,强化了后期的自动标注功能.为了实现系统目标,需要构建与管理本体、自动标注、手工标注、标签冲突检测,以及标签的添加与删除等方面,其具体实现方式如下.
3.1 重用本体的构建与管理

本体(Ontology)是共享概念模型明确的形式化规范说明[13],它是一种有效的表示概念层次结构和语义的知识组织工具.系统设计的重用本体是实现语义标注的基础.顶层本体(Upper-level Ontology)是用来描述概念之间最普遍联系的知识体系,其揭示了领域知识在更高语义层次上的关系.利用顶层本体进行语义标注主要是利用顶层知识体系特点,指导标注本体库的本体间整合,进而形成具有以顶层本体语义结构形式为基础的统一本体资源,并以整合后的统一本体作为标注本体对语料库进行统一语义标注.顶层本体有标注案例类(AnnotationCASE)、类别类(CategoryClass)和词条类(WordClass)等,具体重用本体结构如图3所示.每个类别类和词条类下面有中文和英文取值.在标注时可以实例化一个案例,并创建相应的类别类和词条类.词条类之间的同义词作为概念的实例.相应的类别类实例后就是标注对应的标签集.具体而言,相应的属性有:hasCreator,hasCreateTime,hasColor,hasCode,hasCnValue,hasEnValue,hasCategory,hasFatherCategory等.这种结构,可以方便地将主题词表(范畴对应于类别类)、同义词表(词条类和实例)进入转换后导入系统.
3.2 自动标注
自动标注是通过机器快速地进行自动或批量标注.对于进入文档库中的文档,首先采用自动标注方式进行.设置待标注的本体后,可以进行自动标注.自动标注可以一篇一篇标注,也可以采用批量的方式标注.本系统采用的自动标注处理过程如下列代码所示:


3.3 手工标注
自动化语义标注有利于实现工程的自动化.交互式手工语义标注往往由专家来操作,因此标注的准确度很高,然而由于人的随意性较大,在面对海量资源时标注的时间和速度方面存在效率低下的问题.因此,从工程化角度考虑,宜采用自动化大规模标注与人工辅助标注相结合的方式.自动标注完成后,用户可以查看标注效果,并进一步进行手工标注.手工标注一般由专业人员进行标注,标注方式更加灵活.手工标注过程包括获取用户待标注的类别代码、待标注的文本和位置信息,并根据情况使用添加标注或删除标注进行不同的操作.手工标注详细过程如图4所示.
手工标注过程中,获取鼠标选择的文本信息是一项重点工作.获取的信息包括两方面的内容:其一是获取鼠标在网页正文部分DIV中的文本内容;其二是获取文本在正文中的位置信息,即文本内容在正文DIV中的起始位置(start)和结束位置(end).本系统使用JS脚本获取相关信息.JS脚本获取DIV选中文字在整篇文章的起始位置和结束位置,主要代码如下:


3.4 标签冲突检测
标签冲突检测是指当待标注文本中出现多个相同的词条而且词条之间存在重合情况时,可能出现语义冲突,此时要从多个候选的语义对象中选择唯一的标注词条进行标注,即语义消歧(semantic disambiguation).只有标签冲突检测合格时才能正确地进行语义标注.系统中,标签冲突存在两个方面,一是存在标签交叉,二是存在所属类别冲突.标签冲突检测的两种情况如图5所示.

所谓标签交叉,就是一个标签的开始和结束标签中包含有其他标签的一半标签.标签交叉判断可以根据已标注标签与待标注的位置(开始位置S1、结束位置E1)进行判断.若满足下面两条件之一,则判断存在标签交叉的情况:
(1)S1<Sn and Sn<=E1 and E1<En
(2)Sn<and S1<=En and En<E1
类别冲突是指用来标注的某个词条同时属于相矛盾的类别,其原因是本体所属类别之间存在属分关系.例如,在“皮肤病本体”中,一级类别名称为“疾病(A01)”下存在下级类别名称“呼吸道疾病(AD02)”;此时,若词条“感冒”已经标注为“呼吸道疾病”类别,就不应该再标注为“疾病”类别,因为这两个类别属于父子关系.类别冲突可以通过本体的清洗解决,但是对于手动标注,尤其是当用户标注已经出现在本体中的词条上时,本系统建立冲突检测机制解决冲突.例如,某词条已经标注为类别A,此时若再选择一段包括已标注类别A文本的词条标注为相冲突的类别A1,则本系统会提示用户不能进行标注.
3.5 标签添加与删除
冲突检测合格后,系统判断操作类型,对标签进行添加或者删除.
当用户选择一段文本进行标注时,如果选择的文本原来标注过而且选择本体类别同原标注的类别相同,则系统判定当前操作类型为“删除标注”.添加标签时,将选择的文本、点击的本体类别、选择文本的开始位置、选择文本的结束位置、当前文档ID、选择文本的长度等信息记录在数据库中.标签的删除是将选择文本中包含的成对标签移除,系统还支持删除当前文档的所有标注信息.删除标签包括清除html文档中当前选择的标注信息和移除数据库中相关标签记录两个动作.从数据库中移除开始位置S1和结束位置E1所包含的标签信息,系统使用下列语句进行删除:
Delete from表名where S1<=StartPos and EndPos<=E1
4 应用效果
本文设计的基于重用本体的语义标注系统已经开始实际应用,其功能在不断加强与完善中.用户可以根据自己的需求,定制不同的标注本体进行标注,具有极大的灵活性.标注后的结果通过HTML页面展示,用户能够一目了然看到标注的词条.图6为其中一个医学本体的数据浏览,其中左侧为本体导入系统的范畴,右侧为范畴对应的实例.图7为标注页面显示,同一种颜色的标签意味着来自同一个本体,而不同的颜色标签对应着不同的本体.

图7中,对于“诊断”(实例代码名称为“AC08”)这个词条,对其语义标注后,添加的标签代码为“AA04”,其对应的类别名称为:“分析、诊断、治疗技术和设备”,其显示格式与实际标注代码如下:
<本体代码:类别代码style=”color:red”></本体代码:类别代码>
实际标注代码为:<CASE1:AA04 style=“COLOR:red”start=“122”end=“124”>诊断 </ CASE1:AA04>

5 结束语
为了提高语义标注的实用性和本体的重用性,本文从实际需求出发,设计与实现了基于重用本体的语义标注系统.顶层本体的构建保证了系统的实用性,也是其驱动进行混合语义标注.自动标注与手工标注的结合,既有利于系统的工程化推广,也保证了系统标注的准确性.另外,冲突检测也是系统准确率提高的关键.本系统的不足之处在于当词条数量较大,例如达到数十万条时,判断的方式在效率方面显得不足.如何更有效的标注是未来要进一步研究的重点.Web文档的语义标注是语义Web与Web智能的基石,系统下一步研究的重点是怎样结合实际标注效果进行智能检索的应用与开发.
[1]Erdmann M,Maedche A,Scnurr H-P,et al.From manual to semi-automatic semantic annotation:About ontology-based textannotation tools.The COLING 2000Workshop on Semantic Annotation and Intelligent Content,Luxembo urg,2000.
[2]王本年,高阳,陈世福,等.Web智能研究现状与发展趋势[J].计算机研究与发展,2005,42(5):721-727.
[3]牟冬梅,范轶,王丽伟.数字资源语义互联研究(III)——语义标注子系统的设计与实现[J].现代图书情报技术,2010(9):13-17.
[4]张功杰,黄穗.基于本体的语义标引研究与实现[J].计算机工程与设计,2008,29(8):2078-2080.
[5]魏墨济,于涛.基于领域本体的专业文档语义标注方法[J].计算机应用,2011,31(8):2138-2142.
[6]米杨,曹锦丹.顶级本体统控的多本体语义标注实证研究[J].现代图书情报技术,2012(9):36-41.
[7]张泽宇,李莉,谭凤,等.基于语义的文档标注方法研究[J].计算机工程与科学,2013,35(9):151-156.
[8]郭文丽,张晓林.基于粒度的本体模块描述方法[J].现代图书情报技术,2010(2);1-6.
[9]王润梅,徐德智,赖雅,等.基于模块抽取的大本体分块与映射[J].计算机科学,2011,38(10):248-251.
[10]张维一,陆汝占.本体模块化的研究与实现[J].计算机应用研究,2007,24(11):206-209.
[11]冯兰萍,朱礼军,蒋亚东.一种模块化本体构建方法研究[J].现代图书情报技术,2010(6):53-59.
[12]刘紫玉,黄磊,杨明欣,等.基于模块化本体的协同进化方法研究[J].情报杂志,2013,32(10):131-135.
[13]Studer R,Benjamins V R,Fensel D.Knowledge engineering:Principles and methods[J].Data&Knowledge Engineering,1998,25(1-2):l61-197.
Semantic Annotation System Based on Reuse Ontology
Wu Guofang Yu Yuxia
(College of Information Engineering,Shaoxing Vocational and Technical College,Shaoxing Zhejiang 312000)
Ontologymodularization technique is an effective solution to ontology reuse.To approach the obstacles in ontology application with the growing number and content of ontology,this paper proposes establishing ontology reusemechanism so as to bring into the system the ontology that conforms to the norms,hence the semantic annotation driven by diversified individuals.The paper additionally introduces the conflict detection and annotation process visualization and export functions in semantic annotation.The practice shows that the system offers great flexibility and reusability of ontology.The reuse ontology for semantic annotation is an effective attempt to combine ontology reusewith its application,and it has laid the foundation for such semantic applications as the realization of knowledge discovery.
ontology;modularization;semantic annotation;automatic annotation;manual annotation
TP391
A
1008-293X(2015)07-0032-07
(责任编辑 鲁越青)
10.16169/j.issn.1008-293x.k.2015.07.08
2015-01-19
浙江省大学生科技创新资助项目(2014R458004);浙江省教育厅高等学校访问学者专业发展资助项目(FX2013236).
吴国芳(1978-),女,浙江东阳人,硕士,讲师.研究方向:智能信息处理与软件工程.
