面向信息抽取的指代消解探究
2015-06-01许永良周晓辉李晓戈
许永良,周晓辉,李晓戈
(西安邮电大学计算机学院,西安 710121)
面向信息抽取的指代消解探究
许永良,周晓辉,李晓戈
(西安邮电大学计算机学院,西安 710121)
指代消解是自然语言处理中的重点难点,对信息抽取具有重要意义.指代分有三种形式:代词指代,名词指代及零形回指.其中代词指代和名词指代是汉语中最基础的指代形式,以上两种指代的消解是指代消解研究的基础.为解决这一基本问题,使用决策树方法同时对两种形式指代进行处理.实验结果显示,所提出方法在不牺牲指代消解准确率的基础上,较大提高了指代消解的召回率.
信息抽取;指代消解;命名实体;决策树;有限状态机
指代消解是信息抽取中极其重要的一项任务.在正常文本中,相同信息会在同文本中出现若干次.作者为了行文简练,文本的概念关联性会更多地通过指代关系来描述.为实现相关信息的融合,获得相应信息在该文本中最完整的描述集合,将这些指代相互联系起来是十分必要的.
1 指代相关概念
指代作为一种常见的语言现象,广泛存在于自然语言的各种表达中,它是指篇章中的一个语言单位(通常是词或短语)与之前出现的语言单位存在的特殊语义关联,其语义解释依赖于前者.用于指向的语言单位称为指代语(Anaphor),被指向的语言单位称为先行语(Antecedent),而确认指代语所指的先行语的过程即为指代消解.
2 指代消解相关研究
指代消解的相关研究历史很长.早期方法多偏向于理论中探索,使用大量人工编制的语言知识甚至是学科领域的知识来进行指代消解.近年来,机器学习等自然语言自动处理技术发展迅速,基于弱语言知识的自动指代消解技术广泛出现.但受制于弱语言知识,近年来自动指代消解技术的性能增进遇到了瓶颈,研究人员开始将目光转向结构化句法信息及语义信息等基于自动产生的深层语言知识方面的研究.
与其他语言不同,汉语回指的三种形式:零形回指,代词回指和名词回指中,零形回指出现的频率最高,分布最广,被认为是汉语回指的标准形式[1].代词回指和名词回指中回指词都有实体形式——相对应的回指词为代词和名词,相对于零形回指来说,这两种指代消解的类型是有标记的消解.零形回指中零形式的出现没有具体的标记,已有的零形回指的消解工作大多默认零形式位置已知,人工标注零形式的位置.
由于实际需要,自然语言处理领域的中文指代消解的研究正迅速发展.但受限于中文的特点,目前更集中在有实体形式的代词及名词指代消解方面,零形回指的处理研究较少.
人称代词方面,王厚峰等采用了近似Mitkov的基于弱化语言知识的方法,解决人称代词的消解[2];李国臣等使用决策树机器学习算法,结合优化选择策略,进行人称代词消解研究[3];王智强等利用决策树方法进行了中文共指消解处理研究[4].
名词方面,孔芳等提出一种基于中心理论的指代消解研究,在对代词指代消解基础上,增加了对名词指代的消解工作[5];谢永康等提出一种谱聚类的共指消解方法[6];胡乃全等基于最大熵模型对中文指代进行了消解研究[7];高俊伟等基于支持向量机方法对中文名词短语指代消解进行了研究[8].
3 实验内容
实验使用用于信息抽取的多层级混合架构自然语言处理系统.系统主要用于批量文本的信息抽取处理.
系统多层级模块间,传输同一数据结构—tokenlist[9].结构中标有文本中所有文字字符以及相应文字的特征属性.模块中,对文字特征属性进行添加删除操作.最终以命名实体为中心,创建相应关键实体的信息抽取结果文件—profile[10].
指代消解处理后,同一命名实体的实体词和相关指代词将完成合并,会大大丰富每一实体profile中的有效信息,并降低profile的合并复杂度.
本文基于规则方法,使用有限状态机,在tokenlist结构上,完成对文本中名词指代和代词指代的语句定位,使用决策树方法,完成对这两种回指的消解工作.
3.1 实验语料
语料库使用2012年6月中,在百度新闻栏目中截取的80篇文章语料,并进行了指代词的人工标注.
语料中对与命名实体相关的指代词进行了分类标注:先行词为命名实体的零形指代词、人称代词、名词指代词、代词名词组合指代词等.
3.2 指代消解处理流程
指代消解需要基本自然语言处理结果,相关系统流程如图1所示.
3.2.1 分词及词性标注
分词及词性标注使用中科院分词系统ICTCLAS进行基本处理.词性标注集文本处理范例:
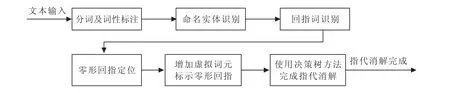
图1 指代消解系统流程
中国/ns 联合/v 网络/n 通信/vn 集团/n 有限公司/n (/w 简称/v “/w 中国/ns 联通/nz”/w)/w 于/p 2009年/t 1月/t 6日/t 在/p 原/b 中国/ns 网/n 通/v 和/c 原/b
中国/ns 联通/nz 的/u 基础/n 上/m 合并/v 组建/v 而/c 成/m,/w 是/v 中国/ns唯一/b 一/m 家/q 在/p 纽约/ns 、/w 香港/ns 、/w 上海/ns 三/m 地/u 同时/d 上市/v 的/u 电信/n 运营/vn 企业/n ./w
3.2.2 命名实体识别
信息抽取以命名实体为核心.本系统使用最基本的四类命名实体作为信息采集的中心:人物实体(NePer),组织实体(NeOrg),地点实体(NeLoc),时间实体(NeTIME).其中,与指代消解关系最为密切的是人物实体与组织实体.
人物实体(NePer)在文本中表现形式主要为人物姓名,以及部分常见别名、简称等,如:
曾国藩/NePer谥号是文正,因而也被人称为文正公/NePer.
组织实体(NeOrg)包括组织机构的全名及简称,如:
中国联合网络通信集团有限公司/NeOrg(简称“中国联通/NeOrg”)于2009年1月6日/NeTIME在原中国网通/NeOrg和原中国联通/NeOrg的基础上合并组建而成,是中国/NeLoc唯一一家在纽约/Ne-Loc、香港/NeLoc、上海/NeLoc三地同时上市的电信运营企业.
系统使用条件随机场模型进行人物实体、地点实体及部分组织实体的识别.辅助使用有限状态机对部分组织实体进行识别,并进行识别结果修正.
3.2.3 回指词识别
系统使用有限状态机对指代词进行识别.同时为特征属性明显的指代词添加相应特征.进行标记的特征有:
基本指代词(IsAnaphor),例:
这/IsAnaphor是一个梦一样的地方.
人物指代词(Anaphor-person),分有男性指代词(Anaphor-male),女性指代词(Anaphor-female),例:
李宏和王雪今年刚结婚,他/Anaphor-male是她/Anaphor-female的高中同学.
组织指代词(Anaphor-org),例:
东莞市鼎立检针器检测试验设备有限公司是一新兴的高科技公司,自成立以来,公司/Anaphor-org坚持:“诚实守信,持续发展”的经营理念.
地点指代词(Anaphor-area),例:
许昌市人大常委会主任石克生主持召开第十七次主任(扩大)会议,认真听取了该市/Anaphor-area农信社服务“三农”情况汇报.
复数指代词(Anaphor-complex),例:
对于湖人队和纳什的球迷来说,他们/Anaphor-complex只希望下赛季能有一个健康的纳什.
3.2.4 决策树方法进行指代消解
决策树方法是在分类技术方面应用最广泛的一种方法,也是目前对一般指代消解处理性能较优秀的方法之一.本文参考王智强的《基于决策树的汉语代词共指消解》搭建决策树指代消解模块.流程如图2.
系统使用80篇新闻语料的前60篇作为训练语料,后20篇作为处理对象.
3.3 实验数据
80篇语料中,与命名实体相关,即指代词数据如表1所示:
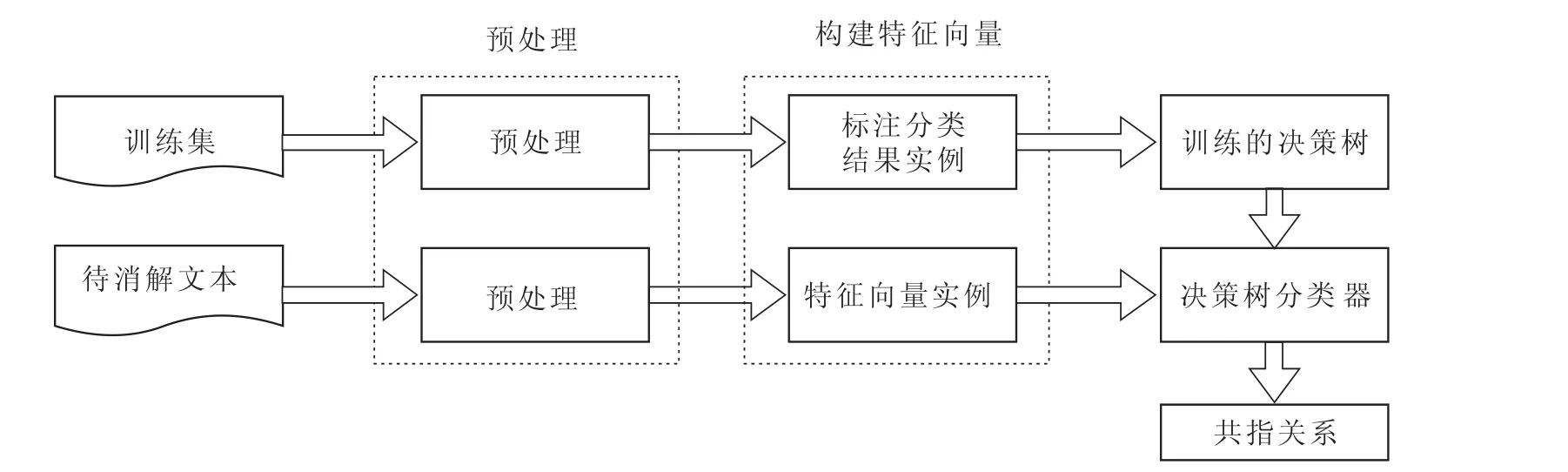
图2 指代消解模块原理图

表1 80篇语料命名实体指代词统计
指代消解完成结果如表2所示:

表2 指代消解结果统计
指代消解准确率和召回率结果统计如表3所示.
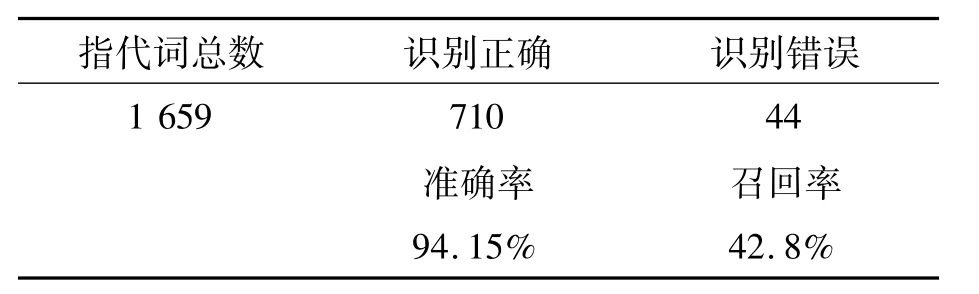
表3 指代消解准确率和召回率
3.4 实验结果分析
本文共选取4个feature作为决策树训练和分类的依据:sig-plu,gender,nature,distance.各个feature的属性值及说明如下:
(1)sin-plu表示的是先行词和代词之间单复数的一种关系,sin-plu的值总共有3种情况,分别是true、false和unknown.当先行词与代词都为单数或者先行词与代词都为复数时,此时sin-plu为true;当先行词与代词之间的单复数不一致时,此时sin-plu为false;当先行词和代词两者中有一个词的单复数未知时,此时sin-plu为unknown.
(2)gender表示的是先行词与代词的性别之间的一个关系,gender的值总共有3种情况,分别是true、false和unknown.当先行词与代词都表示的是男性或者都表示的是女性时,此时gender的值为true;当先行词与代词之间的性别不相同时,此时gender为false;当先行词与代词两者有一个词的性别未知时,此时gender的值为unknown.
(3)nature表示的是先行词与代词在句子中做的句子成分是否一致.nature的值总共有3种情况,分别是true、false和unknown.当先行词与代词在句子中做的句子成分一致时,此时nature为true;当先行词与代词在句子中的句子成分不一致时,此时nature为false;当先行词与代词两者中有一个在句子中词性未知或者是两者的词性都未知,此时nature的值为unknown.
(4)distance表示先行词与代词之间的距离关系.当先行词与代词在同一个句子里时,此时distance为0;当先行词在代词上一个句子里时,此时distance为2,按照此关键依次增长.
自然语言处理的结果一般采用正确率(precision)、召回率(recall)评估试验结果,即


其中,正确率表示:在识别出的标注中,我们的判定有多少是正确的;召回率表示:在所有的标注中,被识别出来的标注有多少,包括正例和反例.
我们选取80篇文章中的60篇作为训练数据,通过决策树训练得到分类规则,剩余的20篇作为处理对象(测试数据),用训练得到的分类规则对测试数据进行分类测试.通过手工标注正确的指代集作为标准,对测试数据进行统计分析.
通过测试,通过决策树完成的指代消解结果中,代词指代词消解完成532个,其中正确个数501个,准确率为94.17%;名词指代词消解完成222个,其中正确个数为209个,准确率为94.14%.但是,总共1 659个指代词中,一共完成了754个指代词的消解(其中,正确消解710个,错误消解44个),召回率为42.8%.经过比对和分析,发现召回率过低的原因是某些指代词的指代词标注漏标.例如:在topic54中关于房地产的采访,有一段话:在他看来,房地产市场的调控还在延续,房价会往哪个方向走,依然是个未知数,根本看不清楚.文中,有人称代词“他”,但是系统并没有标注出指代词的feature,导致后续指代消解召回率的降低.
实验结果说明:基于决策树的指代消解,能够比较出色地完成代词指代消解和名词指代消解,但是其召回率有待提高.
4 结论
本文提出一种基于自然语言基本处理结果的用决策树进行指代消解的方法,该方法弥补了决策树忽略属性关联性的缺点.实验结果显示:人称代词指代消解和名称代词指代消解的准确率分别为:94.17%和94.14%,达到了较高的指代消解准确率.召回率为42.8%,召回率比较低,这也是我们今后要改进的方向.
基于决策树的指代消解方法是自然语言处理使用较为普遍的方法,与其他的使用规则过滤的方法不同,我们尝试使用自然语言基本处理和决策树来进行指代消解,取得了显著的效果.但是,召回率过低.
在后续的研究中,我们将会朝两个方向继续研究:(1)考虑更加复杂的、甚至是网络语料库,用其来进行决策树指代消解实验,检验基于决策树的指代消解方法的健壮性,并研究影响指代消解准确率的因素或者feature;(2)在进行词性标注处理的模块上,做出改进,提高系统的召回率.
[1] 陈平.话语分析说略[J].语言教学与研究,1987(3):3-19.
[2] 王厚峰.鲁棒性的汉语人称代词消解[J].软件学报,2005,16(5):700-707.
[3] 李国臣,罗云飞.采用优先选择策略的中文人称代词的指代消解[J].中文信息学报,2005,19(4):24-30.
[4] 王智强,李蕾,王枞.基于决策树的汉语代词共指消解[J].北京邮电大学学报,2006,29(4):1-5.
[5] 孔芳,朱巧明,周国栋,等.基于中心理论的指代消解研究[J].计算机科学,2009,36(6):219-222.
[6] 谢永康,周雅倩,黄萱菁.一种基于谱聚类的共指消解方法[J].中文信息学报,2009,23(3):10-16.
[7] 胡乃全,孔芳,王海东,等.基于最大熵模型的中文指代消解系统实现[J].计算机应用研究,2009,26(8):2948-2951,2955.
[8] 高俊伟,孔芳,朱巧明,等.基于SVM的中文名词短语指代消解研究[J].计算机科学,2012,39(10):231-234.
[9] SOONW,NG H,LIM D.Amachine learning approach to coreference resolution ofnoun phrase[J].Computational Linguistics,2001,27(4):521-544.
[10]ZHOU G D,SU J.A high-performance coreference resolution system using amulti-agent strategy[C]∥COLING'2004.Geneva,Switzerland,2004:522-528.
[责任编辑马云彤]
Anaphora Resolution Inquiry for Information Retrieval
XU Yong-liang,ZHOU Xiao-hui,LIXiao-ge
(School of Computer Science&Technology,Xi'an University of Posts&Telecommunications,Xi'an 710121,China)
Anaphora resolution is a difficult and important point in Natural Language Processing and important for information retrieval.Anaphora consists of three main forms:pronominal anaphora,nominal anaphora and zero anaphora.In Chinese,pronominal anaphora and nominal anaphora are themost fundamental forms,the resolution ofwhich are the research focus of Coreference Resolution.To solve this problem,we adopt Decision Tree Approach for the treatment of both the anaphora forms.The experimental result shows that the proposed approach can promote the recalling of anaphora resolution without lowering the precision.
information retrieval;anaphora resolution;naming entity;decision tree;finite statemachine
TP391
A
1008-5564(2015)02-0065-05
2015-01-15
许永良(1986—),男,山东烟台人,西安邮电大学计算机学院硕士研究生,主要从事高性能计算研究;
周晓辉(1978—),男,山东高密人,西安邮电大学计算机学院教授,博士,主要从事高性能计算、金融大数据研究;
李晓戈(1962—),男,浙江杭州人,西安邮电大学计算机学院教授,博士,主要从事自然语言处理研究.
