龚小龙,王明文,万剑怡,王晓庆
(江西师范大学 计算机信息工程学院,江西 南昌 330022)
结合邻近度的语义位置语言检索模型
龚小龙,王明文,万剑怡,王晓庆
(江西师范大学 计算机信息工程学院,江西 南昌 330022)
在传统的检索模型中,文档与查询的匹配计算主要考虑词项的统计特征,如词频、逆文档频率和文档长度,近年来的研究表明应用查询词项匹配在文档中的位置信息可以提高查询结果的准确性。如何更好地刻画查询词在文档中的位置信息并建模,是研究提高检索效果的问题之一。该文在结合语义的位置语言模型(SPLM)的基础上进一步考虑了词的邻近信息,并给出了用狄利克雷先验分布来计算邻近度的平滑策略,提出了结合邻近度的位置语言检索模型。在标准数据上的实验结果表明,提出的检索模型在性能上要优于结合语义的位置语言模型。
语义位置语言模型;Dirichlet平滑;邻近度信息;检索模型
1 引言
在过去的几十年间,信息检索领域出现了很多经典的模型,诸如布尔模型、向量空间模型以及概率模型等。1998年,Ponte和Croft[1]首次将统计语言模型应用于信息检索,提出了查询似然语言模型,之后研究者又陆续提出了隐马尔科夫模型、统计翻译模型和风险最小化模型等,但是大多数检索模型都是仅使用了词在文档中的频率这一特征,而未考虑词在文档中的位置关系,对那些相同词在不同文章中的位置和顺序的不同,大多数检索模型对这样的文档的检索得分是一样的,而考虑了位置关系的检索模型的检索效果就会有所区分。基于此,Lv和Zhai[2]提出了一种位置语言模型(PLM),该模型细微到每个位置建立一个语言模型,并成功应用于信息检索,而且考虑了文档中词与词的位置关系。但该模型还具有可完善的地方,在上述模型基础上,余伟和王明文[3]对其做出了改进,提出了一种结合语义的位置语言模型(SPLM),并在文中提出了一种新的技术——“平滑互信息”来度量两个词之间的转移概率。通过使用Jelinek-Mercer平滑和相对熵(KL)来衡量查询词的分布和查询词在文档中的位置i的检索得分。
信息检索中的关键任务是对用户的查询所匹配的相关性文档集进行排序。在这一领域里,概率模型已经很成功地被应用于文档的排序中。但是传统的检索模型并没有考虑一篇文档中查询词的邻近度信息,而最近几年提出的PLM模型和SPLM模型在其检索模型中也没有明确详细地指出查询词在文档中的邻近度关系。邻近度代表的是一篇文章中查询词和查询词之间的靠近程度和紧密程度,潜在的意思是,词与词之间如果越紧密,就越能说明它们的主题相关,也因此说明该文档和用户查询的意图是相关的。Beeferman,Berger和Lafferty[4]在其文中也表达出了词项邻近度对于词与词之间的依赖性有较强的影响。
先前也有一些研究将邻近度因素整合到已有的检索模型当中去[5-7],这些工作都说明了一个恰当的邻近度策略的设计可以提高概率检索模型的性能。本文提出了在SPLM的检索模型的基础上,加入了查询词在文档中的内部结构信息,即邻近度信息,来提升文档检索的准确率,并且我们使用了Dirichlet先验平滑方法来对比SPLM中的JM平滑的方法。实验结果表明本文提出的加入邻近度信息的检索模型使得文档检索的准确率相比于原检索模型有一定的提高。
本文组织如下:第2节对传统的模型与邻近度信息的结合进行了介绍与分析;第3节介绍结合邻近度的语义位置语言检索模型的构建;第4节描述了多种不同的词项邻近度策略的计算方法;第5节介绍了实验环境并对实验结果进行了分析;第6节是工作总结。
2 相关研究
词项邻近度所表达的是在一个指定的距离范围中词项同现的情况。国外有相当一部分工作是将词项邻近度的信息整合到传统的布尔模型和概率模型当中,如Keen[8-9]首先尝试将词项邻近度加入到布尔检索模型中,而后Buttcher[10]等人提出将词项邻近度得分加入到BM25中以此得到对多个不同数据集合上效率的提升。Tao[6]等在文章中系统地阐述了五个邻近度策略,并分别对KL距离的检索模型中和BM25检索模型中所达到的效率做了相应的比较。国内相关的工作中韩中元、李生[11]等提出的利用近邻信息取代聚类语言模型中的聚类信息,通过计算文档之间的KL距离来选择近邻文档,有助于消除聚类边界文档使用聚类语言模型时所带来的不确定性影响。对邻近度的建模可以看作是间接捕捉词项独立性的一种方法,在一些早期的工作当中,是通过计算查询词项在文档中的跨度和密度来度量文档间相似度得分的。文献[6]尝试将邻近度因子分别和BM25概率模型与KL距离模型相结合,最终的得分函数表示为式(1)和式(2)。
Rank(Q,D)=BM25(q,d)+
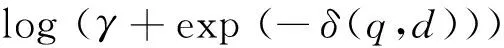
(1)
Rank(Q,D)=KL(q,d)+
(2)
其中,KL(q,d),BM(q,d)是分别通过KL距离和BM25模型计算的排序得分,δ(q,d)是和查询q有关的文档d中的邻近度距离的度量。
以上所有的工作主要集中在将词项邻近度信息整合到布尔模型和概率模型中,国内外也有部分研究者尝试将邻近度信息加入到语言模型中。但也包含两个主要的问题:1) 国内多数研究如文献[11]旨在处理文档之间的邻近关系,丁凡、王斌[12]在文中提出的融入词项依存关系的检索模型, 金凌、吴文虎[13]提出考虑一个句子中非相邻词之间的关系,通过距离加权函数来引入距离信息以及文献[14]中提出的查询词项之间的平行概念效应,大部分对文档中查询词项间的邻近度没有给出详细的形式化定义。2) 国外研究者如文献[15]中提出的整合邻近度信息的语言模型较复杂(如式(3)),从而导致算法复杂度过高,效果虽有,但致使计算效率降低,

(3)
其中dl,i为词i在文档dl中的频率,nl是文档总长度,C为文档集合,V为文档集合中所有词汇表的集合。Prox(wi)为词项邻近度得分,μ,λ为平滑参数。实验部分将文献[15]中提出的上述模型与本文提出的模型进行了复杂度的对比。
在语言模型方面,Lv和Zhai[2]提出的位置语言模型(PLM),余伟和王明文[3]提出的结合语义的位置语言模型(SPLM)在检索效率方面都有不错的效果。但以上语言模型中的平滑方法都忽略了文档中词项结构的信息,本文结合SPLM模型,并利用Dirichlet平滑的方法,仅考虑查询词在文档中的邻近度信息,为确保降低计算复杂度,本文采用平滑方法与邻近度线性结合的方式,以期能够更好地利用词在文档中的分布,获得检索性能上的提升。
3 结合邻近度的语义位置语言检索模型
为了形成一个有效的查询语句,用户会尽可能用多的查询词来共同的表达其查询的意图。在文档中查询词越是相近,此文档就与查询词越相关,文档就更能满足用户查询的意图。如给定两篇文档Da和Db,假设其他因素都是相同的,当查询q中的查询词在Da中比在Db中出现的要更加邻近,那我们可认为文档Da相比于文档Db和查询q更相关。由此,在SPLM上的检索模型中,增加查询词Wi为中心的邻近度得分这个因素。
3.1 语义位置语言检索模型的建立
在文献[3]中首先引入一个随机变量d,d表示文档D中其他位置与目标位置i的距离,这个距离含有正负关系(d>0,表示在目标位置i的后面,d<0表示在目标位置i的前面)。由此,d=1-i,d=2-i, ...,d=|D|-i就是样本空间一个划分,根据全概率公式有式(4)。
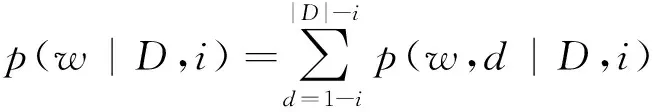
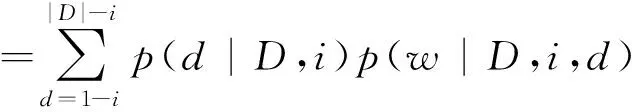
(4)
p(j|D,i)和p(w|D,j)的估计以及模型中其他概率估计均可参看文献[3]。并最终提出SPLM模型为式(5)。
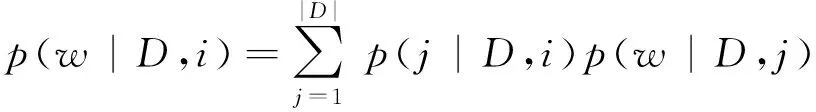
(5)
其中k(i,j)是权重函数(式(6)),文献[3]中选取高斯核函数来度量:
(6)
由上式可知: 当位置j离位置i越远时,位置j对位置i的权重就越小。还可以对式(5)的分母进行如下近似计算:
(7)
由于文档集中词的稀疏性,需对SPLM进行Jelinek-Mercer平滑,即文献[3] 最后提出的检索模型为式(8)。
(8)
其中ε是平滑参数,范围[0,1];p(w|D,i)可采用式(5)计算。
3.2 结合邻近度的语义位置语言检索模型的建立
假设有一查询“搜索引擎”和两篇不同的文档,文档1中为“…搜索引擎…”,而文档2中为“…搜索…引擎…” 直观上看,文档1中查询词是毗邻的,文档1理应比文档2的排序得分高。相比之下,文档2中两个查询词不相邻,并不能直接表达出作为名词的“搜索引擎”的概念,而更可能是一篇同时阐述有关“搜索”和“引擎”两个不同概念的文档。这就说明文档1查询的相关性要强于文档2,而事实上,在传统平滑算法的语言模型中,这两篇文档对于该查询的计算得分是相同的,这也暴露出语言模型中平滑方法的不足。
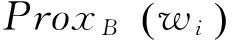
(9)
其中μ是平滑参数,wi表示查询语句中第i个位置的单词,|q|是查询语句的长度。
其次,使用w在查询词Q的分布和在文档D中位置i的分布的差异性(负KL散度)来衡量文档D中位置i的检索得分,并取文档中得分最高的前k个位置的平均得分作为文档D的检索得分:
(10)
所以如果位置i上w的分布与查询词中w的分布越一致,则检索得分S(Q,D)就越高。其中topK表示文档D中检索得分最高的k个的位置。
4 词项邻近度策略
第一, 如何定义一篇文档中两个不同的查询词之间的距离?
第二, 如何设计一个恰当的非线性函数来将距离转化为邻近度得分?
4.1 词项距离和邻近度得分定义方法
首先来解决第一个问题。要想知道不同查询词之间的距离,先要知道每个查询词在文档中的位置信息,但主要的困难在于一个查询词可能在一篇文档中出现了多次。本文按如下方式来解决,设Q={Q1,Q2……Qn}代表一条查询语句中不同的查询词,用另外一个集合PQi={Pi1,Pi2……Pim}来表示查询词Qi在文档D中出现的所有位置。用Dis(x,y;D)(式(11)和式(12))来表示不同词项间的距离。跟随文献[6]的工作,本文用词项在文档中的位置靠得最近的那段长度来作为这对词项之间的距离。
Dis(Qi,Qj;D)=
(11)
(12)
|D|代表的是文档D的长度,|PQi|代表的是查询词
Qi在文档D中出现的次数。这里要注意到词项对的距离是有对称性的即Dis(Qi,Qj;D)=Dis(Qj,Qi;D)。
解决了查询词之间距离的问题之后,接下来定义一个函数来将距离转化成词项对的邻近度得分。根据前面所得的分析可知,查询词距离越远说明表达的意图和文档主题越不相关,那它们的得分也要相应的低些。下面的指数形式的公式(13)用来给邻近度打分,其中arg是控制得分函数的参数,distance代表的是距离:
(13)
所以最终的词项邻近度得分本文定义为式(14)。
(14)
4.2 以词项为中心的邻近度计算方法
基于以上的策略,考虑三种不同的词项中心化邻近度计算方法(Minimum,Average和Summation)。
定义1(基于最小距离的词项邻近度(MinDist)): 在这个策略中,查询词项的邻近度得分是依靠查询词之间的最短距离来计算的,本文表示成式(15)。
(15)
定义2(基于平均距离的词项邻近度(Average)): 用所有查询词之间的平均距离来计算查询词项的邻近度分数,本文表示成式(16)。
(16)
定义3(基于所有词项对邻近度求和的词项邻近度(Summation)): 这个方法首先对任何一个查询词不同的配对进行邻近度得分计算,然后再将其相加作为本查询词的邻近度得分:
(17)
注意,以上提出的方法都要首先通过计算匹配查询词项之间的距离而后才能进行定义。
5 实验
5.1 数据集与评价指标
5.1.1 数据集介绍与预处理
本文选取了三个常用的标准测试文档集adi,
med, cran*ftp://ftp.cs.cornell.edu/pub/smart/,数据集的具体情况如表1所示。
预处理阶段主要进行了以下步骤:
Step1 提取了每篇文档中的
和<BODY>部分的内容;</p><p>Step2 对< TITLE >和<BODY>中的内容过滤非法字符(包括标点符号和阿拉伯数字等),只保留我们需要的英文单词,然后将英文字母全部转换成小写形式;</p><p>Step3 根据标准的英文停用词表,对Step 2所得的文本去停用词;</p><p>Step4 采用Porter Stemmer算法,对Step 3所得的文本进行词干化处理。</p><p><img src="https://img.fx361.cc/images/2023/0130/3fefd0ea1a0eac2044704770ea615e21575a3bdd.webp"/></p><p>表1 实验中的数据集</p><p>值得注意的是,Zhai在文献[17]的实验采取了保留停用词,文献[18]中采取了去除停用词。本文选择的是后一种情况,理由是停用词的加入会疏远词与词的位置关系。当然停用词不能去除得太多,因为这些词毕竟含有语义。在计算邻近度方面,我们只考虑了查询语句中在总词汇表中存在的查询</p><p>词,舍弃不在总词汇表中的查询词,然后计算其相应的邻近度。</p><p>5.1.2 参数设置与评价指标</p><p>本文对三种检索算法进行了实验: BM25和采用JM平滑的SPLM的检索模型,两者作为基准线;使用Dirichlet平滑改进的SPLM检索模型,为了方便,实验结果中简记为“SPLM_1”;结合邻近度的Dirichlet平滑的SPLM的检索模型,实验结果中简记为“Pro_SPLM”。</p><p>本文的检索模型和SPLM的检索模型含有1个共同的参数: topk,而Pro_SPLM,即公式(9),还另外含有2个参数: arg,μ。通过对数据集上的训练,按如下方法设置参数: (1)对于topk,三个数据集都取2;(2)对于核函数中的σ和公式(9)中μ这两个参数,将在表2的结果中具体给出;(3)本文在三个数据集中统一对Dirichlet参数μ取: 100,150,200,……,1 000做了实验。图1为Adi数据集上的数据结果,给出选取不同μ,σ对检索结果的影响,纵坐标为3-AVG的值;(4)在Pro_SPLM中一个重要的参数是arg,在第四部分中公式(13)提到,这个参数是用来控制不同查询词项邻近度得分规模大小的。当前,本文按如下的范围对arg进行设置: arg:1.1,1.2,……,2.0。本文选取最终的arg为1.7,在三个数据集上的效果都较好。SPLM中其他参数参照文献[3]中的设置。</p><p><img src="https://img.fx361.cc/images/2023/0130/5f76d20bdd8e46aba805b5436a5a008935c86662.webp"/></p><p>表2 三个检索模型在三个数据集上的检索性能</p><p>由于三个数据集上的相关文档是无序的,因此采用了下面三个检索度量指标:</p><p>(1) 3-AVG: 当召回率R分别达到三个等级(R=0.2,0.5,0.8)时,各自对应的准确率求均值作为3-AVG。</p><p>(2) 11-AVG: 当召回率R分别达到11个等级(R>0,R=0.1,0.2,...,0.9,1)时,所对应的准确率,再对这11个准确率取平均值作为11-AVG。</p><p>(3) MAP: 平均准确率是每篇相关文档检索出后的准确率的平均值。</p><p>5.2 检索性能对比</p><p>表2给出了四个检索模型在三个数据集上的检索得分,需要说明的是:①粗体: 在每个数据集上,四个检索模型中获得最高检索得分的数值使用粗体标出;②百分比: 分别表示SPLM_1在SPLM基础上增加的百分比和Pro_SPLM在SPLM_1基础上增加的百分比;③SPLM_1和Pro_SPLM下面的参数: 表示两个模型获得最优性能时所取的参数值。</p><p>这里要重点说明一下表2中Pro_SPLM用的邻近度策略是PSumProx,本文在表4中进行了三种不同策略的比较。同样我们在表3中给出了四种检索模型在MAP评价标准下的对比,对比结果和在插值平均(3-AVG/11-AVG)的评价标准下的对比效果一致。</p><p>表4中展现的就是不同邻近度得分计算策略分别在三个不同的数据集上的检索性能的比较,可以看到PSumProx和PMinDist都要比PAveDist的性能好。同样的还可以看到PSumProx比PMinDist性能上要优越一点。</p><p><img src="https://img.fx361.cc/images/2023/0130/bc2f6c29b9bc49907094f0068b856e592714adf8.webp"/></p><p>表3 MAP评价标准下的检索性能对比</p><p>通过三个检索模型的得分比较可发现: SPLM_1在三个数据集上都要优于SPLM;而Pro_SPLM在三个数据集上的检索得分都要明显好于SPLM和SPLM_1,特别是在adi上提升较大。直观上来说,检索效果对于那些更能从邻近度信息中获益的长查询语句来说应该更好,但是先前有工作表明当使用了邻近度的信息特征时,查询语句的长度和检索性能是成反比的[19]。而在本文工作当中正好说明了这点,经过统计,adi和med数据集中的查询语句的平均长度是三个数据集中比较短的,所以两者检索性能也是提高较多的。</p><p><img src="https://img.fx361.cc/images/2023/0130/2d2e6d7c58441df84bce4f5d8709d9140a6cd1d9.webp"/></p><p>表4 使用不同邻近度策略的Pro_SPLM在三个数据集上的检索性能</p><p>5.3 σ和μ对模型检索性能的影响</p><p>在文献[3]中,同样做出了σ对模型的解释,但它们是在PLM中和SPLM中做出的比较,本文主要是在SPLM_1和Pro_SPLM中说明。表2中,为了获得最优的性能,数据集最小的adi上σ在本文提出的模型中取40,稍大的med和cran都取了100。这说明,σ的取值变化是和数据集的大小成正比的,因本文考虑邻近度时只考虑了查询词在文档中的距离,实验的过程中发现,在adi数据集中,由于其数据量较小,文章的数量、长度和总词汇量也相应的少,一条查询语句中的查询词在文档中出现的次数会比较少,并且本文丢弃了查询语句中没有在总词汇表中出现的词,这样做的目的,一是为了提高查询的准确率,二是为了简化计算查询词之间的邻近度得分。同理在med和cran中,由于这两个数据集比较大,查询词分别在其文档中出现的次数也会变多,相应查询词的检索贡献就会越大。在图2中给出了adi数据集上的σ的敏感度分析,其他两个数据集上的曲线规律是类似的。</p><p>图2中曲线“SPLM_1_3-AVG”表示该数据集上基于SPLM_1的检索模型对3-AVG评价指标的检索得分,其他曲线代表含义可类推。由图可知: SPLM_1和Pro_SPLM在σ=40时获得最好性能;当σ小于35或大于45时,两个模型的性能整体上都呈现递减趋势;因为Pro_SPLM和SPLM_1只是邻近度上的区别,前者只是一个线性的结合,它们在变化趋势基本上是持平的。</p><p>在图3中表示出了在med数据集上不同的μ对检索模型的性能影响。med数据集上当σ=100性能达到最好,图3中的μ的范围都是在σ=100时计算的,以此来获得最优的参数μ。图3表明当μ=550,med数据集上的检索性能达到最好,再当μ增大时,两个模型的性能整体上保持平稳,趋于缓慢的下滑趋势,斜率变化非常小,说明σ相对与μ来讲,对模型的检索性能影响更大一些。经实验表明,改进后的检索模型对于不同的数据集,达到最优性能的μ一般不同,但基本处于[500,600]上,μ对检索模型性能的影响的效果和文献[16]中分析的Dirichlet平滑的效果基本一致。</p><p><img src="https://img.fx361.cc/images/2023/0130/5340ce37cc901a9886982c4612074dd8d189a16f.webp"/></p><p>图1 不同μ下,σ对评价标准的影响</p><p><img src="https://img.fx361.cc/images/2023/0130/73919b94bab52a9e1ad01ebab8c971e66849dfd2.webp"/></p><p>图2 σ对检索性能的影响</p><p><img src="https://img.fx361.cc/images/2023/0130/bad2d61871558193222898ab9325cb1a4e4f9950.webp"/></p><p>图 3 μ对检索性能的影响</p><p>5.4 模型复杂度分析</p><p>算法1给出了本文提出的检索模型的实现过程,算法2给出了式(3)的实现过程。给定数据集,本文提出的检索模型在训练过程中的时间复杂度分为:</p><p>1. O(Nd): 语义位置语言模型部分的复杂度主要来自文档的长度N和文档集的大小d。</p><p>2. O(NQ*Dis): 邻近度模型中复杂度主要考虑查询语句中所有查询词在文档中的位置关系,即算法1中步骤2和步骤3。Q为查询语句的长度,Dis为词项之间最小距离。</p><p>3. O(Nd)+O(NQ*Dis): 与邻近度模型线性结合,故本文提出的模型的总复杂度为上述两部分之和。</p><p>给定相同的数据集,算法2在训练过程中的复杂度分为:</p><p>1. O(Nd): 语言模型部分的复杂度主要来自文档的长度N和文档集的大小d。</p><p>2. O(NV*Dis): 公式(3)中给出的邻近度模型主要考虑查询词和文档集中所有词项的位置关系,即算法2中步骤2其中V为词汇表的长度。</p><p>3. O(Nd)*O(NV*Dis): 与邻近度模型是整体结合,在实现过程中在要考虑语言模型的结构。</p><p>则通过对比发现,由于V>>Q,且多项式复杂度远小于算法2的复杂度。则本文提出的模型在时间复杂度上具有一定优势。</p><p>算法1 结合邻近度的语义位置语言检索模型</p><p>输入:</p><p>D=(x1,...,xN): 文档向量</p><p>Q=(q1,...,qN): 查询词项向量</p><p>Dis (qi,qj;D): 查询词项在文档中的距离</p><p>f>0: 查询词项距离转换成邻近度得分</p><p>1. 首先对数据集中文档进行文档向量化,并记录每个单词的位置信息。</p><p>2. 其次对数据集中对应的查询语句向量化,并记录每一个查询词在文档中的位置。</p><p>3. 按照邻近度策略计算每个查询词的邻近度得分,只考虑文档中查询词之间的位置关系。</p><p>输出:</p><p>模型中利用Dirichlet平滑的语义位置语言检索模型与邻近度模型线性相加来计算Pμ(w|D,i),进而计算文档检索得分。</p><p>算法2 整合邻近度的语言模型</p><p>输入:</p><p>D=(x1,...,xN): 文档向量</p><p>Q=(q1,...,qN): 查询词项向量</p><p>Dis (qi,qj;D): 查询词项在文档中的距离</p><p>f>0: 查询词项距离转换成邻近度得分</p><p>1: 对文档进行文档向量化,记录每个单词的位置信息,以及整个数据集中词汇表信息。</p><p>2: 计算查询词与词汇表中所有单词的邻近度得分。见公式(3)。</p><p>输出:</p><p>模型中利用Dirichlet平滑的语言模型与邻近度模型整合为一体来计算 P(w|D,i),进而计算文档检索得分。</p><h2>6 结论及未来工作</h2><p>本文认为考虑查询词项邻近度的信息能够更合理地反映词项在文档中的分布,有助于提升检索模型的效果,因此将查询词在文档中的邻近度信息整合到结合语义的位置语言模型当中去,提出结合邻近度的语义位置语言检索模型。进一步地,对于查询词在文档中的位置关系给出详细的解释和关注。最后,在标准数据集上的测试了结合邻近度的语义位置语言检索模型的性能。总体上有如下几点工作: (1)采用Dirichlet先验平滑方法对检索模型提出改进,并结合邻近度的信息;(2)对词项之间的距离做了具体的定义,并引入非线性的函数,将距离转化成邻近度得分;(3)引入三种不同的计算邻近度得分策略,并在实验中带入不同检索模型进行性能比较;(4)实验表明基于Dirichlet平滑的SPLM检索模型在性能上要优于基于Jelinek-Mercer平滑的SPLM模型,而结合邻近度的Pro_SPLM检索也要明显好于上述所有检索模型;本文还分析了两个模型对受参数μ和σ的影响程度,得出了最优的μ取值范围。未来将在以下方面进一步研究: (1)本文提出的模型只是在小数据集上进行实验,在下一步的工作中将会在大数据集上进行检测。(2)本文中提出的结合邻近度的信息是线性的结合方式,即多项式模型,结合方式在不提高计算复杂度的前提下还有待进一步改善。</p><p>[1] Ponte J M, Croft W B. A language modeling approach to information retrieval [C]//Proceedings of the 21st annual international ACM SIGIR conference on research and development in information retrieval,Melbourne,Austrailia: ACM,1998: 275-281.</p><p>[2] Yuanhua Lv,Chengxiang Zhai. Positional language models for information retrieval [C]//Proceedings of the 32nd international ACM SIGIR conference on research and development in information retrieval,Boston: ACM, 2009: 299-306.</p><p>[3] 余伟,王明文,万剑怡,等. 结合语义的位置语言模型[J].北京大学学报(自然科学版),2013,49(2): 203-212.</p><p>[4] Beeferman D,Berger A, Lafferty J. A model of lexical attraction and repulsion [C]//Proceedings of the 8th Conference on European Chapter of the Association for Computational Linguistics,1997: 373-380.</p><p>[5] Bai J,Chang Y,Cui H,et al. Investigation of partial query proximity in web search [C]//Proceedings of the 21st Annual Conference on World Wide Web,Beijing,China: 2008: 1183-1184.</p><p>[6] Tao T, Zhai C. An exploration of proximity measures in information retrieval [C]//Proceedings of the 30th annual international ACM SIGIR conference on research and development in information retrieval,Amsterdam,Netherlands: ACM,2007: 295-302.</p><p>[7] Y Rasolofo, J Savoy. Term Proximity Scoring for Keyword-Based Retrieval Systems [C]//Lecture Notes in Computer Science,2003: 207-218.</p><p>[8] E Michael Keen. The use of term position devices in ranked output experiments [J]. The Journal of Documentation,1991,(47): 1-22.</p><p>[9] E Michael Keen. Some aspects of proximity searching in text retrieval systems [J]. Journal of Information Science,1992,(18): 89-98.</p><p>[10] Stefan Buttcher, Charles L A Clarke, Brad Lushman. Term proximity scoring for ad-hoc retrieval on very large text collections [C]//Proceedings of the 29th annual international ACM SIGIR conference,New York,USA: ACM,2006: 621-622.</p><p>[11] 韩中元,李生,齐浩亮,等. 面向信息检索的近邻语言模型[J]. 中文信息学报,2011,25(1): 67-70.</p><p>[12] 丁凡,王斌,白硕,等. 文档检索中句法信息的有效利用研究[J]. 中文信息学报,2008,22(4): 66-74.</p><p>[13] 金凌,吴文虎,郑方,等. 距离加权统计语言模型及其应用[J]. 中文信息学报,2001,15(6): 47-52.</p><p>[14] 乔亚男,刘跃虎,齐勇. 查询词相似度加权的邻近性检索方法[J].模式识别与人工智能,2013,26(2): 191-194.</p><p>[15] Jinlei Zhao, Yeogirl Yun. A Proximity Language Model for information Retrieval[C]//Proceedings of the 32nd international ACM SIGIR conference, Boston, USA: ACM,2009: 291-298.</p><p>[16] Zhai C, Lafferty J. A study of smoothing methods for language models applied to ad hoc information retrieval [C]//Proceedings of the 24th annual international ACM SIGIR conference,New Orleans,Louisiana,USA: ACM,2001: 334-342.</p><p>[17] Zhai C, Lafferty J. Two-stage language models for information retrieval [C]//Proceedings of the 25th annual international ACM SIGIR conference on research and development in information retrieval,Tampere,Finland: ACM,2002: 49-56.</p><p>[18] Yuanhua Lv,Chengxiang Zhai. Positional Relevance Model for Pseudo-Relevance Feedback [C]//Proceedings of the 33rd international ACM SIGIR conference on research and development in information retrieval,Geneva,Switzerland: ACM,2010: 579-586.</p><p>[19] Krysta M Svore,Pallika H Kanani,Nazan Khan. How Good is a Span of Terms Exploiting Proximity to Improve Web Retrieval [C]//Proceedings of the 33rd international ACM SIGIR conference on research and development in information retrieval,Geneva,Switzerland: ACM,2010: 154-161.</p><p>Semantic Positional Language Retrieval Models with A Proximity Information</p><p>GONG Xiaolong, WANG Mingwen, WAN Jianyi, WANG Xiaoqing</p><p>(School of Computer Information Engineering, Jiangxi Normal University, Nanchang, Jiangxi 330022, China)</p><p>In most existing retrieval models, the calculations on the relevance between the document and the query are based on the statistical features, such as within-document frequencies, inverse document frequencies, document lengths and so on. Recent studies show that the term position information can promote the precision of the query results, but how to best employ this information remains an open issue. This paper proposes to integrate the terms proximity information into the semantic positional language model(SPLM), with a Dirichlet prior distribution as smoothing measure to compute proximity. The proposed semantic positional language retrieval models with a proximity information performs better than classical semantic positional language model in the experiments.</p><p>semantic positional language models; Dirichlet smooth; proximity information; retrieval model</p><p><img src="https://img.fx361.cc/images/2023/0130/2c2ebd4c5ee4fd6ebd2e7c20c72ba95c3cf422db.webp"/></p><p>龚小龙(1991-),硕士,主要研究领域为信息检索与机器学习,数据挖掘。E-mail:gxl121438@sjtu.edu.cn王明文(1964-),博士,教授,主要研究领域为信息检索,数据挖掘,自然语言处理。E-mail:mwwang@jxnu.edu.cn万剑怡(1974-),博士,教授,主要研究领域为智能信息处理。E-mail:wanjianyi@aliyun.com</p><p>1003-0077(2015)04-0183-09</p><p>2013-07-23 定稿日期: 2013-11-25</p><p>国家自然科学基金(60963014,61163006,61203313);江西省科技厅自然科学基金(20132BAB201038)</p><p>TP391</p><p>A</p></div></div>
<!-- <div class="m_article_pdf"><a href="https://cimg.fx361.com/kkb.apk">查看pdf文档请下载app</a></div>--><div class="article_love_part">
<h3>猜你喜欢</h3>
<div class="article_love_keyword"><span><a href="/tags/7/d/79290a9cd3cdc449/3483544.html" target="_blank">集上</a></span><span><a href="/tags/3/5/c0eb5cb77d8024b6/1.html" target="_blank">文档</a></span><span><a href="/tags/5/a/3ec7629d528fb6a2/1.html" target="_blank">语义</a></span></div>
<div class="article_love_news"><dd><a href="/news/2022/0831/11267948.html" target="_blank" title="真实场景水下语义分割方法及数据集">真实场景水下语义分割方法及数据集</a></dd><dd><a href="/news/2022/0531/10341748.html" target="_blank" title="浅谈Matlab与Word文档的应用接口">浅谈Matlab与Word文档的应用接口</a></dd><dd><a href="/news/2021/1227/14194345.html" target="_blank" title="GCD封闭集上的幂矩阵行列式间的整除性">GCD封闭集上的幂矩阵行列式间的整除性</a></dd><dd><a href="/news/2021/0727/8621423.html" target="_blank" title="有人一声不吭向你扔了个文档">有人一声不吭向你扔了个文档</a></dd><dd><a href="/news/2020/0331/14523854.html" target="_blank" title="语言与语义">语言与语义</a></dd><dd><a href="/news/2018/1225/16095743.html" target="_blank" title="R语言在统计学教学中的运用">R语言在统计学教学中的运用</a></dd><dd><a href="/news/2017/0506/1721133.html" target="_blank" title="Word文档 高效分合有高招">Word文档 高效分合有高招</a></dd><dd><a href="/news/2017/0131/15562078.html" target="_blank" title="批评话语分析中态度意向的邻近化语义构建">批评话语分析中态度意向的邻近化语义构建</a></dd><dd><a href="/news/2016/0311/11669282.html" target="_blank" title="“吃+NP”的语义生成机制研究">“吃+NP”的语义生成机制研究</a></dd><dd><a href="/news/2015/1222/13022959.html" target="_blank" title="Persistence of the reproductive toxicity of chlorpiryphos-ethyl in male Wistar rat">Persistence of the reproductive toxicity of chlorpiryphos-ethyl in male Wistar rat</a></dd></div>
</div><div class="phbk_part"><h3>杂志排行</h3>
<ul><li><a href="/bk/hzjjykj/202413.html" class="title">《合作经济与科技》</a><a href="/bk/hzjjykj/202413.html" class="date">2024年13期</a></li><li><a href="/bk/hyyjk/202410.html" class="title">《婚育与健康》</a><a href="/bk/hyyjk/202410.html" class="date">2024年10期</a></li><li><a href="/bk/swyzhsby/20247.html" class="title">《思维与智慧·上半月》</a><a href="/bk/swyzhsby/20247.html" class="date">2024年7期</a></li><li><a href="/bk/tckjyjs/202311.html" class="title">《陶瓷科学与艺术》</a><a href="/bk/tckjyjs/202311.html" class="date">2023年11期</a></li><li><a href="/bk/zgsr/20247.html" class="title">《中国商人》</a><a href="/bk/zgsr/20247.html" class="date">2024年7期</a></li><li><a href="/bk/jsbl/20244.html" class="title">《教师博览》</a><a href="/bk/jsbl/20244.html" class="date">2024年4期</a></li><li><a href="/bk/sdjy/20246.html" class="title">《师道·教研》</a><a href="/bk/sdjy/20246.html" class="date">2024年6期</a></li><li><a href="/bk/zgdwmy/20246.html" class="title">《中国对外贸易》</a><a href="/bk/zgdwmy/20246.html" class="date">2024年6期</a></li><li><a href="/bk/bl/20246.html" class="title">《伴侣》</a><a href="/bk/bl/20246.html" class="date">2024年6期</a></li><li><a href="/bk/jjjsxzxx/20246.html" class="title">《经济技术协作信息》</a><a href="/bk/jjjsxzxx/20246.html" class="date">2024年6期</a></li></ul>
</div><div class="bk_part">
<div class="bk_im_b"><a href="/bk/zwxxxb/20154.html"><img src="https://img.fx361.cc/images/2023/0130/13e3e3d796680a5ba73e6ef1a3cb5708a2e3fe2d_mini.webp" alt=""></a></div>
<div class="dbk_title"><a href="/bk/zwxxxb/" target="_blank">中文信息学报</a></div>
<div class="dbk_date"><a href="/bk/zwxxxb/20154.html" target="_blank">2015年4期</a></div>
</div><div class="others">
<h3><a href="/bk/zwxxxb/" target="_blank">中文信息学报</a>的其它文章</h3>
<ul><li><a href="/news/2015/0421/16156169.html" title="基于层叠CRF模型的词结构分析">基于层叠CRF模型的词结构分析</a></li><li><a href="/news/2015/0421/16156314.html" title="基于评论质量的多文档文本情感摘要">基于评论质量的多文档文本情感摘要</a></li><li><a href="/news/2015/0421/16156411.html" title="基于微博的情感倾向性分析方法研究">基于微博的情感倾向性分析方法研究</a></li><li><a href="/news/2015/0421/16156610.html" title="基于全局变量CRFs模型的微博情感对象识别方法">基于全局变量CRFs模型的微博情感对象识别方法</a></li><li><a href="/news/2015/0421/16157117.html" title="基于多层次语言特征的弱监督评论倾向性分析">基于多层次语言特征的弱监督评论倾向性分析</a></li><li><a href="/news/2015/0421/16157166.html" title="Zipf定律与网络信息计量学">Zipf定律与网络信息计量学</a></li></ul></div></div>
<div class="m_footer"></div>
<script>
if ('serviceWorker' in navigator) {
window.onload = function () {
navigator.serviceWorker.register('/sw.js');
};
}
</script>
<script type="text/javascript" src="https://s1.pstatp.com/cdn/expire-1-M/jquery/3.4.0/jquery.min.js"></script>
<script type="text/javascript" src="https://s2.pstatp.com/cdn/expire-1-M/Swiper/4.5.0/js/swiper.min.js"></script>
<script type="text/javascript" src="https://s1.pstatp.com/cdn/expire-1-M/jquery.lazyload/1.9.1/jquery.lazyload.js"></script>
<script type="text/javascript">
document.write('<script src="https://img.fx361.cc/js/m.index_cc.js"><\/script>');
</script>
</section>
</body>
</html>