基于全局变量CRFs模型的微博情感对象识别方法
2015-04-21郝志峰杜慎芝蔡瑞初
郝志峰,杜慎芝, 蔡瑞初,温 雯
(广东工业大学 计算机学院,广东 广州 510006)
基于全局变量CRFs模型的微博情感对象识别方法
郝志峰,杜慎芝, 蔡瑞初,温 雯
(广东工业大学 计算机学院,广东 广州 510006)
微博行文具有较大的自由性,其中情感对象识别是一个困难的问题,尤其是情感对象未显性出现情况下的情感对象识别,暂未发现有效解决方法。该文针对这一难题,结合中文微博的特点,提出了一种改进的条件随机场的模型。该模型把情感对象识别看作一个序列标记问题,通过在传统的CRF序列标记模型上增加情感对象的全局节点,有效地结合上下文信息、句法依赖以及情感词典,从而可以识别出微博中的情感对象。该方法的优势在于能够应用于情感对象未显性出现的情况。实验结果表明该方法比现有方法能更有效地识别出微博中的情感对象。
条件随机场;微博;情感对象识别;信息抽取;情感分析
1 引言
近年来,随着社交网络的高速发展,微博作为一种新的媒介承载了海量的互联网信息,如何有效地对微博信息进行观点挖掘与情感分析具有重要意义。 近年来国内外已有许多情感表达和情感对象方面的研究,但是他们大多是针对产品评论信息或者新闻信息进行分析。与传统的文本信息不同,微博字数限制和网络行文的自由性,使得其含有大量缩略的表达,以及中英混用、错别字、特殊符号(如表情符号等)等各类非规范中文表达,这些因素增加了情感分析的难度。目前国外已经有一些学者针对Twitter等[1-2]信息进行情感分析方面的研究,如Twitter Sentiment*http://twittersentiment.appspot.com/,也取得了不错的效果。然而,由于国内的情感分析和观点挖掘起步较晚以及中英文的差异性,准确识别出情感对象是困难的。
本文针对中文微博文本内容提出了一种情感对象的识别方法,把情感对象抽取看成一个词级别的序列标记问题,即微博文本内容为需要进行标记的序列,通过对序列中不同位置的词标记不同的标签,达到识别情感对象的目的。为了更好地理解微博情感对象的抽取过程,通过一个例子来说明其工作过程。例如,现有一条微博“太开心了!今天买了个新手机,它的屏幕非常清晰,但是电池不太耐用!”,对之进行分析可以看出:
(1) “太开心了!”句中有一个明显带有情感倾向的词“开心”和修饰的程度副词“太”,该句是带有正向的情感倾向的,但是情感作用的对象却不在微博文本内容中,而是作用于发表该微博的作者“我”。 微博中存在大量这种博客主在网上进行个人情感表达的信息。
(2) “今天买了个新手机”是陈述一个事实,因此不带有情感倾向。
(3) “它的屏幕非常清晰”是带有正向情感倾向的表达,对象在文本中为“屏幕”,更粗粒度也可以是“它的屏幕”。
(4) “但是电池不太耐用!”中有一负向情感对象“电池”。
在上例中,情感对象识别的目标是将上述的如“它的屏幕”、“电池”以及隐藏的“我”这类情感对象标记出来,并为情感对象标记情感倾向。从例子中还可以看出,情感对象可能在标记文本内容中,也可能不在文本中。由于隐性情感对象未直接显性地出现在文本内容中,因此要从文本内容中正确提取出这种情感对象是困难的,现有的研究和方法都不能解决这个问题。 在实际问题中除了上例中的这种情感对象是作者这个人的此类情况以外,微博中还包括一种常见的对象非显性情况就是话题评论。例如,微博中包含有“#”符号的Hashtag等主题(话题)信息或者承接上一句话题等,在这些情况下对带有主题背景的句子进行带有情感倾向的评价时,对象本身就可能不在文本中,而默认的情感对象就是该话题本身。本文针对该问题提出了一种有效的解决办法,对隐藏情感对象进行归纳和抽象化,使得抽取这类情感对象变得可行。同时提出了一种基于条件随机场模型进行微博情感对象识别的方法,该方法综合考虑了微博文本内容的上下文信息,以及其各个词之间的句法依赖关系进行统计建模,通过向常见的条件随机场模型中添加全局变量节点的方法来解决情感对象不在文本内容中的这种情况。
本文主要贡献如下:
(1) 提出了一种基于条件随机场模型的方法来进行微博情感对象识别,该方法对文本进行句法解析处理,充分利用了词、词性标注、情感词、句法依赖和表情符等多种有效特征,有效地提高了模型标注的性能。
(2) 提出了一种向传统的条件随机场模型中添加全局变量节点的方法,用于识别情感对象不在微博文本内容中的情况,这使得方法具有更好的适用性,能够有效地识别出微博中一些非显性蕴含的情感对象。
(3) 针对微博内容的特殊性,对之进行特殊处理,有效地提高数据集的质量。构建特殊的网络用语情感词典和用户分词词库,能够有效地提高特征的情感词判定和分词的准确度。
本文第2部分介绍相关工作,第3部分重点详细介绍情感对象抽取模型,第4节进行对比实验验证模型,并对实验结果进行分析,第5部分进行相关总结。
2 相关工作
早期的情感对象抽取的方法主要是针对产品评论信息而提出的,在此过程中,通常将情感对象看成是产品的特征信息,这些特征信息包括产品的组成部件和产品的属性等信息。Hu和Liu等人[3-4]最早提出的方法是:产品评论信息评论的是与产品相关的产品特征信息,而产品的特征信息是有限的,通常为名词(或名词性短语)并且频繁的在评论中出现,对于非频繁的特征信息则通过离情感词(通常为形容词)最近的名词(或名词性短语)来进行补充。在此基础之上,Popescu和Etzioni等人[5]提出了需要在预先已知给定一些产品属性信息情况下,通过网络搜索和计算名词(或名词性短语)与指定属性的PMI值来确定是否为一个产品的特征。但该工作需要依赖Web或其他类似语料库搜索来保证其足够的覆盖范围。Scaffidi等[6]则认为在产品特征抽取过程中,产品评论信息中产品特征比在一般语料中更加频繁出现,该方法在较小的语料集下则不一定可靠。
Kobayashi等人[7]则针对博客中写的产品评论提出了不同的方法,通过利用模式挖掘抽取的句法模式,对之抽取情感对象和极性对。与该方法不同的是本文利用的是句法依赖树而不是句法模式,因此不仅要考虑情感词和情感对象之间的关系,还要考虑其他多种类型的依赖关系。
Stoyanov和Cardie等人[8]则把情感对象抽取看成一个主题指代确定问题,核心思想是把针对同一个对象的观点进行聚类,用来判断是否是针对相同的对象。而在本文中则是把情感对象识别看成一个序列标记问题。另外,Qiu和Liu等人[9]提出利用情感词和情感对象之间的句法依赖关系不断迭代来进行对象识别。这种方法则不能识别上文提到的情感对象不在文本中的情况。
以上几种方法针对的是产品评论的情感对象抽取,由于评论中有指定的产品信息和限定的领域,使得问题更加具体、清晰,因此抽取工作往往都能达到比较好的效果。但是在其他文本中,情感对象抽取效果并不佳。例如,在新闻中抽取情感对象,主要通过主观动词(认为、相信)来找。这主要在于这些文本中评论对象很杂,另外情感词也多样化。Ma和Wan[10]提出在中文新闻评论中抽取中心词作为情感对象。该方法对一句话只能抽取一个对象,因为没有考虑其情感,所以抽取的对象未必是情感对象。
情感对象抽取过程通常可以当成序列标记问题,条件随机场(CRF)由于有较好的序列标注效果使得其在情感对象抽取方面具有得天独厚的优势,目前国内的郑敏洁[11]和王荣洋[12]等人有对基于CRF的情感对象识别进行了研究。而在微博情感对象识别方面,文坤梅[13]和高磊[14]等人通过对微博文本内容进行句法依赖关系分析结合情感词典得到成对的<情感词,情感对象>关系,进行抽取情感对象。现有中文情感对象抽取的研究和方法,要么不能较好应用于微博这种特殊的文本,要么存在较大性能瓶颈,而面对对象不在文本中的情况尚未提出适用的解决办法。为了解决这些问题,本文提出了一种方法进行情感对象抽取,在第3节将对该方法进行详细介绍。
3 基于改进CRF模型的情感对象抽取方法
在本节中将详细介绍情感对象抽取方法的过程及其原理。该方法是基于条件随机场模型提出的,下面3.1节首先介绍一下条件随机场模型,3.2节介绍情感对象抽取模型及其推理和参数估计,在本节的最后介绍情感对象抽取模型用到的特征。
3.1 条件随机场模型
条件随机场(Conditional Random Fields,CRFs)是由Lafferty等人[15]于2001年提出来的概率无向图模型,主要用来进行序列标记和切分。CRFs被广泛的应用于文本处理,计算机视觉系统和生物信息学等领域[16],特别是在中文分词、词性标注、命名实体识别和信息抽取等自然语言处理领域都取得了不错的效果,目前已有一些利用条件随机场模型进行情感分析和情感对象识别方面的研究[11-12,16]。
传统的线性链条件随机场如图1所示,已知其观测值X={x1,x2,…,xn}为一个输入序列,序列第i个位置的元素为xi,总共包含n个元素,输出标记序列为Y={y1,y2,…,yn}同样包含n个元素且第i个位置的元素为yi表示对应位置的输入元素xi的输出标记标签。由上述可知,在通常的条件随机场模型中,输入元素的个数和输出元素的个数是相等的。
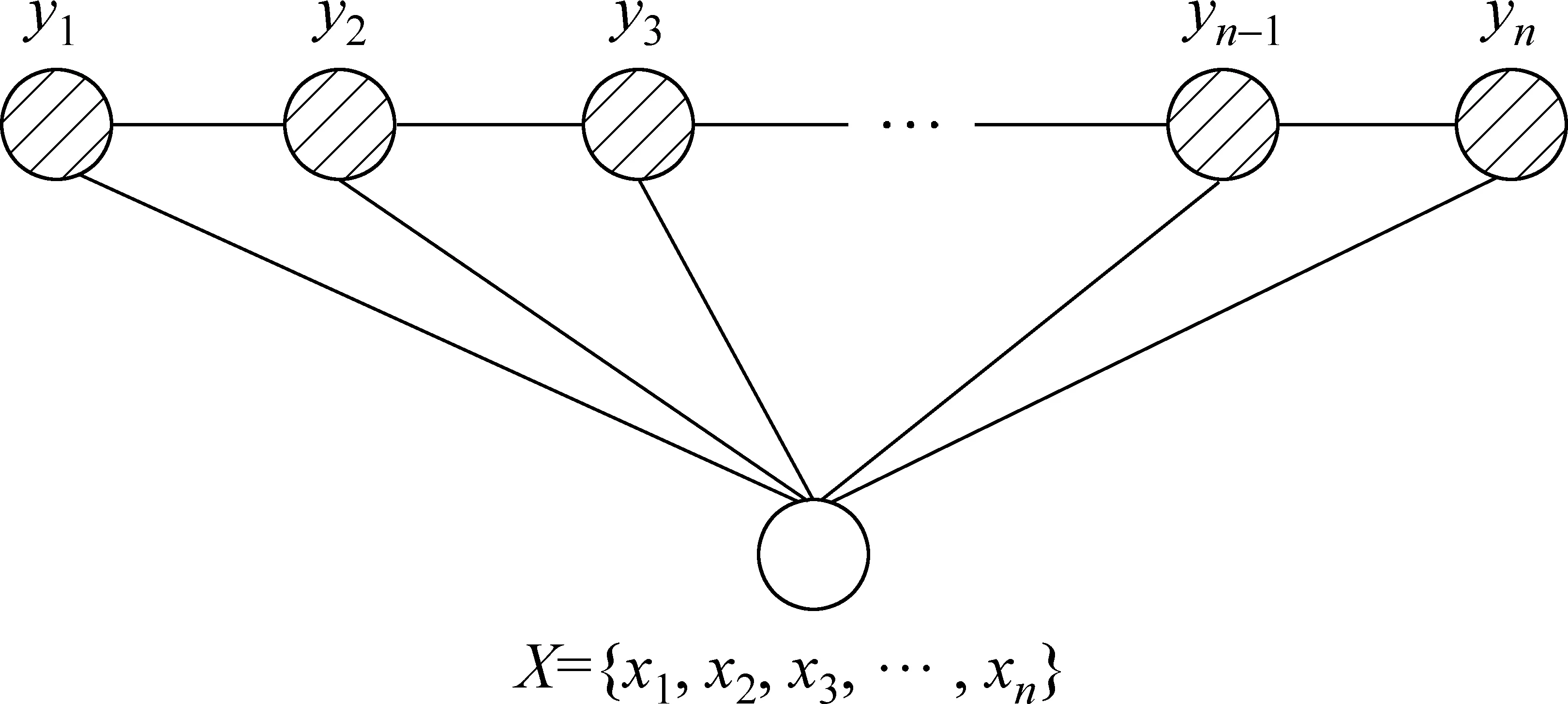
图1 线性链条件随机场
在概率模型进行情感对象抽取过程中,给定目标序列X取值为x的情况下,随机变量Y取值为y的条件概率式(1)所示。
(1)
(2)
(3)
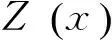
(4)
式(4)中Kn和Ke分别表示点特征集合和边特征集合。
3.2 针对情感对象抽取的改进CRF模型
如果情感对象全部都在输入的观测序列X中,那么就可以用条件随机场模型进行序列标记,从而抽取出情感对象。然而在进行情感对象抽取的过程中,发现情感对象不一定都在文本序列本身之中,上文中的微博例子中的“太开心了!”就属于这种情况。为了解决这个问题,通过观察微博发现其包含有这种隐藏的情感对象通常是有限的几种可能,本文认为通常两种就能概括:要么是微博主本人情感表达,这种情况可以认为对象为“我”;要么就是句子或者微博有个主题(话题)作为背景,类似于产品评论有一个确定的评价产品,这种情况对象即为“主题”。因此考虑到LDCRF(Latent-DynamicConditionalRandomField)模型[17-18],可以通过在线性链条件随机场的基础上添加两个全局节点g1和g2,用于标记情感对象为“主题”和“我”,该模型如图2所示,称之为LLCRF(Linear-chainLatent-DynamicConditionalRandomField)模型。

图2 添加两个全局节点后的线性链条件随机场(LLCRF)模型
LLCRF模型每个状态节点仅与它邻接的状态节点相连,yn和g2都与g1相连 ,则其求条件概率时有:
(5)
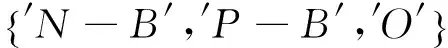
考虑到“我”和“主题”为整个句子的全局情感对象,因此链式连接的方式与句子末尾的词进行联系起来显然不是最好的选择。为了提高全局情感对象识别效果,提出另外一种改进模型(图3),把两个全局节点与句子中每个位置的词进行全连接,提升两个全局节点g1和g2跟整个句子之间的联系,从而达到提高模型隐藏情感对象的识别效果。为了方便,把该模型称之为GLCRF(GlobalLatent-DynamicConditionalRandomField)。
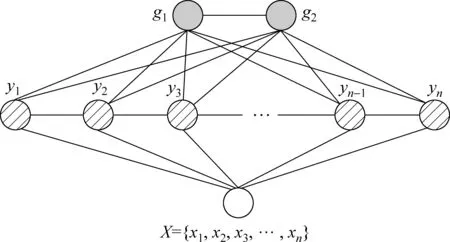
图3 改进的GLCRF模型
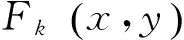
(6)
3.3 模型推理和参数估计
下面讨论在给定一个句子x情况下,如何得到该句子输出对应的情感对象标记标签s。在对句子进行分词之后,输出s序列由句子中每个词对应的情感对象标记标签yi以及g1和g2组成,即有s={y1,y2,…,yn,g1,g2},因此s可以进行如式(7)计算得到:
(7)
在计算各个节点的情感对象标记si的边际概率过程中,直接用枚举法进行计算将是困难的,因此采用了LoopyBP(LoopyBeliefPropagation)算法来进行计算。LoopyBP算法能够非常有效地对概率图模型中的边际概率进行计算,它主要是通过各个随机变量以及用因子(factors)连接变量的边之间的消息(beliefs)传递来求出边际概率(关于置信传播算法的详细描述请见文献[19])。
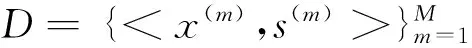
(8)
(9)
其中σ是一个给定的高斯先验值,Lλ的偏导形式如式(10)所示。
(10)
在已知目标函数和它的偏导,模型的参数λ可以通过L-BFGS拟牛顿法来进行计算。
3.4 特征选择
模型用到的主要有五类特征,包括基本词特征、词性标注特征、情感词特征、句法依赖特征和表情特征。
基本词特征:基本词特征采用了一个固定长度的滑动窗口作为特征。例如,有一个句子分词后序列为{“最近”,“天气”,“一直”,“很”,“阴沉”},当前位置为第二个位置,即基本词为“天气”,假如窗口size为3,则基本词特征为:{“最近”,“天气”,“一直”}。为了防止特征过多造成维度灾难,在此过程中需要过滤掉一些词。
词性标注特征:该特征与基本词特征类似,把词换成了词的词性标注,但是它的窗口被固定为3,即当前词的词性标注以及前后两个词的词性标注。
情感词特征:构建一个情感词典,对每个词的情感倾向进行标注,在情感词典中就对之标注为对应的情感倾向,不在情感词典中的词则默认不带有情感。pi表示序列第i个位置的词wi的情感倾向。由于网络微博用语的特殊性,在实验中没有直接采用常用的公开情感词典(HowNet中文情感词典*http://www.keenage.com/html/c_index.html和NTU情感词集*http://nlg18.csie.ntu.edu.tw:8080/opinion),而是手工建立了包含微博常用网络用语情感词的一个情感词典(如“给力”,“脑残”等)与公开情感词典相结合的情感词典。
句法词依赖特征:依赖特征包含三种情况,第一种,当前第i个位置的词依赖的词和被依赖的词及其词性;另一种为当前第i个位置的词与其依赖的词和被依赖的词之间的依赖关系;最后一种是当前第i个位置的词是否依赖情感词或被情感词依赖。

4 实验和结果分析
4.1 数据预处理
在数据预处理阶段,主要是对收集的微博进行处理,主要有以下几个步骤。
第一步,微博处理和分句。由于微博数据的随意性,为了方便后期断句和分词等处理需要进行一些必要的处理,微博中存在大量网络用语和缩写,因此需要对之进行转换;有些人习惯用空格或其他符号(如“~”)代替标点符号进行断句,因此也需要对之进行转换;还有一些对实验评估无用的链接(如图片链接等)和特殊字符串需要剔除掉。在微博中常常包含有带“#”符号的话题和带“@”符号的联系人也进行了处理,把微博头和尾出现的话题和联系人直接删除,在微博句子中的则只删除“#”和“@”符号。每条微博为一条文本数据,它通常包含一个或几个句子以及一些表情符号,而模型情感对象抽取是在句子级别上进行序列标记的,因此需要对之进行分句处理,这样做有助于提高分词和语法解析的效率。表情为一种带有强烈情感表达的方式,因此也需要把它提取出来,便于后期的特征提取过程。
第二步,分词。在进行情感对象抽取的过程中,标记序列是一个由若干个词和标点符号组成的序列。因此需要预先对句子进行分词处理。在实验中用到了斯坦福大学发布的自然语言处理工具*http://nlp.stanford.edu/index.shtml,其中用StanfordWordSegmenter*http://nlp.stanford.edu/software/segmenter.shtml分析工具来进行句子分词处理。
第三步,词性标注和句法解析。在情感对象抽取模型中用到了多种特征,其中包括有词性标注特征和词依赖特征,因此需要对句子中各个词语进行词性标注和句法解析才能得到。在此过程中用到了StanfordParser*http://nlp.stanford.edu/software/lex-parser.shtml句法解析工具来进行处理。该工具能够对分词后的句子进行词性标注,并进行句法解析得到词之间的依赖关系。针对微博的特殊性,分词过程中有添加一个用户词典来提升分词的效果,该词典收集了一些常用网络用语(如“抓狂”、“围观”等)。
第四步,标注。手工对每个词进行标注,实验用到的都是有监督学习,因此需要对实验数据进行标注才能进行实验。
第五步,数据规范化。将第四步处理得到的数据转化为各个模型软件工具包或程序需要的规范化数据,以便进行实验。
4.2 不同模型对比实验及结果分析
为了避免过拟合现象发生,实验结果均采用五折交叉验证进行实验验证。实验数据包括两部分: 手工收集数据集和NLP&CC2012评测数据集,数据详情如表1所示。手工收集数据全部来自新浪微博,通过新浪开放API随机爬取的真实微博数据,然后手工筛选和标注的。手工收集数据集中标注有情感对象1 264个,其中隐性情感对象约395个,全局隐形情感对象中“我”为193个,“主题”为147个。在NLP&CC2012评测数据集中,454个隐性情感对象包含对象“我”37个以及对象“主题”417个。
为了验证模型的有效性,实验过程中采用了朴素贝叶斯(NaïveBayes,NB)、支持向量机(SVM)和链式条件随机场(LLCRF)以及其改进的全局变量条件随机场(GLCRF)模型进行对比,四种模型均采用前文所述全部特征,并对表1中的实验数据集进行五折交叉验证实验。实验采用的GRMM*http://mallet.cs.umass.edu/grmm/是一个实现了CRF等概率图模型的软件工具包,被大量地用于科研领域。支持向量机(SVM)模型部分的实验是利用libsvm*http://www.csie.ntu.edu.tw/~cjlin/libsvm/软件工具包来进行的。实验环境为: 2.0G双核CPU,8G内存,64位Linux操作系统。
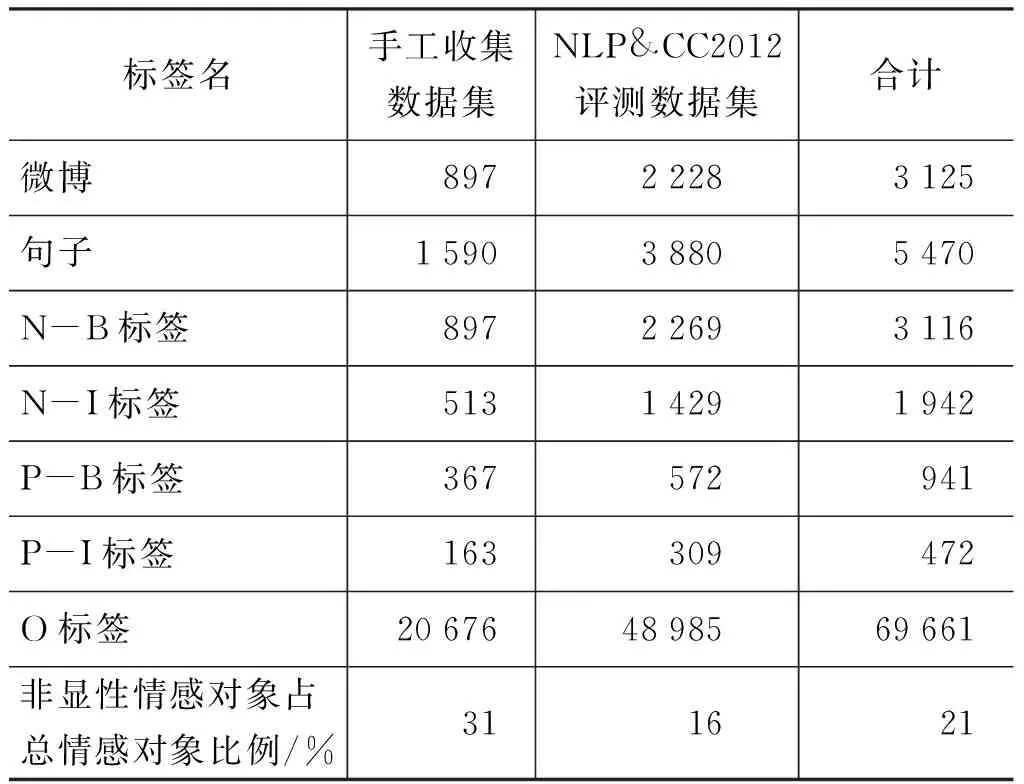
表1 实验数据集的详细情况
由于模型本身的复杂性以及引入了较多的特征,LLCRF和GLCRF模型的训练过程比较费时,具体消耗时间根据训练数据集的大小不同有所变化(本文实验环境进行一次五折交叉验证一般需花费数十分钟),但是模型的标注过程比较迅速。同时实验过程还发现,引入的各种特征、各种词典以及分词和句法解析过程均需消耗较多的内存(本文实验过程中峰值期需要消耗6G以上的内存空间)。
实验采用Precision值和Recall值的综合评价指标F1值对实验结果进行评价。实验结果如图4所示,其中图4(a)表示手工收集数据集实验结果,图4(b)表示NLP&CC2012评测数据集实验结果,图4(c)表示手工收集数据集加NLP&CC2012评测数据集实验结果。从曲线图4(a)可以看出, LLCRF和GLCRF模型评测结果在N-B和P-B这两个标签已经体现出了优势,但是其他标签相对于SVM模型没有表现出明显优势,这可能是由于手工收集数据集规模不够造成,随着数据集的增大,LLCRF和GLCRF的优势会越来越明显。O标签在几个模型中的F1值表现都比较好,评价结果都在0.9以上,而主要目标是提取出其他四种情感对象标签,因此非情感对象标签O的参考意义不大。在图4(b)和图4(c)中均可以看出LLCRF和GLCRF在N-B、N-I、P-B和P-I这四种情感对象标记标签上F1值明显优于SVM和NB。综合三个实验结果NB表现最差,SVM模型次之,LLCRF和GLCRF模型表现较好,能够比较有效地标记出微博中的情感对象。
图4 不同数据集的F1值结果曲线图
另外注意到图4的三个图中, GLCRF模型在N-B和P-B标签这两个标签上的表现均不同程度优于LLCRF模型,这是由于“我”和“主题”在表现为隐性全局情感对象时标记为N-B(负情感对象)或者P-B(正情感对象)这两种标签,GLCRF模型改进的实际效果就是体现在N-B和P-B标签上。为了进一步验证GLCRF模型对非显性情感对象识别提升效果,我们进行了另一组实验,统计了非显性情感对象识别结果(表2)。从实验结果数据可以看出,仅在NLP&CC2012评测数据集中“我”表现为情感对象时识别率有所降低,主要原因可能是由于评测数据集均为带有hashtag的主题微博,而这种“我”情感对象所占比例太少(仅有37个)造成。而在其他情况下,非显性情感对象识别率都有不同程度地提升,这说明了从LLCRF模型到GLCRF模型的改进,对隐性情感对象“我”和“主题”的识别具有一定提升效果,模型改进设计恰好是出于这一点考虑。因此,只要数据中包含有一定比例的非显性情感对象,通过该方式提升识别率具有实际意义。
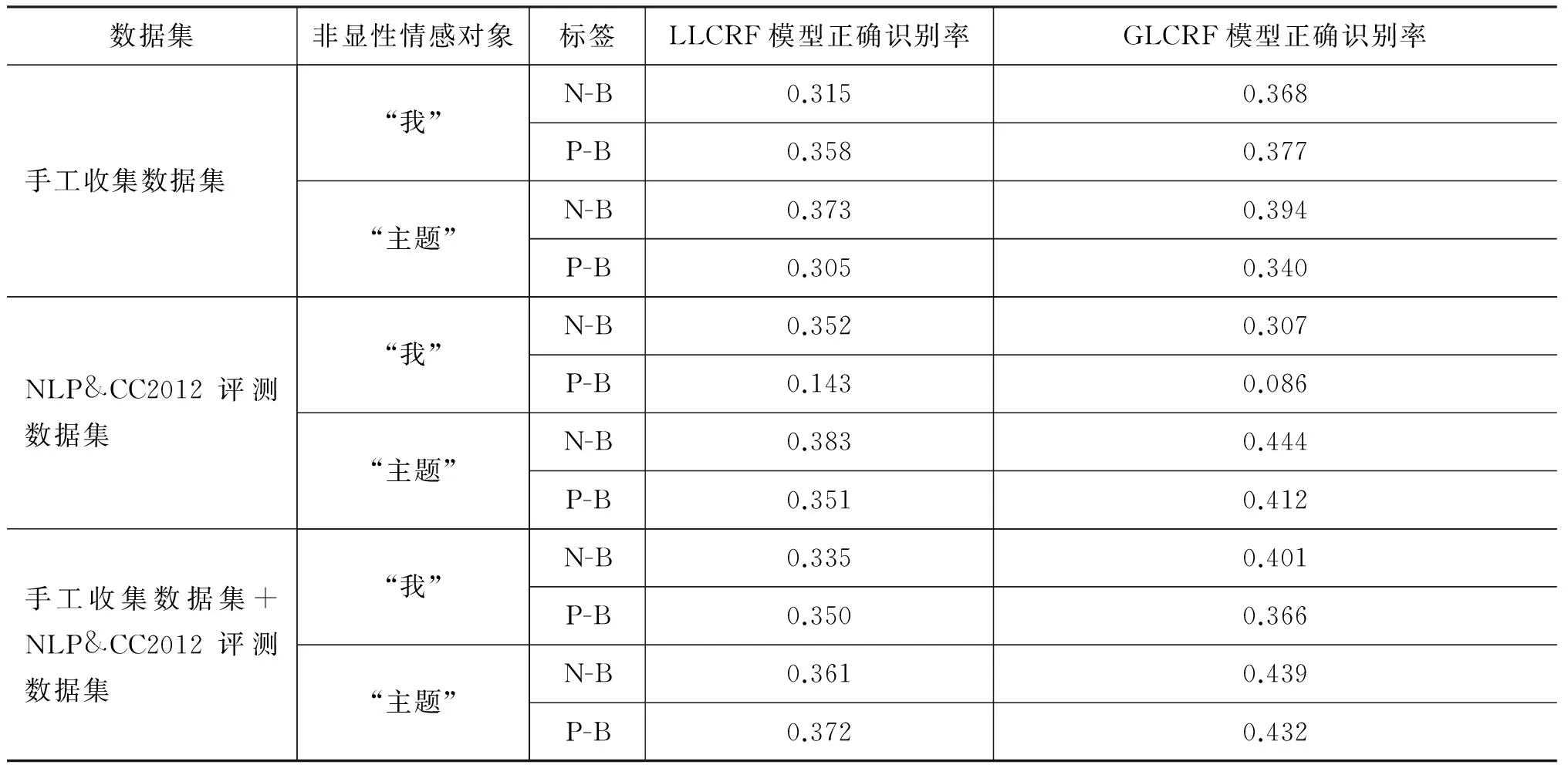
表2 非显性情感对象识别结果
4.3 同现有同类研究实验结果对比
针对非显性地全局情感对象尚未发现类似的研究和评测,为了更好地评测模型性能,将模型与NLP&CC2012*http://tcci.ccf.org.cn/conference/2012/index.html评测结果进行对比。第一届自然语言处理与中文计算会议(NLP&CC2012)是由中国计算机学会(CCF)主办,其评测任务中包含有一个情感对象抽取的任务,并提供了公开评测数据集。在实验过程中由于本文中创新性地引入了全局情感对象,而评测中并不包含这类情感对象,因此需要在原公开数据集上额外标记了全局情感对象。为了使本文中的模型同NLP&CC2012评测结果具有可比性,在此实验过程中采用与评测任务参赛队伍一样的训练集和测试集进行实验。对比实验取宽松评价指标宏平均值进行比较,在宽松评价中,评价指标通过提交的结果与标准标注结果之间的覆盖率计算(详情参见NLP&CC2012),值越高效果越好。
将本文中用到的四种有效的情感对象标签汇总计算与标准标注结果之间的覆盖率同NLP&CC2012评测结果中的宽松评价指标宏平均值提交结果进行对比,结果如图5所示,从图中可以明显看出本文提出的LLCRF和GLCRF模型各项评测均大幅度优于NLP&CC2012评测的平均结果,在精确度(precision)上也明显优于NLP&CC2012的最好结果,最后的F1综合评测也达到了与NLP&CC2012的两个最好结果Best1和Best2相当的性能。实验结果表明模型具有较好的性能,由于本文中的模型用于解决更复杂的问题,更多情感对象引入导致了recall值有所下降。
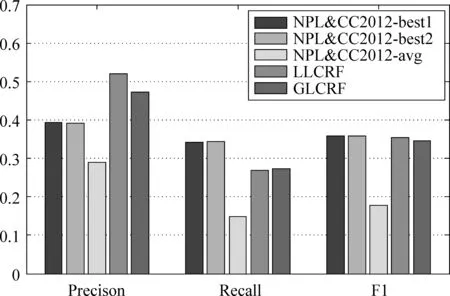
图5 同NPL&CC2012评测结果对比
综上所述,本文提出的基于CRF的模型相比于其他两种模型具有一定的优势,能够较好地对情感对象进行提取。当存在大量的情感对象不在文本内容本身中这种情况时,LLCRF到GLCRF模型的改进是有意义的,反之则是有限的。尽管从实验结果数值上看,微博情感对象的抽取性能离实用还有一定的距离,但是相比于同类方法具有一定的优势,能够解决更复杂的问题。
5 总结
本文提出了一种基于条件随机场的情感对象识别模型,能够在给定微博这种表达非常自由的文本信息下,不进行主题背景设定,从微博等文本信息中抽取出情感对象以及作用在该情感对象上的情感倾向,特别是该模型能够有效识别出情感对象没有显性出现在文本信息中的情况。实验对比证明该方法在实际表现中具有较好的效果,相比其他模型具有一定的优势。
[1] Jiang L, Yu M, Zhou M, et al. Target-dependent Twitter Sentiment Classification[C]//Proceedings of ACL. 2011: 151-160.
[2] Barbosa L, Feng J. Robust sentiment detection on twitter from biased and noisy data[C]//Proceedings of the 23rd International Conference on Computational Linguistics: Posters. Association for Computational Linguistics, 2010: 36-44.
[3] Hu M, Liu B. Mining and summarizing customer reviews[C]//Proceedings of the 10th ACM SIGKDD International Conference on Knowledge Discovery and Data mining. ACM, 2004: 168-177.
[4] Hu M, Liu B. Mining opinion features in customer reviews[C]//Proceedings of AAAI. 2004, 4: 755-760.
[5] Popescu A M, Etzioni O. Extracting product features and opinions from reviews[M]//Natural language processing and text mining. Springer London, 2007: 9-28.
[6] Scaffidi C, Bierhoff K, Chang E, et al. Red Opal: product-feature scoring from reviews[C]//Proceedings of the 8th ACM Conference on Electronic Commerce. ACM, 2007: 182-191.
[7] Kobayashi N, Inui K, Matsumoto Y. Extracting Aspect-Evaluation and Aspect-Of Relations in Opinion Mining[C]//Proceedings of EMNLP-CoNLL. 2007: 1065-1074.
[8] Stoyanov V, Cardie C. Topic identification for fine-grained opinion analysis[C]//Proceedings of the 22nd International Conference on Computational Linguistics-Volume 1. Association for Computational Linguistics, 2008: 817-824.
[9] Qiu G, Liu B, Bu J, et al. Opinion word expansion and target extraction through double propagation[J]. Computational linguistics, 2011, 37(1): 9-27.
[10] Ma T, Wan X. Opinion target extraction in Chinese news comments[C]//Proceedings of the 23rd International Conference on Computational Linguistics: Posters. Association for Computational Linguistics, 2010: 782-790.
[11] 王荣洋, 鞠久朋, 李寿山, 等. 基于 CRFs 的评价对象抽取特征研究[J]. 中文信息学报, 2012, 26(2): 56-61.
[12] 郑敏洁, 雷志城, 廖祥文, 等. 基于层叠 CRFs 的中文句子评价对象抽取[J]. 中文信息学报, 2013, 27(3): 69-76.
[13] 高磊,李斌,戴新宇等.基于依存分析和褒义指向的微博情感队形抽取方法[C]//自然语言处理与中文计算会议(NLP&CC).北京:2012.
[14] 文坤梅,徐帅.基于句法依存关系的微博情感分析方法[C]//自然语言处理与中文计算会议(NLP&CC).北京:2012.
[15] Lafferty J, McCallum A, Pereira F C N. Conditional random fields: probabilistic models for segmenting and labeling sequence data[C]//Proceedings of the 18th International Conference on Machine Learning(ICML-2001). Morgan Kaufman. 2001.
[16] Sutton C, McCallum A. An introduction to conditional random fields[J]. Machine Learning, 2011, 4(4): 267-373.
[17] Nakagawa T, Inui K, Kurohashi S. Dependency tree-based sentiment classification using CRFs with hidden variables[C]//Proceedings of the 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics. Association for Computational Linguistics, 2010: 786-794.
[18] Morency L P, Quattoni A, Darrell T. Latent-dynamic discriminative models for continuous gesture recognition[C]//Proceedings of the Computer Vision and Pattern Recognition, IEEE Conference on. IEEE, 2007: 1-8.
[19] Murphy K P, Weiss Y, Jordan M I. Loopy belief propagation for approximate inference: An empirical study[C]//Proceedings of the Fifteenth Conference on Uncertainty in Artificial Intelligence. Morgan Kaufmann Publishers Inc., 1999: 467-475.
Sentiment Target Extraction Based on CRFs Global Variables for Chinese Micro-blog
HAO Zhifeng, DU Shenzhi, CAI Ruichu, WEN Wen
(Department of Computers, Guangdong University of Technology, Guangzhou, Guangdong 510006, China)
Owing to informal words and expressions widely used in micro-blogs, target recognition for the sentiment analysis of microblogs is difficult, especially when the targets are not clearly mentioned. An improved conditional random fields model is proposed to deal with this issue, treating sentiment target extraction as a sequence-labeling problem. Through adding global nodes, the contextual information, syntactic rules and opinion lexicon are considered in the targets extraction. The major contribution of this method is that it can be applied to the texts in which the targets are mentioned in the sequence. Experimental results on the Sina microblog data demonstrate that this method outperforms the state-of-art methods.
CRFs; microblog; sentiment target; information extraction; sentiment analysis

郝志峰(1968—),博士,教授,博士生导师,主要研究领域为机器学习,仿生算法,生物信息学。E-mail:zfhao@gdut.edu.cn杜慎芝(1988—),硕士,主要研究领域为机器学习,自然语言处理。E-mail:dushenzhi@qq.com蔡瑞初(1983—),博士,副教授,主要研究领域为机器学习,数据挖掘。E-mail:cairuichu@gmail.com
1003-0077(2015)04-0050-09
2013-08-22 定稿日期: 2013-12-02
国家自然科学基金(61100148,61202269);广东省自然科学基金(S2011040004804);广东省科技计划项目(2010B050400011)
TP391
A
