基于微博的情感倾向性分析方法研究
2015-04-21李思雨阮冬茹刘邵博周二亮乔世权
高 凯,李思雨,阮冬茹,刘邵博,周二亮,乔世权
(河北科技大学 信息科学与工程学院,河北 石家庄 050018)
基于微博的情感倾向性分析方法研究
高 凯,李思雨,阮冬茹,刘邵博,周二亮,乔世权
(河北科技大学 信息科学与工程学院,河北 石家庄 050018)
随着微博等新型社会网络媒体的发展,人们在网络上传播着对各类话题的情感,社会网络也因此成为了挖掘社情民意的有效平台。传统文本分析算法难以适应篇幅短小、内容琐碎且富含情感特征的微博等短文本挖掘的需要。该文提出基于情感单元和评价对象分析的微博情感倾向性分析方法,通过基于词性共现概率计算的情感单元和情感评价对象抽取,计算情感单元的情感度,建立博主个性化及情感倾向性分析模型,完成情感倾向性分析。实验结果及分析验证了上述算法的有效性。
社会网络;短文本挖掘;情感单元;评价对象
1 引言
近年来,微博等社会网络新媒体发展迅速。由于在博文中蕴含着潜在的舆情价值,因此需要有效的处理机制来获取用户观点并分析其情感倾向性,对基于微博的文本情感倾向性方法进行研究,是必要的。选择微博作为研究数据集是出于如下考虑: 首先,博文内容短小,口语化、内容碎片化等特点明显,常规的文本挖掘算法常难以发挥有效作用;其次,微博用户倾向于发布自己当前感受等主观性信息,博文可能富含情感因素;最后,微博传达着社会舆情,通过对博文的深度分析,可对相关部门了解社情民意提供帮助。
目前,人工智能领域中的心理状态与认知分析主流方法多是采用有监督学习方法分析情感并借助语言和心理学所发现出的规则完成相应处理,所处理的文本多是电子邮件、新闻或文学作品等较规范的文本。将微博文本中蕴含的情感与自然语言处理、文本挖掘中所涉及到的方法结合起来进行的研究较少,且相关工作中存在的主要问题有: 单纯基于规则的方法需要领域专家定义大量的规则,代价较高,在对情感倾向性分析过程中有局限性;已有的情感分析多是将对评价词语的识别作为分析基础,并基于评价词语完成相关分析(如采用基于情感句打分的方法和基于有指导的分类方法等),但只考虑评价词语的作用常常是不够的,因为出现在句中的评价词语并不一定总能表现出一定的情感倾向性。
本文提出一种针对评价类博文中情感单元的抽取方法,通过基于词性共现概率的情感单元和情感评价对象抽取,利用正态分布规律对情感词权重进行计算,分析情感单元的情感度;通过博主个性化分析,完成针对博主的情感倾向性分析。研究成果对呈短小、碎片、不规范、富含情感特征的社会网络文本挖掘有重要意义。
2 相关工作
由于立场、观点等的不同,人们对生活中各种事件所持态度和情感倾向性存在差异,这种差异尤其体现在社会网络等反映草根观点的社会网络媒体上。情感倾向性分析对说话人态度进行分析,并识别出其情感倾向。利用它,便于分析热点事件背后的舆情,可为企业、政府等机构提供重要的决策参考依据。相关工作中,文献[1]在针对Twitter的文本进行情感分析后,提出它可作为社会投票调查的一种替代方法。而对微博语言分析主要指面向事实的博文挖掘,包括主题抽取与情感评价、热点话题探测、共同兴趣挖掘等。在主题抽取与情感评价方面,文献[2]提出一种基于句法路径的情感单元自动识别方法;在热点话题探测方面,文献[3]给出在社区网络中基于用户讨论话题内容和链接分析的统计模型。按照技术递进关系,文献[4]将文本情感分析归纳为三项递进的研究任务: 情感信息抽取、情感信息分类、情感信息检索与归纳。在情感信息抽取方面,构建情感词典是一项基础性工作。相关工作中,文献[5]用两种资源对情感词典进行扩展,建立了具有倾向程度的情感词典;基于统计和上下文信息来发掘评价词和评价对象的方法也在一些文献中提到[6-7],其中,文献[6]提出语义词典构建及扩展方法,通过对情感词汇与所对应的评价主题关系的分析,给出一种基于Propagation思想的情感词扩展方法,文献[7]讨论了针对不同应用域的基于条件随机场CRF的评价对象抽取方法;文献[8]给出基于双语信息和标签传播算法的中文情感词典构建方法,并借助机器翻译,结合双语言资源的约束信息,利用标签传播算法计算词语的情感信息,但它缺乏对语料中存在的情感极性反转情况(如否定、转折等)的分析;文献[9]给出评价对象及其倾向性的抽取和判别方法,在LTP平台对语料处理结果的基础上,利用SBV极性传递法,引入指代消解、ATT链算法和互信息法,对语料中的评价对象进行抽取,并在对极性词进行倾向性判别时考虑不同类型的句子以及副词、连词对极性的影响,但基于浅层句法分析的方法对句法分析结果的依赖度较大。在情感信息分类方面,文献[10]提出SentiRank方法;文献[11]认为在判断文档的情感极性时,不同句子具有不同的情感贡献度。限于篇幅,本文不对情感信息检索与归纳的相关工作进行介绍。
在对社会网络情感倾向性分析的主要方法中,一类是基于情感知识的方法,另一类是基于机器学习的方法。基于情感知识的方法将表示情感的词语分为正、负情感词,再与规则相结合,以便决定句子情感倾向,文献[12]将抽取的每个句子的情感词表及依存关系进行情感倾向计算,评价情感句子和整个博文的情感倾向。基于机器学习的方法是选择文本中的一些特征标注训练集和测试集,通过机器学习算法训练得到分析结果,相关工作中,文献[13]将训练集中的文本分别标记情感倾向和主题类别,根据不同情感和主题的语言表达方式分别估计情感和主题语言模型,评估测试文本与模型之间的相似性并确定文本主题和情感倾向;文献[14]提出一种基于浅层篇章结构的评论文倾向性分析方法,采用基于n元词语匹配的方法识别主题,通过对比与主题的语义相似度大小和进行主客观分类抽取出候选主题情感句,计算其中相似度最高的若干个句子的倾向性,将其平均值作为评论文的整体倾向性,但没有针对非评论文文体的处理效果分析;文献[15]提出一种基于动态随机特征子空间的半监督学习方法,通过动态生成多个随机特征子空间,基于协同训练方法,在每个特征子空间中挑选置信度高的未标注样本,并使用这些挑选出的样本更新训练模型;文献[16-17]提出依据粉丝或@、Follow等标记,基于SVM完成微博信息分类研究,并基于正文和评论之间的关系等进行微博情感分析。
3 算法设计与系统实现
3.1 概述
算法流程如图1所示。在进行情感分析与处理前,需要对微博文本进行预处理,包括基于Double-Trie Tree的词法分析、词义消歧、未登录词处理等。由于中文自然语言的极端复杂性以及博文中网友自造词的普遍使用,词义消歧处理是必要的,通过基于Bi-Gram模型,通过计算最短路径的Viterbi算法,得到切词产生的前后两个词条间的前后依赖得分,其绝对值越大,说明两个词条的前后关系越密切,即这两个词条应切分出来。对未登录词的处理是采用基于统计和基于规则并用的方法,对博文中切分出来的词条集合进行基于距离的词条间共现概率统计,当两个或多个词条相邻共现概率相同或达到指定阈值时,认为它们可合并为一个新词,例如:“我是歌手节目不错。”正常可分为“我/是/歌手/节目/不错”,但当“我是歌手”共现频率相同或达到指定阈值时,则将其视为一个新词被识别出来,即切分成“我是歌手/节目/不错”;同时,采用基于规则方法(如词性关联关系规则、连续数值串规则、连续字母串规则、数值字母符号混合规则等),可将诸如“50”、“3.5%”、“百分之八十”、“x5”、“2014年3月8日”、“4月9日”等词条正确切分出来,从而对达到未登录词识别的目的。采用基于距离的词条间共现概率统计方法发现未登录词,即迭代统计各词条间的共现概率及其距离值,当两者满足指定的阈值条件时,则合并词条。

图1 算法主要流程
3.2 基于词性共现概率的情感单元抽取方法
基于词性共现概率的情感单元抽取,是在情感词典的帮助下,找出博文中出现的情感词并确定情感单元在句中位置,计算词性共现概率,判断其左右词汇是否易于与情感词结合构成情感单元。通过对情感句进行分词和词性标注,统计待处理语料中词汇的词性共现频数,具体步骤如算法1所示。

Algorithm1:基于词性共现概率的情感单元抽取BeginStep1 训练语料获得词性共现频率input:训练语料库;1)输入博文;2)分词,词性标注;3)根据情感词典进行情感词正负性标记;4)统计词性共现频率;Step2 根据词性共现频率抽取情感单元;input:情感句;1)分词,词性标注;2)情感词正负性标记;3)计算词汇在当前词性下为情感词的概率;分析词性共现概率;End
如在博文“这个宾馆的房间没有做出改进”中,“改进”是情感词,“没有做出改进”是情感单元,“房间”是情感评价对象。先对该句进行分词以便获得词汇列表,处理结果是:“这个/r 宾馆/n 的/uj房间/n 没有/v 做出/v 改进/v”。对该词汇列表进行情感词标记,处理结果是:“这个/r,宾馆/n,的/uj,房间/n,没有/v,做出/v,改进/v@”,其中@表示正向情感词。使用本文采用的情感语料库(详见后续试验数据说明),按算法1得词性共现概率结果是:“v=159278v@=8560 vv@=1324 vvv@=162 dvv@=391”。分别计算v@情感词在情感词为动词v出现下的概率(即a: = v@/v),计算vv@情感单元在情感词v@中出现下的概率(即b: = v v@/v@)。由于vv@向后结合没有词汇,故其概率c=0。比较a、b、c大小,以vv@作为情感单元并重新计算情感单元的b、c值,一直循环直到b、c值全部小于a值时停止,可得到情感单元“做出改进”。显见,此例中的实际情感单元应是“没有做出改进”。导致上述错误的原因是词汇“没有”在句子中既可作动词v又可作副词d来使用,如能将其标记为副词d,根据dvv@在已知条件下的概率,就能正确抽取情感单元,可见这种在句中具有改变情感正负性的词汇对于句子情感度的影响较大,不恰当的分词和词性标注(这几乎是不可避免的)可能会将其误标记为其他词性。本文针对这种情况的处理策略是在抽取情感单元结束后,如发现情感单元前的词汇是这种可改变情感正负性的词汇,就将其加入情感单元中,见公式2中影响因子β的使用。
3.3 基于词性共现概率的情感评价对象抽取方法
情感评价对象多是一些名词性短语,它们往往位于情感单元附近。通过情感单元位置向前或向后搜索名词,可初步确定情感评价对象位置。如果单纯以名词来断定哪个词汇是情感评价对象,情感评价对象的位置就可能是在情感单元的前或后,而对于在句子中存在多个名词及情感评价对象等不确定位置的情况,可通过词性共现概率来抽取情感评价对象,具体方法如算法2所示。

Algorithm2:基于词性共现概率的情感评价对象抽取BeginInput:情感句;1)执行Algorithm1算法,获得情感单元在句中位置信息及词性共现频数;2)抽取情感单元前最近名词与情感单元间词汇词性串(含名词和情感单元);3)抽取情感单元后最近名词与情感单元间词汇词性串(含名词和情感单元);4)分析上述结果,确定情感评价对象;End
下面给出基于上述算法抽取情感评价对象的过程。如针对博文“公司在美丽的郑州”的分词结果为:“公司/n 在/p 美丽/a 的/uj郑州/ns”。句中存在两个名词“公司”和“郑州”。究竟“公司”是“美丽”的?还是“郑州”是“美丽”的?通过对语料的词性共现概率分析可知,“美丽/a,的/uj,郑州/ns”的词性共现概率比“公司/n,在/p,美丽/a”的词性共现概率大。因此可获得正确的情感评价对象,并确定情感评价对象是“郑州”,而非“公司”。
由于中文自然语言的极端复杂性,应区分不同情感评价对象。如对博文“酒店房间有点小”以及“酒店房间的衣柜有点小”,这两句所表达的情感对象不一样——前句对“房间”表达了不满,而后句对房间的“衣柜”表达了不满。经统计发现,词汇“房间”的使用频数远高于“衣柜”的频数。对情感评价对象对情感倾向的影响度进行分析,统计语料中的名词频率,利用指数函数Y=ax, x∈(0,1)计算名词权重,再进行归一化处理。实验结果表明,随着a值变化,情感句的判别准确率发生相应改变,且正负情感句判定变化一致,可见情感评价对象对情感单元情感度确实存在影响(详见后文的实验结果与分析)。
3.4 情感单元的情感度及其计算
对于抽取出来的情感单元,要计算其情感词权重(即情感度)。对于不同的情感词,其权重是不一样的。统计发现,测试语料中具有极端正、负倾向的情感词的使用是较少的,而具有中庸倾向的情感词汇是出现频率较高的,可见情感度的分布基本满足正态分布规律。公式(1)中,x表示词汇的情感度,F(x)表示词汇出现的频率。对实验语料库中的情感词词频进行统计,计算情感词出现的频度并作为此情感词的y值,通过正态分布函数的逆函数计算出该情感词的x值(即该词情感度)。由于情感词分布不一定是标准正态分布,在建立计算模型时,分布的期望μ值一般为0,直接影响情感词分布稀疏与稠密程度的正态分布标准差σ值可通过实验来确定。
(1)
实际中,情感单元不仅存在正、负向情感词,也可能存在一些修饰词汇,这些词汇可能会加强、削弱甚至扭转情感的极性。对于这些本身不存在情感但却对情感表达有增强、削弱或扭转作用的词,可单独设置词表。当计算情感单元的情感度时,可对其进行一定的加权计算——即对情感有增强效果的词汇,定义其影响因子β>1;对情感有削弱作用的词汇,其影响因子0<β<1;对情感取扭转效果的词汇,其影响因子-1<β<0。当这样的副词有多个时,其总体影响因子为多个影响因子的加权代数式。情感度的形式化计算如式(2)所示,式中n为修饰词汇个数,x为情感词情感度,degree为情感单元情感度,f()为情感度函数。

(2)
3.5 情感倾向性分析
3.5.1 基于博文的情感倾向性分析
将博文表示为情感向量A(用抽取的情感评价对象数目作为A的维度,用其情感度作为A中相应维的值);计算情感向量A在设定向量B上的映射向量C,用C的正负情感倾向作为博文的情感倾向。该模型与传统文本分类算法中向量空间模型VSM的区别在于,传统VSM算法选择在文本中对文本内容具有代表性的词汇作为文本特征词,通过特定的特征权重计算方法计算出特征权重并将其作为维度权值,由此建立分析模型。具体地,抽取情感句中的情感评价对象的数目作为向量维度,利用情感词典抽取句中具有情感倾向的词汇为特征词,用基于词性共现概率计算的情感单元抽取算法抽取情感单元,计算情感单元的情感度,并将其作为模型中相应维度的权重。如对于博文“这个宾馆的环境不错,交通很便利,家具都很新,大床,大电视,就是卫生间有点小”,情感评价对象存在包含关系(即上层对象“宾馆”包含下层对象“家具”、“卫生间”等)。为此,建立情感向量,针对本例为A(a1,a2,a3,a4,a5,a6) (注:A(a1,a2,a3,a4,a5,a6)数值分别为此例中的情感单元“不错”、“便利”、“很新”、“大”、“大”、“有点小”的情感度权值),计算A在设定向量B上的映射向量C(C的方向为情感句的情感倾向)。本例情感向量是正值,其情感度越高,则所获得的对评价客体的评价就越高。当对客体“宾馆”的子客体的评价存在不同的评价态度时,可计算出该句对评价客体“宾馆”的总体情感态度。
首先需要对语料库进行分词与标注,以便将句子切分成带有词性标注的词汇,得到相应的统计信息(含词性共现、情感词词频、名词词频等);之后,通过分析完成情感单元抽取、情感评价对象抽取、计算情感单元的情感度等,系统处理流程如图2所示,主要包括情感词情感度计算、情感评价对象影响因子计算、情感单元抽取、情感单元情感度计算、情感评价对象抽取、情感句向量构建等六个部分(见图2中的模块)。其中,情感词情感度计算模块通过统计情感词词频,利用正态分布逆函数计算获得情感词汇的情感度;情感评价对象影响因子计算模块计算情感评价对象对情感的影响因子;情感单元抽取模块利用情感词词典统计词性共现频率,抽取情感句中的情感单元;情感单元情感度计算模块利用情感词情感度、情感评价对象影响因子和副词词典计算抽取到的情感单元的情感度;情感评价对象抽取模块利用词性共现和抽取到情感单元的位置抽取情感句中的情感评价对象;情感句向量构建模块利用抽取的情感评价对象和计算的情感单元情感度构建情感句向量。
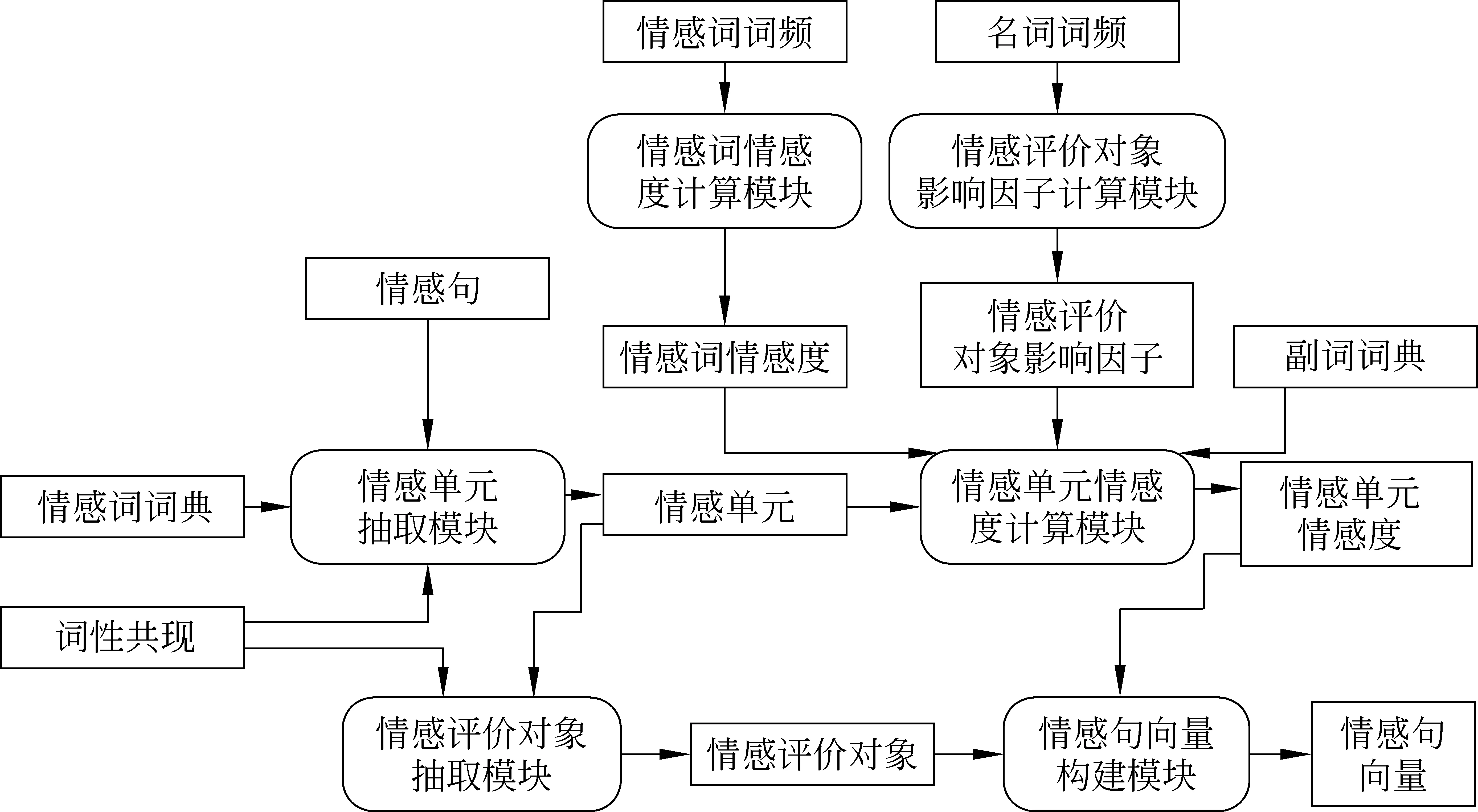
图2 系统处理流程
3.5.2 基于博主的情感倾向性分析
认知科学研究表明,人的相对稳定的情感特征不仅和外部事件的刺激有关,也和人的个性和历史情感态度相关。虽然可通过基于词性共现概率实现情感单元和情感评价对象抽取,计算情感单元的情感度,但中文较为复杂,单纯基于博文进行分析常常是不够的,因为同样的话出自不同人之口,其权威性也有很大差异。如果缺少对博主历史情感态度和个性化属性的分析,可能会对情感分析带来不利影响,而依据博主的个性与历史言论,可得出较合理的情感分析结论。从前期工作中统计的数字来看,一部分博主已完成了实名认证(且这个数字目前还在继续增长)。因此,对拥有背景和个体信息的博主进行个性化建模,从结合了博主个性化因素的多个维度去分析,是必要的。提出基于博主个性化建模分析的方法,刻画博主的个性化信息的主要维度是博主个性化特征向量V、博主权威度W、博主影响度F。
• 博主个性化特征向量V: 分析博主的微博标签和博主的历史博文。通过对其内容的主题词提取,形成个性化特征向量集合。
• 博主权威度W: 分析博主是否完成了实名认证、所在领域domain、学历情况等。其中,认证代表其身份的可信性;学历代表自身知识的广度和深度层次;所在领域代表自身所善长的方向,如存在行业领域domain,则将其作为衡量权威度的一个因子,即当博主个性化特征向量涉及其行业领域时,要进行相应的加权操作,以强化博主在该特征向量上的权威度,如不存在行业领域值,则将特征向量设定为经验阈值。设实名认证权重为经验参数wr,学历权重为经验参数we(其基值base=1),权威度计算方法如公式3所示。

(3)
• 博主影响度F: 计算博主影响度时,需要参考博主发布的博文、转发、评论等对其他网络用户的传播影响力。由于存在僵尸粉、水军等,故只从粉丝、关注等的某一方面去度量显然是不合理的。考虑从两个方面来综合度量: 一方面是粉丝数与关注数之比值,说明该博主的正反关系倍数R1;一方面为被转发数、点赞、收藏数、评论数的和与发博数之比值,说明该博主所发博文的真实受众的倍数R2。博主影响度F的测度公式见公式4。
(4)
4 实验结果与分析
4.1 基于博文的情感倾向性实验结果与分析
为验证相关算法性能,进行了相关实验,实验硬件环境为: CPU双核主频1.60GHz+2G内存+Window系统,训练语料库使用的是公开的10 000篇中文情感挖掘语料[18](其中7 000篇为正向语料,3 000篇为负向语料),测试语料有上述中文情感挖掘语料的6 000篇语料子集[18](其中3 000为正向语料,3 000为负向语料)。
4.1.1 参数确定
实验采用的词典中的词本身是无权重的。通过计算,在建立模型时为其赋予合理权重,之后再进行情感分析。使用的情感词的情感权重是通过正态分布逆函数计算出来的,其中正态分布期望μ=0,正态分布标准差σ通过实验确定;情感评价对象对情感度的影响因子是通过指数函数Y=ax计算获得的(a为情感评价对象属性权重影响因子,其值通过实验确定)。通过训练和测试,从结果中选择最优的情感权重,来确定最优的参数σ以及影响因子a。训练语料采用前述的10 000篇公开语料,测试语料采用前述的6 000篇语料子集,情感词典采用知网词典(含4 370个负向词以及4 566个正向词),实验结果如表1所示,其行表头表示在计算情感词情感度中不同标准差的正态分布,列表头为计算对象影响因子所采用的指数函数,表中数据为正向情感判定正确率和负向情感判定正确率(表中“|”前为正向情感判定正确率,“|”后为负向情感判定正确率)。随着对象影响因子指数函数Y=ax中的a取值从1升到3,正向情感判定和负向情感判定正确率都先增加后减少,在a=2的时候正确率最高,这表明情感评价对象确实对情感单元情感度有一定的影响;对情感词情感度的计算中,随着标准差的增加,负向情感判定正确率增大,正向情感判定正确率减小,二者表现不一致,这说明标准差越大,词汇情感度值分布越分散,对负向情感的判定越有利,反之词汇情感度分布越稠密,对正向情感的判定越有利。实验表明情感词权重计算标准差σ最优为1.2,情感评价对象影响因子计算中指数函数最优为Y=2x。
4.1.2 情感元素抽取
通过召回率和准确率对情感元素抽取结果进行评估。实验中采用的训练语料为上述中文情感挖掘10 000篇公开语料(正向7 000篇,负向3 000篇),测试语料为上述中文情感挖掘6 000篇语料子集(正向3 000篇,负向3 000篇)。情感词汇情感度计算时正态分布标准差σ=1.2,情感评价对象影响因子采用Y=2x,采用由对相关领域语料人工统计情感词获得的情感词典,对情感单元及情感对象属性进行抽取,专家对实验结果评测,结果如表2所示,可见提出的通过判断情感词前后词性共现概率的情感元素抽取算法具有一定可行性。

表1 情感词及权重对情感分类的影响

表2 抽取结果性能分析
表2中的情感单元的召回率和准确率比情感评价对象的相应指标高,是因为通过情感单元的位置来寻找情感对象并进行抽取,这样在寻找情感对象的过程中就会存在一定误差;情感单元和情感评价对象的召回率都大于准确率,说明在抽取过程中存在误将非情感对象或非情感单元当作情感对象或情感单元抽取的情况。为验证这个结论,对抽取结果进行分析,如存在博文:“酒店的软硬件设施不够完善”,其评价单元为“不够完善”,其中“不够”只是情感词“完善”的一个修饰词,但由于“不够”和“完善”这两个词都存在于情感词典中,系统错误地将其拆分为多个情感单元,导致情感单元的准确率下降。如何解决该问题,是我们下一步的研究内容。
4.1.3 情感判定性能指标分析
为了评价和分析情感判定情况,采用前述的由对相关领域6 000篇语料人工统计情感词获得的情感词典,训练语料为前述的10 000篇中文情感挖掘语料,测试语料为从训练语料中随机抽取200个评论语料(其中100句正向评价,100句负向评价),情感词权重计算标准差σ=1.2,情感对象影响因子计算函数为Y=2x,统计经情感分析后的召回率和准确率情况如表3所示。

表3 情感判定性能指标
4.1.4 情感分析结果评价
为了测试算法在其他公开微博评测语料上的准确性,验证其扩展性,采用中国计算机学会中文信息技术专业委员会发布的2012年CCF自然语言处理与中文计算会议上(NLP&CC 2012)的微博博主对自己所使用的ipad的评价测试语料[19]。表4是上述会议中编号1-16单位情感判定的评测结果,最后一行是本文提出方法对微博语料的测试结果,情感词权重计算标准差σ=1.2,情感对象计算影响因子函数Y=2x。采用的情感词典是从中国计算机学会自然语言处理与中文计算会议上相关微博语料中统计情感词获得的情感词典(含负向词汇57个,正向词汇85个)。
表4 NLP&CC2012中部分单位及本文基于博文的情感判定评测结果比较

单位编号准确率召回率F1值10.8310.574067920.8240.6140.70430.7610.6980.72840.7640.440.55950.7340.5680.6460.7820.5650.65670.7240.4030.51880.7180.3790.49690.8410.5070.633100.8330.4930.619.110.4260.4260.426120.8810.640.741130.8630.6260.726140.2580.0970.141150.2610.0990.143160.5590.5590.559本文基于博文分析的算法0.610.750.673
由于NLP&CC2012评测数据是未加任何修饰的真实微博语料,句式更加复杂,博文中的口语化内容较多,博文经常省略前文提到的内容或采用指代方式,且博文中也存在一些网络新词汇,所以使得分词及词性标注效果相应有所下降,从而对最终的情感判定效果产生一定程度的影响;另外,由于使用的词典词汇量小,而本算法受词典影响较大,词典中词汇越准确,最终的分析效果也会越好,说明本文算法有一定的可行性和实用价值。
4.1.5 存在的不足和下一步的研究计划
随着情感词典的不断完善,情感词的情感度越来越准,说明利用情感句中各属性及其情感权重建立模型的方法是可行的,但情感判定结果还有待进一步提高,原因有:1)某些情感词对不同的情感评价对象所表达的情感倾向有可能是相反的,如博文“酒店的性价比高,硬件设施比过去更加改善。满意”,以及博文“房间小,价格还高,以后再也不住这家酒店了”,两句中同时出现了情感词“高”,但表达的意思却截然相反;2)某些词本身不具有情感倾向,但当用来修饰特定对象时,可能会赋予一定的情感,反之亦然,如博文“房间叫餐好,方便,味道足,量足,价格平民”,这里“平民”本身不具情感倾向,但它却表达了一种肯定的正向倾向;又如“苹果的价太高了”句中用“高”来表达负向语气,但词典中“高”往往表示正向语气,由此可能产生语义偏差;而与此相反,某些词本身具有情感倾向,但当和其他词结合后却不再拥有情感倾向性,如博文“我在2月23日定了郑州大酒店的豪华单人间”,这里的“豪华”已没有了情感倾向;3)有些本身并不具有情感倾向的词在句中也可表达情感倾向,如博文“酒店在CBD中心,周围没什么店铺,不知道为什么卫生间没有电吹风”中并没有出现情感词,但博文却表达了对酒店的不满。如何处理上述问题,是下一步的研究内容。
4.2 基于博主个性化建模的情感倾向性实验结果与性能评价
4.2.1 测试数据集及实验结果
为验证基于博主个性化建模分析算法的效果,以采集的微博语料库为实验数据集。由于该语料中不同博文数据中有可能是同一博主发布的情况,故去掉重复博主,实际得到博主数量为6 545,其中有正向情感的博主3 135个,有负向情感的博主3 410个。抓取去重后博主的个人信息及其所发表的所有博文信息,共得到全部博主的个人信息6 545条,博文数据1 538 073条。提取博主数据的主题词的top-20作为该博主的特征词表示(即主题词抽取过程中,打分从高到低排序,取其排名前20的主题词)。抽取的数据源分为两部分,第一部分是用户的基本信息抽取,因其相对较简短且较有代表性,预设取其主题词的top-5;第二部分是用户的博文数据,其数据相对较多,取其主题词的top-15。示例结果如表5所示。从表中可得,其主题词提取结果基本符合人们对他们的定位。
针对该方法在不含博主个性化信息的测试集上的性能见表5。为公平起见,同样也采用中国计算机学会中文信息技术专业委员 会发 布的2012年CCF自然语言处理与中文计算会议上(NLP&CC 2012)的微博博主对自己所使用的ipad的评价测试语料[19]。由于评测语料没有提供博主个性化等背景信息,因此本文提出的基于博主个性化建模方法和上文基于博文分析方法的性能差异不大。也就是说,在没有博主个性化信息的情况下,该方法不能有效地发挥其作用。表6中评测数据出现差异的原因可能是由于在基于博主个性化分析的算法中,采用的博文预处理方法包括基于Double-Trie Tree的分词、词性标注、未登录词处理、数据清洗等;而在基于博文分析的算法中,预处理仅仅是完成了基本的数据清洗、正则匹配等。

表5 博主信息主题词提取示例
表6 基于博文的情感判定评测结果与基于博主个性化的分析结果比较

单位编号准确率召回率F1值基于博文分析的算法 0.610.750.673基于博主个性化分析的算法0.6440.7650.699
为此,在前述的包含博主个人信息(6 545条)和博文数据(1 538 073条)的测试集上,我们针对拥有个性化背景信息的微博大V的情感倾向性进行了分析。首先,请不同专家对待测试的博文的情感倾向性进行了人工标注;之后,采用基于博主个性化建模的情感倾向性分析方法,得出实验结果如表7所示(其中,人工标注统计结果是选择了不同专家人工标注的结果)。

表7 基于博主个性化的情感倾向性分析结果比较
4.2.2 存在的不足和下一步的研究计划
首先,本文提出的基于博主个性化建模的情感分析方法与某些人工标注结果是基本吻合的,这也说明应对结果进行置信度评估,通过设置正负倾向性的置信度阈值,对独立计算的情感倾向性进行极性纠正。如何确定博主总体情感倾向性概率分布、博文对应的上下文之间的情感倾向性概率分布、动态调整权重方法等,是下一步的研究计划。
其次,在不同的语境下,同样的词可能有不同的含义或情感色彩。而真实语境中少部分词汇的情感倾向会受到其修饰的情感对象的影响——有些词本身带有情感倾向,但与情感对象结合后,并没有表现出情感倾向;而有些词本身没有情感倾向,但与情感对象结合后却表现出了情感倾向;甚至还有的情感倾向不确定,与不同的情感对象结合会有不同的情感倾向。如何解决上述问题以及反讽、褒义贬用、贬义褒用等也是下一步的研究内容。对于反讽的识别,拟根据评论内容,计算该用户是否为广告用户、枪手等异常用户,计算包括该用户的相似用户群体对该评论对象的总体评价、该评论对象的总体评价等,以便做进一步的判断。
5 结论
本文给出基于情感单元和评价对象分析的短文本情感挖掘与分类算法,通过计算情感句对情感评价对象的情感倾向和情感权重,完成情感计算。通过情感单元抽取、情感评价对象抽取、情感词情感权重、博主个性化建模分析,给出了情感分析算法,实现了微博情感分类及检索系统。结果表明算法具有一定可行性和实用价值。同时,也对可能存在的问题及下一步的研究计划进行了说明。
[1] Brendan O C, Ramnath B, Bryan R R, et al. From Tweets to Polls: Linking Text Sentiment to Public Opinion Time Series[C]//Proceedings of the 4th International AAAI Conference on Weblogs and Social Media, USA, 2010:122-129.
[2] 赵妍妍, 秦兵, 车万翔, 等. 基于句法路径的情感评价单元识别[J].软件学报, 2011, 22(5): 887-898.
[3] Sachan M, Contractor D, Faruquie T A, et al. Using Content and Interactions for Discovering Communities in Social Networks[C]//Proceedings of the International Conference on World Wide Web, France, 2012: 331-340.
[4] 赵妍妍, 秦兵, 刘挺. 文本情感分析[J], 软件学报.2010, 21(8):1834-1848.
[5] 杨超, 冯时, 王大玲, 等. 基于情感词典扩展技术的网络舆情倾向性分析[J]. 小型微型计算机系统, 2010, 31(4):691-695.
[6] Qiu G, Liu B, Bu J, et al. Expanding Domain Sentiment Lexicon through Double Propagation[C]//Proceedings of the 21st International Joint Conference on Artificial Intelligence(IJCAI2009), USA, 2009:1199-1204.
[7] Jakob N, Gurevych I. Extracting Opinion Targets in a Single- and Cross-Domain Setting with Conditional Random Fields[C]//Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing(EMNLP2010), 2010: 1035-1045.
[8] 李寿山, 李逸薇, 黄居仁, 等. 基于双语信息和标签传播算法的中文情感词典构建方法[J]. 中文信息学报, 2013, 27(6):75-81.
[9] 顾正甲, 姚天昉. 评价对象及其倾向性的抽取和判别[J]. 中文信息学报, 2012, 26(4): 91-97.
[10] Tan S B, Cheng X Q, Wang Y F, et al. Adapting Naive Bayes to Domain Adaptation for Sentiment Analysis[C]//Proceedings of the European Conference on Information Retrieval, France, 2009: 337-349.
[11] 林政, 谭松波, 程学旗. 基于情感关键句抽取的情感分类研究[J]. 计算机研究与发展, 2012, 49(11): 2376-2382.
[12] 冯时, 付永陈, 阳峰, 等. 基于依存句法的博文情感倾向分析研究[J]. 计算机研究与发展, 2012, 49(11): 2395-2406.
[13] 樊娜, 蔡皖东, 赵煜. 基于混合模型的文本主题情感分析方法[J].华中科技大学学报(自然科学版), 2010, 38(1): 31-34.
[14] 杨江, 侯敏, 王宁. 基于浅层篇章结构的评论文倾向性分析[J]. 中文信息学报, 2011, 25(2):83-87.
[15] 苏艳, 居胜峰, 王中卿, 等. 基于随机特征子空间的半监督情感分类方法研究[J]. 中文信息学报, 2012, 26(4):85-90.
[16] Tan C, Lee L, Tang J. User-Level Sentiment Analysis Incorporating Social Networks[C]//Proceedings of the 17th ACM SIGKDD international conference on Knowledge discovery and data mining, USA, 2011:1397-1405.
[17] Jiang L, Yu M, Zhou M, et al. Target-dependent Twitter Sentiment Classification[C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics, USA, 2011: 151-160.
[18] 中文情感挖掘语料[OL], http://www.datatang.com/data/14617, 2013.
[19] 中国计算机学会自然语言处理与中文计算会议. 中文情感分析及词汇语义关系抽取评测数据[OL],http://tcci.ccf.org.cn/conference/2012/pages/page04_evares.html, 2012.

高凯(1968—),博士,副教授,主要研究领域为大数据搜索与挖掘、自然语言处理、网络信息检索、社会计算等。E-mail:gaokai@hebust.edu.cn李思雨(1990—),硕士研究生,主要研究领域为自然语言处理、情感计算。E-mail:l_sy1111@126.com阮冬茹(1967—),硕士,副教授,主要研究领域为自然语言处理、大数据挖掘及信息安全。E-mail:ruandr@hebust.edu.cn
第十届中国中文信息学会暑期学校在北京大学成功举办
2015年7月24日至25日,第十届中国中文信息学会暑期学校在北京大学成功举办。自2005年以来,语言技术暑期学校已成功举办九届,是国内语言信息处理领域最为重要的学术活动之一。历届暑期学校获得了广大师生的普遍好评,为自然语言技术的人才培养和技术推广做出了卓越贡献,数以千计的学子在暑期学校中获得了来自国内外著名高校和科研机构的知名学者的当面指导,受益匪浅。
本届2015年度暑期学校由北京大学计算语言学研究所承办。此次暑期学校的特邀讲师均是在机器学习、自然语言处理领域有着较高知名度的华裔学者。其中,24日上午,来自美国布兰迪斯大学的薛念文教授讲解了语言学研究中语义分析方面的基本方法和算法;24日下午,来自德克萨斯大学达拉斯分校的Vincent Ng教授介绍了指代消解的相关技术成果;25日上午,中国科学院信息工程研究所王斌研究员针对信息检索相关技术做了详细讲解并介绍了其团队针对传统方法的一些改进;25日下午,在微博圈中享有很高人气的来自卡内基梅隆大学的王威廉博士梳理了信息抽取领域基础算法,并分享了自己团队的最新技术和成果。25日晚上,由来自诺特丹大学的蒋伟教授,介绍了机器翻译的相关技术和成果,并针对具体问题进行了现场答疑。最后北京大学计算语言学研究所所长王厚峰教授做了简单总结和回顾。
中国中文信息学会秘书长,中国科学院软件研究所孙乐研究员,中国科学院自动化研究所宗成庆研究员,计算语言学教育部重点实验室主任穗志芳教授等国内知名专家出席了暑期学校并致辞。来自全国各地高校,研究所和企业的300多名研究生、教师和研究人员参加了此次为期两天的暑期学校,学员规模为历届之最。
本届暑期学校的成功举办,不仅让大家对自然语言处理及相关技术有了更深入的认识,而且通过交流让大家对自然语言处理技术的发展前景更加充满信心,大家都非常珍惜这次难得的学习机会,纷纷表示希望以后还有更多的学习交流机会。
A Micro-blog Sentiment Analysis Approach
GAO Kai, LI Siyu, RUAN Dongru, LIU Shaobo, ZHOU Erliang, QIAO Shiquan
(School of Information Science & Engineering, Hebei University of Science and Technology, Shijiazhuang, Hebei 050018, China)
The social network has become an effective platform to mine the society and public opinions. This paper proposes a sentiment analysis approach based on sentiment unit and opinion target. The extraction of sentiment unit and sentiment evaluation object is based on the co-occurrence probability. This paper also calculates sentiment degree of the sentiment unit. Experimental results validate the feasibility of the approach.
social network; short-text mining; sentiment unit; opinion target
1003-0077(2015)04-0040-10
2013-09-12 定稿日期: 2014-05-19
河北省社会科学发展研究课题(2015030344)
TP391
A
