基于统计专用字符的维、哈、柯文文种识别研究
2015-04-21买买提依明哈斯木吾守尔斯拉木维尼拉木沙江努尔麦麦提尤鲁瓦斯
买买提依明·哈斯木,吾守尔·斯拉木,维尼拉·木沙江,努尔麦麦提·尤鲁瓦斯
(1. 新疆大学 信息科学与工程学院,新疆多语种重点实验室,新疆 乌鲁木齐 830046;2. 和田师范专科学校,计算机科学系,新疆 和田 848000)
基于统计专用字符的维、哈、柯文文种识别研究
买买提依明·哈斯木1,2,吾守尔·斯拉木1,维尼拉·木沙江1,努尔麦麦提·尤鲁瓦斯1
(1. 新疆大学 信息科学与工程学院,新疆多语种重点实验室,新疆 乌鲁木齐 830046;2. 和田师范专科学校,计算机科学系,新疆 和田 848000)
在Unicode编码方案中维、哈、柯文字符安排在阿拉伯字符区域,三种语言中共享字符比较多,跟阿拉伯字符区域混在一起,没有专用的语言ID。在信息检索和自然语言处理领域对维、哈、柯文的识别、处理带来不便。该文首先分析并总结了维、哈、柯文三种语言中的专用字符、复合字符、某些字符在某种语言中出现形势的独特性等特征,然后在此基础上设计了维、哈、柯文种识别算法。 实验结果表明该文提出的文种识别算法的正确率在文本多于70词时达到96.67%以上。
文种识别;专用字符;复合字符;维文;哈文;柯文;Unicode
1 引言
维吾尔语、哈萨克语、柯尔克孜语(下文简称维、哈、柯语)属于阿尔泰语系突厥语族。虽然有Uyghur、Kazakh、Kyrgyz不同语言之分,但其字模,字符串构成方式,语序以及句法和语法规则大体相通。另外,三种语言对应字符串的Unicode编码不仅内容上大体相同,而且在表现形式上(斜体字部分)也较接近。在字母表中的大部分字母完全相同并非常相近阿拉伯语[1-2],所以在Unicode编码方案中维、哈、柯文字符安排在阿拉伯字符区域(0600~06FF),跟阿拉伯字符区域混在一起,该区域中维、哈、柯共用一些字母,而且没有语言ID。该区域中字母的顺序符合阿拉伯字母表,维、哈、柯文字母的顺序非常混乱[3],所以在信息交换和自动识别应用中很难区分维、哈、柯文,且存在语言上的二义性。
近年来随着互联网技术的发展,维、哈、柯文网站越来越多。如何按文种分类、整理维、哈、柯文互联网信息资源是在维、哈、柯文信息检索、舆情分析、在线机器翻译中,首先需要解决的问题。专用字母识别是一种常用的文种识别技术。本论文研究通过统计维、哈、柯文三种语言各自独有的专用字符、复合字符和有些字符在某种语言中出现形式的独特性等特征来对维、哈、柯文进行文种识别。
2 相关技术
文种识别技术是在信息检索和在线机器翻译领域使用的基础技术之一,用来判断某一个文本是由哪种语言来描述的[4-5]。文种识别技术中用各种各样的特征来对文本进行分析。它们包括专用字符、独有词集合和独有N元字符序列等,分别有各自的优缺点[6]。基于统计专用字符的文种识别技术是最简单的文种识别方法,对于大规模的文本文种识别性能非常好,但是对于处理小规模的文本(包含一个句子)性能较差[7]。基于统计独有词集合的文种识别技术中选用独有词集合进行识别时,首先为每一个语种建立独有词库,并统计每一个语言中独有词的出现频率,这项工作较难实现[5,7]。这种方法不适合用于像英、维、哈、柯等粘性语言,因为这种语言中单词的前后加上前缀或后缀来表示不同的语法现象,形态变化活跃。统计单词的出现频率必须要进行分词、词法分析和词干提取等预处理操作[6,8]。没有指定文种之前无法对文本进行以上预处理操作。而且大多数语言的词法分析和词干提取技术不公开,不容易实现。所以这种文种识别方案难度高,不可取。另一种文种识别方法是由Canver和Trencke提出的基于N元模型的文种识别方法,该方法的思想是根据每种语言中出现频率组多的N元字符(连续字符序列)进行文种识别[8]。
在维、哈、柯文文种识别技术方面维尼拉·木沙江、吐尔地·托合提等人提出了基于静态重定位的维、哈、柯文Unicode编码方案,在该方案中,维、哈、柯文字母根据各自的字母表排序在三个不同的区域(仍然在0600~06FF),自动获取各自的语言表示信息,消除了语言上的二义性[3]。买尔旦·吾守尔用“维吾尔语-汉语”、“哈萨克语-汉语”和“柯尔克孜文-汉语”词库,分别统计以上词库中的维、哈、柯文专用字母和复合字母的出现频率,采用统计学知识、理论和方法,使得三种语言之间的文种识别率达到58.18%[9]。薛亚平也提出了采用维、哈、柯文特有字母的字母和特殊的字母组合进行文种识别的算法。在该算法中,如果该文件中只出现了维文特有的字母或字母组合,则可以判定该文为维文文件。同样方法也可以判断哈文文件。如果两种语言的特殊字母或字母组合均有出现,则可以判断为维、哈文的混排文件[10]。但该工作没有给出详细的统计实验数据。倪耀群、曹鹏等人使用N元语法模型实现了维吾尔文的快速语种判别,准确率超过98%[11]。
3 基于统计字符的维、哈、柯文文种识别系统的设计
3.1 维、哈、柯文Unicode字符介绍 Unicode字符编码是一种使用16bits(两个字节)唯一表示一个字符、一共能够表示65 536个字符的国际标准[11]。其中阿拉伯字母所有文字字符(包括维、哈、柯文)都集中在阿拉伯字母区域(0600~06FF),但是该区域中维、哈、柯文字符分布是不连续的,没有分配语言ID,共用一些代码位。0600~06FF范围包括,在“中华人民共和国国家标准(GB 21669-2008)信息技术维吾尔文,哈萨克文,柯尔克孜文编码字符集”中有制定的维、哈、柯文字母的42个名义字符形式和160个位于Arabic Presentation Forms的变形显现形式[12]。而以上42个名义字符代码位的大部分被三种语言共用。如表1~7中列出了三种语言中共用和独用字符[6]。

表1 维、哈、柯文共用字符名义形式及编码

表2 维吾尔文复合字符名义形式及编码

表3 哈、柯文共用名义字符及编码

表4 维吾尔文专用名义字符及编码

表5 维、哈文共用名义字符及编码

表6 哈萨克文专用名义字符及编码

表7 柯尔克孜文专用名义字符及编码
3.2 维文字符独特特征分析
维吾尔语中一共有32个字母,其中有8个元音字母和24个辅音字母。维文与哈文和柯文相比有以下三个特点。
a) 维文元音字符的特点。有些元音字符的独立形式、尾字符和首字形式由相应的元音字符前加“”(编码为0626,HAMZA ABOVE)来实现,如表8中的带下划线的字符,在哈、柯文中不会出现这种形式的字符组合。
c) 表4中的三个辅音字母是维文专用字符。
根据维文的以上三个特征,通过统计维吾尔文专用字符和复合字符,能够识别维吾尔文。

表8 维文复合字符名义形式和变形显现形式及编码
3.3 哈文字符独特特征分析
哈萨克语中一共有33个字母,其中有9个元音和24个辅音字母。目前哈萨克文网页上的字符有如下特点。
a) 理论上,根据表6中的哈萨克文专用字符可以识别出哈萨克文,但统计500篇哈萨克文网页正文中出现的哈文字符,只出现了28个哈文字符,几乎没出现表9中的带下划线的四个元音字母,也没出现哈文元音前置符“”(HIGH HAMZA, 编码为

表9 哈文专用名义字符形式和变形显现形式及编码

表10 哈文错误字符编码统计结果


3.4 柯文字符独特特征分析
柯尔克孜语中一共有30个字母,其中有8个元音字母,22个辅音字母。柯文专用字符有如下特点。
a) 编码为06C5和06C9及它们的变形显现形式是柯文专用的,如表11所示。

表11 柯文专用名义字符形式和变形显现形式及编码
b) 编码为0649的字母和它的变形显现形式在维文和哈文中都出现,所以从字符编码角度上不能作为专用字符,如表8和10所示。
c) 编码为0626(HAMZA ABOVE)的字母在维文中也出现,但出现时后面连接的字符必须是元音字符,如表8所示。在柯文中出现该字符的首字符形式和中字符形式时后面连接的是辅音字符,它的尾字符形式、独立字符形式是柯文专用的。在维文中词的最后不出现编码为0626的字符,也不以独立字符形式出现,后面必须要连接维吾尔元音字符。
d) 柯文中有同一个元音字符形式前后出现的现象,而在维文和哈文中的外来语中也会出现,主要出现在外来语中,但出现频率很低。柯文中的特殊元音字母组合如表12所示。
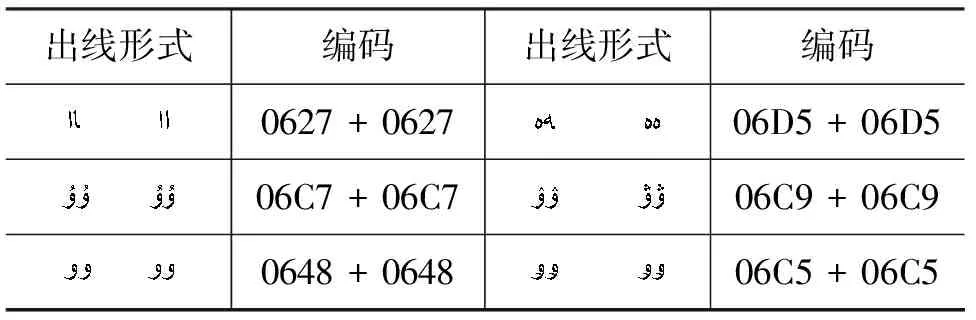
表12 柯文中的特殊元音字母组合
根据以上柯文的四个特征,通过统计柯文字符的独特特征,能够识别柯文。
3.5 基于统计字符独特特征的维、哈、柯文文种识别算法的设计 按照上述分析的维、哈、柯文专用字符、复合字符以及有些字符在某种语言中出现形式的独特性,本文设计了维、哈、柯文文种识别算法。该算法的思路是首先分别统计文本中出现的属于维、哈、柯三种语言的专用字符、复合字符、某种语言中出现的独特的字符形式,然后判断属于哪种语言统计值最高,统计值最高的语种被判断为该文本文种。因为维、哈、柯文是粘性语言,用户的拼写错误导致文本中出现属于其他语种的字符形式,有时候文本中也会引入其它语种描述的文本信息。所以为了避免文本中出现的其它文种的独特特性对文种识别的干扰,要分别统计文本中出现的属于三种语言的独特特征。具体分析思路是: 首先要读取文本,然后分析文本中的所有字符,判断某个字符是否满足如下条件:
a) 该字符是否属于某种语言的专用字符。
b) 能不能跟它后面的字符组合,形成属于某种语言的复合字符或特殊的元音字母的组合形式。
c) 该字符的出现形式是否属于该字符在某种语言的出现形式的独特字符。
按照上述的三个条件分别统计文本中出现的属于三种语言字符的独特特征。统计公式如下:
Chracter(x)=

(1)
4 实验与分析
4.1 实验数据的采集 维、哈、柯文到目前为止没有公开的文种识别语料库,本文设计了一个定向网页数据采集系统,在人民网、天山网、新华网和一些热门的维、哈、柯文综合网站中采集了相应的文本数据。本文采集的三种语言的文本集规模如表13所示。目前柯尔克孜文网站的数量比维文和哈文网站少,所以测试语料库中柯尔克孜文的数据比较少。

表13 测试语料库的规模
4.2 统计三种语言的专用和复合字符的出现频率
为了验证基于统计专用字符和复合字符的维、哈、柯文文种识别技术的有效性,需要统计维、哈、柯三种语言中的专用字符和复合字符出现的频率。在测试文本集中统计了第三节中总结出的三种语言的专用字符和复合字符的出现频率。
在表14~16中所示的数据分别为测试语料库中的维、哈、柯文文本中出现的维、哈、柯文字符的独
表14 10 606篇维文文本中维文字符的独特特性出现的文本数量

字符网页数字符网页数063A102190626+,06C710073062E10460626+,06C684810698193206C898560626+,06271045006D010425626+,06D5101740626+,0649101000626+,06488623
特特性。通过观察可以判断通过统计维、哈、柯文字符的独特特性的方法来识别维、哈、柯文文种的有效性。

表15 测试语料中哈文字符的独特特性出现的文本数量

表16 测试语料中柯文字符的独特特性出现的文本数量
在表15中几乎没有出现在表9中的带下划线的哈文专用字符,而代替出现了表10中的字符和字符的组合。出现以上错误的原因是当前使用的哈文输入法没有根据“中华人民共和国国家标准(GB 21669-2008)信息技术维吾尔文,哈萨克文,柯尔克孜文编码字符集”设计的原因。所以不能在统计理论上的哈文专用字符的基础上识别哈文,必须要借用实际出现编码的特点来识别哈文。
在表16中带下划线的数据是柯文文本中的特殊元音字母组合出现的文本数量。在表17中带下划线的数据是不考虑柯文双元音字母组合时不同规模的柯文文本段的识别正确率,比较两组数据可以得到结论,考虑特殊双元音字母组合很大程度上提高了对柯文文种的识别准确率。从表中的数据可以看出柯文中的特殊的元音字母组合可以作为特征来识别柯文。
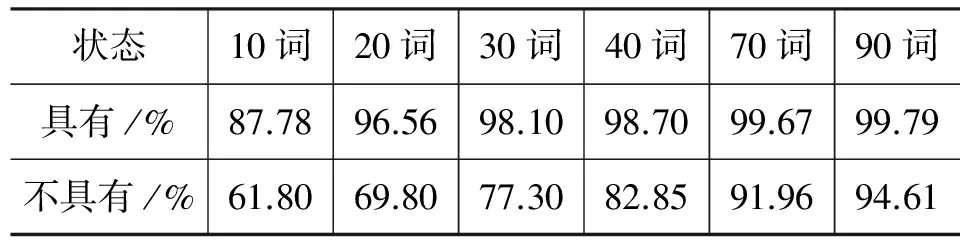
表17 测试双元音字母特征对柯文文种识别印象
在表18~20中所示的数据分别为测试语料库中的维、哈、柯文文本中出现的其他文种的独特特性。所以为了避免文本中出现的其他文种的独特特性对文种识别的干扰,首先要分别统计文本中出现的各个文种字符的独特特性,然后出现独特特性最高的文种被指定为该文本的文种。
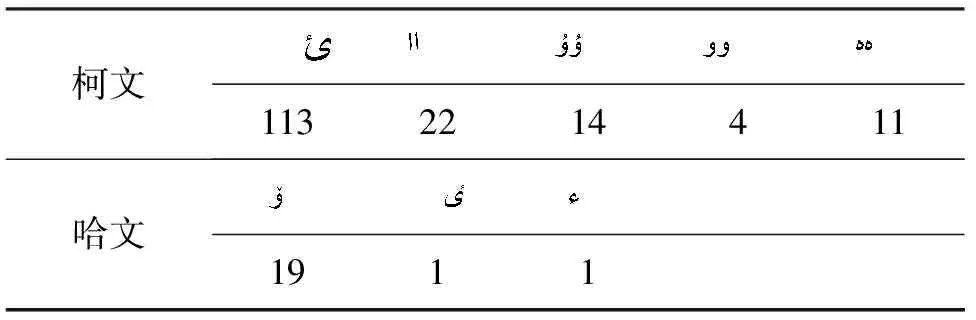
表18 10 606篇维文本中出现其他文种独特特性的文本数量
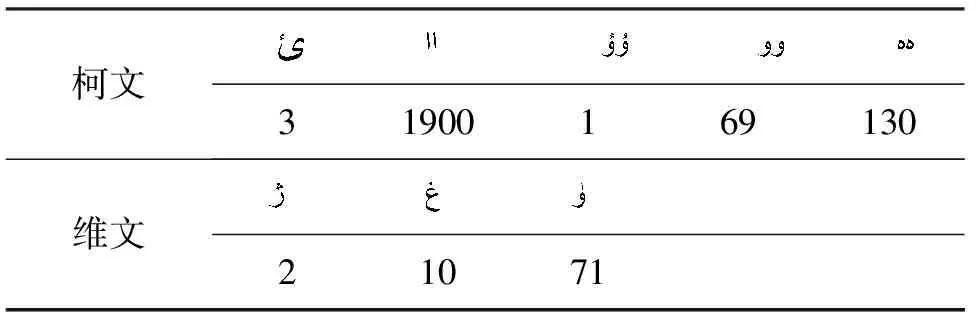
表19 8 039篇哈文本中出现其他文种独特特性的文本数量

表20 1 503篇柯文本中出现其他文种独特特性的文本数量
4.3 性能测试
为了验证本文研究的文种识别算法的准确率,分别测试了语料中的识别率和包含不同字数文本中的准确率,实验结果如表21和表22所示。
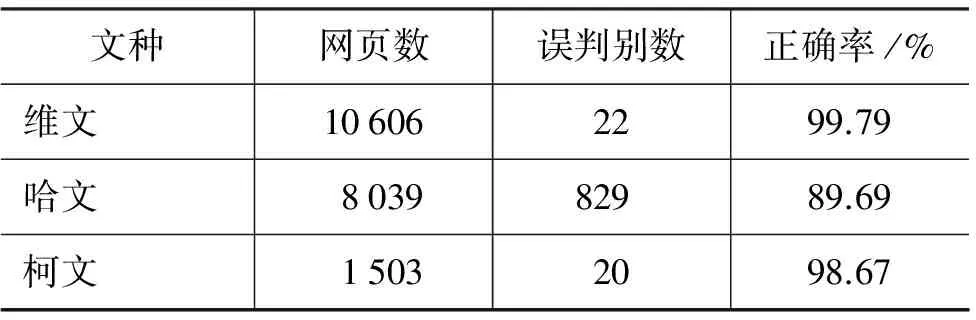
表21 在测试语料中的识别率
通过分析表21中的数据可以总结出本文研究的维、哈、柯文文种识别算法对维文和柯文的识别性能是很理想的,哈文识别效果不如维、柯文,因为哈文字符的独特字符特征比维、柯文少得多。
为了测试本文研究的文种识别算法在不同规模的文本中的性能,把测试语料库中的文本分组成不同规模的文本段,在不同规模的文本段中测试文种识别算法的精确度。通过分析表22中的数据可以总结出文本中包含的词总数70以上时,它的识别效率是很理想的,准确率高于96.67%。维、柯短文本的识别效率是很理想的,对包含词数小于30的哈文段文本的识别效率不太理想。
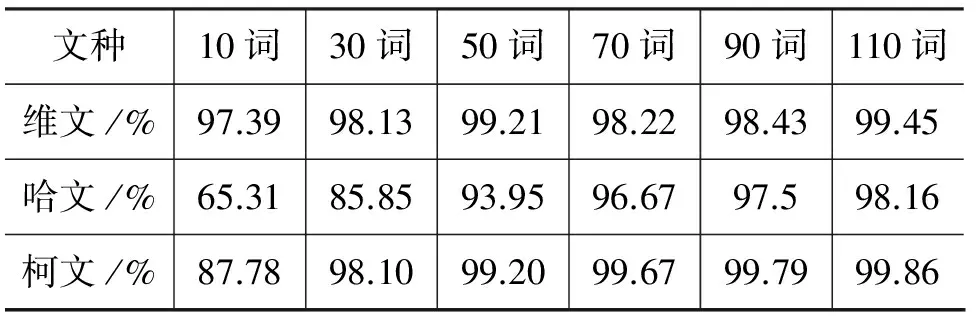
表22 包含不同词数文本中的识别率
5 结论
本文研究的基于统计字符的维、哈、柯文文种识别技术对长文本性能非常好,文本包含的词数多于70词的时候准确率达到96.67%以上。对维、柯文的识别率比哈文的识别率高,因为哈文的独特字符特征比维、柯文少得多。在文本规模比较大时可以达到各领域实际应用的目标。
[1] 吐尔根·依布拉音,袁保社.新疆少数民族语言文字信息处理研究与应用[J].中文信息学报,2011,25(6):150-156.
[2] 王玲,达瓦·伊德木草,吾守尔·斯拉木.维哈柯及蒙语多文种语言相似性考查研究[J].中文信息学报,2013,27(6):180-186.
[3] 维尼拉·木沙江,吐尔地·托合提,吐尔洪·吾司曼。基于重定位的维、哈、柯文Unicode编码及多文种索引技术研究[J].郑州大学学报(理学版),2009,41(1):48-51.
[4] R D Lins and P. Gonçalves. Automatic language identi_cation of written texts[C]//Proceedings of SAC-2004, the 2004 ACM symposium on Applied computing, ACM Press, 2004:1128-1133.
[5] Chew Y Choong, Yoshiki Mikami, C A Marasinghe et al. Optimizing ngram Order of an ngram Based Language Identification Algorithm for 68 Written Languages[J]. The International Journal on Advances in ICT for Emerging Regions 2009,02 (02):21-28.
[6] Bruno Martins, M rio J.Silva. Language Identification in Web Pages[C]//Proceedings of SAC’05 March, Santa Fe, New Mexico, USA:ACM, 2005: 13-17.
[8] W B Cavnar and J.M.Trenkle. N-gram-based text categorization[C]//Proceedings of SDAIR-94, the 3rd Annual Symposium on Document Analysis and Information Retrieval, Las Vegas, Nevada, U.S.A, 1994: 161-175.
[9] 买日旦·吾守尔,维尼拉·木沙江.多文种多向电子词典软件系统关键技术研究[J].计算机应用与软件,2011,28(4):170-173.
[10] 薛亚平,袁保社. 全文检索系统中语种识别与索引技术研究[J].技术应用,2009,12: 49-51.
[11] 倪耀群,曹鹏,许洪波,唐慧丰,程学旗.网络维吾尔文判别及其文本长度下界的探讨[J].中文信息学报,2012,26(6):109-115.
[12] 中华人民共和国国家标准(GB 21669-2008)信息技术维吾尔文,哈萨克文,柯尔克孜文编码字符集[C],2008-04-11发布,2008-09-01实施.
Unique Character Based Statistical Language Identification for Uyghur, Kazak and Kyrgyz
Maimaitiyiming Hasimu1,2, Wushouer Silamu1, Weinila Mushajiang1, Nuermaimaiti Youliwasi1
(1. School of Information Science and Engineering, Xinjiang University, Multilingual Information Technology Laboratory of Xinjiang, Urumqi, Xinjiang 830046, China; 2. Department of Computer Science Hotan Teachers College, Hotan, Xinjiang 848000, China)
In Unicode encoding consortium, Uyghur, Kazak and Kyrgyz characters are arranged in the Arabic characters area and mixed with Arabic characters. Some characters in these languages shares same code without language ID,which brings difficulty in information retrieval and natural language processing. After analyzing the unique characters, compound characters and the special features of some characters in certain language context, this paper designs a language identification algorithm of Uyghur, Kazak and Kyrgyz. The experimental results show that the accuracy achieves 96.67% for texts with 70 words or more.
language identification, unique characters, compound characters, Uyghur text, Kazak text, Kyrgyz text, Unicode

买买提依明·哈斯木(1980—),博士研究生,讲师,主要研究领域为信息检索。E⁃mail:mamtimin116@163.com吾守尔·斯拉木(1942—),中国工程院院士,本科,教授,博士生导师,主要研究领域为自然语言处理。E⁃mail:wushour@xju.edu.cn维尼拉·木沙江(1960—),本科,教授,硕士生导师,主要研究领域为信息检索。E⁃mail:winira@xju.edu.cn
1003-0077(2015)02-0111-07
2014-03-17 定稿日期: 2014-04-25
国家“973”重点基础研究计划(2014CB340506);国家自然科学基金(61262063,61363063)
TP391
A
