基于MapReduce的并行PLSA算法及在文本挖掘中的应用
2015-04-21罗文娟庄福振史忠植
李 宁,罗文娟,庄福振,何 清,史忠植
(1. 中国科学院计算技术研究所 智能信息处理重点实验室,北京 100190;2. 中国科学院大学,北京 100190;3. 河北大学 数学与计算机学院机器学习与计算智能重点实验室, 河北 保定 071002)
基于MapReduce的并行PLSA算法及在文本挖掘中的应用
李 宁1,2,3,罗文娟1,庄福振1,何 清1,史忠植1
(1. 中国科学院计算技术研究所 智能信息处理重点实验室,北京 100190;2. 中国科学院大学,北京 100190;3. 河北大学 数学与计算机学院机器学习与计算智能重点实验室, 河北 保定 071002)
PLSA(Probabilistic Latent Semantic Analysis)是一种典型的主题模型。复杂的建模过程使其难以处理海量数据,针对串行PLSA难以处理海量数据的问题,该文提出一种基于MapReduce计算框架的并行PLSA算法,能够以简洁的形式和分布式的方案来解决大规模数据的并行处理问题,并把并行PLSA算法运用到文本聚类和语义分析的文本挖掘应用中。实验结果表明该算法在处理较大数据量时表现出了很好的性能。
概率主题模型;MapReduce;并行;语义分析
1 引言
当我们得到一个大规模的文本数据集或者是其他类型的离散数据集合时,为了便于理解,总是希望找到这个庞大的数据集的一个简短描述和概括,来代表或是反映出整个数据集的特征信息。对文本数据来说,就是抽取出一个或几个主题这样的抽象概念来描述整个文本数据集。例如,一本期刊,我们如果知道它主要是关于娱乐和时尚的,那么它里面所有的文章自然也是这两个主题相关的,由此可以根据自己的爱好选择是否阅读这些文章。
传统的VSM模型使用关键字来表示主题。但这种表达方式比较局限于对文档贡献较大的词,很多用于表示文档的词语,由于存在二义性,对于文档的语义上的描述,效果往往差强人意[1]。为了克服VSM 模型的这些缺点,有学者提出了主题模型。
主题模型(topic model)又称层面模型(aspect model),是近几年兴起的一种对数据进行挖掘、分析的一种建模方法,它们不仅在场景分类、对象识别等领域取得了好的效果,也成功地应用于图像的自动标注和检索[2-5]。其主要思想为:给定多项分布的潜在变量,捕获词的共现模式。一个文档不再表示为一组词的共现集合,而是在给定一个潜在变量的情况下,经过建模表示为一系列的词共现集合的混合。这些词共现集合建模为词汇表上的多项分布,可称为文档集中的“主题”。将这个词上的多项分布解释为主题能够给文档集一个直观的结构,所以这类概率模型常常称为主题模型。
主题模型的思想最早来源于隐含语义索引(Latent Semantic Indexing,LSI)[6]。其工作原理是利用矩阵理论中的“奇异值分解(SVD)”技术,将词频矩阵转化为奇异矩阵,通过去除较小的奇异值向量,只保留前K个最大的值,将文档向量和查询向量从词空间映射到一个K维的语义空间(主题)。在该空间中,来自词语—文档矩阵的语义关系被保留,同时词语用法的变异(如同义性,多义性)被抑制。
主题模型的第二次重大突破是Hofmann提出的PLSA(Probabilistic Latent Semantic Analysis)模型[7-8]。PLSA使用图模型来表示文档、主题和词语三者之间的关系,将文档和词语映射到同一个主题空间。
在文档层面上,PLSA可以将文档映射到各个主题,这些主题可以看作文本类别,每一文本所属类别中概率最大的那一类可作为文本最终所属类别[9],这样PLSA的建模过程实际也是对文本进行聚类的过程,从而可以将PLSA模型用于文本聚类。
在词语层面上,每个词语对每个主题都有相应的概率值,我们可以将概率值最大的那个主题来作为这一词语所对应的最终主题。反过来,每一主题下会有多个词语与之对应。这些词语被认为是主题相关的,即在主题角度上语义相近的。因此,我们可以将PLSA模型用于文本中词语的语义分析。
随着信息技术和网络的迅猛发展,网络中积累了各个行业的海量数据。如何从这些数据中挖掘出人们感兴趣的主题成为了一个新的研究课题。传统PLSA算法采用EM迭代算法来进行求解,使其在处理大数据上性能不够好,将其并行会是一种比较好的解决方案。
对PLSA相关算法的并行已有一些工作。文献[10]中,作者采用共享内存的OpenMP编程模式,基于Lemur[11]中的TEM对PLSA算法进行了并行实现,并提出了分块算法和块调度算法,以达到负载平衡。Wan等人[12]对上述算法进行了扩展,将OpenMP与MPI结合,采用了共享内存和分布式存储。OpenMP这种模式不适合集群环境,而MPI虽适合于各种机器,但它的编程模型复杂。需要分析及划分应用程序问题,并将问题映射到分布式进程集合,并且需要解决通信延迟大和负载不平衡两个主要问题。
Hadoop[13]是一个实现了MapReduce[14-17]计算模型的开源分布式并行编程框架,借助于MapReduce,我们可以轻松地编写并行程序,将其运行于计算机集群上,完成海量数据的计算。与OpenMP和MPI相比,MapReduce这种并行编程模式通过主节点的JobTracker来调度和分发构成一个作业的所有任务,无需人工干预,其实现算法的机理是不同的。
本文采用MapReduce编程模式对PLSA算法进行并行实现,文献[18]中提出了两种并行策略P2LSA和P2LSA+,P2LSA在Map阶段进行PLSA算法中的E步操作,在Reduce阶段进行M步操作,这种并行方式需要在Map和Reduce之间进行大量数据的传递,会加重网络和总的运行时间开销。P2LSA+首先将E步和M步进行整合,设计两个job来完成迭代更新操作。本文设计了一种新的并行策略,迭代过程只涉及一个job,取得了更好的并行效果。
本文的安排如下:第二部分介绍PLSA算法和MapReduce的相关知识;第三部分给出基于Map-Reduce的并行PLSA算法的详细实现过程;第四部分实验结果及在文本聚类和语义分析中的应用;第五部分对整篇文章进行了总结。
2 相关知识
2.1 PLSA算法 概率潜在语义分析(Probabilistic Latent Semantic Analysis(PLSA))模型,是在主题建模(Topic Modeling)领域发展成熟的一种统计技术,主要用于双模态(two-mode)和共生(co-occurrence)型数据。PLSA模型提出了对文本集进行主题建模的基本思想,通过对潜在语义分析(LSA)模型进行一层概率封装,可以将一个文本文档建模为若干潜在主题的混合,而每个主题都表示为一个词的多项分布。
PLSA模型使用图模型来表示文档、主题和词语三者之间的关系,将文档和词语映射到同一个主题空间。文档可以用主题的混合比重来表示,建模可以使离散的共现矩阵降维成固定主题集下的概率分布。其原理图如图1所示。

图1 PLSA模型的两种图模型表示
PLSA模型的主要任务是针对共现矩阵寻求一个生成模型。图1(a)中d表示文档,词以 w∈W,W={w1,…,wM} 表示,其中字典W相当于是M个字词所形成的集合。假定每个字词由给定文档下的语义主题(隐藏变量)z∈Z={z1,…,zK} 产生,整个文档生成过程如下:
• 选择一篇文档,其概率表示为p(d);
• 基于当前文档条件下,挑选一个潜在主题z,其概率为P(z|d),服从多项分布;
• 基于当前主题下,产生一个词的概率为P(w|z),服从多项分布。


(1)
由上述生成过程,可得出共现矩阵的联合概率模型如式(1)所示,式中对所有可能的z模拟意向模型,条件概率 P(w|z) 是K个关于主题的条件概率平面P(z|d) 的凸组合。文档由其P(w|z) 的因子的混合描述。PLSA主要基于两个方面的工作,即基于统计的潜在主题模型和两个独立性假设:
• 在潜在主题z状态下,文档和词是独立产生的;
• 词和潜在主题也是独立产生,与具体的文档没有关系。
根据上述两个独立性假设,可将模型转化潜在主题z下的对称模型,如图1(b)所示。则式(1)中的联合概率可改写为式(2)中的形式。

(2)
PLSA的模型参数是两个条件概率分布P(w|z) 和P(z|d),这两个参数都满足多项分布,可以使用EM算法计算得到[19]。EM算法的两个步骤表示如式(3)~(6)所示。
(1)E步:
(3)
(2)M步:
(4)
(5)
(6)
2.2MapReduce
MapReduce将复杂的运行于大规模集群上的并行计算过程高度的抽象到了两个函数:Map和Reduce,适合用MapReduce来处理的数据集(或任务)有一个基本要求: 待处理的数据集可以分解成许多小的数据集,而且每一个小数据集都可以完全并行地进行处理。
图2说明了用MapReduce来处理大数据集的过程,这个MapReduce的计算过程简而言之,就是将大数据集分解为成百上千的小数据集,每个(或若干个)数据集分别由集群中的一个节点(一般就是一台普通的计算机)进行处理并生成中间结果,然后这些中间结果又由大量的节点进行合并,形成最终结果。
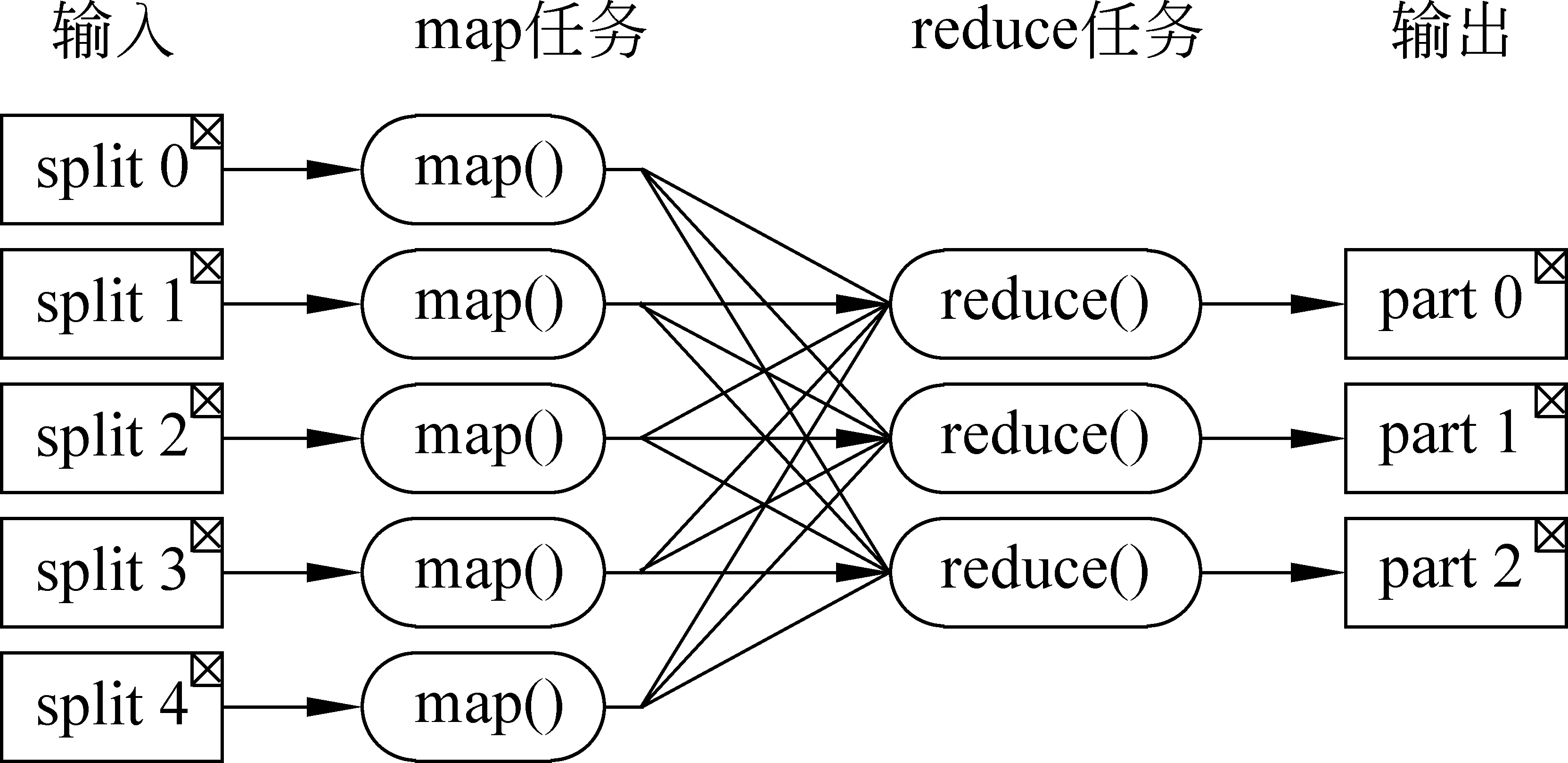
图2 MapReduce计算流程
计算模型的核心是Map和Reduce两个函数,这两个函数由用户负责实现,功能是按一定的映射规则将输入的
3 基于MapReduce的并行PLSA算法
通过对PLSA算法的分析我们可以看出,其主要的求解步骤为通过EM算法来计算P(w|z),P(z|d)和P(z)。为了方便说明问题,将n(d,w)P(z|d,w)用A表示,代入公式(4)~(6),得式(7)~(9)。
(7)
(8)
(9)
整个迭代过程主要是计算 ∑dA,∑wA 和R,而计算每篇文档的A和 ∑wA是相互独立的,互不干扰,可以在不同节点上并行完成。R的计算过程为一个计数过程,即将文档中所有出现单词的词频求和。因此,可以设计两个job来完成以上计算,一个job用于计算∑dA和∑wA,另一个job计算R。
对于计算 ∑dA和 ∑wA的job,在Map阶段完成每一篇文档的A和 ∑wA的计算,输入为一系列的
对于R的计算,在Map阶段完成一篇文章的 ∑wn(d,w), 如CountRMapper所示。在此基础上,计算所有文档的 ∑d,wn(d,w) 在Reduce阶段完成,如CountRReducer所示。

CountAMapperMap(key,value)输入:pz,pdz,pwz,,偏置key,字符串value输出: CountAReducer Reduce(key,value)1.初始化计数器sum=0;2.for(Textvalue:values)3. sum+=value/∗对具有相同key值的value值求和∗/4.end5.输出(key,sum); CountRMapper Map(key,value)输入:偏置key,字符串value输出: CountRReducer Reduce(key,value)1.初始化sum=0;2.for(Textvalue:values)3. sum+=value;4.end5.输出(key,sum); 根据以上并行策略,我们给出完整的并行 PLSA 算法。如算法PPLSA所示。 算法PPLSA1.初始化p(z),p(w|z),p(d|z);2.执行计算R的job;3.for(circleID=1;circleID<=numCircle;circleID++)/∗numCircle为最大循环次数∗/4. 执行计算∑dAand∑wA的job5. 计算∑d,wA;6. 更新p(z),p(w|z),p(d|z);7.end8.输出p(z),p(w|z),p(d|z). 为验证所提出的并行PLSA算法的性能,我们将其置于云计算平台上运行。实验环境为由10台计算机搭建的集群,我们选用其中的四个节点来运行,每个节点CPU配置为2.8GHz,内存为4GB。MapReduce系统所采用的Hadoop版本为0.20.2,Java版本为1.5.0_14。 4.1 实验设计 文本聚类技术可以有效组织网络文本、帮助使用者获得他们想要的信息[20-21]。本文中,我们将并行PLSA算法应用于文本聚类和语义分析上。用于文本聚类的数据来源于从中兴、华为主页及相关论坛上采集的网页文本。网址如下: http://www.zte.com.cn, http://www.huawei.com/cn, http://bbs.c114.net, http://www.hwzte.com。 对于语义分析,我们将证券相关网页作为训练数据,对给定的检索词,输出与其主题相关的词。对于一个文档数据集,PLSA算法可以找到每个单词所对应的主题并输出相对应的概率值,我们可以由此找出每个单词所对应的主题,即概率值取值最大的那个主题。从而建立单词-主题-概率值这样的映射关系。 建立映射之后,可以根据映射关系找到每个主题下所有的单词及其所属概率值,对于输入的检索词,首先根据映射关系找到其所属的主题,然后输出这一主题下概率值最大的前几个词作为语义分析的输出。 为了验证并行PLSA算法在处理大数据集时的性能,我们选用两个数据集来进行实验,其中一个为TREC AP文档集,包含2 246篇文档,10 473个单词。另一个为从证券相关网页上采集到的网页文本,包含216个html文档,27 925个单词。 性能指标方面,采用scaleup,sizeup,speedup来评价PLSA算法的并行性能。 Scaleup: 度量了不同处理器规模下,处理不同规模数据的性能。具体定义公式为式(10)。 Scaleup= (10) Sizeup: 度量了在平台固定的情况下,不断增大数据集时的性能。具体定义公式为(11)。 (11) Speedup: 度量了并行计算比串行计算加快的程度。具体定义公式为(12)。 (12) 为说明本文所提算法的高效性,与文献[18]中的P2LSA+算法进行了时间上的对比。 4.2 实验结果 4.2.1 在文本聚类中的应用 我们从中兴、华为主页及相关论坛上对网页文本进行了采集,经过网页解析,文本净化,词频统计,向量表示,特征选取等预处理过程,将网页文本表示成可以直接处理的向量。然后用并行PLSA对其进行聚类。表1列出了聚类结果,共聚出了10类文本,每类文本分别用10个词来描述其主题。 表1 PLSA聚类结果 从表1中可以看出,PLSA算法可以很好的应用到文本聚类中。 4.2.2 在语义分析中的应用 我们对308个证券相关网页进行处理,表2列出了所得到的结果。 表2 主题相关的语义分析结果 从此结果可以看出,PLSA算法可以找到在主题层面上语义相关的词,而不单单是词义相近的。 4.2.3 Scaleup 为验证算法在多处理器下处理大数据集的性能,我们将原数据集扩大至原来的60倍,120倍,240倍,分别在4,8,16台机器上运行。将四个节点的运行时间做为基准,所得到的scaleup性能如图3所示。 图3 Scaleup性能展示 从图3中可以看出,随着数据规模和节点规模的增大,所得到的scaleup曲线几乎保持为常数1,显示了很好的扩展性能。 4.2.4 Sizeup 为验证算法的sizeup性能,我们分别固定节点数为4,8和16,对于每种固定节点,不断增大数据规模,图4展示了两个数据集的实验结果。 从图4中可以看出,算法表现出了较好的sizeup性能,随着数据规模的增大,性能提升也越明显。原因在于,增大数据规模会增加I/O操作和文档处理,使得非通信时间增大,进而导致通信时间在整个算法运行时间中的比例减少。而CPU处理又有着很好的扩展性能,因此我们得到了比较好的sizeup性能。 图4 Sizeup性能展示 4.2.5 Speedup 我们用四核机器的数据作为基准来验证加速比性能。结果如图5所示。 图5 speedup性能展示 从图5可以看出,当核数比较少的时候,并行PLSA算法可以达到线性加速比。当节点数增长时,提高的性能并不明显。原因在于随着节点数增多,节点间相互通信的绝对时间增大,其在整个执行时间中所占比例也随之增大。当计算时间减小时,增加节点数已经不能提高更多的加速比。 另外,算法在大的数据集上表现出了比较好的加速比性能。因为数据集增大,每个节点处理的数据量相应增加,计算时间在整个执行时间中所占比例提高,因此,算法可以有效地处理大数据集。 4.2.6 与其他方法的比较 如前所述,文献[18]中提出了两种并行策略P2LSA 和P2LSA+,后者比前者表现出了较好的并行效率,执行速度更快。本文针对240倍大小的AP数据集,在相同实验环境下,用四核机器的数据作为基准,与P2LSA+进行了speedup的对比,结果如图6所示。 图6 与P2LSA+算法的speedup对比结果 由于本文所提算法用一个job来完成PLSA算法中的迭代过程,而P2LSA+则需要两个job来完成,因此本文算法有着更好的并行性能,从图6也可以看出,本文所提算法比P2LSA+显示了更好的加速比性能。 针对串行PLSA算法难以处理大数据集的问题,本文提出了一种基于MapReduce的并行PLSA算法,并将其应用到文本聚类和主题语义分析中。实验证明所提算法有着较好的并行性能,并且在聚类和语义分析中有着很好的应用。 [1] 宋晓雷,王素格, 李红霞, 等. 基于概率潜在语义分析的词汇情感倾向判别[J]. 中文信息学报, 2011, 25(2): 89-93. [2] Blei D M, Jordan M I. Modeling annotated data[C]//Proceedings of the 26th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval. Los Alamitos: IEEE Computer Society, 2003: 127-134. [3] Monay F, Gatica-Perez D. Modeling semantic aspects for cross-media image indexing [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2007, 29(10): 1802-1817. [4] Li Z-X, Shi Z-P, Liu X, et al. Automatic image annotation with continuous PLSA[C]//Proceedings of the 35th IEEE International Conference on Acoustics, Speech and Signal Processing. Los Alamitos: IEEE Computer Society, 2010: 806-809. [5] Mark Steyvers. Probabilistic Topic Models[C]//Proceedings of Latent Semantic Analysis: A Road to Meaning. Laurence Erlbaum,2007:420-440. [6] Scott CD, Susan TD, Thomas KL,et al. Indexing by latent semantic analysis[J]. Journal of the American Society for Information Science, 1990,41(6):391-407. [7] Hofmann T. Probabilistic Latent Semantic Analysis[C]//Proceedings of 15th Conference on Uncertainty in Artificial Intelligence, San Francisco: Morgan Kaufmann, 1999: 289-296. [8] Hofmann T. Unsupervised learning by probabilistic latent semantic analysis [J]. Machine Learning, 2001, 42(1): 177-196. [9] 张玉芳, 朱俊, 熊忠阳. 改进的概率潜在语义分析下的文本聚类[J]. 计算机应用, 2011, 31(3): 674-676. [10] Hong C, Chen W, Zheng W, et al. Parallelization and characterization of probabilistic latent semantic analysis[C]//Proceedings of Parallel Processing, 2008. ICPP’08. 37th International Conference on. IEEE, 2008: 628-635. [11] The Lemur Toolkit for Language Modeling and Information Retrieval. Available at http://www.lemurproject.org. [12] Wan R, Anh V N, Mamitsuka H. Efficient probabilistic latent semantic analysis through parallelization[M]Information Retrieval Technology. Springer Berlin Heidelberg, 2009: 432-443. [13] Hadoop: Open source implementation of MapReduce, Available: http://hadoop.apache.org, June 24, 2010. [14] Dean J, Ghemawat S. MapReduce: Simplified Data Processing on Large Clusters[C]//Proceedings of Operating Systems Design and Implementation, San Francisco, CA, 2004: 137-150. [15] Ghemawat S, Gobioff H, Leung S. The Google File System[C]//Proceedings of Symposium on Operating Systems Principles, 2003: 29-43. [16] Lammel R. Google’s MapReduce Programming Model—Revisited. Science of Computer Programming 70, 2008: 1-30. [17] 李锐,王斌.文本处理中的MapReduce技术[J].中文信息学报, 2012, 26(4):9-20. [18] Y Jin. P2LSA and P2LSA+: Two Paralleled Probabilistic Latent Semantic Analysis Algorithms Based on the MapReduce Model[C]//IDEAL 2011, LNCS 6936, 2011: 385-393. [19] Qiaozhu Mei, ChengXiang Zhai. A note on EM algorithm for probabilistic latent semantic analysis[C]//Proceedings of the International Conference on Information and Knowledge Management (CIKM),2001. [20] 赵世奇, 刘挺, 李生. 一种基于主题的文本聚类方法[J]. 中文信息学报, 2007, 21(2): 58-62. [21] 刘远超, 王晓龙, 徐志明, 等. 文档聚类综述[J].中文信息学报, 2006,20(3): 55-62. MapReduce Based Parallel Probabilistic Latent Semantic Analysis for Text Mining LI Ning1,2,3, LUO Wenjuan1,2, ZHUANG Fuzhen1, HE Qing1, SHI Zhongzhi1 (1. The Key Laboratory of Intelligent Information Processing, Institute of Computing Technology, Chinese Academy of Sciences, Beijing 100190, China; 2. University of Chinese Academy of Sciences, Beijing 100190, China; 3. Key Lab. of Machine Learning and Computational Intelligence, College of Mathematics and Computer Science, Hebei University, Baoding, Hebei 071002, China) PLSA((Probabilistic Latent Semantic Analysis) is a typical topic model. To enable a distributed computation of PLSA for the ever-increasing large datasets, a parallel PLSA algorithm based on MapReduce is proposed in this paper. Applied in text clustering and semantic analysis, the algorithm is demonstrated by the experiments for s its scalability in dealing with large datasets. probabilistic latent semantic analysis; MapReduce; text clustering; semantic analysis 李宁(1982—),博士,讲师,主要研究领域为机器学习,数据挖掘,主题模型。E⁃mail:lin@ics.ict.ac.cn罗文娟(1987—),博士,主要研究领域为社交网络,文本挖掘,个性化推荐。E⁃mail:wenjuan.luo@renren⁃inc.com庄福振(1983—),博士,副研究员,主要研究领域为迁移学习,机器学习与并行数据挖掘。E⁃mail:zhuangfz@ics.ict.ac.cn 1003-0077(2015)02-0079-08 2013-06-09 定稿日期: 2014-02-19 国家自然科学基金(61175052,61203297,61035003);国家863高技术研究发展计划(2014AA012205, 2013AA01A606, 2012AA011003)。 TP391 A



4 实验及在文本挖掘中的应用








5 结语

