强语义模糊性词语的情感分析
2015-04-21张志飞苗夺谦岳晓冬聂建云
张志飞,苗夺谦,岳晓冬,聂建云
(1. 同济大学 计算机科学与技术系,上海 201804;2. 上海大学 计算机工程与科学学院,上海 200444;3. 加拿大蒙特利尔大学 计算机科学系,蒙特利尔)
强语义模糊性词语的情感分析
张志飞1,3,苗夺谦1,岳晓冬2,聂建云3
(1. 同济大学 计算机科学与技术系,上海 201804;2. 上海大学 计算机工程与科学学院,上海 200444;3. 加拿大蒙特利尔大学 计算机科学系,蒙特利尔)
语义的模糊性给词语的情感分析带来了挑战。有些情感词语不仅使用频率高,而且语义模糊性强。如何消除语义模糊性成为词语情感分析中亟待解决的问题。该文提出了一种规则和统计相结合的框架来分析具有强语义模糊性词语的情感倾向。该框架根据词语的相邻信息获取有效的特征,利用粗糙集的属性约简方法生成决策规则,对于规则无法识别的情况,再利用贝叶斯分类器消除语义模糊性。该文以强语义模糊性词语“好”为例,对提出的框架在多个语料上进行实验,结果表明该框架可以有效消除“好”的语义模糊性以改进情感分析的效果。
情感分析;语义模糊性;粗糙集;贝叶斯分类
1 引言
近年来,情感分析一直是自然语言处理领域的研究热点并取得了广泛应用[1-2],如商务决策、舆情监控等。随着社交媒体的普及,文本的表达由规范化向口语化逐渐转变,而且文本的规模也十分可观。情感分析借助社交媒体也取得了意想不到的成功,例如,股票走势预测[3]、政府选举预测[4]、用户兴趣发现[5]等。
国内外学者在情感分析方面开展了很多研究[6-7],其中也不乏关于特殊句式的研究,如条件句[8-9]和比较句[10-11]等。从这些研究中发现,中英文处理时存在一定的区别。同样,在单个词语上也存在区别,例如,英文的“Good”表达积极的情感,而中文对应的“好”虽然在大部分情况下也表达积极的情感,但是在与其他字组合或者在特殊情境下却表达消极或者中立的情感。目前,单个词语在情感分析中的研究还鲜有报道。
根据国家语委发布的《现代汉语常用字表》和《现代汉语常用词表(草案)》,汉语常用字有3 500个,常用词有56 008个。研究每个字词在情感分析中的作用既不符合实际,也完全没有必要。但是,汉语中有些词语不仅使用频率高,而且语义模糊性强。以“好”为例,在北京大学CCL现代汉语语料库*http://ccl.pku.edu.cn:8080/ccl_corpus/index.jsp?dir=xiandai的9 711个字中排名第88位,在《现代汉语词典(第5版)》中具有15个释义,足见“好”具有很强的语义模糊性[12]。
如果句子“维修站的服务好差”中的“好”被认为褒义词,那么句子的情感倾向判断错误。如果通过语义模糊性分析,认为不体现情感(实际为程度副词),那么句子的情感倾向判断正确。因此,研究具有强语义模糊性的词语有助于提高情感分析的效果。文献[13]利用HowNet*http://www.keenage.com/计算词语的语义倾向, HowNet中“好”具有13个概念, 会影响正确度
量其他词与“好”的语义相似度,因此文献[14]提出利用概念来识别词语的情感倾向。
本文重点描述了如何消除情感词语的语义模糊性。第二部分详细描述了一种规则和统计相结合的框架消除语义模糊性;第三部分以词语“好”为例具体阐述消除模糊性的方法;第四部分给出了实验结果;最后总结了全文的工作。
2 语义模糊性处理框架
2.1 基本框架 本文提出的语义模糊性处理框架如图1所示。以强语义模糊性词语为研究对象,通过规则和分类器消除在特定句子中该词语的语义模糊性。从训练语料中抽取该词语的特征(A部分),利用粗糙集自动生成决策规则(B部分),同时构造贝叶斯分类器(C部分)。当规则失效时,分类器作为补充。

图1 基本框架图
2.2 特征表示
特征主要指相邻信息,如相邻的词语、相邻词语的词性、是否位于句子的左端或右端等。

表1 相邻基本信息
表1从词性和位置角度列出了16个常见的相邻基本信息,所有符号的全集记作BI, 每个符号的值域为{0,1},1和0分别表示出现和不出现。
定义1 (基本特征)从基本信息中抽取满足一定条件的作为基本特征,通常采用阈值设定条件,将基本特征的全集记作BF, 于是有BF⊆BI, 每个基本特征的值域仍然为{0,1}。
(1)
公式(1)中的“特征名称=值”表示特征取该值(下同)。
定义2 (附加特征)当限定基本特征取特定词语时,称其为基本特征对应的附加特征,将附加特征的全集记作AF。

表2 附加特征
表2列举了5个附加特征,采用阈值法确定附加特征的值域。以LUW为例:

(2)
公式(1)和(2)中 count(*) 表示在训练语料中的计数,按照经验分别设置阈值为0.01和0.005。附加特征的阈值比基本特征的阈值小,因为附加特征是基本特征的补充,需要尽量保留。
将上述抽取出的特征表示成一张决策表,即框架图中的A部分。决策表定义如下。
定义3 (决策表)决策表形式化为一个四元组DT=(U,C∪D,V,f)[15],其中:
U:U为对象的非空有限集合,称为论域;
C:C=BF∪AF称为条件属性集合,包括基本特征和附加特征;
D:D={l} 称为决策属性集合,只有一个情感倾向属性;
V:V=∪Va(∀a∈C∪D),Va表示值域,有Va∈BF={0,1},Va∈AF=Y(a),Vl={1,-1,0};
f:f={fa|fa:U→Va},fa表示属性a的信息函数。
2.3 粗糙集规则生成
粗糙集理论是一种新的处理模糊和不确定性知识的数学工具,主要思想是在保持分类能力不变的前提下,通过属性约简或属性值约简,导出决策规则,这些规则可以有力解释一些语言现象,对应框架图中的B部分。首先给出粗糙集理论中常用的定义[16]。
定义4 (不可分辨关系)给定论域U和属性子集R⊆C∪D,则称IND(R) 为U上的不可分辨关系,简记为R,见公式(3),显然R是一个等价关系。

(3)
则 [x]R为包含x的R等价类,U/R表示U上所有的R等价类,有U/R={[x]R|∀x∈U}。
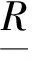

(4)
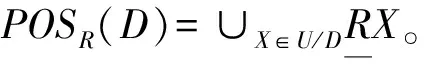
由于细粒度的词语倾向性标注需要付出更多的时间和人力,因此基于词语的倾向与句子保持一致的假设,设定决策表的决策属性l的值,见算法1。

算法1 设定决策属性l的值输入:强语义模糊性词语word和句子sentence输出:决策属性l的值(1)(2)(3)(4)(5)对句子sentence进行分词和词性标注并利用标点符号划分为子句集合Subs;找出子句集合Subs中含有word的子句sub;如果sub为否定句,则word的情感倾向和句子sentence的情感倾向相反;如果sub为肯定句或双重否定句,则word的情感倾向和句子sentence的相同;设定决策属性l的值为word的情感倾向并返回。
根据算法1得到的决策表通常是不相容决策表,即条件属性完全相同的情况下会出现决策属性值不同。为了获取确定性规则,将不相容决策表转变为相容决策表。转化的思想是: 在同一条件属性下,保留决策类别数最多的对象,舍弃决策类别少的对象。
对相容决策表运行属性约简算法[16](如基于Pawlak属性重要度、基于差别矩阵和基于互信息等),得到相对约简,记作Red⊆C, 相对约简可能为多个,进而生成决策规则。

算法2 不相容决策表转化为相容决策表输入:不相容决策表DT=(U,C∪D,V,f)输出:相容决策表DT′=(U′,C∪D,V,f)(1)(2)(3)(4)(5)(6)(7)令U′=∅;计算条件属性等价类全集U/C={Uc1,…,Ucn}和决策属性等价类全集U/D={Ud1,…,Udm};对于U/C的元素集合Ucs(1≤s≤n),计算与U/D的每个元素集合Udt(1≤t≤m)的交集Ucs∩Udt;找出基数最大的交集Ucs∩Udk,其中k=argmax1≤t≤mUcs∩Udt;U′=U′∪(Ucs∩Udk);返回到第(3)步,直到U/C的每个元素集合计算完毕;返回DT′=(U′,C∪D,V,f)。
定义7 (决策规则)给定相容决策表DT′=(U′,C∪D,V,f) 及其相对约简Red, 令Xi和Yj分别代表U′/Red与U′/D中的各个等价类, des(Xi) 和 des(Yj) 分别表示对Xi和Yj的描述(即属性的特定取值),则决策规则定义为:rij:des(Xi)→des(Yj)。
通过支持度和覆盖度对规则进行过滤,支持度Sup和覆盖度Cov分别反映了决策规则的强度和质量,见公式(5),采用阈值法进行过滤,只保留Sup(rij)≥0.01 且Cov(rij)≥0.01 的决策规则。
(5)
算法3给出了决策规则生成的具体步骤。

算法3 决策规则生成输入:相容决策表DT′=(U′,C∪D,V,f)输出:规则集合Rules(1)(2)(3)(4)(5)(6)(7)令Rules=∅;计算DT′的相对约简,由于可能为多个,用集合{Red}表示;对于每个约简Red,执行(4)至(6)步;计算Red和D的等价类全集({X}和{Y}),得到所有的候选决策规则{r};对于每条规则r,计算支持度Sup(r)和覆盖度Cov(r);如果Sup(r)≥0.01且Cov(r)≥0.01,则Rules=Rules∪{r};返回规则集合Rules。
2.4 贝叶斯分类
相容决策表提取的规则均为确定性规则,且无法匹配所有语言现象。当规则不能匹配时,进一步使用贝叶斯分类方法将消除语义模糊性问题转化为分类问题,即框架图中的C部分。词语属于不同情感倾向的概率等于所有特征属于不同情感倾向的概率的综合表达式。
定义8 (基本特征先验概率)基本特征在不同情感倾向中出现的概率,对于 ∀b∈BF有式(6)。
(6)
定义9 (附加特征先验概率)附加特征取某一个词语时在不同情感倾向中出现的概率,由于附加特征和基本特征之间存在依赖关系,比基本特征先验概率的计算要复杂。对于 ∀a∈AF,a=w有式(7)。

(7)
其中b为a对应的基本特征,参见表2。P(a=w|b,l=k) 的计算公式为式(8)。

(8)
公式(6)和(8)中的count(*) 为决策表DT中满足 * 的对象的计数,采用加一平滑避免零概率对其他后验概率的影响。在公式(8)中,当count(b=1,l=k)=0,count(a=w,b=1,l=k)=0, 于是设定一个很小的值0.001。
定义10 (特征组合后验概率)当若干特征组合出现时,词语属于不同情感倾向的概率。通常认为特征之间是相互独立的,但是本文中附加特征和对应的基本特征之间不独立,当附加特征被赋值时,对应的基本特征必然取值为1。特征组合F的后验概率为式(9)。
(9)
其中δ(F∩AF) 表示特征组合F中的附加特征集合对应的基本特征集合,F(a) 表示特征组合F中附加特征a的取值,P(l=k) 计算公式为式(10)。
(10)
朴素贝叶斯分类方法根据最大的特征组合后验概率确定词语的情感倾向。但是在实际应用时,数据中含有的噪声或者算法1的假设都可能导致后验概率之间的差异性不明显。当差异性不明显时,拒绝决策(通常赋值为0),否则决策很可能是错误的。
利用实际标准差和最大标准差来判断后验概率是否具有明显的差异性。最大标准差和实际标准差计算公式如式(11)和(12)所示。
(11)
(12)
根据公式(13)确定词语的情感倾向:

(13)
贝叶斯分类的完整过程见算法4。

算法4 基于贝叶斯分类的情感倾向计算输入:不相容决策表DT=(U,C∪D,V,f),特征组合F输出:给定F下的词语的情感倾向(1)(2)(3)(4)(5)根据DT和公式(6)计算基本特征的先验概率;根据DT和公式(7)计算附加特征的先验概率;根据公式(9)计算特征组合F的后验概率;根据公式(11)和(12)分别计算最大标准差和实际标准差;根据公式(13)确定词语的情感倾向并返回。
3 强语义模糊性词语“好”的情感分析
3.1 存在的问题 从分词及词性标注和依存句法分析角度体现研究的必要性。分词及词性标注工具采用了ICTCLAS*http://ictclas.nlpir.org/、HIT LTP*http://ir.hit.edu.cn/ltp/和FudanNLP*http://code.google.com/p/fudannlp/,HIT LTP和Stanford Parser*http://nlp.stanford.edu/software/lex-parser.shtml用于句法分析。
例1 “还好退了”
ICTCLAS结果(A):还/d 好/a 退/v 了/y
HIT LTP结果(B): 还/d 好/a 退/v 了/u
FudanNLP结果(C):还/副词 好/副词 退/动词 了/时态词
结果A和B均认为“好”为形容词,C认为是副词,最好的结果应该是“还好”整体作为一个副词。由于形容词“好”一般作为褒义词,结果A和B导致情感误判。
例2 “设置好都不用20分钟”
ICTCLAS结果(A):设置/v 好/a 都/d 不/d 用/v 20/m 分钟/q
HIT LTP结果(B): 设置/v 好/a 都/d 不/d 用/v 20/m 分钟/q
FudanNLP结果(C):设置/动词 好/趋向动词 都/副词 不/副词 用/动词 20/数词 分钟/量词
三个结果中只有C给出了更为准确的词性,趋向动词“好”不体现感情色彩。结果A和B却因为形容词性“好”而体现褒义色彩,导致情感误判。
例3 “维修站的服务好差”
ICTCLAS结果(A):维修/v 站/v 的/u 服务/v 好/a 差/a
HIT LTP结果(B): 维修站/n 的/u 服务/v 好/a 差/a
FudanNLP结果(C):维修站/名词 的/结构助词 服务/名词 好差/名词
三个结果均没有标注最好的结果“好/d 差/a”。如果不考虑情感强度,结果A和B认为是中性;如果考虑情感强度(“好”大于“差”),则为褒义。结果C将“好差”整体作为一个词,指“服务的好和差”,体现中性色彩。
从这三个例子看出,三个软件的词性标注结果不太一致,仅仅通过表面的词性来确定“好”的感情色彩也会有失偏颇。如果仅仅依赖词性不能满足要求,是否可以借助依存句法来解决这个问题呢?仍然对这三个例子进行分析,抽取其中与“好”有关的依存关系。
对于例1,HIT LTP的结果: ADV(退, 好),Stanford Parser的结果: advmod(退, 还好)。两者均认为“好”出现在状中结构中的副词,不体现感情色彩,符合实际情况。
对于例2,HIT LTP的结果: CMP(设置, 好),Stanford Parser的结果: dep(设置, 好)。前者为述补结构,后者识别为非定义的依赖关系,均不体现感情色彩,符合实际情况。
对于例3,HIT LTP的结果: ADV(差, 好),Stanford Parser的结果: nsubj(好, 服务)、root(ROOT, 好)、comod(好, 差)。前者正确判断,而后者句法分析错误,导致情感误判。
依存句法分析在一定程度上解决了问题,但是还存在局限性,如句法分析不正确会导致情感误判,而且需要付出一定的时间代价。因此,可以仅仅使用ICTCLAS,然后通过消除语义模糊性来确定“好”是否表达情感。
以强语义模糊性词语“好”为例,将本文所提出的框架用于消除“好”的语义模糊性,将其转化为二值分类问题,即表达褒义感情色彩和不表达感情色彩。根据框架,详细介绍“好”的特征表示、决策规则生成和特征组合后验概率计算三个过程。
3.2 “好”的特征表示
将实验数据集整合为一个训练语料。根据表1获取“好”的基本信息:

表3 “好”的基本信息
根据公式(1),选择13个基本特征,并从中选择LU、RU和RY为其设置附加特征LUW、RUW和RYW, 最终得到“好”的16个特征。参照公式(2),计算三个附加特征的值域如表4所示(其中“出现次数”指附加特征取对应词语的次数)。
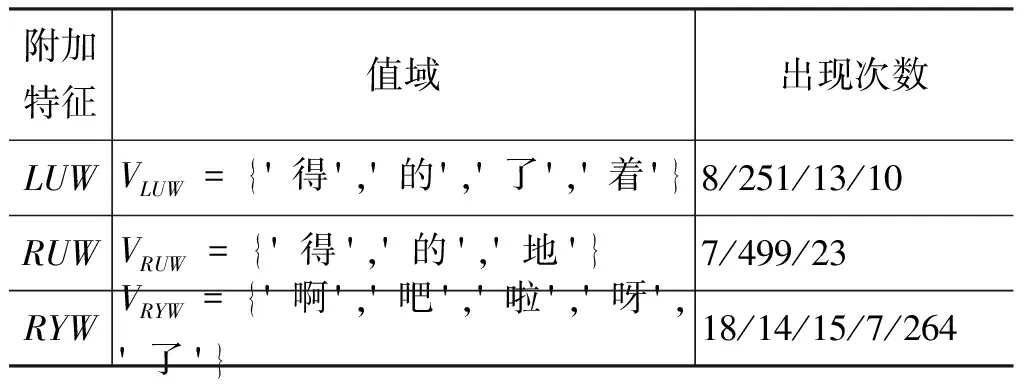
表4 “好”的附加特征

3.3 “好”的决策规则
从表5所列的6条规则来看,十分符合实际情况,说明利用粗糙集抽取的规则能够消除一定的语义模糊性。
3.4 “好”的特征组合概率
27条规则很难覆盖词语“好”发生的所有语言现

表5 “好”的决策规则
象。当无法匹配到任何规则时,使用贝叶斯分类方法消除“好”的语义模糊性。
将表5中的规则前件转化为特征组合F, 根据算法4计算这些特征组合下的词语情感倾向,并补充其他两条规则不能覆盖的特征组合情况,如表6所示。σmax=0.5, 第5个和第6个如果不考虑标准差则导致误判,前6个特征组合的识别结果与表5完全一致。贝叶斯分类器对最后两个特征组合也能够正确判断。对于F={RV,LUW(′了′)}, 例如,“休息 完 了 好 学习”中的“好”仅仅表达“可以”的意思;对于F={LD,RYW(′啊′)}, 例如,“很 好 啊”中的“好”表达褒义情感。

表6 “好”的特征组合概率
3.5 “好”字句的情感分析
将句子中含有“好”字的句子称为“好”字句。分词和词性标注后如果含有独立的词语“好”,则需要消除“好”的语义模糊性。通过更新“好”的词性标记来实现,见算法5,如果词性标记为NULL,则说明“好”不体现褒义情感,否则为褒义词。
句子中其他情感词语采用一般方法处理。图2给出了“好”字句的情感分析流程。

算法5 更新“好”的词性标记输入:不相容决策表DT=(U,C∪D,V,f),特征组合F输出:“好”的词性标记POS(′好′)(1)(2)(3)(4)(5)根据DT使用粗糙集属性约简生成决策规则;根据DT生成贝叶斯分类器;如果F和某条决策规则匹配,当规则后件l=1时,POS(′好′)=′a′,否则POS(′好′)=′NULL′;转至第(5)步;根据F和贝叶斯分类器,如果l=1时,POS(′好′)=′a′,否则POS(′好′)=′NULL′;返回POS(′好′)。

图2 “好”字句的情感分析
4 实验结果与分析
4.1 实验数据 实验数据有COAE2012[17]任务1的数据集,记作COAE,分别标注了来源于电子和汽车两个领域的1 200条句子;SEMEVAL2010[18]任务18的数据集,记作SEMEVAL,主要是含有情感歧义形容词的句子,共计2 917条;中科院谭松波提供的情感语料*http://www.searchforum.org.cn/tansongbo/senti_corpus.jsp,本文使用了其中正负类各2 000篇的书籍和电脑评论语料,记作TAN。详细信息如表7所示。

表7 语料统计情况
从表7可以看出,“好”字句在三个语料中的出现比例分别约为0.2、0.1和0.4。COAE和TAN涉及的都是产品评论,“好”出现的情况要明显多于SEMEVAL。此外,这些“好”字句中的“好”绝大部分都是独立成词,比例达到90%。
以COAE的525条“好”字句为例,用ICTCLAS分词得到词序列,对这些词序列中“好”的相邻信息进行统计,采用IBM Word Cloud*http://www-958.ibm.com/software/data/cognos/manyeyes/page/Word_Cloud_Generator.html展示如图3所示。

图3 COAE语料上“好”的词云图
图3表明程度副词修饰“好”的情况出现最多,而容易产生歧义的“最好”、“还好”、“要好”也十分明显。此外,“好”和动词搭配的情况也不少,由于各个动词不一样,词云图上不够突出。该图也进一步说明了研究强语义模糊性情感词语的必要性。
4.2 实验设置
预处理: 采用ICTCLAS分词和词性标注,并利用标点(不含顿号和引号)切分子句。
情感词典: 在情感词汇本体[19]基础上,加入自己根据《学生褒贬义词典》整理的中文褒贬词*http://tjzhifei.github.io/resources/bbycd.zip,并补充一些日常用语,最终得到含有28 567个条目的褒贬词典。
否定副词: 否定副词的出现会改变情感倾向,仅考虑情感词语周围3个词之内的否定副词,共计65个。
程度副词: 程度副词会加强或者减弱情感,仅考虑情感词语周围3个词之内的程度副词,但不改变情感倾向,共计140个。
特殊句式: 对于让步和转折句,不考虑让步部分的情感,仅考虑转折部分的情感;对于假设、目的和条件句,不考虑体现的情感。本文中表转折的词12个,表让步的词6个,表假设的词20个,表目的和条件的词分别是4个和6个。
评价指标: 对“好”字句进行情感分类,采用精确率 Pre 、召回率 Rec 和 F1值三个评价指标(此处均为微平均)。
情感分析方法: 实验使用了四种情感分析方法。两种基准方法是简单的情感值求和(记作Baseline1)、融合特殊句式的情感值求和(记作Baseline2)[20]。这两种方法均考虑了否定副词和程度副词,但是后者还考虑了特殊句式。在这两种基准方法的基础上,加入消除“好”的语义模糊性过程得到对应的两种方法,记作Defuzz1和Defuzz2。
4.3 实验结果
4.3.1 Baseline1和Defuzz1的性能比较
将三个语料整合为一个全语料,记作ALL。Baseline1和Defuzz1在全部4个语料上的分类结果如图4所示。

图4 Baseline1和Defuzz1的比较
在4个语料上,Defuzz1的各项指标都不低于Baseline1。从全语料ALL上看,Defuzz1的 F1值高出Baseline1约两个百分点。主要原因在于Defuzz1消除了“好”的语义模糊性,例如,Defuzz1能够正确识别如下例子,但是Baseline1却因为“好/a”的出现而误判。
那/r 就/d 考虑/v 好/a 了/y
传阅/v 了/u 好/a 一阵子/m
配/v 好/a 多/a 小/a 配件/n
已经/d 写/v 好/a 的/u 代码/n
注: 均来自实验数据集中真实句子的ICTCLAS分词结果。
4.3.2 Baseline2和Defuzz2的性能比较
Baseline2和Defuzz2在全部4个语料上的分类结果如图5所示,显然Defuzz2的各项指标均要高于Baseline2。从全语料ALL来看,Defuzz2的 F1值高出Baseline2约1.5个百分点。对于上一节的例子,Defuzz2能够正确识别,但是Baseline2不能。
对于实验效果,补充两点: 在SEMEVAL语料上的分类效果不是很令人满意,主要是因为该语料主要用于情感歧义形容词(如“高”、“低”、“大”、“小”等)的分析,而这四种方法均未处理; 融入特殊句式的情感求和要优于一般的情感求和,即Baseline2优于Baseline1,Defuzz2优于Defuzz1。
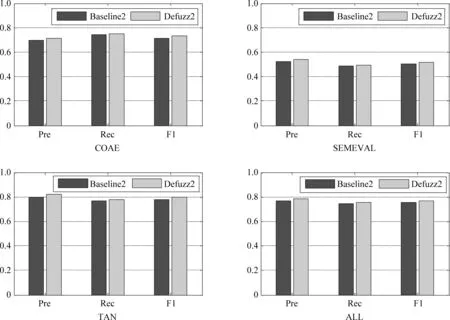
图5 Baseline2和Defuzz2的比较
4.3.3 决策表决策属性值标注的一致性
算法1基于词语的倾向与句子保持一致的假设来设定决策属性值。为了说明这一假设的合理性,借助标注者间可信度来评估,本文采用Cohen的kappa指标[21]:
(14)
其中,Pr(a) 是观测一致性,Pr(e) 是期望一致性。
实验中认为有两个标注者: 基于假设的标注(记作H)和基于消除语义模糊性的标注(记作D)。
两个标注者间的列联表,如表8所示(由于“好”的左右会出现未定义的特征,所以该表中的总数2 505低于表7中的“好”字句总数)。

表8 列联表
公式(14)中的 Pr(a) 和 Pr(e) 分别计算如式(15)和(16)所示。
(15)
(16)
于是Pr(a)=0.7,κ=0.345, 即两个标注的一致程度为70%,可信程度为0.345。
5 结论
消除情感词语的语义模糊性能够帮助确定其体现的感情色彩。本文提出了一种基于规则和统计的消除语义模糊性的框架,主要过程如下:
(1) 特征表示: 对相邻信息进行阈值过滤,抽取基本特征和附加特征并构造决策表。
(2) 粗糙集规则生成: 将不相容决策表转化为相容决策表;对相容决策表进行属性约简,生成决策规则;使用支持度和覆盖度对规则过滤生成最终的规则。
(3) 贝叶斯分类: 根据不相容决策表计算基本特征和附加特征的先验概率;脱离特征独立性假设,计算特征组合出现的后验概率;通过标准差度量后验概率的差异程度,并结合最大后验概率进行分类。
情感词语“好”在汉语中频繁使用,且具有很强的语义模糊性。本文以“好”为例具体阐述消除语义模糊性的方法,实验表明所提的方法可以提高情感分析效果。
由于强语义模糊性词语决策属性值标注的可信度不高,因此如何更为准确地标注情感倾向(非人工细粒度标注)值得进一步研究。此外,使用拓展的粗糙集模型(如概率粗糙集)直接对不相容决策表进行处理,在生成确定性规则的同时生成不确定性规则,不确定性规则也将有助于消除语义模糊性。
[1] 姚天昉, 程希文,徐飞玉. 文本意见挖掘综述[J]. 中文信息学报, 2008, 22(3): 71-80.
[2] 赵妍妍, 秦兵, 刘挺. 文本情感分析[J]. 软件学报, 2010, 21(8): 1834-1848.
[3] Bollen J, Mao HN, Zeng XJ. Twitter Mood Predicts the Stock Market [J]. Journal of Computational Science, 2011, 2(1): 1-8.
[4] Tumasjan A, Sprenger TO, Sandner PG, et al. Predicting Elections with Twitter: What 140 Characters Reveal about Political Sentiment[C]//Proceedings of the 4th International AAAI Conference on Weblogs and Social Media, 2010: 178-185.
[5] Liu ZY, Chen XX, Sun MS. Mining the Interests of Chinese Microbloggers via Keyword Extraction [J]. Frontiers of Computer Science, 2012, 6(1): 76-87.
[6] Pang B, Lee L. Opinion Mining and Sentiment Analysis [M]. Foundations and Trends in Information Retrieval, 2008, 2(1-2): 1-135.
[7] Liu B. Sentiment Analysis and Opinion Mining [M]. Synthesis Lectures on Human Language Technologies, 2012, 16: 1-167.
[8] Narayanan R, Liu B, Choudhary A. Sentiment Analysis of Conditional Sentences[C]//Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing, 2009: 180-189.
[9] 杨源, 林鸿飞. 基于产品属性的条件句倾向性分析[J]. 中文信息学报, 2011, 25(3): 86-92.
[10] Ganapathibhotla M, Liu B. Mining Opinions in Comparative Sentences[C]//Proceedings of the 22nd International Conference on Computational Linguistics, 2008: 241-248.
[11] 黄小江,万小军,杨建武,等. 汉语比较句识别研究[J]. 中文信息学报, 2008, 22(5): 30-38.
[12] 孙秋秋. “好”在语义上的模糊性与确定性[J]. 辽宁大学学报(哲学社会科学版), 1982, 1: 70-76.
[13] 朱嫣岚,闵锦, 周雅倩,等. 基于HowNet的词汇语义倾向计算[J]. 中文信息学报, 2006, 20(1): 14-20.
[14] 陈岳峰,苗夺谦,李文,等. 基于概念的词语情感倾向识别方法[J]. 智能系统学报, 2011, 6(6): 489-494.
[15] 张志飞, 苗夺谦. 基于粗糙集的文本分类特征选择算法[J]. 智能系统学报, 2009, 4(5): 453-457.
[16] 苗夺谦, 李道国. 粗糙集理论、算法与应用[M]. 北京: 清华大学出版社, 2008.
[17] 刘康, 王素格, 廖祥文, 等. 第四届中文倾向性分析评测总体报告[R]. 第四届中文倾向性分析评测论文集, 2012: 1-32.
[18] Wu YF, Jin P. SemEval 2010 Task 18: Disambiguating Sentiment Ambiguous Adjectives[C]//Proceedings of the 2010 Evaluation Exercises on Semantic Evaluation, 2010: 81-85.
[19] 徐琳宏, 林鸿飞, 潘宇, 等. 情感词汇本体的构造[J]. 情报学报, 2008, 27(2): 180-185.
[20] 张志飞,李飏,卫志华,等.中文否定句的情感倾向性分析[R].第五届中文倾向性评测论文集,2013:111-120.
[21] Cohen J. A Coefficient of Agreement for Nominal Scales [J]. Educational and Psychological Measurement, 1960, 20(1): 37-46.
Sentiment Analysis with Words of Strong Semantic Fuzziness
ZHANG Zhifei1,3, MIAO Duoqian1, YUE Xiaodong2, NIE Jian-Yun3
(1. Department of Computer Science and Technology, Tongji University, Shanghai 201804, China; 2. School of Computer Engineering and Science, Shanghai University, Shanghai 200444, China; 3. Department of Computer Science and Operations Research, University of Montreal, Montreal, Canada)
Some frequent sentiment words have strong semantic fuzziness, i.e., have ambiguous sentiment polarities. These words are particularly problematic in word-based sentiment analysis. In this paper, we design an approach to deal with this problem by combining rough set theory and Bayesian classification. To determine the sentiment polarity of a fuzzy word, we use a set of features extracted from its context of utilization. Decision rules based on the features are derived using rough sets. In case the rules fail to classify a case, a Bayes classifier is used as complement. We investigate the case of “HAO” in Chinese—a very frequent sentiment word, but with many different meanings. The experimental results on several datasets show that our combined method can effectively cope with the semantic fuzziness of the word and improve the quality of sentiment analysis.
sentiment analysis; semantic fuzziness; rough set theory; Bayesian classification

张志飞(1986—),博士,博士后,主要研究领域为自然语言处理和情感分析。E⁃mail:tjzhifei@163.com苗夺谦(1964—),博士,教授,主要研究领域为粒计算和机器学习。E⁃mail:dqmiao@tongji.edu.cn岳晓冬(1980-),博士,讲师,主要研究领域为软计算和数据挖掘。E⁃mail:yswantfly@gmail.com
1003-0077(2015)02-0068-11
2013-06-27 定稿日期: 2013-10-22
国家自然科学基金(61273304,61103067);高等学校博士学科点专项科研基金(20130072130004)
TP391
A
