基于依存句法关系的文本情感分类研究
2015-04-16张庆庆刘西林
张庆庆,刘西林
ZHANG Qingqing,LIU Xilin
西北工业大学 管理学院 管理科学与工程系,西安710129
School of Management,Northwestern Polytechnical University,Xi’an 710129,China
1 引言
基于机器学习的文本情感分类技术有两个重要步骤,文本表示和分类器的使用。经典的文本表示模型——向量空间模型,俗称“词袋”模型在信息检索、主题分类取得不错的效果。然而这种模型把文本看作是无序的词汇组合,忽略了词与词之间的顺序信息和句子语义信息,已不能满足文本情感分类任务的需求。为了使得一种文本表示方法包含更多的语义信息,很多研究基于“词袋”模型,借助于人工特征工程,在已有特征基础上不断添加新特征。其中一类与句法相关,着重句子的个体组成成份和他们的排列顺利,如二元词(bigram)、多元词(n-gram)、词性、标点符号等[1-3],也有在其基础上构建组合较复杂的特征[4-6]。利用情感词典计算情感得分判断文本情感极性作为一种快速粗略判断方法切实可行,但准确率提高受到限制。一些学者则结合文本情感词典构造特征作为文本表示特征向量的一部分[7-8]。除此以外,依存句法关系是近年来的研究热点,它通过对语言单位内成分之间的依存关系揭示其句法结构,指出词语之间的搭配关系。有学者从依存解析树中提出了树深度、句法类别、分枝数量等作为特征[9],也有学者利用依存关系和词性信息组合确定消息极性[10]。然后某些特征构建复杂,基于“词袋”框架上,某些特征对分类影响不大。
文本情感分类任务中分类器的选择也是关键的一步,常用分类器有朴素贝叶斯(Naïve Bayes)、最大熵(Maximum Entropy)和支持向量机(Support Vector Machine)等[11-13]。而支持向量机被普遍认为分类精度高于其他分类器。近年来用于文本情感分类最新的技术是深度学习。深度学习是一种强大的特征学习工具,它通过多隐层的非线性映射学习到输入数据的深层特征表示。其中,深度信念网络(Deep Belief Network)通过波尔兹曼机预训练和后向传播算法进行微调,从输入结点学习一种深层的输入数据的表示[14],已在多个领域取得很好的效果。在文本情感分类领域也有应用,如Duyu Tang 等从微博数据中抽取一元词、标点符号、情感词典、拟声词、功能词作为基本特征,用于为深度信念网络的输入[15],取得不错的分类效果;Xiao Sun 将文本信息的特征与社交网络的特征用于深度信念网络,并应用于中文微博的情感分类中[16],分类结果均得到明显提高。所以,语义丰富的文本表示方法用深度神经网络可以得到更好的应用。
为了提高文本情感分类精度,本文提出一种三元组文本表示方法。从句子的依存解析树出发,通过合并与删除冗余结点,得到用于文本表示的三元组依存关系特征。为了检验此种文本表示方法的有效性,同时构造了以一元词特征为基础,在其上添加由二元词、词性、标点符号构成的句法特征,结合情感词典的词典得分和从依存句法树中抽取的简单依存关系特征的组合特征表示方法。将本文的三元组依存关系特征向量和以一元词为基础的组合特征向量用于支持向量机和深度信念网络中,探索三元组依存关系特征文本表示方法对中文文本情感分类研究的作用和影响。
2 方法介绍
2.1 三元组依存关系表示形式
一篇文档一般由多个句子组成。给定一篇由n个句子组成的文档D,表示为:
D=[S1,S2,…,Sn]
对单个句子Si进行分词,则句子变换为由离散的一系列单词和标点符号组成的向量,即:
Si=[t1,t2,…,tm]
tk为组成句子成分的词或标点符号。对于单句Si,经过句法依存解析器解析后,得到:
Gi=(Si,Ei)
Ei对应着Si所有的边集合:Ei={e1,e2,…,ek}
对于任意的ej用三元组表示,是依存解析树中的支配词(governor),一般为修饰部分,是连接两结点的关系(relation),是依存解析树的从属词(dependent)。
那么,一元词特征和二元词特征用以上符号表示为:
unigram(Si)={(t1),(t2),…,(tm)}
bigram(Si)={(t1,t2),(t2,t3),…,(tm-1,tm)}
用treegram表示三元组依存关系特征,则得到:
以句子S=“周围环境还可以比较安静”为例,用上述符号来表示。分词后,得到S=[周围 环境 还 可以 比较 安静]
在分词的基础上得到依存树结构如图1 所示。
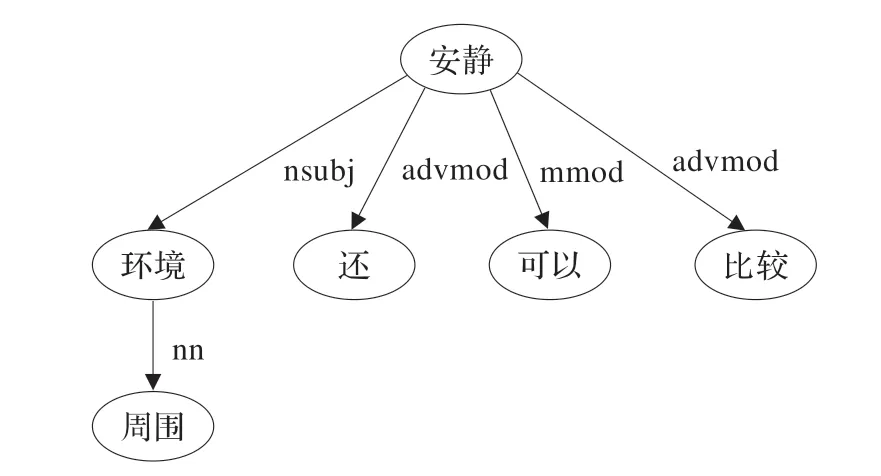
图1 “周围环境还可以比较安静”的依存解析树
由图1 得到treegram向量为:

2.2 三元组依存关系特征构成方法
三元组依存关系特征在句子的完整依存解析树上进行。为了压缩特征空间并且得到有效的特征项,对得到的依存解析树做以下处理:先在完整依存树基础上根据一定的规则对树结构中某些结点进行删除和合并,再对保留下来的树结构进行三元组转换,最后为了保证所得特征的泛化能力,对保留的三元组关系特征进行一般化处理。
2.2.1 结点的删除与合并
得到的原始特征中存在着大量的无用和冗余信息,结合中文语法特点制定相应规则,删掉和融合一部分不影响文本情感表达的结点。所使用的规则如下:(1)合并由名词修饰关系nn 连接的两个结点,见例子“大堂环境比较差”一句的依存解析分析。(2)合并由conj 连接的两个名词结点。(3)删除由关系从句关系rcmod 连接的修饰部分,以句子“该酒店对去上海旅游或公务的人都很合适”为例。
句子“大堂环境比较差”,其依存解析树见图2。
关系:环境→大堂,“环境”和“大堂”都为名词,而他们之间的关系为名词修饰语“nn”的关系。(环境,nn,大堂)这样的特征对整个句子情感表达是没有作用的,故合并由名词修饰语“nn”连接的两个结点,合并前后依存解析树如图2 和图3 所示。同理,对于“conj”连接的关系也作同样的处理。
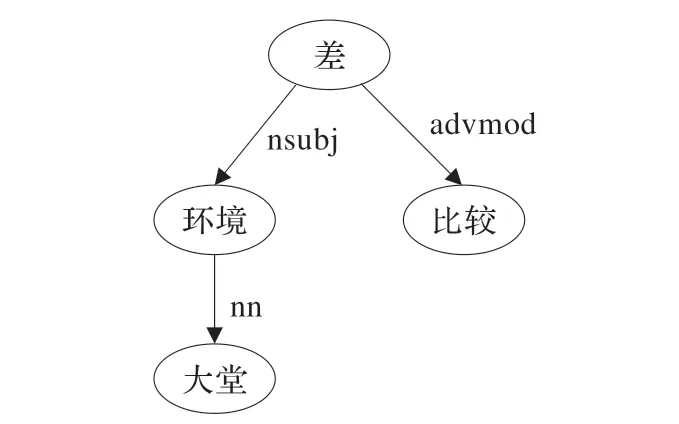
图2 “大堂环境比较差”依存解析树
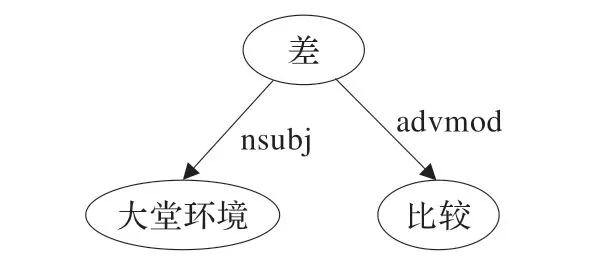
图3 合并结点后的依存解析树
句子“该酒店对去上海旅游或公务的人都很合适”的依存解析树如图4 所示。
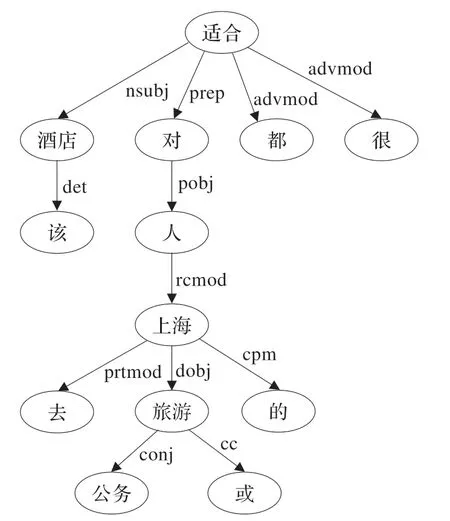
图4 “该酒店对去上海旅游或公务的人都很合适”的依存解析树
“去上海公务或旅游”是对“人”的修饰,这部分不影响整个句子情感倾向的改变。删掉由关系从句修饰“rcmod”连接的依存部分,变换为图5 所示依存解析树。
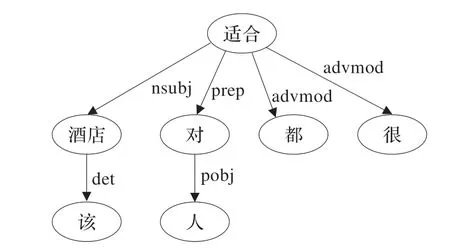
图5 删除结点后的依存解析树
根据以上方法,在得到原句依存解析树基础上执行删除结点和合并结点操作。合并结点在删除结点操作完成之后进行,删除结点与合并结点算法和流程如图6和图7 所示。

图6 删除结点算法

图7 合并结点算法
2.2.2 一般化
为了使得到的特征更具有普遍性,采用通配符策略,且对每个三元组关系分别采用一元通配符和二元通配符的策略。如对于(安静,nsubj,环境),采用一元通配符可以得到以下三个一般化特征项:
1.(*,nsubj,环境)
2.(安静,*,环境)
3.(安静,nsubi,*)
运用二元通配符可以得到:
4.(安静,*,*)
5.(*,*,环境)
6.(*,nsubj,*)
特征6 表示文本中此种关系是否存在,此含义已经在前三条特征中包含,为避免无意义特征,此条忽略。
3 实验
3.1 数据和实验设计
实验数据来源于网上研究学者收集整理的酒店评论语料,语料从携程网采集整理而成(http://www.datatang.com/data/11936)。本文在原有数据基础上重新做了断句处理和类别标注。去除重复和无意义的句子后,从中随机选择正向评论语句4 000 条,负向评论语句4 000 条。
对选定的句子采用中国科学院编写的中文分词工具NLPIR 对评论文本进行分词、词性标注(http://ictclas.nlpir.org/)。在分词和词性标注的文本基础上实施两种处理方式。一种是使用斯坦福大学提供的Stanford Parser 工具包对每个文本进行依存句法解析[17]得到依存解析树,并根据本文所提方法构造出三元组依存关系特征。一种是提取出一元词特征、句法特征、简单依存关系特征、词典得分。其中,句法特征由二元词、词性和标点符号组成。简单依存关系特征,即只是表示依存关系不带从属词和依赖词的标识。词典得分,利用台湾大学提供的中文情感词典,通过词典中词条匹配,找到此句中所有含有情感表达的词,用含有正向情感表达词的个数减去还有负向情感表达词的个数的最终得分作为特征值。公式如下:
Polar(S)=Sum(Postive)-Sum(negative)
为了避免特征冗余造成的向量空间维数过大从而影响分类效果,根据信息增益公式计算每个特征的信息增益分数,选择分数靠前的1 000、2 000、4 000、6 000、8 000、10 000、12 000、14 000 的特征项,以此作为特征向量从而构造所有文本的向量表示,特征值采用二进制表示方法,即特征项出现为“1”,不出现为“0”。
将得到的文本向量分别用于支持向量机和深度信念网络中,实验流程图如图8 所示。
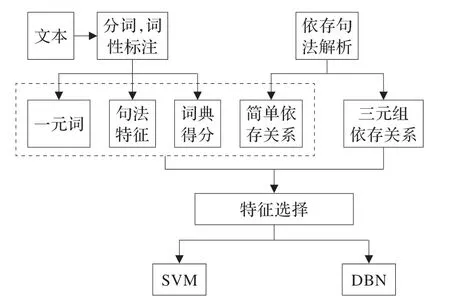
图8 实验流程图
实验的评价指标采用目前文本情感分类领域常用的评价指标:平均分类精度(Average Accuracy),其分类精度指标定义如下:
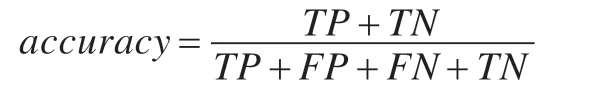
上式中TP(True Positive)表示分类模型正确预测的正样本数,TN(True Negative)表示分类模型正确预测的负样本数,FP(False Positive)表示分类模型错误预测的正样本数,FN(False Negative)表示分类模型错误预测的负样本数。
所选特征用于支持向量机和深度信念网络进行结果比较。
3.2 结果分析
根据以上实验流程,对文本进行分词、词性标注后,一元词7 076 个,句法特征43 108 个,简单依存关系特征45 个,词典得分7 个。为了比较不同特征对分类精度的影响,把一元词作为基准特征,依次加上其余特征。分别用F1、F2、F3、F4 表示一元词、句法特征、简单依存关系特征和词典得分。三元组依存关系特征用treegram表示,总共得到140 911 个。
3.2.1 支持向量机分类结果比较
本实验采用Joachims 编写的SVM_Light 工具箱(http://www.cs.cornell.edu/People/tj/svm_light/)对 文 本数据进行支持向量机分类,参数系统默认。结果如表1所示。
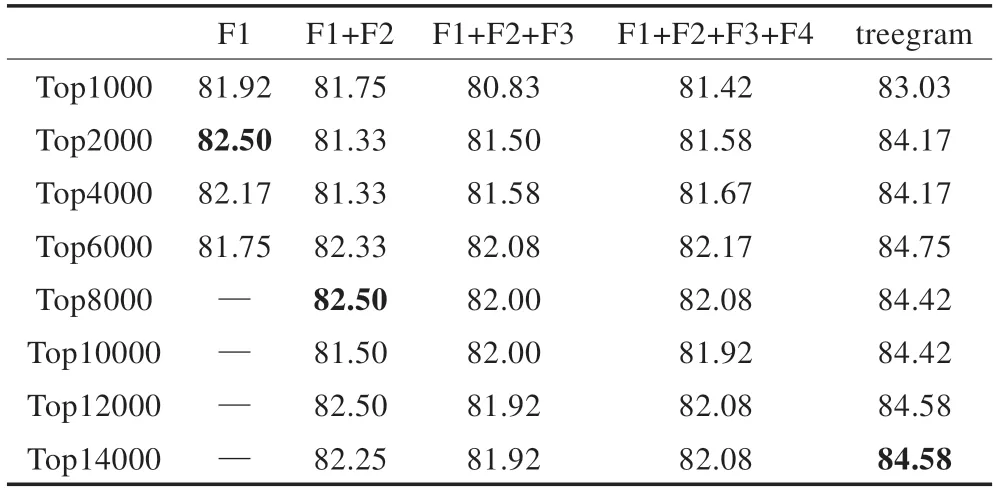
表1 支持向量机分类结果比较 %
从表1 可以看出,三元组依存关系特征的分类最高精度达到84.58%,而一元词、句法特征、简单依存关系特征和词典得分最高精度只达到82.50%,且其他类特征的加入并没有明显给分类精度带来影响。而三元组依存关系特征在整体上提高了文本分类精度,进一步说明三元组依存关系特征文本表示方法的有效性。
3.2.2 深度信念网络分类结果比较
深度信念网络借助于Hinton 教授提供的深度学习工具箱(http://www.cs.toronto.edu/~hinton/)。特征约减后的特征向量作为深度信念网络的输入,经过多次不同DBN 网络结构比较,对于输入为1 000 维的特征向量,采用结构1 000-300-100,即隐层结点依次为300、100。对于其他输入维度,采用结果X-600-300,其中,X表示输入维数,600、300 分别为第一、二隐层结点数。深度信念网络训练过程中参数设置为:限制波尔兹曼机的动量为0.9,学习速率为0.01,微调部分的激活函数为sigmoid函数,学习速率为0.9,动量为0.5,其他为深度学习工具箱默认参数,结果如表2 所示。
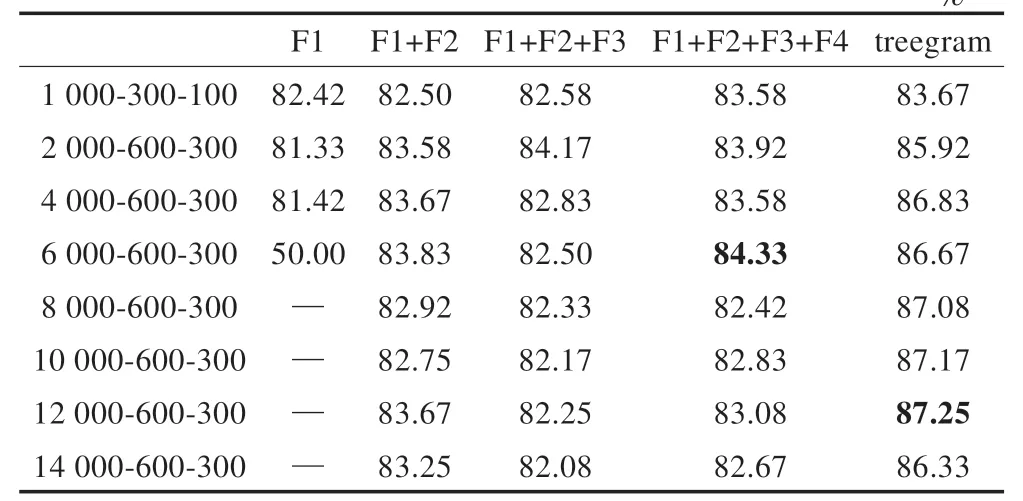
表2 深度信念网络分类结果比较 %
从表2 明显看出,基于深度信念网络的三元组依存关系特征的分类精度上超过了其他特征及其特征组合,最高达到87.25%。而其他组合特征在全部特征组合特征维度为6 000 时达到最高84.33%。
从表1 和表2 整体情况来看,相同维度的特征向量下,基于深度信念网络的分类精度均高于基于支持向量机的文本情感分类精度,不仅验证了深度学习有很强的特征学习能力,更重要的是说明了三元组依存关系文本表示方法蕴含更深层次的文本语义信息,在进行分类时有更高的分类精度。
4 结束语
本文从依存句法关系的角度,结合中文语法表达习惯,以不影响句子情感表达为原则,对句子依存解析树进行冗余结点的合并和删除,构造基于依存句法关系的三元组特征表示方法。同时,从文本中抽取构造用于文本表示的一元词、句法特征、简单依存关系特征和词典得分,并进行组合构成不同的文本表示特征空间。将不同的文本表示方法用于支持向量机和深度信念网络进行检验。结果表明无论支持向量机和深度信念网络,三元组依存关系特征的分类精度均超过了一元词,句法特征,简单依存关系和词典得分的组合。充分说明了三元组依存关系文本表示方法考虑了文本中词语之间的语义信息。但此方法用于文本挖掘领域其他任务能否取得较好的效果还有待进一步的研究。
[1] Cambria E,Schuller B,Xia Y,et al.New avenues in opinion mining and sentiment analysis[J].Intelligent Systems IEEE,2013,28(2):15-21.
[2] Gonçalves P,Araújo M,Benevenuto F,et al.Comparing and combining sentiment analysis methods[C]//Proceedings of first ACM Conference Online Social Network,DOI:10.1145/2512938.2512951.
[3] Abbasi A,France S,Zhang Z,et al.Selecting attributes for sentiment classification using feature relation networks[J].IEEE Transactions on Knowledge & Data Engineering,2010,23(3):447-462.
[4] Gezici G,Yanikoglu B,Tapucu D,et al.New features for sentiment analysis:Do sentences matter?[J].Ceur,2012:5-15.
[5] Genereux M,Santini M.Exploring the use of linguistic features in sentiment analysis[J].Research,2007.
[6] Xia R,Zong C,Li S.Ensemble of feature sets and classification algorithms for sentiment classification[J].Information Sciences,2011,181(6):1138-1152.
[7] Neviarouskaya A,Prendinger H,Ishizuka M.SentiFul:A lexicon for sentiment analysis[J].IEEE Transactions on Affective Computing,2011,2(1):22-36.
[8] Pang B,Lee L.Opinion mining and sentiment analysis[J].Foundations and Trends in Information Retrieval,2008,2(1/2):1-135.
[9] Massung S,Zhai C,Hockenmaier J.Structure parse tree features for text representation[C]//IEEE Seventh International Conference on Semantic Computing,2013:9-16.
[10] Hassan A,Qazvinian v,Radev D.What’s with the attitude?Identifying sentences with attitude in online discussions[C]//Proceedings of 2010 Conference on Empirical Methods in Natural Language Proceedings,2010:1245-1255.
[11] 史伟,王洪伟,何绍义.基于语义的中文在线评论情感分析[J].情报学报,2013,32(8):860-867.
[12] 刘志民,刘鲁.基于机器学习的中文微博情感分类实证研究[J].计算机工程与应用,2012,48(1):1-4.
[13] 夏火松,彭柳艳,余梦麟.自动情感文本分类研究综述[J].情报学报,2011,30(5):530-539.
[14] Bengio Y,Delalleau O.On the expressive power of deep architectures[C]//Proc of the 14th International Conference on Discovery Science,2011:18-36.
[15] Tang D,Qin B,Liu T,et al.Learning sentence representation for emotion classification on microblogs[J].Communications in Computer & Information Science,2013:212-223.
[16] Sun X,Li C,Xu W,et al.Chinese microblog sentiment classification based on deep belief nets with extended multi-modality features[C]//IEEE International Conference on Data Mining Workshop,2014:928-935.
[17] Chang P,Tseng H,Jurafsky D,et al.Discriminative reordering with Chinese grammatical relations features[C]//Proceedings of the Third Workshop on Syntax and Structure in Statistical Translation,2009.
