一种基于粗糙集和欧式距离的手机故障案例匹配算法❋
2015-03-31唐瑞春张肖南郭双乐丁香乾
唐瑞春, 张肖南, 郭双乐, 邱 悦, 丁香乾
(1.中国海洋大学信息科学与工程学院,山东 青岛 266100;2.武汉东方赛思软件有限公司,湖北 武汉;3.滨州学院信息工程系,山东 滨州 256600;4.北京三快在线科技有限公司,北京 朝阳区 100000)
一种基于粗糙集和欧式距离的手机故障案例匹配算法❋
唐瑞春1, 张肖南2, 郭双乐3, 邱 悦4, 丁香乾1
(1.中国海洋大学信息科学与工程学院,山东 青岛 266100;2.武汉东方赛思软件有限公司,湖北 武汉;3.滨州学院信息工程系,山东 滨州 256600;4.北京三快在线科技有限公司,北京 朝阳区 100000)
本文研究在云环境中手机故障案例检索时的案例匹配问题,提出了一种基于粗糙集和欧式距离的案例相似度匹配算法CMARE(Case Matching Algorithm based on Rough sets and Euclidean distance)。首先云计算平台收集手机故障参数,根据参数构建粗糙集信息表,利用粗糙集求出信息表里各案例特征参数的属性客观权重值并结合专家经验给出综合的属性权重值,最后利用此权重值和欧式距离计算案例间的相似度,找出案例库中与新案例最相似的案例。该算法的创新之处在于确定案例属性权重值时基于数据本身和人工经验,避免了过分依靠人工经验知识设定属性权重的不足;与规则推理方式不同,本文使用案例推理的方式。仿真实例说明了算法的有效性。
手机故障检索;粗糙集;欧式距离;信息表
随着相关技术的发展,手机的结构越来越复杂,功能越来越完善,智能化程度也越来越高。手机在使用过程中也会出现各种故障,当前,人工智能领域中没有专门针对手机的故障诊断方法,手机故障点的查找都是依靠人工查找,往往会出现误诊或者漏诊,其准确性有待进一步提高。
随着移动互联网和云计算的发展,手机可以与云计算平台更好的交互,从而可以利用云计算平台辅助手机故障的诊断。利用云计算环境收集手机运行时的参数,在云平台上与已有的故障案例进行相似度的计算,依据相似度的高低对新故障进行推理,从而能够在故障发生时进行有效的分析和处理,这对于故障点的确定有着重要的意义。
基于案例的推理即CBR(Case Based Reasoning),核心思想是使用过去人们解决问题的经验解决新问题,它需要研究以往的案例库,如果无法在案例库中找到与当前案例相同的案例,则需要找到一个与当前情况最相似的案例。CBR由4个基本过程组成—4R循环:Retrieve、Reuse、Revise、Retain,分别对应着案例的检索、重用、改编和保存(学习)[1]。
CBR在故障推理和预测工作中有着广泛的应用。文献[2]提出了使用云计算平台云景,通过CBR推理的方式来预测大型风力发电机故障;文献[3]将CBR推理应用到了飞机故障预测系统中,同时结合了故障树的方式,逐步完善数据库,提高了案例库的准确度。事例的检索和选择是CBR系统的一个关键步骤,也是CBR系统技术实现研究的一个热点问题。文献[4]研究了在进行相似度检索时使用最近相邻法来进行案例检索,利用海明距离(Hamming Distance)来计算相似度;文献[5]中在使用CBR进行故障推理时使用欧式距离(Euclidean Distance)来计算相似度。以上各文献在确定故障案例中各特征的属性权重时都是根据人工经验直接指定,从而引入了人为因素,导致案例检索准确性不够。
为解决上述问题,本文提出了基于知识粒度粗糙集的属性权重计算方法,在结合欧式距离的基础上以知识粒度粗糙集来计算案例中各属性的客观权重值,结合人工经验给出最终的属性权重值,将其应用到手机故障案例匹配中能够提高案例匹配的精确度。云计算平台收集手机运行时的状态参数,提取故障参数并创建新案例,云平台根据故障参数构建决策表,利用决策表计算各参数代表的属性权重值,之后结合人工经验给出最终的属性权重值;在计算相似度时利用欧式距离求案例的相似度,并结合决策表求出的属性权重值,从而得到更准确的相似度结果。
1 相关研究
1.1 研究环境
如图1所示,手机故障案例的检索主要在云计算平台上完成,手机运行时的故障特征参数作为输入。在服务器端,收集到手机运行时的参数并保存,权重计算模块会根据故障特征参数,从云存储的案例库中选出相关的案例集,组成信息表并进行权重计算,之后进行案例的匹配计算。

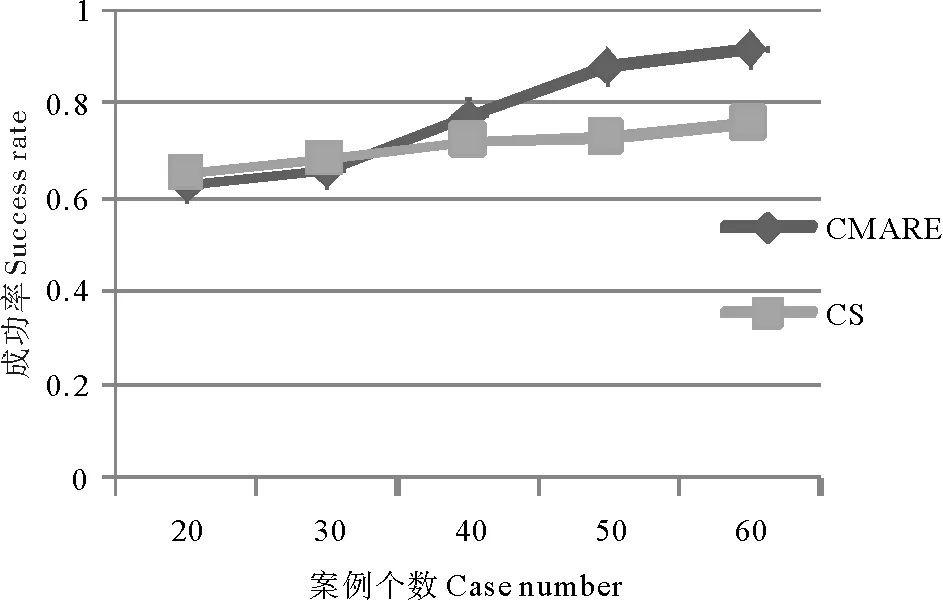
图1 基于粗糙集和欧式距离的相似度检索算法应用环境
1.2 基于粗糙集和欧式距离的CBR模型
CBR模型广泛应用在案例推理与故障预测中,模型如图2所示,CBR是模拟人脑类比学习的过程。常见的CBR模型有高斯案例推理预测模型和贝叶斯案例推理模型等。
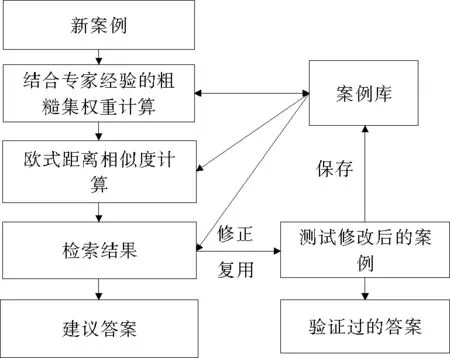
图2 基于粗糙集和欧式距离的CBR模型
基于粗糙集与欧式距离的CBR案例匹配过程为:对新出现的故障案例,首先在案例库中查找到相关的案例构建决策表,利用知识粒度粗糙集求出决策表中的客观属性权重值并结合专家经验给出最终权重值,利用欧式距离求出新产生的案例与案例库中的案例最为匹配的案例,最后将检索到的结果返回。
2 CMARE算法
2.1 基于粗糙集的属性权重确定
对于手机而言,故障工作状态参数包括由其操作系统读取的当前工作状态下系统中各项设备的运行状态及特征信号。手机故障征兆指以一定形式表现出来的状态信息,如供电端电压过高或者过低,电容失效等。除了故障工作状态参数和故障征兆外,手机其他信息还包括一些设备及运行信息,如手机型号、CPU处理器型号、运行状态等。手机的这些工作参数通过云计算平台收集起来用于创建新的故障案例。在计算新案例与已有案例的相似度时,各属性的权重值直接影响到相似度的值,获得准确的属性权重值至关重要,因此,计算出权重值是相似度计算的前提。属性的权重将根据案例库中的已有案例计算得出。
手机故障案例库S′可由一个四元组来描述:
S′=(U′,A′,V′,f′)。
(1)
其中:U′为所有的故障案例的集合;A′是案例中所有的故障特征即故障属性的集合;V′是A′中所有属性值的集合;f′是指定U′中每个案例对象属性值的信息函数,f′:U′×A′→V′。
知识粒度粗糙集理论框架,主要研究一个由对象集和属性集构成的信息系统S[6]:
定义1 定义一个知识系统:
S=(U,A,V,f)。
(2)
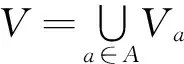
(1)故障案例集U′对应粗糙集理论中的论域U。
(2)故障特征属性A′对应粗糙集理论中的属性集合A。
(3)案例属性值域V′对应粗糙集理论中的值域集合V。
(4)案例与属性之间的关系函数f′对应粗糙集中的关系函数f。
因此,案例库中属性求权重问题可以转换成粗糙集理论中的属性权重值求解问题。在粗糙集中,存在着由关系函数f确定的“属性—值”的二维表,即信息表,案例库中的信息表对应于粗糙集中的决策表。通过求出决策表中各条件属性对应于决策属性的权重值,进而得到不同故障特征对应于故障结果的重要程度。具体在粗糙集中求解如下:
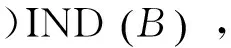
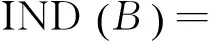
(3)
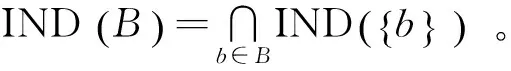
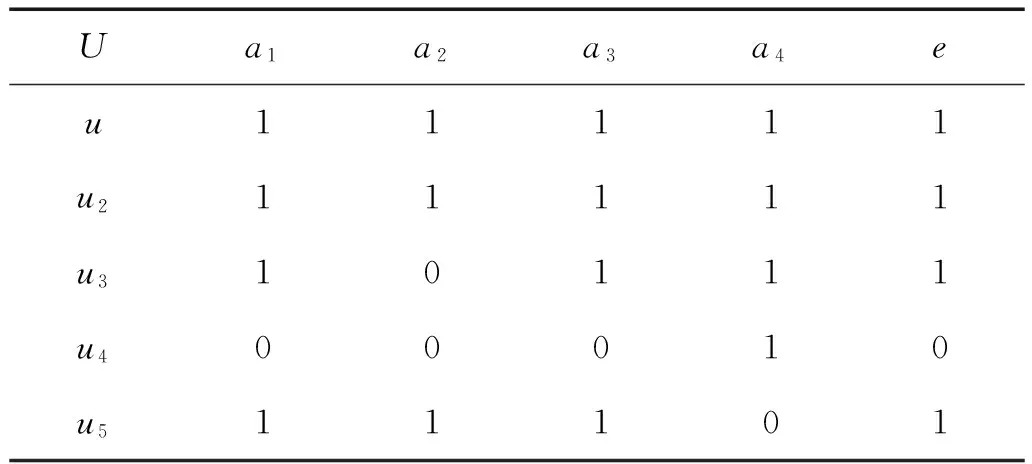
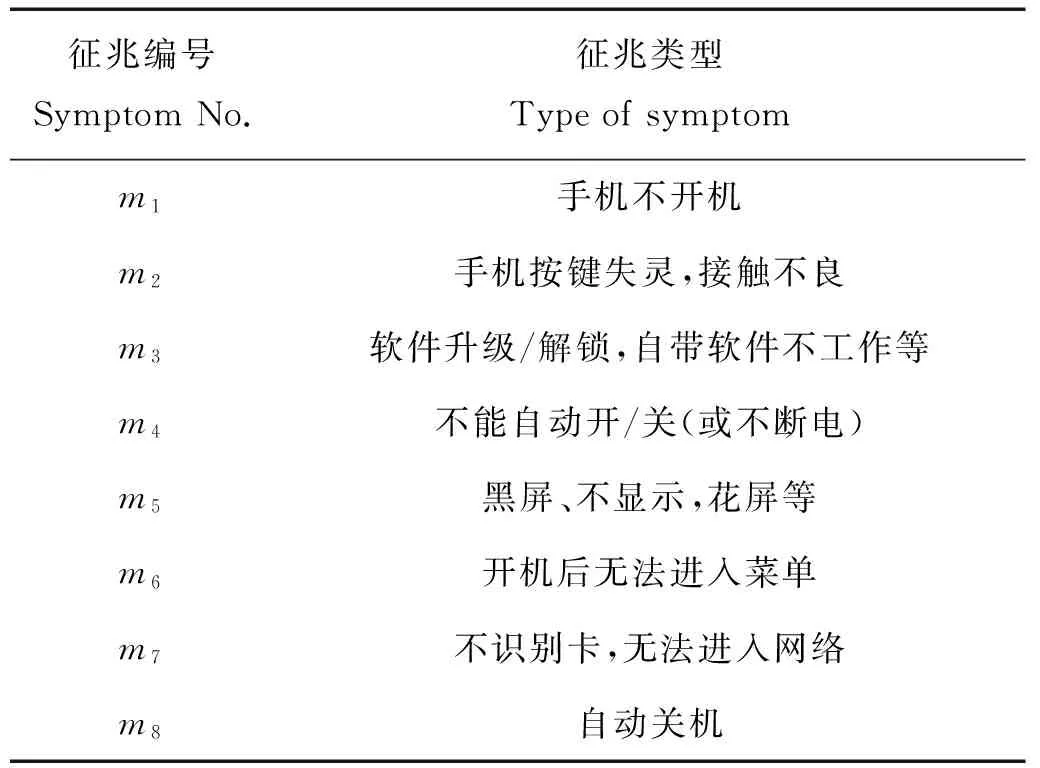
表1 故障集信息系统
属性重要程度:依据知识粒度粗糙集模型,设X⊆A是一属性子集,x∈A为一属性,记x对X的属性重要度为Wx,其定义为[7]:
(4)
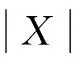
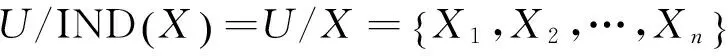
(5)
(6)
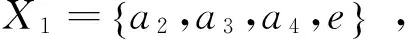
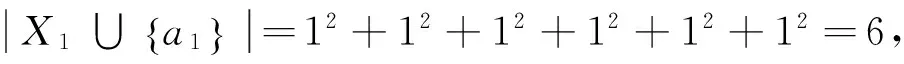
(7)
归一化之后Wi就作为每个属性的客观权重。
在信息系统S=(U,A,V,f)中,条件属性C⊆A中每个属性对于决策属性取值的影响是不同的,应该赋予它们不同的权重。该文给出的最终权重结果有两部分权重组成,一是由大量历史数据体现,并通过知识粒度粗糙集理论处理而得到的客观权重W,二是由专家经验知识直接确定的主观权重P:
(8)
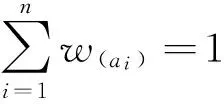
I=∂W+(1-∂)P0≤∂≤1。
(9)
其中:∂为经验因子,0≤∂≤1反映了决策过程中决策者f对客观权重和主观权重的偏好程度:∂越大,表明决策者越重视客观权重;∂越小,表明决策者越重视专家的经验知识。特别地,若∂=1,则决策者只考虑客观权重;若∂=0则决策者只考虑专家的经验知识。在得到综合权重之后,对综合权重再进行归一化处理,即可得到各个属性的最终权重值。
依据信息表求出的各属性权重值,其结果比较客观,再结合专家经验直接给出权重值,求出属性权重值后将权重值带入相似度计算公式,即可以得到案例的相似度结果。
基于粗糙集的属性权重计算过程:
Step1 根据新案例特征属性ai1到ain确定信息表;
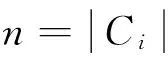
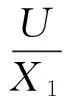
Step4 根据公式(4)计算属性aij的客观权重;
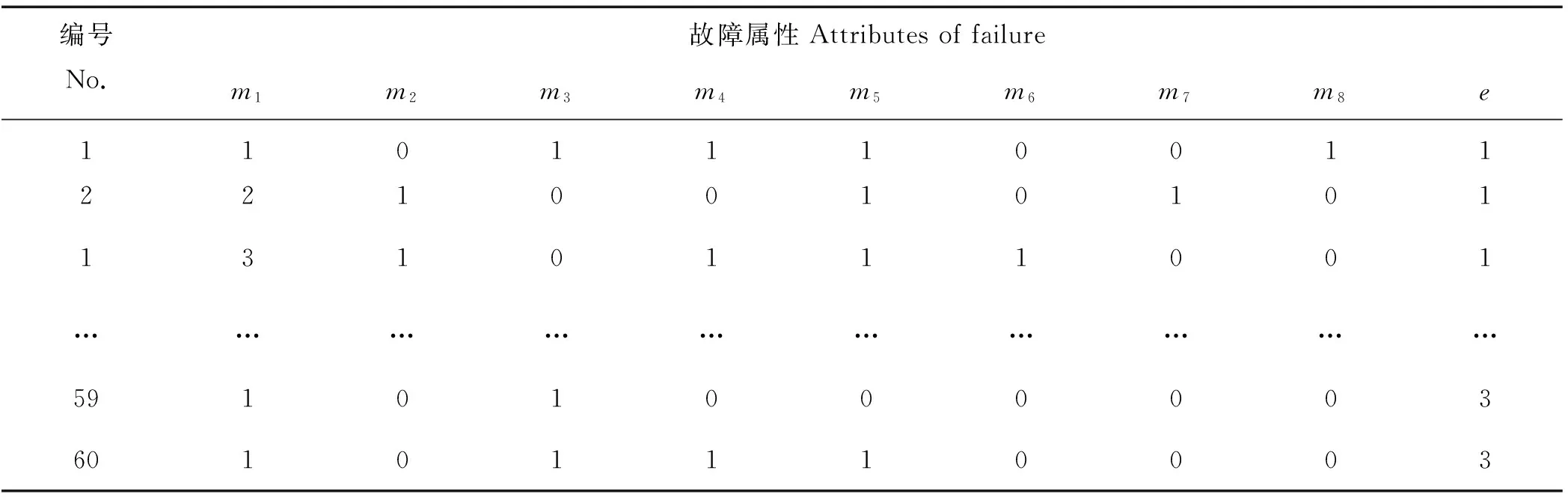
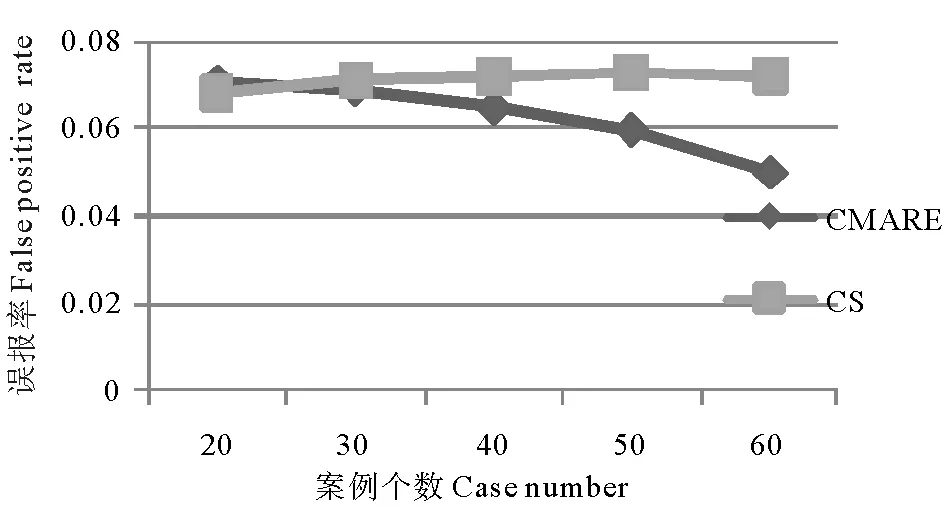
Step5 若j Step6 结合公式(8)设定的权重利用公式(9)计算最终的属性权重值I。 2.2 基于知识粒度粗糙集和欧式距离的案例匹配 (10) 其中d为案例Ci和C0中对应属性的欧式距离,两案例在各属性上的对应分量相同,则其欧式距离为0,其相似度为最高1[8]。 (11) 其中表示案例库中案例的属性值,a0j表示新产生的案例中的属性值,Iaj表示对应属性由粗糙集求出的综合权重值。 案例匹配是在案例库中寻找与当前案例相同或者最相似案例的过程,在收集到新的故障案例时,云平台先去查找案例库中是否存在完全相同的案例,如有直接返回案例结果,如不存在,则利用基于欧式距离的检索算法进行检索计算。本文基于粗糙集和欧式距离的相似度匹配算法过程如下: Step1 提取手机故障征兆并创建新故障案例; Step2 根据故障属性提取故障库案例,并构建信息表; Step3 根据基于粗糙集的属性权重计算算法计算属性权重; Step4 按式(10)计算当前案例与案例库中案例各条件属性的欧式距离; Step5 通过对各条件属性的欧式距离进行加权求案例间的整体相似度,其中权重为Ia1,Ia2,,…,Ian,由Step3求出,相似度计算依据式(11)。在求出新案例与案例库中的案例相似度以后,按照相似度由大到小的顺序排列,设定阈值,将阈值以上相似度最高的结果返回。若结果中没有阈值以上的结果,则认为是案例库中不存在的新故障,将新案例加入案例库,因本文重点在于案例的相似度计算和案例匹配,新案例如何加入案例库部分不再赘述。 先由粗糙集理论来确定属性的权重值,之后利用欧式距离来求两案例的相似度,避免了人工设定权重值主观性,可以使检索结果更具有客观性,也更加准确。 为了验证CMARE算法的有效性,本文选择某手机厂商测试数据为研究目标,使用VC++6.0搭建仿真环境实现算法,利用测试数据中手机运行故障参数和已量化的案例库作为输入,评估CMARE手机故障案例匹配算法的性能。 将手机中常出现的3种故障主板故障、电源故障、软件故障作为研究的对象进行量化:决策属性为1代表手机主板故障,决策属性为2代表电源故障,决策属性为3代表软件故障,其伴随的征兆集合即故障现象量化如表2。 表2 征兆集合列表 表3 手机故障案例决策表 本文选取其中的8种属性进行决策,如果某项征兆出现,则对应的属性我们量化为1,反之量化为0。从手机的测试数据库中选取60组数据作为案例库数据,则手机的故障案例决策表可量化表示如表3。 新案例依据相同的方式进行量化,量化后为一维数组,之后将量化的结果输入查询匹配,并将结果返回。 首先,案例匹配检索的准确性是衡量预测算法成功与否的一个因素。因此,用成功率(Successrate)表示当前系统在同样给定的案例库时,仅仅基于专家设定权重值参数的CS算法和利用粗糙集获取权重值参数的CMARE的正确率(见图3)。 图3 案例检索的准确率 图中CMARE表示基于粗糙集和欧式距离的检索算法,CS表示由专家设定权重值的预测算法,图中纵坐标表示推理预测的准确率,横坐标表示案例库中的案例的个数,由于实验条件限制,本文案例库选择了60组案例,由图可以看出来,随着数据库中的案例个数的增加,推理预测的准确性会越来越高,同时,可以看出CMARE准确率刚开始和CS的准确率高相差不大,但随着案例数目的增加,CMARE算法的准确率不断提高并超过CS的准确率,这是因为随着案例库中案例的增加,各属性的权重值越接近客观均值,从而在计算相似度时使准确率更高。 其次从误报率的角度考虑,仿真实验仍然采用上面给出的案例库,新案例采用与案例库中案例差别较大的案例,统计其误报率,如图4。 图中纵坐标表示案例检索的误报率,横坐标表示案例库中的案例的个数,由图可以看出来,随着数据库中的案例个数的增加,CRE案例检索算法的误报率会越来越低,说明基于粗糙集案例匹配算法的有效性。 图4 案例检索的误报率 本文研究在云计算环境中手机故障预测算法,提出了一种基于粗糙集的CMARE检索算法。目前专门针对手机故障诊断的方法较少,本文将基于案例推理的故障诊断方法引入手机的故障诊断中,同时为了提高故障案例的匹配准确度,利用粗糙集计算属性权重值,结合专家系统给出最终的权重值,使用欧式距离来计算案例的相似度。该算法在确定属性权重值时基于数据本身和专家经验,避免了仅仅依靠专家经验设定属性权重值的不足,仿真结果说明了该算法的有效性。 [1]TomásdelaRosa,AngelGarcía-Olaya,DanielBorrajo.Acaseba-sedapproachtoheuristicplanning[J].AppliedIntelligence, 2013, 39(1): 184-201. [2]ArshdeepBahga,VijayK.Madisetti.AnalyzingmassivemachinemaintenanceDatainacomputingcloud[J].IEEETransactionsonParallelandDistributedSystems, 2012, 23(10): 1831-1843. [3]ZhouYilin,LiHongning.Aircraftfaultdiagnosisbasedonc-ase-Basedreasoningandfaulttreeanalysisintegrated[C]//2011InternationalConferenceonElectronics,CommunicationsandControl,Ningbo,China:IEEEComputerSociety, 2011: 703-706. [4] 王晓亮, 刘西拉. 基于事例推理系统中的模糊检索[J]. 上海交通大学学报, 2007, 41(11): 1783-1787. [5] 董磊, 任章, 李清东. 基于模型和案例推理的混合故障诊断方法[J]. 系统工程与电子技术, 2012, 34(11): 2339-2343. [6]JuanM.Alberola,AnaGarcia-Fornes.Usingacase-basedreas-oningapproachfortradinginsportsbettingmarkets[J].App-liedIntelligence, 2012, 38(3): 465-477. [7] 王洪凯, 姚炳学, 胡海清. 基于粗集理论的权重确定方法[J]. 计算机工程与应用, 2003, 40(36): 20-21. [8]BohaiHong,RuichunTang,YiliZhai.AResourcesAllocationAlgorithmbasedonMediaTaskQoSinCloudComputing[C].Beijing:Proceedingsof2013IEEE4thInternationalConferenceonSo-ftwareEngineeringandServiceScience, 2013: 841-844. 责任编辑 陈呈超 A Failure Case Matching Algorithm Based on Euclidean Distance and Rough Sets TANG Rui-Chun1, ZHANG Xiao-Nan2, GUO Shuang-Le3, QIU Yue4, DING Xiang-Qian1 (1.College of Information Science and Engineering, Ocean University of China, Qingdao 266100,China;2.East Science software Co.of Wuhan, Wuhan 43000,China;3.College of Information Engineering,Bin Zhou University,Bin Zhou 256600,China;4.Peking Science and Technology Co.,Three Fast Anliml,Beijing 100000,China) Study the mobile phone fault case retrieval in a cloud environment when matching cases, we propose a similarity matching algorithm CMARE (Case Matching Algorithms based on Rough sets and Euclidean distance).First, cloud computing platform collects mobile phone fault parameters, and then it builds a Rough sets information table according to these parameters. Second, property weight is computed based on objective weight of feature parameters of each case in the table calculated by Rough sets as well as in the light of expertise. Finally, with the weight and Euclidean distance, the degree of similarity between cases are figured out and then the most similar one from the case base is chased down. This algorithm is based on the date and experience, avoiding the disadvantage of being overly dependent on artificial expertise. This algorithm is based on the date and experience, avoiding the disadvantage of being overly dependent on artificial expertise. The simulation shows the effectiveness of the algorithm. the mobile phone fault case retrieve; rough sets; euclidean distance; information table 国家科技支撑计划项目(2012BAH15F01)资助 2014-04-26; 2014-11-20 唐瑞春(1968-),女,教授。研究方向:网络流媒体。E-mail:tangruichun@ouc.edu.cn O241.6 A 1672-5174(2015)12-125-06 10.16441/j.cnki.hdxb.201400303 仿真实验
4 结语
