基于分级教学的Apriori算法改进
2015-03-25李志
李 志
(武警学院 基础部,河北 廊坊 065000)
基于分级教学的Apriori算法改进
李 志
(武警学院 基础部,河北 廊坊 065000)
学员之间计算机基础能力的巨大差异,使《大学计算机基础》实践课程分级教学的需求越来越强烈。如何摆脱单纯依靠测试分数进行分级的简单方法,得到更加客观、高效的分级结果,是实施分级教学急需解决的首要问题。结合分级教学的应用目的,将Apriori算法从减少事务数据库中事务数量和减少候选项集项数两方面改进后,从新学员计算机基础能力表中得到对分级结果起决定作用的强关联规则,提高了分级结果的客观性和高效性。
大学计算机基础;分级教学;关联规则;Apriori
一、研究背景
随着大学生入伍的普及,战士本科生源中计算机基础能力差异越发明显,为计算机基础教学,尤其是《大学计算机基础》实践课程教学带来很大挑战。经过广泛查阅资料、调查分析、认真思考,笔者认为:为有效解决学员计算机基础能力差异带来的教学矛盾,目前最好的方法就是实施分级教学。[1]
分级教学,在承认学员个别差异的前提下,确立以学员为主体的意识,在调查问卷、能力测试、交流座谈等基础上,结合学员个人意愿,依据教学大纲和教学内容要求,对学员的教学进行分级。
为保证分级教学的有效性,必须首先制定完备、适用、有效的学员分级、教学目标分级和评价分级方案。其中,对学员科学合理的分级是成功实施分级教学的前提。在充分了解学员实际情况的前提下,结合学员的入学计算机测试成绩、基础能力调查,在尊重学员意愿的基础上,按照学员基础水平和学习意愿,将学员划分为不同的等级层次。这是一种比较全面、比较理想的学员分级方法。目前,陆续有一些高等院校对计算机基础课程实施了分级教学。但是,在实践应用中,大多数高等院校都采用了摸底成绩决定制的方法对学员进行简单分级。虽然有些高等院校对学员事先进行了问卷调查或座谈等,但并没有应用到学员分级过程中,忽略了一些主、客观因素可能对摸底成绩的影响,使对学员的分级可能出现一些片面性,分级结果具有偶然性。数据挖掘技术在《大学计算机基础》实践课程中对学员分级的应用,将有效提高分级结果的客观性和有效性。
二、Apriori算法
关联规则是数据挖掘领域重要的研究方向之一。关联规则的任务是:给定一个事务数据库D,在基于支持度、置信度框架中,发现数据与项目之间大量有趣的相关联系,生成所有支持度和置信度分别高于用户给定的最小支持度和最小置信度的关联规则,以揭示数据与数据之间未知的相互依赖关系。[2]
目前,关联规则技术在数据挖掘领域研究中,主要应用于挖掘大规模数据集数据间潜在的、有价值的联系,它既可以检验业内长期形成的知识模式,也能发现其中隐藏的新规律[3],其应用已经从开始的商业指导广泛发展到社会的各个领域,如医疗、金融、保险、教育等。
Apriori算法根据有关频繁项集特性的先验知识而命名,它使用一种逐层搜索的迭代方法来完成频繁项集的挖掘工作。它是最成熟、最具有影响力的关联规则挖掘算法之一。
为保证关联规则的质量,需要对规则进行支持度、置信度和提升度的计算。
关联规则是如同A⟹B的蕴含式[4],项目集A,B均属于I,且A∩B=Ø。关联规则的支持度用Support表示,规则A⟹B在事务数据库D中的支持度,是指包含项目集A和B的事务在事务数据库D所有事务之中所占的百分比。其表达式如下所示:
Support(A⟹B)=P(A∪B)
关联规则的置信度用Confidence表示,规则A⟹B的置信度,是指同时包含项目集A和B的事务在所有包含项目集A的事务中所占的百分比。其表达式如下所示:
Confidence(A⟹B)=(Support(A⟹B))/
(Support(A))= P(B|A)
关联规则的提升度用Lift表示,规则A⟹B的提升度,是目标的密度(置信度)对总目标的密度(规则中右端的结果)的比率。其表达式如下所示:
Lift(A,B) =P(A∩B)/P(A)P(B)
=P(B|A)/(P(B))
支持度是对关联规则重要性的衡量,表示规则的频度。支持度越大,说明关联规则越重要,同时说明这条规则应用越广泛。置信度是对关联规则准确度和可信度的衡量,表示规则的强度。提升度是判断强关联规则对后件属性的正相关性的运算,Lift(A,B)>1,说明A与B正相关,否则,说明A与B负相关。
三、算法的改进
(一)传统Apriori算法存在问题
由于Apriori算法采用多次迭代的算法,严格按标准寻找不小于最小支持度的频繁项,此过程中需要多次扫描事务数据库。在事务数据库较少的情况下,该算法的性能很好,但随着事务数据库的增大,其较为严重的性能瓶颈就显现了[5]:
1.多次扫描事务数据库,需要的I/O负载很大。在每次迭代过程中,候选项集的每一项都需要重新扫描事务数据库来确定其是否为频繁项集,候选项集中项数越多,需要扫描事务数据库的遍数就越多,增大了I/O负载。
2.可能产生庞大的候选项集,造成时间和空间威胁。候选项集都是由前一项频繁集连接生成的,其数量成指数增长。随着频繁项集的计算,候选项集的数量可能会变得极为庞大。这时,将对频繁项集的计算时间和当前存储空间造成很大的威胁。
(二)以分级教学为应用目的的算法改进
针对Apriori算法面临的两大缺陷,对于该算法的改进主要从减少事务数据库中事务数量和减少候选项集项数两方面着手:
1.越过1项频繁集,直接计算2项频繁集。根据Apriori算法在此的应用目的是寻找对分级结果起决定作用的强关联规则,确定其应用目的为生成关联规则。关联规则至少涉及两个不同的项,因此1项频繁集在这里计算没有任何意义,可以直接越过,生成2项候选集,进入2项频繁集的运算。
2.对候选项集进行过滤,只保留分级结果为后件的项。根本目的是寻找分级结果为后件的强关联规则,因此,可以对候选项集进行过滤,只保留分级结果字段为后件的项作为候选项集即可,这样,在很大程度上减少了候选项集的数量。同时,在强关联规则的判断过程中,也只需要对分级结果为后件的规则计算其支持度。
3.强关联规则分次计算,及时删除确定为强关联规则的对应事务。因为可以预想到某些特定项(如:入伍前为计算机相关专业)对分级结果有着很强的决定作用,如果某个事务已经存在此前提,就没必要再进行下一项频繁集的计算,所以第1步可以先把这种起决定作用的强关联规则进行计算并存储、输出。同时,该事务其他项也失去了强代表性,可以从事务数据库中删除。
4.及时删除数据项小于当前频繁项集个数的事务。一个非频繁项集,它的所有超集也一定是非频繁项集。因此,在计算候选项集支持度前,可以先对事务数据库进行预扫描,将不包含任何候选项集的事务删除,再进行候选项集支持度的扫描和计算。
四、改进算法在分级教学中的应用实现
在分级教学过程中,根据教学内容,综合考虑学习者生理、心理特点,结合学习者学习能力水平,制定客观、科学、合理的层次划分标准是有效实施分级教学的首要问题和关键问题。因此,在我院《大学计算机基础》实践课程的分级教学中采用入学摸底测试、调查问卷和学生意愿三者结合的方法。
为充分了解我院入学新学员计算机基础能力,在学员开设计算机基础课程前,统一填写“武警学院入学新生计算机水平调查问卷”,其内容包括籍贯、家庭情况、计算机学习情况、计算机技能掌握情况、计算机技能拓展情况、上网情况、兴趣判断等。由于生源的特殊性,对于战士生源的学员还应该包括入学前服役地、入学前工作性质、入伍前最高学历、是否大学生入伍、是否计算机相关专业等信息。其结构如表1所示。

表1 新生计算机水平调查表
为保证调查结果的客观性,调查问卷设计力求全面。然而,在实际应用中,这些字段并不一定与分级结果密切相关,不适宜用于分级依据。关联规则Apriori算法在《大学计算机基础》实践课程分级教学的应用目的,就是为了通过对调查信息进行分析,从众多字段中寻找与分级结果密切相关的字段,以辅助以后的分级过程。
大多数数据挖掘算法都要求处理离散型数据,即便是可以处理连续型数据的算法,相对来说,离散型数据处理也更简单、更直观。因此,在对采集的原始问卷调查数据进行数据清理后,还需要对其中籍贯和入学前工作性质两个字段进行离散化。
对入学前工作性质进行汇总整理,其取值可以概括为:战斗员、通讯员、卫生员、话务员、驾驶员和文书。根据工作性质与计算机接触几率分析,将入学前工作性质分成“计算机相关”和“计算机无关”,其中“计算机相关”包括“通讯员”和“文书”,“计算机无关”包括“战斗员”,“卫生员”,“话务员”和“驾驶员”,完成该字段的泛化离散化。为顺利应用到关联规则Apriori算法中,进一步将其抽象为逻辑变量“计算机相关工作”,其值分别取Y或N。
籍贯属性因涉及值较多,其数据离散化无法用一般方法完成。可结合分级结果,借用Apriori算法进行数据离散化。对于后件为“A”的强关联规则,其对应籍贯属性值可以约简为“先”。同理,对于后件为“B”的强关联规则,其对应籍贯属性值可以约简为“中”。其他籍贯属性值均约简为“后”。
为简化数据调用过程,将离散化后的能力调查表与分级结果进行合并,离散化后的各字段属性域如表2所示,其部分数据如表3所示。
对于离散化后的事务数据库进行扫描,根据Apriori算法生成2项频繁集,设定其最小支持度为5,筛选后件为分级的频繁项,分别计算其置信度,设定其最小置信度为60%,其强关联规则如表4所示。
为确保强关联规则对后件属性的正相关性,分别计算各强关联规则提升度,其结果如表5所示。
其中,计算机相关专业⟹A、通过计算机等级考试⟹A、自我兴趣判断A⟹A提升度高,可以基本决定分级属性。其他关联规则提升度均在1左右,虽然也是正相关关系,但还不能直接提取该属性,需要进一步判断。由此得出,计算机相关专业、通过计算机等级考试、自我兴趣判断三个属性与分级结果密切相关,可以作为分级用判断属性。
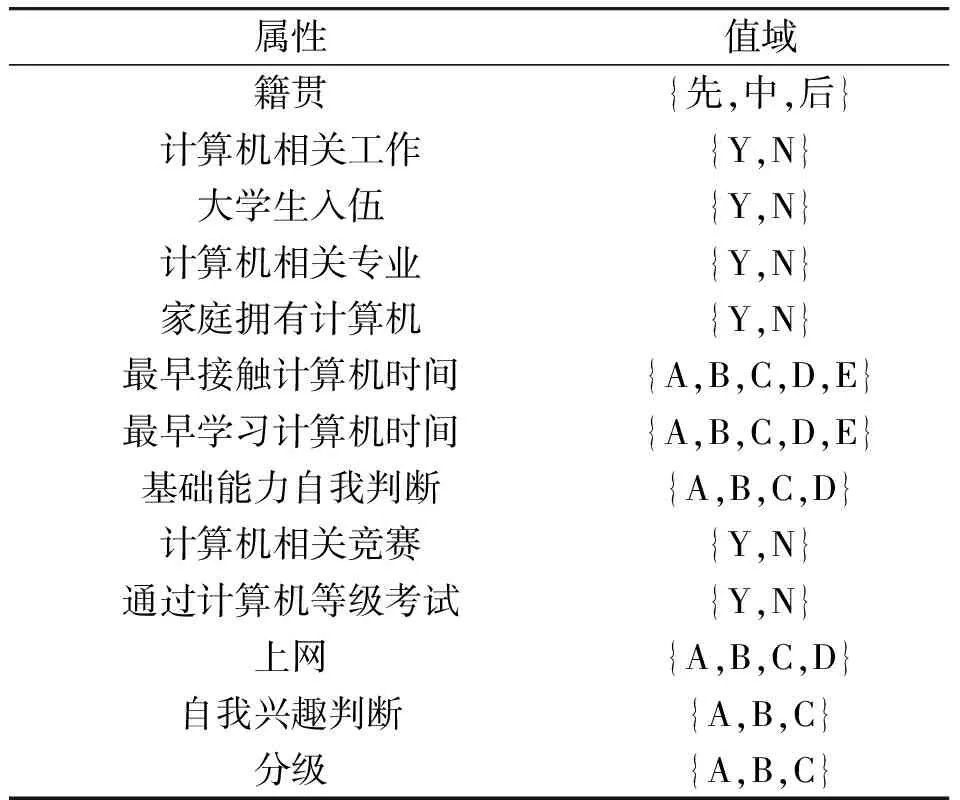
表2 离散化后属性值域
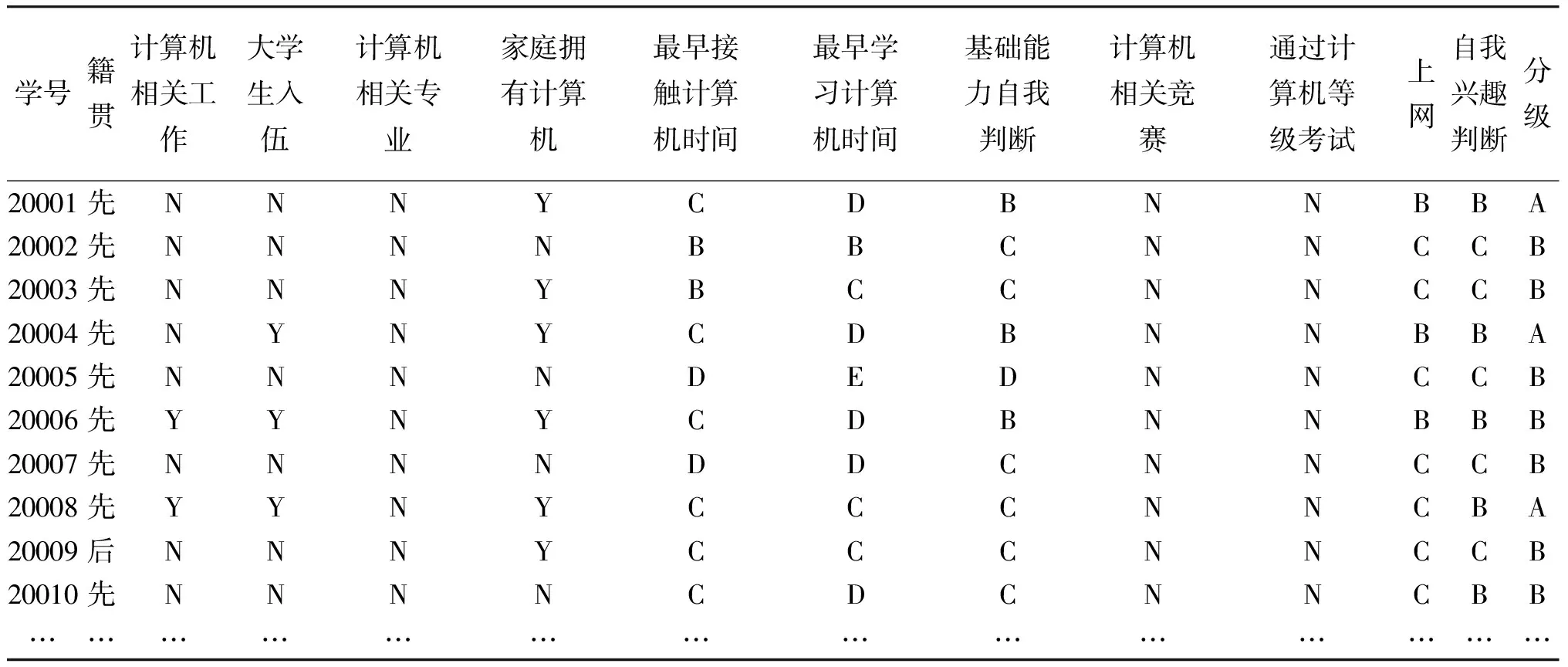
表3 离散化后部分数据
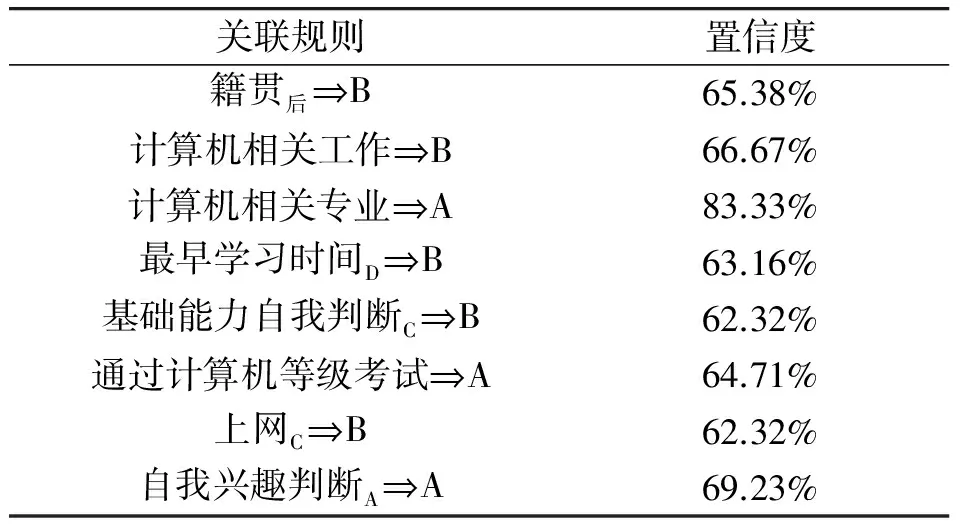
表4 计算强关联规则

表5 强关联规则提升度
当对其他属性计算其基于3项频繁集的强关联规则时,为减少扫描事务数量,将计算机相关专业=Y、通过计算机等级考试=Y和自我兴趣判断=A的事务从事务数据库中删除,并删除计算机相关专业和计算机等级考试两个属性。同时,由于计算机相关竞赛属性支持度<5,该属性也被删除。
约简后的部分数据如表6所示。
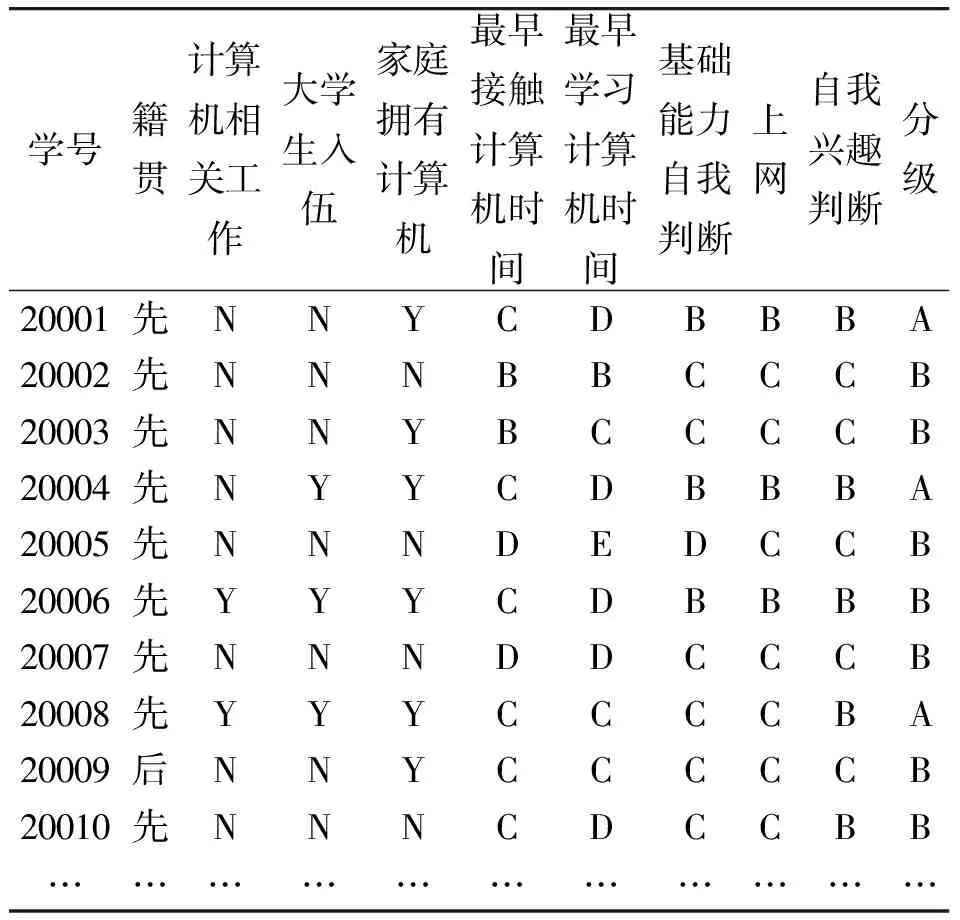
表6 约简后部分数据
再次扫描事务数据库,根据Apriori算法生成3项频繁集,筛选其后件为分级的频繁项,分别计算其置信度。设定其最小置信度为60%,其部分强关联规则如表7所示。
分别计算各强关联规则提升度,其结果如表8所示。
经过分析,计算机相关且大学生入伍与分级结果为A的提升度为4.6,与分级结果密切相关,可以作为下一步进行分级的判断属性。
至此,经过分别寻找基于2项频繁集的强关联规则和基于3项频繁集的强关联规则,共得到与分级结果密切相关属性有4个,分别为:计算机相关专业、通过计算机等级考试、自我兴趣判断以及计算机相关工作且大学生入伍。
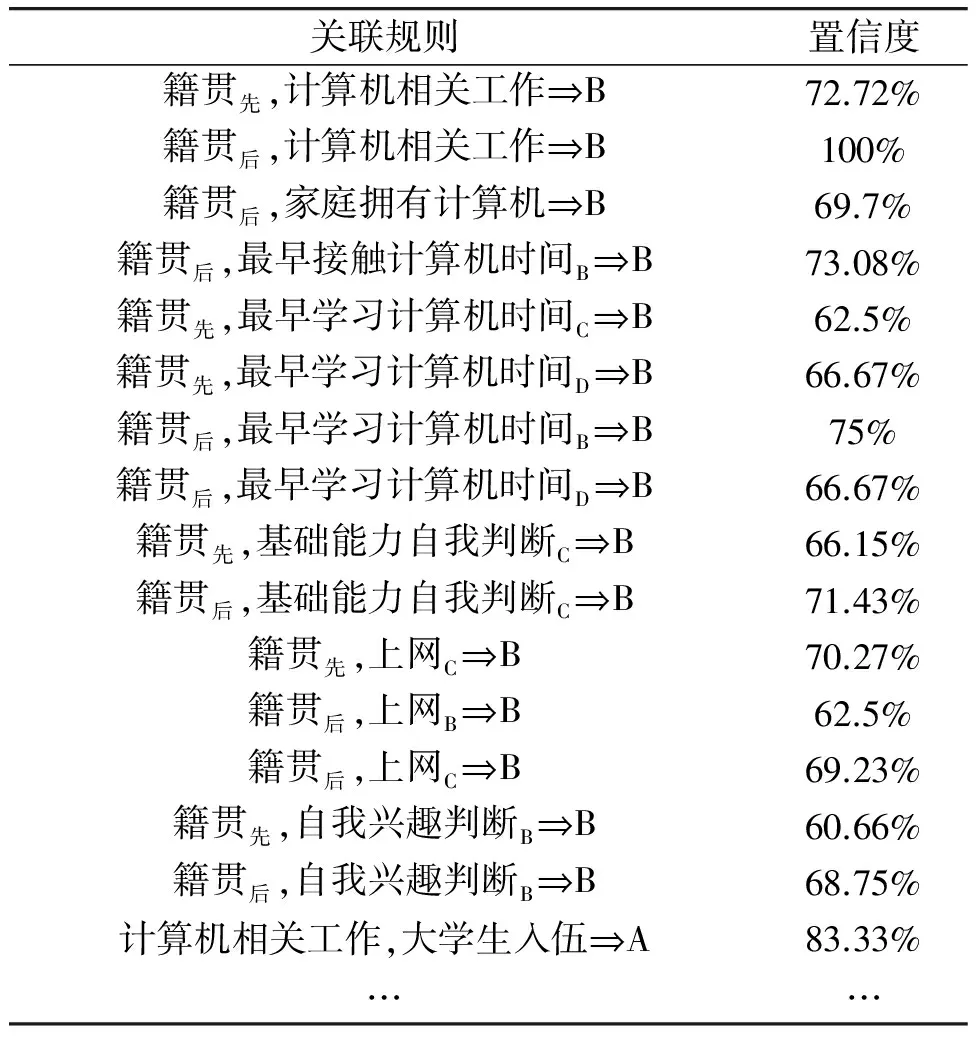
表7 基于3项频繁集的强关联规则
五、结束语
学员计算机基础能力差异对教学带来的困难越来越大,《大学计算机基础》实践课程分级教学的开展,对教学效果必将有显著提高。但如何从繁杂的海量数据中快速、高效地寻找到有用信息,是客观、有效地开展分级教学的第一步。关联规则Apriori算法的应用,通过对新生计算机水平调查表中大量数据的分析、计算,从14个已有字段中抽取出与分级结果密切相关的4个属性,为提高分级结果的效率和准确性提供了保障。
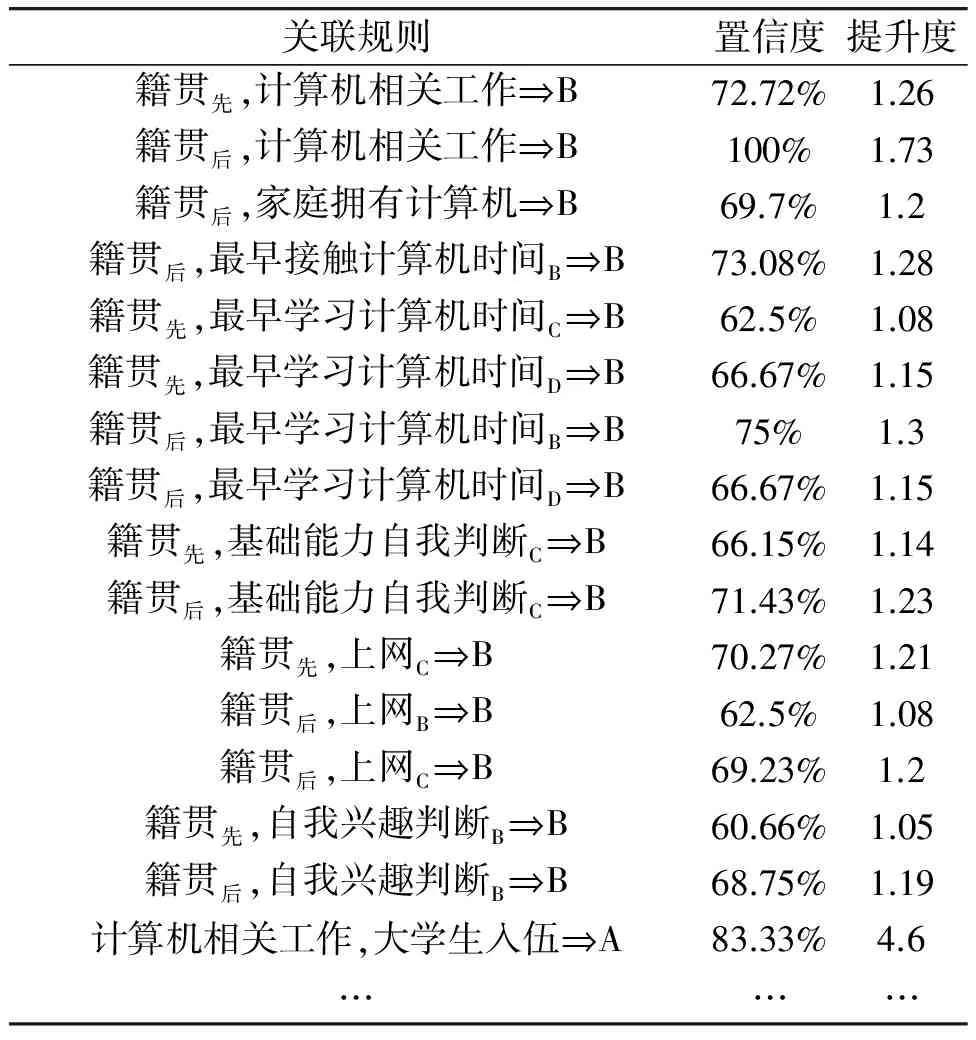
表8 基于3项频繁集的强关联规则提升度
[1] 李志,张晶.公安现役院校计算机基础课程分级教学探析[J].武警学院学报,2013,29(9).
[2] 纪希禹.数据挖掘技术应用实例[M].北京:机械工业出版社,2009.
[3] 刘平.关联规则算法在高校教务管理系统中的应用与实现[D].石家庄:河北科技大学,2010.
[4] 曹扬波.数据挖掘技术在寿险市场分析中的应用[D].重庆:重庆大学,2010.
[5] 杨秋叶.改进的Apriori算法在Excel智能考试系统中的应用[D].桂林:广西师范大学,2012.
(责任编辑 李献惠)
The Improved Apriori Algorithm Based on Gread-teaching
LI Zhi
(DepartmentofBasicCoursesTeaching,TheArmedPoliceAcademy,Langfang,HebeiProvince065000,China)
The bigger difference between a computer basic ability of students produces a strong demand on the grade-teaching inUniversityComputerFoundation’spractical course. How to get rid of the simple way which relys solely on tests in grading for obtaining more objective and efficient classification results. It is the most important to be implemented in grade-teaching. It makes the improvement to the Apriori algorithm based on grade-teaching application, such as reducing the number of scanning and candidate set. The strong association rules which play a decisive role is obtained from new students’ basic computer capability table. The purpose is to improve the classification results of objectivity and efficiency.
UniversityComputerFoundation; grade-teaching; association rules; Apriori
2014-11-13
河北省教育厅项目“公安现役院校《大学计算机基础》分级教学模式研究”(Z2012114)
李志(1977— ),女,河北衡水人,副教授,硕士。
TP311.13
A
1008-2077(2015)05-0066-05
