基于微博情感分析的电影票房预测研究
2015-03-23王洪伟何绍义
史 伟, 王洪伟, 何绍义
(1.湖州师范学院 商学院, 浙江 湖州 313000; 2. 同济大学 经济与管理学院, 上海 200092;
3.加州州立大学 圣马可斯分校 商学院, 美国 加利福尼亚 圣马可斯)
基于微博情感分析的电影票房预测研究
史 伟1*, 王洪伟2, 何绍义3
(1.湖州师范学院 商学院, 浙江 湖州 313000; 2. 同济大学 经济与管理学院, 上海 200092;
3.加州州立大学 圣马可斯分校 商学院, 美国 加利福尼亚 圣马可斯)
微博作为电子口碑的重要载体,极大影响了消费者的购买决策和商家的产品销售.为此,以新浪微博为平台,研究从微博中挖掘情感信息并利用这些信息对产品销售进行预测的方法.分析影响微博评论的因素,基于已构建的情感本体,建立微博中情感计算方法.然后在传统自回归模型的基础上融入情感因素,提出自回归情感预测模型用于产品销量的预测.对电影数据集进行了广泛地实验,分析参数选择,并与其它预测模型进行比较,实验证实我们提出的方法的有效性.
微博; 情感分析; 情感本体; 自回归情感预测模型
销售预测是商业领域一个重要问题.特别是,互联网引发的电子口碑极大影响了消费者的购买决策,因此探究电子口碑对产品销量的影响倍受关注.微博是电子口碑传播的重要载体和形式.通过微博,可以关注或交流关于特定主题的观点,从主流话题(比如饮食、音乐、电影、商品、政治等)到私密爱好[1].截止2012年8月,中国的微博用户约为3.27亿人,微博用户平均每天发表微博2.13条,转发3.12条[2].可以说,微博已成为展现公众情感和观点的平台,也成为影响商家销售的重要因素.
对于电影市场而言,影响票房收入的因素很多,无法全面考虑,从而影响预测模型的准确性.同时也看到,基于微博的影评正成为观众选择影片的重要参考,而且影评本身涉及到电影诸多方面的信息.因此,深入挖掘微博影评信息,可以在一定程度上弥补现有预测模型对影响因素考虑不足的缺陷.为此,本文以关于影视评论的中文微博为对象,探究微博表达的观点和情感是如何影响电影票房预测的.之所以选择电影展开研究,一是因为电影票房数据在网上是公开发布的,而其它产品的销售数据通常都未对外公布或不够准确.同时电影评论也被认为是情感分析中最具挑战性的任务之一[3];另一方面,针对票房建立的预测模型也会适用于其它产品销售的预测,比如书籍、音乐CD和电子产品等.
主要步骤是:通过采用情感分析技术,从微博文本中挖掘观点和情感,选择基本预测模型,将情感信息引入预测模型,构建情感预测模型,根据前期的电影票房收入和微博影评的情感因素对票房进行预测.本文构建的模型将对商务智能提供帮助,包括市场分析、产品规划到有针对性的广告发布.
1 文献综述
一些学者通过提取留言板、聊天室和博客中的相关评论,分析它们与市场的相关性.Tumarkin等人发现相关论坛上网民讨论活跃的那几天市场会呈现不正常的回报,同时也发现这种不正常的活跃日期并不能预测市场的回报[4].相似地,Antweiler等人也指出论坛上发表的股评与股票的波动相关,但是没发现这些讨论的预测功能[5].较早通过在线发表的帖子进行销量预测的是Tong,他利用新闻中关于电影的观点进行票房预测,取得了一定的效果[6].Joshi等人运用线性回归模型,通过分析文本和元数据对电影收入进行预测,达到了初步的预测功能[7].Sharda等人将预测问题当作一种分类问题,运用神经网络将电影分成不同种类,但是该模型的预测准确率不是很理想[8].Gruhl等人研究了如何产生自动询问对博客进行挖掘,进而对书籍的销售进行预测[9].Zhang等人构建了一种新的聚合模型,根据互联网电影资料库(Internet Movie Database,IMDB)中的数据预测电影票房,方法有一定的新意[10].
通过微博进行产品销量预测的研究时间相对不长,前期研究主要考虑微博数量或链接结构等因素来预测产品销售趋势[9],没有考虑微博中的情感因素.已有研究[11]发现尽管微博数量或链接结构与销售趋势具有一定的联系,但是不能提供理想的预测效果.为此,一些学者开始考虑微博中的情感信息对预测效果的影响,文献[12-16]中针对微博或博客文本进行情感分析,并对电影票房和股市进行了预测,取得了不错的效果.
总结相关研究发现,基于微博平台的预测研究多以英文语境下的Twitter为研究平台,采用传统的文本挖掘方法提取微博中的观点和情感进行产品销售预测,只是简单地将微博评论分类为正面和负面,不能对中文微博评论中反应的情感提供充分地理解.为此,本文引入情感本体建模方法,并结合微博中的语义因素和微博影响力分析构建微博情感值计算模型,为提取微博中的情感因素奠定基础.除了考虑微博中的情感因素,本文还将过去的销售记录作为预测产品销量的另一个重要因素.本文提出一种用于产品销售预测的模型,称之为自回归情感预测模型.对于电影数据的广泛实验发现自回归情感预测模型的表现效果比只使用普通预测模型的效果要好很多,进一步证实了我们的预期情感因素在产品销量的预测中扮演了很重要的角色.
2 微博情感因素的提取与度量
对于中文微博的情感分析,可将微博文本作为Web短文本处理,这里采用已建立的情感本体并结合相关语义的方法进行处理.举个例子
“今晚观看了美国大片《碟中谍4》,喜欢这效果!”
这个微博帖子通过情感标记有一个情感类“喜欢” V 喜爱 1.00 .
在前期研究中已详细论述情感本体的构建过程[17],并创建了可用于在线评论情感分析的情感词本体库.主要创新之处是将情感本体划分为评价词本体和情感词本体,利用模糊理论和知网模型,构建情感本体的基本模型.根据评价词和情感词的各自特点(评价词是消费者对产品及其特征发表的“肯定”或“否定”的评价,用来表达自己的观点或立场,情感词是消费者对评论涉及的主题进行各种情感表达,这些情感可以是“期待”、“愉快”等),运用模糊化处理和语义相似度的相关理论,分别对评价词本体和情感词本体的情感类型和隶属度进行了相应处理.情感本体形式如下所例:
FEO=((18;开心;happy; adj; 张三; 知网2007版情感分析用词语集), (快乐;愉快), (高兴;1.00))
最终的情感本体收录9952个词条,各类情感(2种评价类和8种情绪类)统计如表1.

表1 各情感类词汇数量
各情感类词汇分别赋予了相应的情感类和情感隶属度值,情感隶属度取值范围为[0,1],可用于分析微博的情感因素,进而预测商品的销量.情感有积极和消极之分,即情感极性.上述8类情感中期待、愉快、喜爱属于积极情感,而悲伤、生气和讨厌则属于消极情感,惊讶和焦虑在不同的语境下既可能表现为消极也可能为积极.
为了便于公式(8)中情感类参数k的选择,将情感类划分为7种情况:①1类情感,所有收录的情感词汇归为一类;②2类情感,包括评价类6862个词和情感类2090个词;③3类情感,包括3715个G(好)类评价词、3147个B(坏)类评价词和2090个情感词;④4类情感,包括G类评价词、B类评价词、积极情感(期待、高兴、喜爱、惊讶)和消极情感(焦虑、悲伤、生气、讨厌);⑤5类情感,包括G类评价词、B类评价词、积极情感(期待、高兴、喜爱)、中性情感(惊讶、焦虑)和消极情感(悲伤、生气、讨厌);⑥6类情感,包括G类评价词、B类评价词、强积极情感(高兴、喜爱)、弱积极情感(期待、惊讶)、强消极情感(生气、讨厌)、弱消极情感(焦虑、悲伤);⑦10类情感,包括2种评价类和8种情感类.
一条微博文本影响力代表着文本的内容在微博情感分析中的参考价值,主要与发帖者有关[18],从以下几个因素进行考虑:①用户是否是微博平台认证用户,若是说明此用户是社会名人,具有很强的影响力;②用户的跟随者的数目,跟随者越多,说明越有影响力;③用户的朋友数目,如果用户的朋友数目过多,则说明其只是信息的接受者,文本的影响力就很小.综合考虑上面各种因素,得到文本b的影响力计算方法如式(1)
(1)
其中,Ib表示发表帖子b的用户的跟随人数,fb,2表示发表帖子b的用户的朋友数目.函数x(l)是影响力的扩展比例系数,根据微博平台的特性定义如下:当l≥10时x(l)=2;1
对中文表述而言,程度词经常和情感词汇一起出现从而改变情感词汇的情感类强度.为了准确计算微博的情感强度,在情感词的上下文设置一个检测窗口,宽度为5.如果在检测窗口内有程度词出现,则按程度词的等级相应增加情感词的情感强度,从高到低依次增加1.5到0.8倍.从知网中抽取60个程度词并将其分成7类[17],具体设置如表2所列.

表2 程度词赋值表
否定词的出现往往会改变情感词的倾向性,同上节从知网中人工抽取出22个否定词,在情感词上下文设置一个大小为5的检测窗口,若在检测窗口内出现否定词,就对词组情感值取反.如果一条微博存在多个情感词属于同一情感类,就选取隶属强度的平均值作为相应情感类的强度.
综合上述规则,微博中情感值计算如式(2)
(2)

3 自回归情感预测模型
为了构建基于微博情感信息的电影票房预测模型,需要考虑两方面因素:(1)前期的对应票房收入;(2)观众在微博中对电影的情感表达.
3.1 自回归模型
首先考虑第一个影响因素(即前期的票房收入)对当前票房的影响,两者的关系可以通过自回归模型(AR)来反映,如公式(3)所示.
(3)
其中,xt为时间t的电影票房收入,t=1,…,n.t=1为电影首映日,t=n为统计的最后一日.φ1,φ2,…,φp是模型的参数,εt是误差项(平均值为0的白噪声).只有当时间序列{xt}处于稳态的情况,AR模型才是有效的[19].很明显,由于存在趋势性和周期性,这里的时间序列{xt}不是稳态的.其原因是,电影票房随着时间的推移存在着负指数下降的趋势.另外,票房总是在周末达到最高而在周中则普遍偏低.因此,为了更准确地对{xt}进行建模,需要预处理.
第一步去除趋势性.将时间序列{xt}转化为对数域,得到新的时间序列
第二步去除周期性.将滞后算子应用到新的时间序列{x′t}中,得到新的时间序列:yt=x′t-L7x′t=x′t-x′t-7.通过计算某日和7天前票房的不同,有效地去除一周之内不同日子的周期性因素.预处理步骤结束后,形成了新的AR模型:
(4)
需要指出,虽然所建的AR模型是针对电影票房,但同样适用于其它领域.因为趋势性和周期性也存在于很多其他商品的销售中,比如电子产品.
3.2 融入情感因素
如前所述,电影票房还会受到公众观点的影响.为此,引入情感因素对模型(4)进行修正.设Βt为时刻t发表的关于电影的微博.情感类j在时刻t的平均值定义为:
(5)
其中,eb,j的计算方法前面已述.新的自回归情感预测模型可以调整为如式(6)
(6)
其中,p,q和k为用户自主选择的参数,而øi和ρi,j的参数值需要通过训练数据进行估计.参数p表示前期票房的考虑天数,q表示提前几天开始考虑情感因素,k表示情感信息的种类,分类如前所述.
3.3 训练自回归情感预测模型
对自回归情感预测模型的训练包括从真实的票房数据中训练得到参数集øi(i=1,…,p)和从微博数据获得的st,j中学习得到参数集ρi,j(i=1,…,q;j=1,…,k).我们将在下面进行介绍,在对p和q选择后,模型能够通过最小二乘回归拟合估计的参数值.

Aθ≈C.
(7)
更准确地说,寻求Aθ-C差的欧几里德平方的最小值,这是一个最小二乘回归问题.一旦模型通过训练,公式(6)就能根据前期的票房收入数据和从微博中挖掘得到的情感信息预测日期t的票房收入.
4 实证研究
4.1 实验设置
微博数据的提取主要有3种方式:1)采用网络爬虫抓取;2)通过API获取微博文本;3)通过微博平台高级搜索获取.本文主要采用第3种方式获取微博信息,这些信息都是公开的可免费获取,微博的主要特点之一就是“即时分享”,用户通过微博平台将自己的观点和情感分享给听众,所以在研究过程中提取他人公开的微博信息,是完全合乎国家相关法律许可和基本道德规范的,不存在侵犯他人隐私的问题.
以国内最大的新浪微博为数据来源.实验数据包括2部分:1)从新浪微博收集的2012.1.18到2012.2.25期间投放市场的电影的微博;2)这些电影的每日票房收入.
对于每部影片,本文收集影片首映前1周到首映后4周发表的微博.共收集了关于40部不同电影的92 701条微博,比如《大闹天宫3D》2 134条、《碟中谍4》35 215条.然后按照以下步骤进行处理:
1)对在空白边界上的个别词的分离.
2)从微博文本中去除所有非文字的数字字符,例如逗号、破折号等.
3)去除1 208个标准停用词包括常见的一些动词形式.
4)删除一些不相关的微博信息,从微博中过滤掉额外的链接如含有“http:”或者“www.”的表达和用户的名字(用符号@标志的).
5)移除“回复”、“转发微博”等词和转发的内容(只是转发没有增加任何评论的帖子).
6)清理后,将微博文本分成一个个单句,而后进行情感词标记和基本词性标注.
采用人工方式,从中国电影报微博(http://weibo.com/u/2304129841)收集40部电影的票房收入.对于每部影片,收集从它们首映开始4周时段内每天的票房数据.每轮的实验都遵照以下流程:
1)随机选择一半的电影(20部)进行训练,另外一半进行测试.微博文本和电影票房数据也相应的部分作为训练数据集,部分作为测试数据集.
2)根据已建立的情感本体包括2类评价词和8类情感词,在微博文本中将出现的这些情感词汇标注出来,并结合相关语义因素包括否定词和程度词的作用,采用公式1对单条微博文本的情感值进行计算.最后用情感向量eb,j来表示微博b对于某部电影的情感值.
3)将得到情感向量与票房收入投入到自回归情感预测模型中,获得参数的估计值.
4)通过对测试数据进行实验,评估自回归情感预测模型的预测效果.
运用平均绝对百分比误差(MAPE)衡量模型的预测准确率[20]:
(8)
其中,n是总的预测数量,Predi是预测值,Truei表示真实的票房收入.这里的准确率结果是指20部影片的平均值.显然MAPE越小,表示预测准确率越高.
4.2 参数设置
自回归情感预测模型的一些参数需要事先设置,包括情感种类k,提前期p和q.
根据以往的文献研究,通常前1周的票房收入对后期票房的预测效果较佳,情感信息的影响效果这里假设临近时期最佳,所以初始设p=7,q=1,观察k值的变化对自回归模型预测准确性的影响.图1(a)显示,当k从1增加到4,预测准确率不断提高.当k=4,预测模型的MAPE达到10%.这表示情感类越多就越能充分地从微博中捕获情感信息,从而导致高的预测准确性.另一方面,当k超过4预测准确性又开始降低.这里的解释是k值过大引起了过度拟合问题.如果k值过大,就会由于时间和空间问题引起过高的训练成本.
设K=4,q=1,观察p值的变化对自回归模型预测准确性的影响.图1(b)显示,p=7时预测效果最好.这表明p值足够大才能使前期的票房产生显著的效果,但如果过大将导致过久产生的不相关信息影响预测的准确性.
根据上述结果,设K=4和p=7,并观察q值由1增加到5对自回归模型预测准确性的影响.图1(c)显示,当q=1时预测效果最佳,表示发表在前1天的电影微博反应的情感信息对票房的预测效果最好.
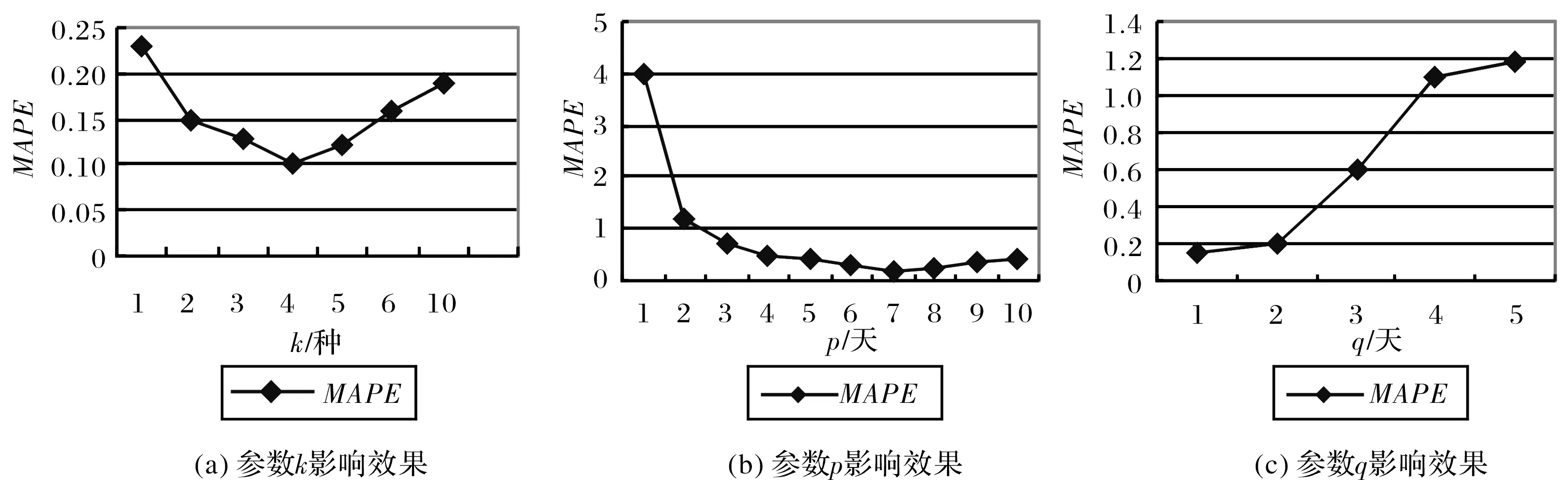
图1 参数对预测准确性的影响效果
为了更好地表现模型参数值对于预测准确性的影响,通过2012.1.17上映的电影《逆战》在中国大陆地区的票房值变化(从首映日开始十日时间里)来进一步观察,如图2所示.运用不同参数值得到的预测票房和真实票房进行比较,发现在整个时间周期内图1所确定的最优参数值得到的票房预测结果最接近真实值,同样的效果在其它电影的票房预测中也能得到体现.

图2 参数对电影《逆战》票房预测影响效果
4.3 与其它方法的比较
将自回归情感预测模型同其它两种不考虑情感因素的方法进行比较.
然后与考虑微博数量的自回归模型进行比较.为此,将微博数量引入自回归模型中,用微博数量来表示电影受欢迎程度.新建模型如下:
(9)
其中,yt的获取方式同本文建立的自回归情感预测模型相同,vt-i表示在日期t-i相关微博的数量,øi和ρi,j的参数值同样需要学习得到.此模型的训练和测试流程和先前建立的模型相似,通过数据对此模型进行实验并与本文的模型进行比较,结果如图3所示.发现这种方法的表现略优于纯粹的AR模型,表明微博数量有一定的预测能力,但其表现还是逊于本文的自回归情感预测模型.

图3 不同方法的MAPE值比较
5 小结
微博作为一种可以传达个人观点和意见的方式被广泛使用,它给大家提供了一种独特的机会去了解公众的情感和应用这些信息推进商业智能.在本研究中,我们以电影为研究对象探讨了微博的预测功能,研究了运用从微博中挖掘出来的情感信息进行销售预测的问题.本工作的一个重要部分就是运用已经构建的情感本体并结合相关语义因素建立了微博的情感分析模型,建立的情感分析模型有助于从简单地对情感“积极或消极”的分类朝着更深入地理解微博中的情感的方向发展.运用情感分析模型对微博中的情感信息进行总结,发展了自回归情感预测模型,该模型基于情感信息和产品过去的销售表现对将来的销售情况进行预测.该模型的有效性已经通过对电影数据集的实验得到证实.本文是前期微博情感分析的一个应用研究,商家可以利用本文的模型,更好地利用微博的预测功能,以一种更有效地方式开展业务.
将来可以从以下几个方面进行完善:1)完善微博情感的分析模型,考虑更多的语义因素;2)除了本文探讨的情感信息和过去的销售情况作为预测的基础信息,还可以考虑其它一些影响因素,以提高模型的预测水平;3)对其它的产品进行研究,验证模型的应用性;4)考虑微博的一些文本因素,体现微博平台的特点.
[1]KumarR,NovakJ,RaghavanP,etal.Structureandevolutionofblogspace[J].CommunicationoftheACM, 2004, 47(12):35-39.
[2]DCCI互联网数据中心. 2012中国微博蓝皮书[EB/OL].http://www.dcci.com.cn.
[3]BingLiu,MinqingHu,JunshengCheng.Opinionobserver:analyzingandcomparingopinionsontheweb[C]//WWW'05Proceedingsofthe14thinternationalconferenceonWorldWideWeb,NewYork:ACMPress, 2005:342-351.
[4]TumarkinR,WhitelawRF.Newsornoise?Internetpostingsandstockprices[J].FinancialAnalystsJournal, 2001, 18(11): 41-51.
[5]AntweilerW,FrankMZ.Isallthattalkjustnoise?TheinformationcontentofInternetstockmessageboards[J].JournalofFinance, 2004, 59(3):1259-1295.
[6]R.Tong.Detectingandtrackingopinionsinon-linediscussions[J].ComputerScience, 2001, 37(6):261-264.
[7]JoshiM,DasD,GimpelK,etal.Moviereviewsandrevenues:Anexperimentintextregression[J].NAACL-HLT, 2010, 33(10):232-238.
[8]ShardaR,DelenD.Predictingbox-officesuccessofmotionpictureswithneuralnetworks[J].ExpertSystemswithApplications, 2006, 12(30): 243-254.
[9]GruhlD,GuhaR,KumarR,etal.Thepredictivepowerofonlinechatter[C]//KDD′05ProceedingsoftheeleventhACMSIGKDDinternationalconferenceonknowledgediscoveryindatamining,NewYork:ACMPress, 2005:78-87.
[10]ZhangW,SkienaS.Improvingmoviegrosspredictionthroughnewsanalysis[J].InWebIntelligence, 2009, 20(16): 301-304.
[11]GruhlD,GuhaR,Liben-NowellD,etal.Informationdiffusionthroughblogspace[C]//WWW'04Proceedingsofthe13thinternationalconferenceonWorldWideWeb,NewYork:ACMPress, 2004: 491-501.
[12]MishneG,GlanceN.Predictingmoviesalesfrombloggersentiment[C]//TheSpringSymposiaonComputationalApproachestoAnalyzingWeblogs.MenloPark,California:TheAAAIPress, 2006: 155-158.
[13]DoshiL.Usingsentimentandsocialnetworkanalysestopredictopening-moviebox-officesuccess[D].Massachusetts:MITMasterTheis, 2010.
[14]BollenaJ,MaoaH,XiaojunZeng.Twittermoodpredictsthestockmarket[J].JournalofComputationalScience, 2011, 2(1):1-8.
[15]JainV.Predictionofmoviesuccessusingsentimentanalysisoftweets[J].InternationalJournalofSoftComputingandSoftwareEngineering, 2013, 3(3):308-313.
[16]JingfeiDu,HuaXu,XiaoqiuHuang.Boxofficepredictionbasedonmicroblog[J].ExpertSystemswithApplications, 2014, 13(41): 1680-1689.
[17] 史 伟, 王洪伟, 何绍义. 基于知网的模糊情感本体构建研究[J].情报学报, 2012,31(6):595-602.
[18] 侯少龙, 赵政文. 面向微博平台的产品市场分析模型研究[J]. 微型电脑应用,2008,27(2):4-6.
[19]EndersW.AppliedEconometricTimeSeries(2ndedition)[M].NewYork:Wiley, 2004.
[20]JankW,ShmueliG,WangShanshan.Dynamic,real-timeforecastingofonlineauctionsviafunctionalmodels[C]//KDD'06Proceedingsofthe12thACMSIGKDDinternationalconferenceonKnowledgediscoveryanddatamining.NewYork:ACMPress, 2006: 580-585.
Study on predicting movie box office based on sentiment analysis of micro-blog
SHI Wei1, WANG Hongwei2, HE Shaoyi3
(1. Business School, Huzhou University, Huzhou, Zhejiang 313000;2.School of Economics and Management, Tongji University, Shanghai 200092; 3.College of Business Administration, California State University, San Marcos, California, USA)
Micro-blog is an important carrier of electronic word-of-mouth, which has affected the purchase decisions of consumers and product sales of businesses. In this article, we study the problem of mining sentiment information from Sina micro-blog and investigate ways to use such information for predicting product sales performance. We analyze the affecting factors of micro-blog reviews, and establish the sentiment compute method of micro-blog based on fuzzy sentiment ontology, then put sentiment factors into the autoregressive model, present autoregressive sentiment predicting model for predicting product sales performance. Extensive experiments were conducted on a movie data set. We analyze the parameters selection, and compare our model with alternative models that do not take into account the sentiment information. Experiments confirm the effectiveness and superiority of the proposed approach.
micro-blog; sentiment analysis; sentiment ontology; autoregressive sentiment predicting model
2014-04-22.
国家自然科学基金项目(71371144);浙江省社会科学界联合会研究课题(2014N021);浙江省教育厅科研项目(Y201430457).
1000-1190(2015)01-0066-07
O213.9
A
*通讯联系人. E-mail: shiwei108108@126.com.
