基于视觉词袋模型的人脸识别方法
2015-03-23崔建涛范乃梅邓璐娟
崔建涛, 范乃梅, 邓璐娟
(郑州轻工业学院 软件学院, 郑州 450002)
基于视觉词袋模型的人脸识别方法
崔建涛*, 范乃梅, 邓璐娟
(郑州轻工业学院 软件学院, 郑州 450002)
近年来,基于视频的人脸识别吸引了很多人的关注,同时,视觉词袋模型已成功应用于图像检索和对象识别中.论文提出了一种基于视觉词袋模型的人脸识别方法,该方法首先在兴趣点提取尺度不变特征变换的图像描述,这些兴趣点由高斯差分检测,然后基于k均值生成视觉词汇,并使用视觉单词的索引以取代这些描述符.然而,在人脸图像中,由于面部姿势失真,面部表情和光照条件变化,采用尺度不变特征变换描述符后识别效果并不理想.因此,论文使用仿射尺度不变特征变换描述符作为人脸图像表示法.在Yale及ORL人脸数据库上的实验结果表明,在人脸识别中,本文方法可以获得较低的错误率.
人脸识别; 视觉词袋; 图像检索
随着人脸识别技术在安全验证、医学、档案管理、人机交互、公安、视频会议和图像检索等领域的广泛应用,人脸识别已经成为计算机视觉和模式识别领域的一个研究热点.人脸识别的挑战来源于视觉刺激的巨大变化,包括光照条件、视觉角度、面部表情、年龄及乔装等.在过去的20年里,人们提出了大量的人脸识别方法来解决这些具有挑战性的问题,如文献[1]所述.这些方法大致可以分为两类:基于几何的方法及基于面部的方法.前者通常用相关位置或者判别特征的其它参数来表示一张人脸图像,如眼睛、嘴巴、鼻子、下巴等.相反,基于面部的方法通常将一个人脸图像视为空间中的一个样本.自从19世纪90年代,因为简单而又高效,基于面部的方法已经占据了人脸识别领域的主导地位.
基于视频的人脸识别一直是一个热门的研究课题,已经提出许多著名的方法克服了人脸识别问题.其中,主成分分析(PCA)[2]在特征空间中寻找一个子空间,其子空间具有最大的方差,然后把特征向量投影在子空间中.线性判别分析(LDA)[3]试图获得另一个子空间,它可以最大化类间方差与类内方差间的比例.局部保持投影(LPP)也试图找到一个最优的线性转换,在一定意义上,它保持了数据集的本地邻居信息.
最近,提出了基于多幅图像/视频序列的人脸识别方法.互子空间法(MSM)[4]考虑了输入和作为相似性度量的参考子空间之间的最小角度,每个子空间是由PCA在每个人的图像序列上操作得到的.限制性互子空间法(CMSM)[4]对MSM有所改进,其输入和参考子空间的构建与MSM相同,除了这些子空间的基础进一步投影到约束的子空间,投影用于计算两个人之间的相似度.
上面所有的方法都集中在投影和特征向量的转换上,这些方法所使用的人脸图像的特征向量,通常是以行为为主要顺序的简单灰度值.然而,在人脸识别中,特征的选择和提取也是非常重要的.最近,在许多计算可视化问题中,使用了视觉词袋(BoWs)图像表示法,表现出了令人印象深刻的性能.第一次在兴趣点上提取尺度不变特征变换(SIFT)[5]的图像特征,兴趣点通常用高斯差分(DoG)方法进行检测.然后,一个聚类方法将这些SIFT特征转换成码字直方图.最后,两个图像之间的相似度可以通过直方图之间的距离来测定.
对同一个人在不同的位置和角度进行明显的变形,由相机拍下不同的人脸图像,图像平面的仿射变换可以缓和这些变形.仿射变换的参数包括尺度、旋转、平移、相机的经纬度角.虽然SIFT方法中,上述五个参数中有三个是不变的,但是它仍不够好.本文提出的ASIFT方法涵盖所有的参数,并且已被证明是完全仿射不变的.而且,通过两种分辨率方案,ASIFT方法的计算复杂度,可以减少到SIFT方法的一半.
本文提出使用ASIFT视觉单词作为人脸图像表示法.在Yale及ORL人脸数据库上的实验结果表明,ASIFT视觉单词方法比其它经典方法要好的多.
1 所提方法设计与分析
1.1 尺度不变特征变换(SIFT)
SIFT方法通过旋转比较了两个图像,平移和标度的变化来决定是否可由一张图像推导出另一张图像.为了实现规模不变性,SIFT模拟放大尺度空间.可以通过搜索所有可能尺度的稳定点,这些稳定点是不变的尺度变化.图像的尺度空间由该图像的卷积和一个在多尺度下可变规模高斯G(x,y,σ)形成,其中σ是尺度参数.卷积结果可定义为:
L(x,y,σ)=G(x,y,σ)*I(x,y),
(1)
其中,*表示坐标(x,y)的卷积操作,并且,
(2)
为了在尺度空间有效地检测到稳定的关键点,使用文献[4]中Lowe提出的方法,它使用了图像的高斯差分函数卷积.两个邻近尺度分离差异,由一个恒定的尺度因子c计算为
D(x,y,σ)=(G(x,y,cσ)-G(x,y,σ))I(x,y)=L(x,y,cσ)-L(x,y,σ).
(3)
在尺度空间特征描述的任何情况下,每个尺度的平滑图像L都需要计算.因此,在这个方法中的D可以用简单的图像减法来计算.
为了可靠地检测到极值,有一个重要的问题,关于如何在尺度和空间域确定采样频率.这里,我们使用由Lowe所做的设置,每倍频程有3个尺度,高斯G的标准偏差σ设置为0.5.
除了所有的采样问题,和应用一些阈值来消除不可靠的特征,SIFT方法计算了空间拉普拉斯算子L(x,y,σ)的尺度空间极值(xi,yi,σi),和这些每个极值的正方形图像小块样品的中心(xi,yi),这对其邻居有主导梯度.因为在尺度σi产生的图像小块是基于梯度方向搜索,它的光照变化是不变的.此外,只有梯度方向的局部直方图被保留,SIFT描述符对平移和旋转是不变的.
1.2 仿射SIFT(ASIFT)
SIFT方法的主要成分是,结合模拟所有查询图像缩放和旋转标准化及平移的想法.基于这个想法,ASIFT方法模拟两个相机轴参数,经度角和纬度角(相当于倾斜),然后应用SIFT方法来模拟尺度(缩小)和标准化平移和旋转.
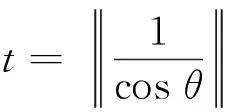
步骤2:由于要考虑计算效率,对有限数量的纬度角和经度角执行采样步骤.
步骤3:查询图像中,所有模拟的图像用相似度匹配方法(SIFT)进行比较.
1.2.2 用两种分辨率计划加速ASIFT 两种分辨率方案是用来加速计算两幅图像之间相似性过程.该方案的主要思想就是,首先选择仿射变换,在低分辨率产生足够的匹配.然后,在这些选定的仿射变换和在原始分辨率的图像中,模拟查询和搜索到的图像.最后,计算这些模拟图像之间的相似性.两种分辨率的步骤的方案总结如下:
步骤1:使用高斯滤波器和降低采样运算符,计算查询图像u和搜索图像v的低分辨率图像.得到的低分辨率图像,可以定义为:
u′=PFGFu,v′=PFGFv,
(4)
其中,u′和v′各自是u和v的低分辨率图像.GF和PF各自是高斯滤波器和降低采样运算符.下标F代表运算符因子的大小.
步骤2:对u′和v′应用ASIFT方法.
步骤3:选择M仿射变换,产生u′和v′之间良好的匹配.
步骤4:在步骤3选择的M仿射变换下,对u和v应用ASIFT方法.在M仿射变换中,选择最好的匹配作为u和v之间的相似性.
同一个人的面部姿态和角度变化得越大,SIFT方法就越无法找到任何匹配.在所有的例子中,ASIFT方法的匹配能力明显优于SIFT方法.
1.3 提出的方法
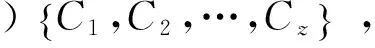
(5)
其中,Ei(j)表示如下
(6)
H(i)是一个长度为z的直方图,同时,它也是这种人脸的视觉单词表示法.两张人脸中,两种视觉单词表示法之间的距离,可以由巴氏距离评估.
1.4 视频序列中人脸识别性能评估
视频序列的人脸分类有很多方案,如概率多数表决制和在文献[7]中提到的贝叶斯最大后验概率的方案.在两个方案中,可通过考虑该测试图像和当前视频序列中所有图像之间的相似性,来计算测试图像和视频序列之间的相似性.这是不恰当的,因为同一个人具有不同的面部姿势的两张人脸图像可能会带来较低的相似性.这将降低同一个人测试图像和视频序列之间的整体相似度.本文定义测试图像w和视频序列S之间的相似性为:
(7)
其中,si是在视频序列S中的人脸图像.该定义中,在一张测试图像和视频序列中所有人脸图像之间的相似性中,我们只使用最大的相似性.
2 实验仿真
2.1 人脸数据库
使用流行的Yale及ORL人脸数据库来估算人脸识别的性能.
Yale人脸库包含了15个人的165张人脸,每人11张,包括了不同光照条件(灯光往左照射、往右照射、往中间照射),不同的面部表情(正常的、开心的、沮丧的、睡着的、惊讶的以及眨眼的),不同场景的(戴眼镜的和不戴眼镜的),如图1所示为Yale人脸库中一个人的11副具有不同特征的人脸图像.

图1 Yale人脸库中某人的11副人脸图像
ORL人脸库共有40个人的400张图片,每人10张,其中有些图像是拍摄于不同时期的,人的脸部表情和脸部细节有着不同程度的变化,比如笑或者不笑、眼睛或睁或闭、戴或不戴眼镜,人脸姿态也有相当程度的变化,深度旋转和平面旋转可达20度,人脸尺度也有多达10%的变化.如图2所示为ORL上某人的10张人脸图像.

图2 ORL人脸库中某人的10张人脸图像
2.2 实验结果及分析
对于所有的视频序列,Yale的人脸检测第一次用于检测每帧中的人脸,然后,检测到位置的人脸是不正确的帧将手动删除.所有检测到的人脸通过光照补偿进行预处理.在实验中,分别用每个对象的训练人脸序列前25帧,和测试人脸序列的前100帧用来进行性能评估.在Yale数据库和ORL数据库中使用的视觉短语数量分别为9 000和16 384.
实验中,我们分别选取Yale及ORL人脸库中的前5幅人脸图像作为训练样本,剩下的人脸图像作为测试样本.此外,我们将本文中的方法与几种经典的方法的单训练样本识别率进行了比较,包括PCA[2],(PC)2A[4],以及SIFT视觉单词[5],局部Gabor二值模式(LGBP)[6], LBP[8].
针对上面提到的几种比较方法,本文作者的实验步骤简单介绍如下.PCA方法中,取95%的能量来确定主成分数;(PC)2A方法中只有1个自由参数α,是人脸图像的投影组合权重,文献[4]中提到,当α的值在0.1至0.5之间时,(PC)2A的性能对α不敏感,因此,在实验中取值0.3;类似地,在LBP中,人脸图像的分块对性能的影响很大,在实验中采用了4种不同的分块数(16、32、40、72),选取了最佳的实验结果(72);LGBP、及SIFT视觉单词的所有参数设置都与参考文献相同.几种方法在Yale及ORL上的实验结果如表1所示.

表1 6个方法在Yale上的人脸识别率
通过表1可以清晰地看到,在Yale及ORL人脸库上,本文方法的识别率明显高于文献其它方法.其中,在Yale上,本文方法比PCA方法高了16个百分点,比(PC)2A方法高了13个百分点,比LBP方法高了12个百分点,比LGBP方法高了14个百分点,比SIFT视觉单词方法高了16个百分点,本文方法的优越性由此可见.
在ORL人脸库上,本文方法比PCA方法高了近8个百分点,比(PC)2A方法高了5个百分点,比LBP方法高了4个百分点,比LGBP方法高了3.7个百分点,比SIFT视觉单词方法高了2个百分点,再次验证了本文方法的高识别率.
本文方法在SIFT视觉单词的基础上,引入了仿射思想,与SIFT视觉单词方法相比较,识别率得到了大大地提高,由此可见,仿射对解决表情、光照等的变化是很有效的.
3 结束语
本文针对基于视频的人脸识别问题进行了研究,采用了仿射尺度不变特征变换(ASIFT)方法,利用视觉单词,在兴趣点提取尺度不变特征变换的图像描述,并且借助于高斯差分检测,生成基于K均值的视觉单词,以索引取代描述符,实现了人脸的识别吗,解决了由于面部姿态、面部表情和光照条件变化所带了的失真问题.
在Yale及其ORL两大人脸数据库上进行了实验,证明了本文所提方法的优越性.仿射尺度不变特征变换(ASIFT)方法的引用,提高了人脸识别率,但在一定程度上增加了额外的计算开销,所以,如何在提高识别率的同时,改进算法的效率,将是进一步研究的重点.
[1]ZhangZ,WangJ,ZhaH.Adaptivemanifoldlearning[J].IEEETransactionsonPatternAnalysisandMachineIntelligence, 2012, 34(1):131-137.
[2]Arandjelovic'O.Computationallyefficientapplicationofthegenericshape-illuminationinvarianttofacerecognitionfromvideo[J].PatternRecognition, 2012, 45(1): 92-103.
[3]ConnollyJF,GrangerE,SabourinR.Anadaptiveclassificationsystemforvideo-basedfacerecognition[J].InformationSciences2012, 192(1): 50-70.
[4]LoweD.Distinctiveimagefeaturesfromscale-invariantkeypoints[J].IntJComputVis, 2004, 60(2): 91-110.
[5]XieZ,LiuG,FangZ.Facerecognitionbasedoncombinationofhumanperceptionandlocalbinarypattern[J].LectureNotesinComputerScience, 2012, 72(2): 365-373.
[6]JiangX,MandalB,KotA.Eigenfeatureregularizationandextractioninfacerecognition[J].IEEETransPatternAnalysisandMachineIntelligence, 2008, 30(3): 383-391.
[7]HafizF,ShafieAA,MustafahYM.Facerecognitionfromsinglesampleperpersonbylearningofgenericdiscriminantcectors[J].ProcediaEngineering, 2012, 45(1): 465-472.
[8]WrightJ,YangAY,GaneshA,etal.Facerecognitionviasparserepresentation[J].IEEETransPatternAnalysisandMachineIntelligence, 2009, 31(2): 210-227.
Face recognition based on bag-of-visual word model
CUI Jiantao, FAN Naimei, DENG Lujuan
(School of Software, Zhengzhou University of Light Industry, Zhengzhou 450002)
Recent years, face recognition based on video has been concerned by more and more persons. At the same time, bag-of-visual words (BoWs) representation has been successfully applied in image retrieval and object recognition recently. In this paper, a video-based face recognition approach which uses visual words is proposed. In classic visual words, scale invariant feature transform (SIFT) descriptors of an image are firstly extracted on interest points detected by difference of Gaussian (DoG), then k-means-based visual vocabulary generation is applied to replace these descriptors with the indexes of the closet visual words. However, in facial images, SIFT descriptors are not good enough due to facial pose distortion, facial expression and lighting condition variation. In this paper, we use Affine-SIFT (ASIFT) descriptors as facial image representation. Experimental results on Yale and ORL Database suggest that proposed method can achieve lower error rates in face recognition task.
face recognition; bag-of-visual word; image retrieval
2014-09-11.
国家自然科学基金项目(61040025).
1000-1190(2015)01-0025-04
TP391.41
A
*通讯联系人. E-mail: 66617880@qq.com.
