综合用户特征和项目属性的协作过滤推荐算法改进
2015-03-08高良友黄梦醒
高良友,黄梦醒
(海南大学 信息科学技术学院, 海南 海口 570228)
综合用户特征和项目属性的协作过滤推荐算法改进
高良友,黄梦醒
(海南大学 信息科学技术学院, 海南 海口 570228)
摘要:在综合用户特征和项目属性的协作过滤推荐算法的基础上,提出了一种改进的基于综合用户特征和项目属性的协作过滤推荐算法,分析不同用户群体对不同项目属性的普遍评分,并结合已评分的项目属性,预测未评分项目.仿真结果表明,改进算法比原算法具有更高的推荐精准度,并进一步降低数据集的稀疏性和缓解冷启动问题.
关键词:协作过滤; 稀疏性; 用户群体; 项目属性
随着互联网技术的发展,可以方便地获取到丰富的信息资源,但同时也容易被海量信息淹没,造成了严重的“信息过载”现象.个性化推荐系统是用来处理严重的“信息过载”问题的常用手段,而在个性化推荐系统中,协作过滤算法是最为经典,应用最为广泛,并且是常用的个性化推荐算法之一.协作过滤算法中最常用的算法有基于用户的协作过滤推荐算法和基于项目的协作过滤推荐算法.基于用户的协作过滤推荐算法[1]的基本思想是用户对未评分项目的预测评分值可以由与该用户相似度最高的K个近邻用户对当前用户未评分项目的评分值进行加权平均而得出.基于项目的协作过滤推荐算法[2]和基于用户的协作过滤推荐算法的原理相近,其基本思路是用户对未评分项目的预测评分值可以由该用户对和当前项目相似度最高的K个近邻项目的评分值进行加权平均而获得.在现实应用当中,伴随着用户数量或项目数量的逐步提升,上述2种协作过滤推荐算法需要处理的数据量越来越大,导致其性能会变差.对于新项目问题,基于项目的协作过滤推荐算法可以在一定程度上缓解问题,但是对于新用户问题,基于用户和基于项目的协作过滤推荐算法都将会失效[3].Sarwar[2]和Deshpande[5]等通过实验得出在同样的应用情境下基于项目的协作过滤推荐算法的推荐精准度比基于用户的协作过滤推荐算法的推荐精准度要高.但是,基于项目的协作过滤推荐算法也同样不可避免地存在数据集稀疏性、冷启动等问题,导致个性化推荐系统的推荐精准度存在瓶颈.
针对以上的问题,国内外学者进行了大量的科学研究.文献[6]对于个性化推荐系统中存在的过度拟合和数据集稀疏性等问题,提出了邻居模型、因子分解模型和情绪上下文相结合的协作过滤推荐算法来解决这些问题.文献[7]对于协作过滤推荐算法普遍存在的由于数据更新需要重复进行相似度的计算而带来的可扩展性问题,以及数据集稀疏性和冷启动等问题,提出了一种基于项目分类的协作过滤推荐算法,并将云模型引入到个性化推荐系统中,两者的结合有效地解决了传统基于云模型协作过滤推荐算法所存在的误推荐问题.文献[8]对传统协作过滤推荐算法中所存在的数据集稀疏性问题,从而导致推荐精准度不高的问题,提出了一种基于云填充和项目属性的协作过滤推荐算法,首先利用云模型中的数据对用户评分矩阵中的稀疏数据进行填充,然后根据传统的相似度计算方法,得出项目之间的相似度,同时计算项目的属性相似度,将2个相似度通过加权因子得到最终的项目之间的相似度.文献[9]在基于项目分类的协作过滤推荐算法的基础之上提出了一种改进算法,先根据用户项目的分类数据,获得用户对类内部尚未评分项目的评分估计值,再计算类内部的用户之间的相似度获得目标用户的最相近的邻居用户,最后产生推荐.
文献[6]和[7]中的算法都有效地缓解了数据集稀疏性的问题,并在一定程度上提高了推荐系统的推荐精准度,但均没有将项目属性作为影响因子考虑到推荐系统中.在实际应用中,项目属性是决定用户偏好的重要因素.文献[8]和[9]中在协作过滤算法中引入项目属性信息,但也还存在一些不足之处:1)在数据集极度稀疏的情境下,仅仅通过项目属性值很难预测出其他未评分项目的评分预测值;2)在对用户进行评分预测时,没有考虑到用户所在群体的普遍评分,而用户对项目的评分值,很多情况下接近其所在群体的普遍评分值[10].文献[10]在预测用户对未评分项目的评分预测值的时候,同时考察用户的特征信息和项目的属性信息,进一步缓解了数据稀疏性和冷启动问题.但是,综合用户特征和项目属性的协作过滤推荐算法也存在很多需要进一步完善的地方: 1)项目属性矩阵填充的普遍评分值和实际情况会有较大的差异; 2)评分预测值计算公式不能适用于方差为零的情况;3)待填充属性的选取方法比较粗糙;4)不能很好地处理多个特征对于相同属性的叠加效应.
本文针对综合用户特征和项目属性的协作过滤推荐算法所存在的缺点进行改进.对于每一个用户,综合用户的多个特征,确定具有这些特征的用户群体,并且计算用户群体对不同项目属性的普遍评分,将超过一定比例的项目属性评分次数的项目属性普遍评分预填充到该用户的项目属性矩阵中.在进行评分预测时,将计算公式进行修改,使其适用于方差为零的情况.仿真结果表明,本文算法提高了推荐精准度,并进一步降低数据集的稀疏性和缓解冷启动问题.
1基于项目的协作过滤推荐算法
基于项目的协作过滤推荐算法主要包括相似度计算、评分预测算法等.
1.1相似度计算基于项目的协作过滤推荐算法所采用的相似度计算公式主要有如下几种
1) 余弦相似度
(1)
其中,simij表示项目i和项目j之间的相似度,Ii和Ij表示项目i和项目j的评分向量.
2) 修正的余弦相似度
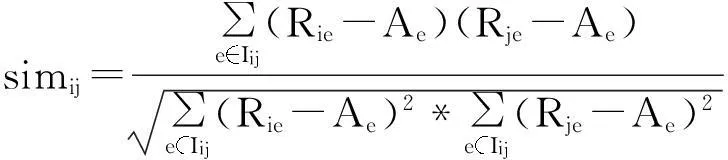
(2)
其中,Rie是用户i对项目e的评分,Ae为共同评分的项目中用户i的平均评分,Iij是被用户i和用户j共同评分的项目集合[11].
3) 皮尔逊相关系数

(3)
这3种计算项目和项目之间相似度的公式都有各自不同的适用场景.本文选取余弦相似度计算公式是为了和文献[10]中的算法进行对比.
1.2评分预测计算本文采用和文献[12]相同的评分预测计算公式
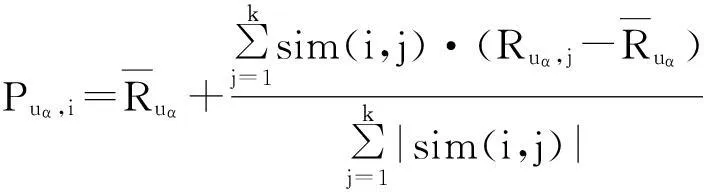
(4)
2综合用户特征和项目属性的协作过滤推荐算法改进
2.1 综合用户特征和项目属性的协作过滤推荐算法的不足
1) 在预测用户对未评分项目的评分预测值的过程中,文献[10]会为每个用户的项目属性矩阵填充普遍评分,但填充的这个普遍评分值却总是一个固定的值(固定值为评分区间的中间值avg).在很多情形下,此种做法不符合实际情况.若评分区间为[1,5],具有某个特征的用户评价特定属性的项目10 000次,但是这个评分值很低,总为1,按照文献[10]的算法,为此属性填充3.
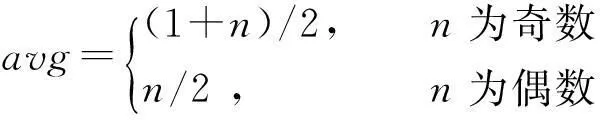
(5)
其中n为评分区间的最大值.
2) 文献[10]的评分预测值计算公式不能适用于方差为零的情形,而在冷启动和数据集极端稀疏的情况下,方差为零的情形比较常见.

(6)
其中,Pu,i表示用户u对项目Itemi的评分预测值,avgk是项目Itemi的项目属性k在用户u的均值矩阵当中的数值,vark表示项目Itemi的项目属性k在用户u的方差矩阵当中的数值.
3) 选取待填充属性的方法比较粗糙:①仅仅根据评分人数来确定待填充属性,而评分人数和评分值之间没有必然的联系;②不同特征的评分用户数目相差较大,但文献[10]总是为每个不同特征选取相同数量的待填充属性.
4) 没有考虑到多个特征对于相同属性的叠加效应.比如某个特征对于一个属性的评分值很高,另外一个特征对于这个属性的评分值也很高.现有一个用户同时具备这2个特征,如果按照文献[10]的算法,在评分区间为[1,5]的情况下,此用户对于这个属性的评分预测值仍然是3.
2.2 改进算法的算法步骤
1) 根据已有用户对项目的评分数据的基础上,建立用户-项目评分矩阵,如表1所示.
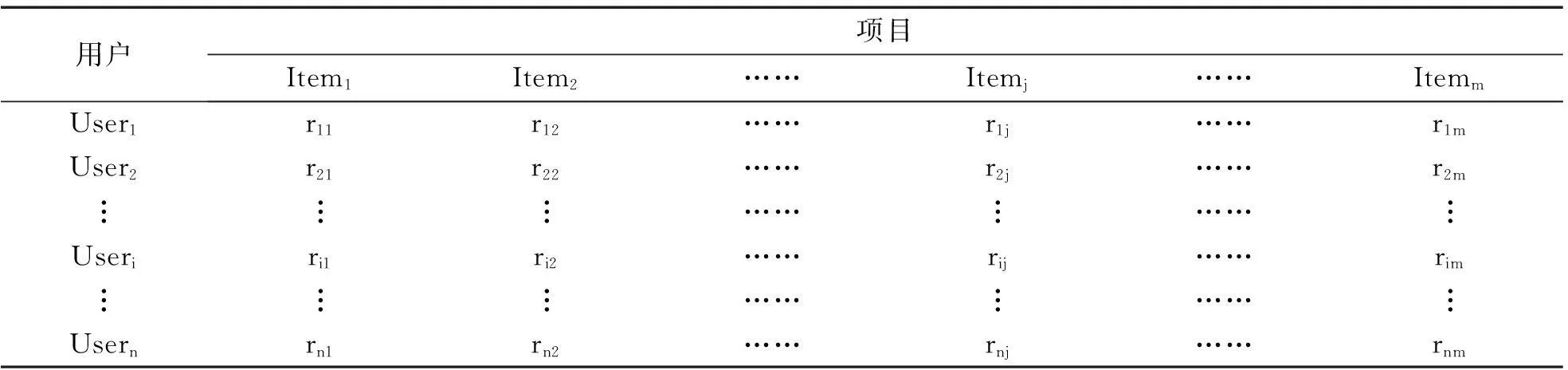
表1 用户-项目评分矩阵
表1中,Itemj表示第j个项目,Useri表示第i个用户,rij表示第i个用户对第j个项目的评分值.若第i个用户对第j个项目有评分信息,则rij为相应的评分;否则rij=0,表示第i个用户尚未对第j个项目评分.
2) 为每个用户建立各自的项目属性评分矩阵,并对每个项目属性评分矩阵进行初始化.任一用户Useri的项目属性评分矩阵,如表2所示.
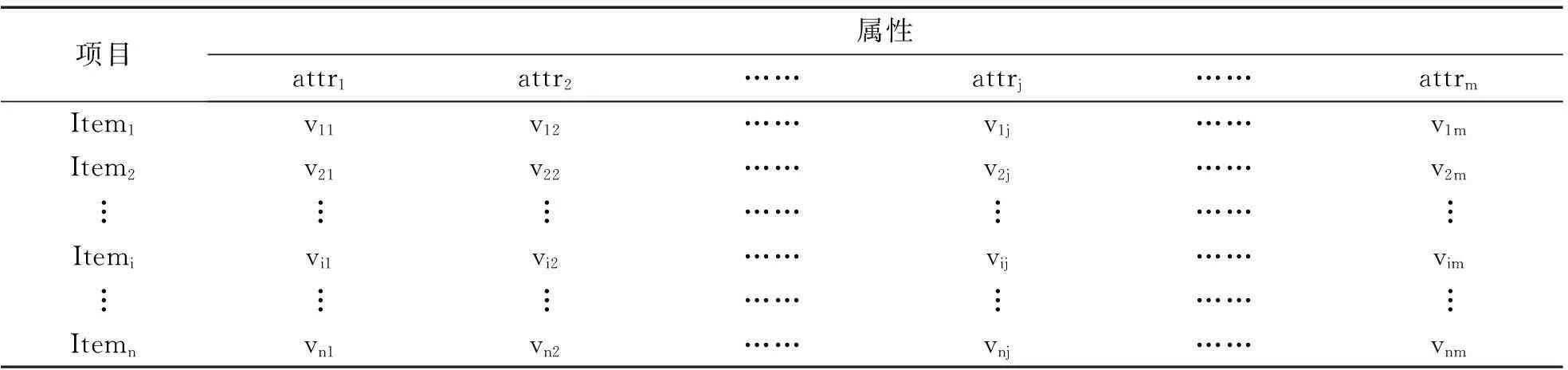
表2 用户Useri的项目属性评分矩阵
表2中,Item1,Item2,…,Itemn表示系统中的所有项目,attr1,attr2,…,attrm表示系统中的所有项目属性集合的并集.初始化每个项目属性评分矩阵是让任一Useri的项目属性评分矩阵中的元素vij均为零.
3) 对用户的项目属性评分矩阵填充用户-项目评分矩阵中的相应非零元素.若用户Useri对项目j的评分为rij≠0,则使Useri的项目属性评分矩阵中

(7)
其中,rij表示用户i对项目j的评分,attrm表示属性m,Attrj表示项目j包含的属性集合.
4) 根据用户的性别、年龄和职业等信息唯一地确定了一个用户群体,统计此用户群体中所有用户的数目sum、任一项目属性的评分次数attrCount[i]和评分总和attrSum[i].
5) 从用户群体中选择满足attrCount[i]≥sum*percent(其中,percent为0到100%之间的数,本文算法采用10%)的项目属性,并添加到候选的待填充属性集Atrribute中.
6) 遍历该用户未评分项目的所有属性,考察其是否属于候选的待填充属性集Atrribute.若是,则为项目属性矩阵填充普遍评分值attrSum[i]/attrCount[i].
7) 对于用户的项目属性评分矩阵中不全为零的列,计算此列的均值和方差,并将结果填充到此用户的均值矩阵和方差矩阵中.用户Useri的均值矩阵和方差矩阵如表3和表4所示.

表3 用户Useri的均值矩阵
表3中,avgi表示用户Useri对属性attri的均值.

表4 用户Useri的方差矩阵
表4中,vari表示用户Useri对属性attri的方差.在用户Useri的方差矩阵当中,如果某一列的方差超过了限定最大值,则就将该方差设为零.
8) 在用户-项目评分矩阵中,如果用户u对项目Itemi的评分值为零(也就是未评分),但是在该用户的项目属性评分矩阵中项目Itemi所对应属性的属性评分值并不为零,则可以通过以下公式计算出该用户对项目Itemi的预测评分值.计算公式如下
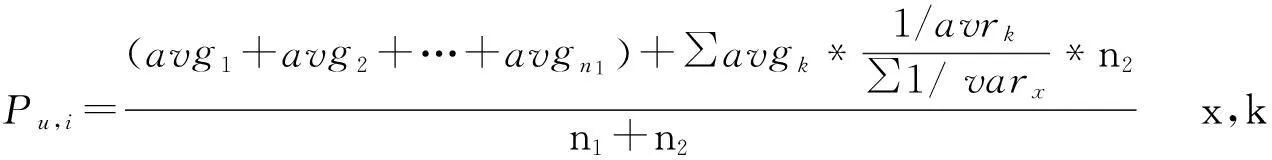
(8)
其中,avgk是项目Itemi的项目属性k在用户u的均值矩阵当中的数值,vark表示项目Itemi的项目属性k在用户u的方差矩阵当中的数值,X代表项目Itemi的项目属性集合,n1表示项目Itemi的项目属性中方差为零的项目属性数目,n2表示项目Itemi的项目属性中方差不为零的项目属性数目.
9) 通过式(8)计算出来的用户对项目的预测评分值,填充该用户的用户-项目评分矩阵.
10) 用式(1)计算出项目和项目之间的余弦相似度,并结合式(4)得出评分预测值.
3实验结果与分析
3.1数据集与度量标准本文的实验仿真数据集利用Minnesota大学项目组GroupLens Research所提供的含10万多条评分记录的MovieLens电影评分数据集,此数据集是由943个用户对1 682部电影所做出的评分数据.MovieLens站点的评分范围是1到5的整数,数值越大,说明此用户对这部电影的喜爱程度越高[12-13].
平均绝对误差(Mean Absolute Error, MAE) 是个性化推荐系统中应用非常广泛的一种评价标准,用来计算测试数据集中通过推荐算法计算出来的预测值和用户的真实评分之间的绝对误差值.MAE值越小,推荐系统的推荐精准度就会越高.
MAE的计算公式为
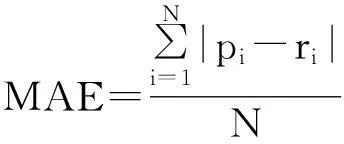
(9)
其中,pi表示用户对项目的预测评分值,ri表示用户对项目的真实评分.
3.2实验结果与分析本实验的目的是将本文的改进算法和文献[10]中的综合用户特征和项目属性的协作过滤推荐算法(USERITEM-CF)进行比较.为了提高实验结果的真实性,从10万条评分记录的电影评分数据集中随机抽取100个用户的评分记录组成仿真数据集,并将仿真数据集按照8∶2的比例划分成训练数据集和测试数据集,实验结果如图1所示.
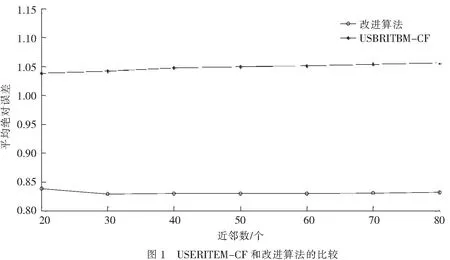
图1可以得出,1)本文的改进算法为用户的项目属性矩阵填充的普遍评分值相对于综合用户特征和项目属性的协作过滤推荐算法预填充的普遍评分值而言,更加具有动态性,同时也更加合理;2)综合用户特征和项目属性的协作过滤推荐算法的评分预测值计算公式在方差值为零的情况下,整个公式会失效,而方差为零的情况在数据集极端稀疏和冷启动等情形下会比较常见.本文改进算法采用了新的评分预测值计算公式,使其能够适用于方差为零的情况;3)改进算法中选取待填充属性的方法比原有算法更加合理; 4)综合用户特征和项目属性的协作过滤推荐算法没有考虑到多个特征对于相同属性的叠加效应.本文的改进算法通过用户的多个特征信息唯一地确定了一个用户群体,很好地解决了此问题.
此外,在随机抽取100个用户的实验数据中,当近邻数取40、50、60和70时,改进算法和原有算法的MAE值都比较稳定,但改进算法的MAE比原有算法的MAE更小.
综上所述,本文的改进算法可以获得比综合用户特征和项目属性的协作过滤推荐算法更好的推荐质量,同时可以进一步降低数据集的稀疏性,缓解冷启动问题.
4小结
首先分析当前协作过滤算法研究当中所存在的一些问题、相应的解决方法以及这些方法的优缺点,然后针对综合用户特征和项目属性的协作过滤推荐算法中所存在的不足之处进行相应的改进,提出了一种改进算法.该改进算法同时根据用户的多个特征信息唯一地确定了此用户所在的用户群体,并将该用户群体的社会普遍项目属性评分数值填充进此用户的项目属性评分矩阵中,然后计算用户对不同项目属性的均值和方差,再通过公式得出此用户对未评分项目的评分预测值,并将其填充到此用户的用户-项目评分矩阵中,改进算法同时改进了评分预测值计算公式,使其能够适用于方差为零的情形.仿真结果表明,该改进算法提高了推荐的精准度,同时进一步降低数据集的稀疏性和缓解冷启动问题.
参考文献:
[1] Chen Z M, Jiang Y, Zhao Y. A collaborative filtering recommendation algorithm based on user interest change and trust evaluation[J]. International Journal of Digital Content Technology and its Applications, 2010, 4(9): 106-113.
[2] Sarwar B M, Karypis G, Konstan J A, et al. Item-based collaborative filtering recommendation algorithms[M]. New York: ACM Press, 2001: 285-295.
[3] 雷琨. 电子商务个性化推荐系统研究[D]. 成都:电子科技大学, 2012.
[4] Su X Y, Taghi M K. A survey of collaborative filtering techniques[J]. Advances in Artificial Intelligence, 2009, 2009(4): 1-20.
[5] Deshpande M, Karypis G. Item-based top-nrecommendation algorithm[J]. ACM Trans Information Systems, 2004, 22(1): 143-177.
[6] 王强强. 基于项目与情绪的协同过滤算法研究与实现[D]. 北京:北京邮电大学, 2013.
[7] 刘芹. 结合项目分类和云模型的协同过滤算法研究[D]. 重庆:重庆大学, 2012.
[8] 孙金刚, 艾丽蓉. 基于项目属性和云填充的协同过滤算法[J]. 计算机应用, 2012, 32(3): 658-660, 668.
[9] 熊忠阳, 刘芹, 张玉芳,等. 基于项目分类的协同过滤改进算法[J]. 计算机应用研究, 2012, 29(2): 493-496.
[10] 孙龙菲, 黄梦醒. 综合用户特征和项目属性的协作过滤推荐算法[J]. 计算机应用研究, 2013, 31(2): 384-387.
[11] Wang M J, Han J T. Collaborative filtering recommendation based on item rating and characteristic information prediction[M]. New York: IEEE, 2012: 214-217.
[12] 张玉芳, 代金龙, 熊忠阳. 分步填充缓解数据稀疏性的协同过滤算法[J]. 计算机应用研究, 2013, 30(9): 2 602-2 605.
[13] 夏培勇. 个性化推荐技术中的协同过滤算法研究[D]. 青岛:中国海洋大学, 2011.
Improvement of Algorithm for Collaborative Filtering Recommendation Based on User Characteristics and Item Attributes
Gao Liangyou, Huang Mengxing
(College of Information Science and Technology, Hainan University, Haikou 570228,China)
Abstract:Based on the algorithms for collaborative filtering recommendation and integrated user characteristics and item attributes, an improved algorithm based on user characteristics and item attributes was introduced to further improve the sparsity of data set and cold start problem and improve the recommendation accuracy. The algorithm predicted ungraded items by analyzing the general score of different user groups on different project attributes and synthesizes the attributes of rated items. The simulation results showed that the improved algorithm has the better prediction accuracy and further reduces the sparsity of data set and cold start problem.
Keywords:collaborative filtering; sparsity; user group; item attributes
中图分类号:TP 393
文献标志码:ADOl:10.15886/j.cnki.hdxbzkb.2015.0025
文章编号:1004-1729(2015)02-0135-06
收稿日期:------------------------ 2014-09-05基金项目: 国家自然科学基金项目(71161007,61462022);海南省重点科技计划项目(ZDXM20130078)
作者简介:高良友(1988-),男,安徽安庆人,2012级硕士研究生.通信作者: 黄梦醒(1974-),男,教授,研究方向:数据与知识工程、云计算与物联网、个性化服务等,E-mail:huangmx09@163.com
