大数据技术在通信行业的应用探讨
2015-03-02江苏省通信管理局通信发展与保障处堵雯曦
江苏省通信管理局通信发展与保障处 堵雯曦
大数据技术在通信行业的应用探讨
江苏省通信管理局通信发展与保障处 堵雯曦
大数据正在深入到各行各业。介绍了大数据概念,并对大数据的存储、挖掘分析和综合展示等技术分别进行了阐述,最后对大数据在通信行业的应用进行了分析。
大数据;数据处理平台;非结构化数据
引言
自从20世纪中期计算机诞生以来,伴随着科技和社会的发展进步,数据的数量不断增多,质量不断提高。尤其是近年来,随着互联网应用技术的全面发展,带来的大规模音频、文字、图片视频等半结构化、非结构化数据,社交网络、物联网、云计算广泛应用,使得个人可以更加准确快捷的发布、获取数据,数据规模、数据种类正在以极快的速度增长,可以说大数据时代[1]已然降临。
面对如此增长迅速的数据资源,特别在数据规模急剧增长的同时,数据类型也越来越复杂,包括结构化数据、半结构化数据、非结构化数据等多种类型,采用传统数据处理手段已难以进行处理。因此,大数据技术应运而生,将大量数据不经过模型和假设直接交给计算机进行处理,从而发现某些传统方法难以得到的规律和结论。
1 大数据概念
大数据作为一个新兴概念,至今尚无确切、统一的定义。大数据前身可以认为是海量数据,但海量数据强调了数据量的规模之大,并没有对其特性进行定义。而大数据不仅用来描述大量的数据,还更进一步指出数据的复杂形式、数据的快速时间特性以及对数据的分析、处理等专业化处理,最终获得有价值信息的能力。当前,较为统一的认识是大数据有4个基本特征:数据规模大(volume),数据种类多(variety),数据要求处理速度快(velocity),数据价值密度低(value),即所谓的4V特性。这些特性使得大数据区别于传统的数据概念。
1.1 数据规模大
数据规模大是大数据的基本属性,根据互联网数据中心(IDC)[2]的定义,至少要有超过100 TB的可供分析的数据。导致数据规模不断增长的原因较多,比如随着各种传感器数据获取能力的大幅提高,使得人们获取的数据越来越接近原始事物本身,描述同一事物的数据量激增。另外,早期的结构化数据,对原始事物进行了一定程度的抽象,数据维度低,数据类型简单,数据量有限,增长速度慢;而随着应用的发展,数据维度越来越高,描述相同事物所需的数据量越来越大,数据越来越接近真实的世界,数据的描述能力不断增强,数据量本身必将以几何级数增长。
1.2 数据种类多
数据类型繁多,复杂多变是大数据的重要特性。以往的数据尽管数量庞大,但通常是事先定义好的结构化数据。这类数据只需事先分析好数据的含义以数据间的相互关系,再根据其属性,将数据存储在合适的位置,就可以方便的处理、查询,限制数据处理能力的只是运算速度和存储空间。而随着互联网络与传感器的飞速发展,非结构化数据大量涌现。非结构化数据没有统一的结构属性,增加了数据存储、处理的难度。而时下在网络上流动着的数据大部分是非结构化数据,人们上网不只是看看新闻,发送文字邮件,还会上传下载照片、视频、发送微博等非结构化数据。大数据正是在这样的背景下产生的,大数据与传统数据处理最大的不同就是重点关注非结构化信息。
1.3 数据处理速度快
要求数据的快速处理,是大数据区别于传统海量数据处理的重要特性之一。随着各种传感器和互联网络等信息获取、传播技术的飞速发展普及,数据呈爆炸的形式快速增长,新数据不断涌现,快速增长的数据量要求数据处理的速度也要相应的提升,才能使得大量的数据得到有效的利用。如果数据尚未得到有效的处理,就失去了价值,大量的数据就没有意义。对不断激增的海量数据的实时处理要求,是大数据与传统海量数据处理技术的关键差别之一。
1.4 数据价值密度低
数据价值密度低是大数据关注的非结构化数据的重要属性。传统的结构化数据,依据特定的应用,对事物进行了相应的抽象,每一条数据都包含该应用需要考量的信息。而大数据为了获取事物的全部细节,不对事物进行抽象、归纳等处理,直接采用原始的数据,保留了数据的原貌。这样虽然可以分析更多的信息,但也引入了大量没有意义的信息,甚至是错误的信息,因此相对于特定的应用,大数据关注的非结构化数据的价值密度偏低。
2 大数据技术
依据大数据生命周期的不同阶段,可以将与大数据处理相关的技术分为相应的大数据存储、大数据挖掘分析和大数据综合展现3个方面。
2.1 大数据存储
从海量数据时代开始,大规模数据的长期保存、数据迁移一直都是研究的重点。从20世纪90年代末至今,数据存储始终是依据数据量大小的不断变化和不断优化向前发展的。其中主要有:DAS(直接外挂存储),NAS(网络附加存储),SAN(存储域网络)和SAN IP等存储方式。这几种存储方式虽然是不同时代的产物,但各自的优缺点都十分鲜明,数据中心往往是根据自身的服务器数量和要处理的数据对象进行选择。
此外,这两年数据存储的虚拟化从研究走向现实。所谓虚拟化,就是将原有的服务器进行软件虚拟化,将其划分为若干个独立的服务空间,如此可以在一台服务器上提供多种存储服务,大大提高了存储效率,节约存储成本,是异构数据平台的最佳选择。从技术角度来讲,虚拟化可以分为存储虚拟化和网络虚拟化。网络虚拟化是存储虚拟化的辅助,能够大幅度提升数据中心的网络利用率和传输速率。目前IBM、浪潮、思科等公司纷纷发力虚拟化市场,可以预见虚拟化会成为未来大数据存储的一个主流技术[3]。
此外,采用NoSQL(非关系型的数据库),去除了关系数据库的关系型特性,简化了数据库结构,便于对数据和系统架构进行扩展。此外,NoSQL可以自定义数据存储格式,是一个非常灵活的数据模型。
NoSQL的优势:
1)易扩展。去掉了关系数据库的关系型特性,数据之间无关系,非常容易扩展。
2)大数据量,高性能。NoSQL数据库具有非常好的读写性能,尤其在大数据量下同样表现优秀。
3)灵活的数据模型。NoSQL无需事先为要存储的数据建立字段,随时可以存储自定义的数据格式。
4)高可用。NoSQL在不太影响性能的情况,可以方便地实现高可用的架构。
2.2 大数据挖掘分析
数据挖掘是从数据集中识别出有效的、新颖的、有用的、最终可理解的模式知识的复杂过程。在大数据的处理技术中,超大规模的数据挖掘一直是难点,也是重点。面对上百TB,甚至PB级别的异构数据,常规的处理工具往往难以担当重任。需要考虑到的是大数据是个不断生长的有机体,因此在挖掘过程中还要考虑到未来数据继续增长所带来的影响。
因此,大数据的挖掘需要采用分布式挖掘和云计算。Google公司一直是分布式挖掘技术的领导者,它研发了MapReduce分布式计算框架[4],英特尔公司在此基础上开发了Hadoop分布式挖掘平台。两者都具有高效、高扩展、高可靠性和高容错率的特点,并提供免费版本,适用于各种类型的大数据挖掘。
2.2.1 Google云计算平台
Google云计算平台主要由文件存储、并行数据处理、分布式锁和结构化数据表4部分组成,其构成如图1所示。
由图1可知,Google4 云计算平台的文件存储采用GFS(谷歌分布式文件系统)[5],并行数据处理技术采用MapReduce[6],分布式锁采用Chubby[7],结构化数据表采用的是BigTable[8],这些共同构成计算平台,为上层的云计算应用服务。
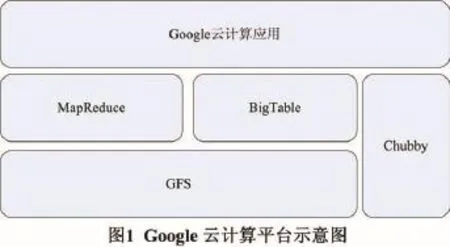
GFS由一个的主服务器和多个块服务器组成,并可以多个客户端的访问,数据存储在块服务器,并且在主服务器上保存其索引。客户端通过查询主服务器,获取所需文件的索引,然后从块服务器上获取所需要的文件。MapReduce是Jeffery Dean设计的一个新的并行处理模型,将并行化、容错、数据分布、负载均衡的等繁琐的实现细节进行封装,用户只需编写简单的计算代码,而并不必关心算法的并行处理过程。Chubby是Google为解决分布式一致性问题而设计的提供粗粒度锁服务的文件系统,其他分布式系统可以使用它对共享资源的访问进行同步。BigTable基于GFS和Chubby的分布式存储系统,对数据进行结构化存储和管理,从而快速地从海量信息中寻找需要的数据。Google现有的平台技术是大数据的成功应用经验,可以作为系统构建时的借鉴和参考。
2.2.2 开源大数据处理平台Hadoop
Hadoop是一个能对大量数据进行分布式处理的软件框架,起源于一个开源的Apache基金会项目,随着越来越多用户的加入,经过不断使用、贡献和完善,已经形成一个强大的生态系统。由于具备低成本和高扩展性,受到许多IT厂商的关注,目前已经成为大数据处理平台的事实标准。Hadoop在业内已有一些比较成功的应用,如Yahoo、Facebook、淘宝等,用于数据统计和分析。
Hadoop的架构如图2所示。主要部件包括:
1)HDFS(Hadoop 分布式文件系统)。用于提供廉价、高可靠性的超大容量的存储。
2)MapReduce(并行数据处理)。当处理一个大数据集查询时会将其任务分解,并在运行的多个节点中处理,体现了分布式计算优势。将这种技术与Linux服务器结合可获得性价比极高、替代大规模计算阵列的方法。
3)Hbase。它以Google BigTable为蓝本,目标是快速在主机内数十亿行数据中定位所需的数据并访问它。HBase利用MapReduce处理内部的海量数据。
4)Pig(数据分析平台)和Hive(数据仓库)。对开发人员来说,直接使用Java API(应用程序接口)可能很乏味,也很容易出错,同时也限制了Java程序员在Hadoop上编程的运用灵活性。Hadoop提供了Pig和Hive两个解决方案,使得Hadoop编程变得更加容易。

Hadoop已成为大数据事实标准,包含数十个具有强大生命力的子项目。具有高扩展性、经济性、高可靠性、高效性等四大优势:
1)高扩展性。不论是存储的可扩展性还是计算的可扩展性,都是Hadoop的根本。
2)经济性。能够部署在普通PC(个人计算机)服务器集群之上,以满足苛刻的生产环境业务需求,通过横向扩展完成以前需要小型机、大型机才能完成的任务。
3)高可靠性。分布式文件系统的备份恢复机制以及MapReduce的任务监控保证了分布式处理的可靠性。
4)高效性。分布式文件系统的高效数据交互实现以及MapReduce结合LocalData处理的模式,为高效处理海量的信息作了基础准备。
目前,随着Hadoop应用不断深入,其扩展性受限、单点故障、难以支持MapReduce之外的计算、多计算框架各自为战,数据共享困难等问题逐渐显露,因此Hadoop2.0版本YARN(另一种资源协调者)应运而生,并已逐步开展应用。
2.3 大数据综合展示
大数据综合展示就是数据的可视化技术,就是要能够艺术性地将数据进行可视化分析,简单明了而且能够展现出数据之间的关联关系。从内容来说,大数据的分析分为技术和方法两种类型;从技术上讲,主要是分布式的数据分析和非结构化数据处理等;从方法上讲,主要是利用常用的数理统计方法来进行数据分析,例如使用可视化的数据分析工具。但两者是一个有机的整体。大数据处理的最终目的是为了将数据之间的关系以可视化的方式呈现在用户面前,包括了处理的全部过程和展现的过程。在数据分析过程中,不仅仅是需要计算机进行自动化的分析,更需要人工进行数据选择和参数的设定,两个是辩证的关系。
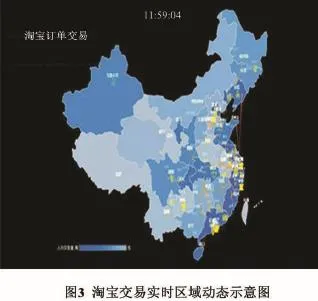
数据显示是将数据经过分析得到的结果以可见或可读形式输出,以方便用户获取相关信息。对于传统的结构化数据,可以采用数据值直接显示、数据表显示、各种统计图形显示等形式来表示数据,而大数据处理的非结构化数据,种类繁多,关系复杂,传统的显示方法通常难以表现,大量的数据表、繁乱的关系图可能使用户感到迷茫,甚至可能误导用户。利用计算机图形学和图像处理的可视计算技术成为大数据显示的重要手段之一,将数据转换成图形或图像,更加直观,方便用户分析结果。可视化的决定性因素包括从数据中分析提炼的信息、信息所属的数据关系种类、想通过图表表达的观点、想要强调的重点。如图3所示,可以直观地反映淘宝在全国范围内,某一时刻的下单情况。又比如大家熟知的支付宝十年账单,都是非常好的数据可视化的典范。
?
3 大数据的应用
目前,信息技术业、互联网行业、商业、遥感探测已经开始应用大数据技术来进行研究和生产效益,大数据的浪潮很快就会覆盖大部分的行业领域。百度、淘宝等公司作为信息技术、互联网和商业领域的杰出代表,已经对大数据开始了深度应用,大数据的技术与应用的前景不可估量。我们必须充分认识到大数据所能带来的革命性改变,保持创新与进步,从而站在行业的最前沿。
以通信行业用户精确营销为例,传统的实体渠道、封闭的电子渠道只重视对用户的单点营销,不重视对社交网络传播能力的利用,投入大、成本高,无法形成良好的传播效果。而基于数据挖掘对社交网络信息进行分析、建立社交网络分析模型和开展营销研究,为企业开辟新营销渠道、实施精准营销、增强营销效果打下良好基础。
主体框架为:
首先是建立交往圈。将用户作为网络节点,通信交往关系做边。保留高强度节点、去除低强度或无联系节点,整理数据形成社交网络。
第二是建立关键联系人模型。根据用户之间的联系信息,建立模型,获得用户在社交网内的影响力、影响范围,结合三网属性和消费行为等信息得到关键人或关键群。
第三是扩散强度评估。测算初始扩散点(业务订购用户)对社交网络其他成员的影响力,是否达到预期效果,不断改进算法,从而获得交往圈内用户自传播的预期效果。
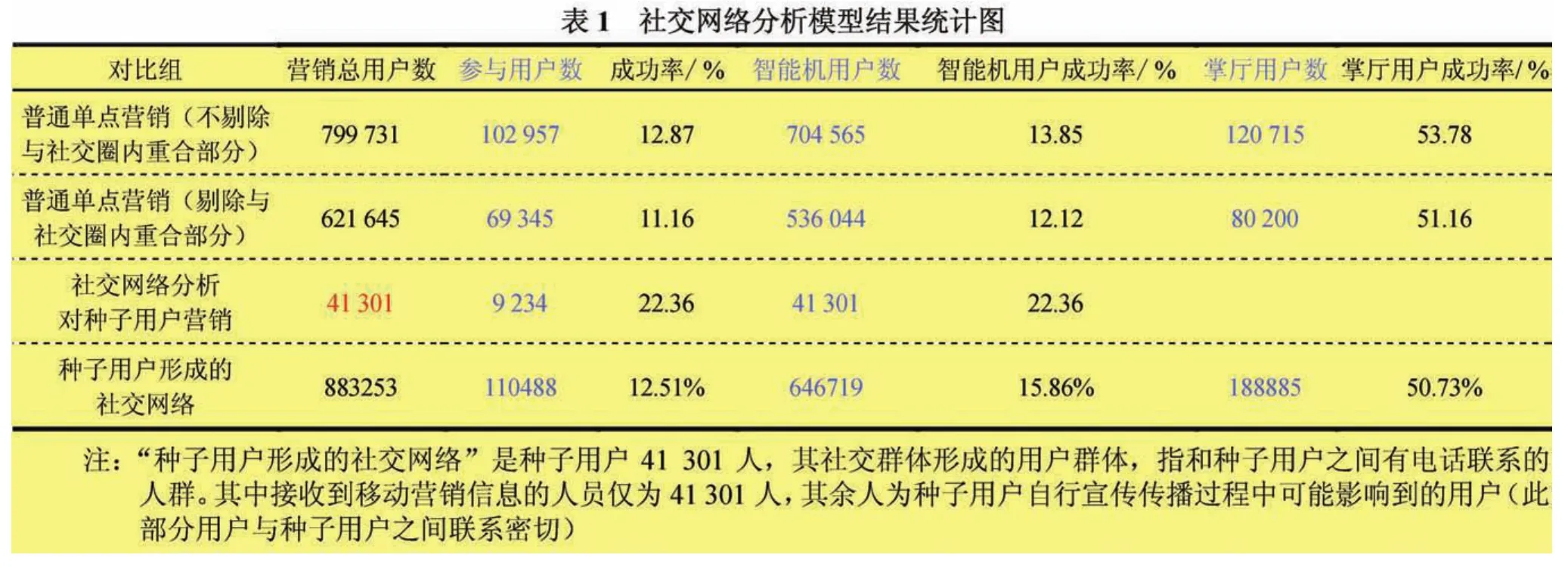
2015年1月,中国移动通信集团江苏有限公司某分公司利用社交网络分析模型对“爱分享,抢流量”活动进行营销,针对部分在网用户通话交往情况进行数据分析得到4万种子用户,然后通过精确营销对此4万用户进行活动宣传。活动结束后,对活动整体情况进行了统计和对比,结果见表1。
整体来看,以社交网络关键点模型营销的用户群,需直接营销的用户较少,仅4万人,其社交网络达到88万人,社交圈内的用户成功参加率为12.5%,此结果与直接单点营销的用户群产的成功率12.9%,有微小差距;在社交圈中,部分用户为非智能机用户,导致其无法参加活动,若以智能机用户来对比,社交网络营销的成功率为15.9%,单点营销成功率为13.9%,明显高于单点营销的成功率;考虑已经安装掌厅的用户的参与成功率,社交网络营销成功率50.7%,单点营销成功率51.1%,社交网络方式略低于单点营销,但是依靠于用户的自传播效应,影响的用户量比较多。总体来讲,社交网络方式的营销直接营销用户少,依靠于关键用户自传播后产生影响广,且成功率较高,对提高用户精确营销率具有积极意义。
4 结束语
随着大数据时代的到来,基于大数据的各种商业模式创新层出不穷,数据一直是通信行业的核心优势,在大数据日益深入的今天,更要充分利用优势资源,借鉴大数据的方法将能够更好地解决通信行业所面临的数据规模大、种类多、速度快、价值密度低等问题,利用新的技术手段对数据进行各种维度的挖掘和分析,从而促进通信行业又好又快发展。
[1] 维克托·迈尔-舍恩伯格. 大数据时代 [M]. 盛杨燕, 周涛, 译. 杭州: 浙江人民出版社, 2012.
[2] WOO Benjamin. World wide big data technology and services 2012-2015 Forecast.2012.5[EB/OL].[2015-04-21] http://ec.europa.eu/information_society/newsroom/cf/dae/document.cfm?doc_id=6242.
[3] 王意洁, 孙伟东, 周松, 等.云计算环境下的分布存储关键技术[J]. 软件学报, 2012,23(4): 962-986.
[4] 覃雄派, 王会举, 杜小勇, 等.大数据分析-RDBMS与MapReduce的竞争与共生[J]. 软件学报, 2012,23(1): 32-45.
[5] DEAN Jeffrey.Designs,lessons and advice from building large distributed system [EB/OL]. [2012-12-05]. http://www.cs.cornell.edu/projects/ladis2009 /talks /deankeynote-ladis2009. pdf.
[6] DEAN Jeffrey, GHEMAWAT Sanjay. Paper about mapreduce[EB/OL]. [2012-12-16]. http://labs.google.com/paper/mapreduce. html.
[7] BURROWS Mike.The chubby lock service for looselycoupled distributed systems[EB/OL]. [2012-11-23]. http://labs.google.com/paper /chubby. html.
[8] CHANGE Fay, DEAN Jeffrey, GHEMAWAT Sanjay, et al. Bigtable: a distribute storage system for structured data[EB/OL].[2012-12-21]. http: //labs.google.com/paper/bigtable.html. ◆
