基于q-gram层次空间的机器翻译中句子相似度计算探析
2015-03-01蒋仁龙蒋子龙
蒋仁龙,蒋子龙
(1.黔南民族师范学院外语系,贵州都匀558000;2.武汉理工大学计算机科学与技术学院,湖北武汉430070)
基于q-gram层次空间的机器翻译中句子相似度计算探析
蒋仁龙1,蒋子龙2
(1.黔南民族师范学院外语系,贵州都匀558000;2.武汉理工大学计算机科学与技术学院,湖北武汉430070)
机器翻译由于其简易性和速度快而成为一个热门的研究对象,然而其翻译质量低也是一个不争的事实。利用q-gram层次空间和Porter Stemming算法,设计了一种计算句子匹配率的方法,并利用算例进行了详细的阐释,从而给机器翻译及英文文本比较提供了一种思路。实验结果表明,该方法在目前基于规则与实例结合的句子相似度计算方法中是可行的。
Porter Stemming Algorithm;q-gram层次空间;相似度
1 引言
机器翻译系统[1]通常可允许针对特定领域加以客制化,以改进翻译的结果。如在政府公文或法律文件中,这类型的句子通常比较正式和制式化,使用机器翻译的结果较为方便。进一步,对于待翻译的句子,通常会从历史库中找与之相似的已完成句子,将翻译提示给使用系统的译员,以提高翻译速度与质量。而快速的从相关历史译文中找到相似的原文,并取得译文参考,这就涉及到比较英文句子的匹配率。本文以比较典型的英文中的简单句、复合句和复杂句的句子相似度为例,笔者测试过100组这样的句子,证实该方法在目前基于规则[2]与实例结合的句子相似度计算方法的效度较高。
2 设计步骤和算法
对于两个待比较的英文句子,我们首先要去除其中没有实际意义的辅助性词汇,如虚词,介词等。其次是对每一个有实际意义的词汇,从它的名词单复数,-ed,-ing等形式中找出最能代表其意义的词干部分,这样才能得出最有比较价值的部分。
相似的英文句子中词项的度量方式通常使用两种:一种为编辑距离(edit distance)[3,4];另一种为q-gram相似度[5,6]。本文选取Tri-gram(3-gram)相似性度量作为统一的相似性标准。分三个步骤计算其相似度去除停用词提取词干构建q-gram层次空间;IV进行相似性计算。
2.1 排除停用词
停用词[7](STOPWORDS)是指在一篇文档中只起到组成句子结构的作用,出现频率较高,却不具备实际意义的词汇。关键词(KEYWORDS)才是句意核心的所在,因此去掉停用词有利于提高匹配的精确度。我们选取数据堂英文停用词表[8]进行实验。
2.2 抽取词干
对一篇英文文档,经过排除停用词后,剩下的即是相对信息含量较高的词汇。而在英文中,形容词和副词有比较级和最高级形式,动词有现在时、过去时、完成时、将来时、动名词形式,名词有复数形式。这些词虽然形式不同,本质的含义却是相同的,如果不加分析,就会影响句子匹配的精确度。我们采用ThePorterStemmingAlgorithm进行词干抽取。算法设计思想[9,10]如下:
如果一个单词的元音-辅音分别由V,C表示,长度大于0的VVV…序列用V表示,长度大于0的CCC…序列是用C表示,任意一个单词或某单词的一部分,都能表示为如下四种形式,CVCV…C;CVCV…V;VCVC…C;VCVC…V;也可以表示为一种总的单一形式[C]VCVC…[V],方括号表示其中内容任意出现,使用(VC){m}来表示VC重复m次,总的单一形式又能表示为[C](VC){m}[V]。m被称为任意单词或单词部分在这种形式中的度量。示例如下:

移除后缀的规则以下面的形式给出(condition) S1-〉S2,意思是如果一个单词以后缀S1结尾,且S1之前的词满足给定的条件,用S2替换S1。条件通常根据m给出,例如:(m〉1)EMENT-〉,此例中S1是“EMENT”,S2是“null”。它将会映射“REPLACEMENT”到“REPLAC”,因为“REPLAC”是m=2的单词部分。
条件部分也可能包含如下:


条件部分可能也包含用and,or,not连接的表达式,因此(m〉1 and(*S or*T))表示一个m〉1且以S or T结尾的词,而(*d and not(*L or*S or*Z))表示一个除了L,SorZ外的双辅音结尾的词。像这样的详细条件很少被要求。
对下面写出的一套规则集,只有一个服从,这个规则就是对于给出的单词能够最长匹配S1的规则。例如,

(此处假设所有的条件都为空),CARESSES映射为CARESS,因为SSES是S1最长的匹配。同样地CARESS映射为CARESS(S1=’SS’),CARES映射为CARE(S1=’S’)。在下面的规则中,其应用的例子,成功或失败,以小写字母在右边给出。算法现在遵守:


映射到单个字符的规则导致了双字符对的移除。-E被放回为-AT,-BL and-IZ,因此-ATE,-BLE和–IZE随后能被识别。E能被移除在step4。
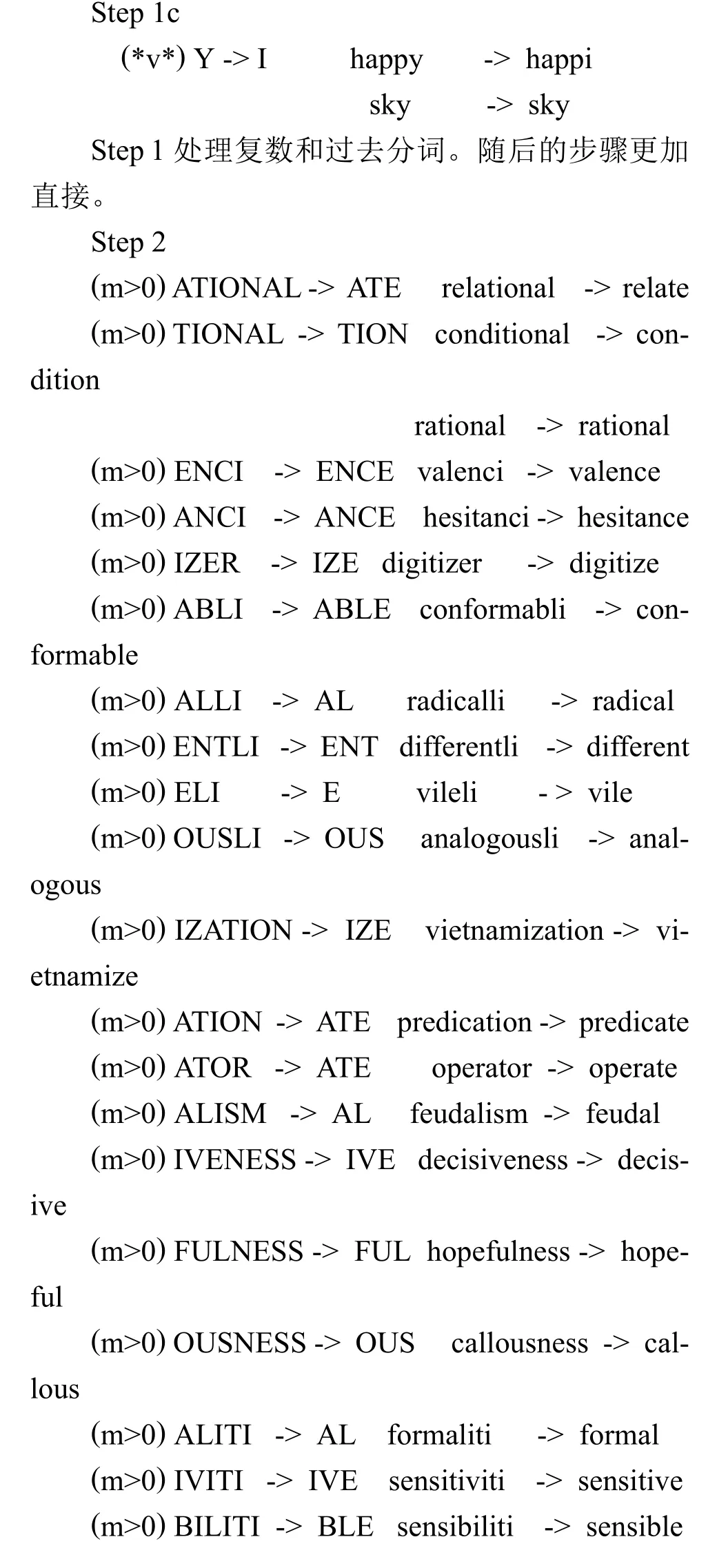
字符串 S1能通过程序转换单词的倒数第二字母来实现。这给了字符串 S1的可能值相当大的突破。事实上step 2中的S1-字符串以它们倒数第二字母的字母顺序出现在这里。相似技巧也应用在其他步骤。


当词太短时,此算法并不会移除后缀,词的长度被它的度量m给出。这个方法没有语言学基础。它仅仅被观察到 m能被相当高效地用来帮助决定是否是明智的对于脱离后缀。例如,如下两个列表:
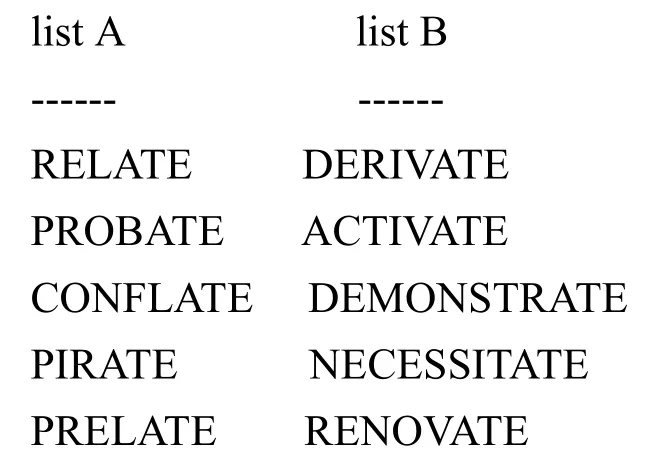
-ATE被从listB中移除出去,但是没有从listB中移除。这意味着词对DERIVATE/DERIVE,ACTIVATE/ACTIVE,DEMONSTRATE/DEMONS-TRABLE,NECESSITATE/NECESSITOUS,将会合并在一起。事实是没有是被前缀的尝试被做来使结果看起来稍微不一致。因而PRELATE没有丢失-ATE,而是ARCHPRELATE变成ARCHPREL.实际上因为前缀的出现减少了错误冲突的可能性。
经过抽取词干后,词汇最终以最本质的构词部分呈现。
2.3 构建q-gram层次空间及进行相似性计算
经过处理后的句子由各个词项(Term)构成,可将各个词项当作字符串来处理。关系R的字段数表示为dom(R),项j的所有字符串集合记为R[j],一个句子记为r,r的第j个项值记为r[j]。定义一个qgram是一个由长度为q的连续字符组成的字符串,故一个总长度为l(l≥q)的字符共有l-q+1个qgram。字符构成上相同的 q-gram在不同的词项中应区别看待,为此,用一个二元组〈j,l1l2…lq〉表示第j个项中出现的一个字符构成上为j,l1l2…lq的q-gram。Gq(r)表示句子r的所有词项的q-gram组成的集合(在计算中q常取1,2,3)。

表1 示例数据

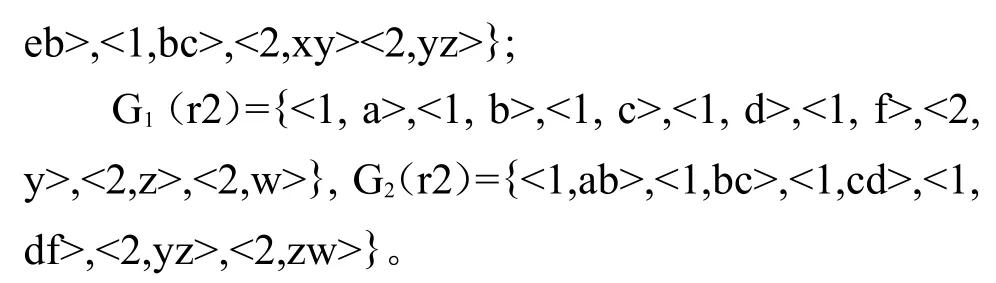
本文中用freqj(l1l2…lq)表示〈j,l1l2…lq〉这个属性在关系的所有记录中的最大出现频率,既freqj(l1l2…lq)=max{〈j,l1l2…lq〉在Gq(r)中的重复数|r∈R}。用F1reqj(l1l2…lq)表示〈j,l1l2…lq〉这个属性在关系的r1记录中的出现频率,用F2reqj(l1l2…lq)表示〈j,l1l2…lq〉这个属性在关系的r2记录中的出现频率。
其中m是q-gram空间[11]的维数。
定义2.曼哈坦距离[12,13]:对于两个点x1={x1,1,x1,2,x1,3,…x1,m}和x2={x2,1,x2,2,x2,3,…x2,m},两点间的距离有:
满足:①d(x1,x2)≥0,距离是一个非负数值;②d (x1,x2)=0,点与自身的距离为0;③d(x1,x2)=d(x2, x1),距离函数具有对称性;④d(x1,x2)≤d(x1,h)+d(h, x2),从点x1到x2的直接距离不会大于途经任何其他点h的距离。


两个记录r1,r2在对应的q-gram空间的相似性可表达为式(1):

则上例关系R所对应的1-gram空间、2-gram空间、3-gram空间如下:
(1)1-gram空间。由于freq1(a)=1,freq1(b)=2,freq1(c)=2,freq1(d)=1,freq1(e)=1,freq1(f)=1,freq2(w)=1,freq2(x)=1,freq2(y)=1,freq2(z)=1,则所形成的1-gram空间是一个以各不同的1-gram作为维度的10维空间:1×2×2×1×1×1×1×1×1×1。

表2 1-gram的10维空间Tab.2 10-dimensional space of 1-gram
r1在1-gram空间的点坐标为(1,2,2,1,1,0,0,1,1,1),r2在1-gram空间的点坐标为(1,1,1,1,0,1,1,0,1,1),Sim1(r1,r2)=0.5。
(2)2-gram空间。由于freq1(ab)=1,freq1(bc)=2,freq1(cd)=2,freq1(de)=1,freq1(df)=1,freq1(eb)=1,freq2(xy)=1,freq2(yz)=1,freq2(zw)=1,因此2-gram空间是一个以各不同的2-gram作为维度的9维空间:1×2 ×2×1×1×1×1×1×1。

表3 2-gram的9维空间Tab.3 9-dimensional space of 2-gram
可知r1在2-gram空间的点坐标为(1,2,1,1,0,1,1, 1,0),r2在2-gram空间的点坐标为(1,1,1,0,1,0,0,1,1),Sim2(r1,r2)=0.4。
(3)3-gram空间。由于freq1(abc)=1,freq1(bcd)=1,freq1(cde)=1,freq1(deb)=1,freq2(ebc)=1,freq2(cdf)=1,freq2(xyz)=1,freq1(yzw)=1,因此3-gram空间是一个以各不同的3-gram作为维度的8维空间:1×1×1× 1×1×1×1×1。

表4 3-gram的8维空间Tab.4 8-dimensional space of 3-gram
可知r1在3-gram空间的点坐标为(1,1,1,1,1,0,1,0),r2在3-gram空间的点坐标为(1,1,0,0,0,1,0,1),Sim3(r1,r2)=0.25。
根据实验统计,当q取1,2,3时,得出的q-gram空间和曼哈坦距离对相似度计算影响最大,我们根据重要程度和经验分别对其赋予不同的权重:k1=0.2;k2=0.4;k3=0.4。
最后,两条记录的相似度可由公式(2)得出:

计算出上例中两句子的匹配率SIM(r1,r2)=0.36。
3 实验结果与分析
随意抽取四组比较句子,得出它们的相似度(见表5)。

表5 相似度比较结果Tab.5 The comparison results of similarity
通过以上表格可以发现该方法在计算两个句子相似度上,充分考虑了关键词对整个句子的影响,并能够用有效的方法提取出关键词中具有实际意义的主干部分,在此基础上运用基于q-gram层次空间的方法对关键词词干的相似性进行了科学精确的计算,得出的总体结果在目前的基于规则的计算方法中效果是很好的。
4 结束语
句子相似度匹配是机器翻译的一个重要环节,计算方法的优劣直接影响到翻译的最终效果。机器翻译诞生50多年以来,因为该领域的复杂性,即使现在基于语义的智能方法[14,15,16]逐渐应用到其中来,发展也一直较为缓慢。基于规则的比较方法因其快速、高效仍然占有重要的地位,探讨更有效的基于规则的句子比较方法将是本文下一步的工作。
[1]郭永辉.英汉机器翻译系统关键技术研究[D].郑州:解放军信息工程大学,2006.
[2]马建军.基于规则和统计的机器翻译方法歧义问题比较分析[J].大连理工大学学报(社会科学版),2010,31(3):114-119.
[3]薛晔伟,沈钧毅,张云.一种编辑距离算法及其在网页搜索中的应用[J].西安交通大学学报,2008,42(12):27-28.
[4]杨志豪,林鸿飞,李彦鹏.基于编辑距离和多种后处理的生物实体名识别[J].计算机工程,2008,34(17):11-14.
[5]Esko Ukkonen.Approximate string-matching with q-grams and maximal matches[J].Theoretical Computer Science, 1992,92(1):191-192.
[6]孙德才.基于q-gram过滤的近似串匹配技术研究[D].长沙:湖南大学,2012.
[7]江兆中.基于语境和停用词驱动的中文自动分词研究[D].合肥:合肥工业大学,2010.
[8]英文停用词表[EB/OL].http://www.datatang.com/data/ 13603.2015-1-7.
[9]M.F.Porter.An algorithm for suffix stripping[J].Program, 1980,(3):130-137.
[10]The Porter Stemming Algorithm[EB/OL].http://snowball. tartarus.org/algorithms/porter/stemmer.html.2014-12-18.
[11]Esko Ukkonen.Approximate string-matching with q-grams and maximal matches[J].Theoretical Computer Science, 1992,92(1):191-192.
[12]Karenkukich.Techniquesforautomaticallycorrectingwords in text[J].ACM Computing Surveys,1992,24(4):377-439.
[13]Robit Ananthak Rishna,Surajit Chaudhuri,Venkatesh Canti.Eliminating fuzzy duplicates in data warehouses[M].San Francisco:Morgan Kaufmann,2002:586-597.
[14]韩习武.机器翻译中语义因素的理论分析[D].哈尔滨:黑龙江大学,2001.
[15]李丹,许霄羽,杨悦.基于语义网技术的网络机器翻译研究[J].现代电子技术,2011,34(4):107-112.
[16]关晓薇.基于语义语言的机器翻译系统中若干关键问题研究[D].大连:大连理工大学,2009.
(责任编辑:魏登云)
An Exploration and Analysis of Sentence Similarity Computing in Machine Translation Based on the“q-gram”Hierarchical Space
JIANG Ren-long1,JIANG Zi-long2
(1.Department of Foreign Language and Literature,Qiannan Normal College for Nationalities,Duyun 558000,China;2.School of Computer Science and Technology,Wuhan University of Technology,Wuhan 430070,China)
Machine translation,with the features of simplicity and fast-speed,becomes a hot research object.However,it is the truth that its qualities are relatively low.Using the algorithm of q-gram hierarchical space and Porter Stemming,this paper designs a kind of method to calculate the matching ratio of sentences and makes detailed explanation with examples,which provides an idea for comparing the machine translation with English text.The result demonstrates that this kind of algorithm is suitable for calculating the sentence similarity basis on rules and instances.
Porter Stemming Algorithm;q-gram hierarchical space;similarity
TP3-0
A
1009-3583(2015)-0089-05
2015-07-12
教育部人文社科基金资助(13YJCZH028)
蒋仁龙,男,湖北天门人,黔南民族师范学院外语系硕士。研究方向:语言学、计算语言学、认知诗学。蒋子龙,男,湖北天门人,武汉理工大学计算机科学与技术学院在读博士。研究方向:机器学习。
