一种改进的文本特征提取算法
2015-02-27刘惠福
马 力, 刘惠福
(西安邮电大学 计算机学院, 陕西 西安 710121)
一种改进的文本特征提取算法
马 力, 刘惠福
(西安邮电大学 计算机学院, 陕西 西安 710121)
针对特征提取忽略特征项语义问题,提出一种基于潜在狄利克雷分配模型(LDA)改进的特征提取算法。该算法基于文档的潜在主题分布,将文档转换为隐含主题与主题下的单词分布按特定比例组成的集合,通过一定的概率选中某个主题,并从该主题下以一定的概率选中某个词语来生成一篇文档。同时,针对LDA算法“平等”对待所有特征项的情况,对LDA模型进行高斯加权。实验结果表明,该算法相比TF-IDF算法、信息增益法,能够提取更多的有效特征,使得分类准确率有所提高。
文本分类;特征提取;潜在狄利克雷;支持向量机
对文本信息快速、有效地进行聚类、分类、检索和过滤已成为自然语言处理重要的应用研究方向,而特征提取则是基础技术之一。目前,最常用的特征提取算法是特征频率-逆文档频率算法(Term Frequency-Inverse Document Frequency, TF-IDF),该算法实现简单而且计算量较小,但易排除中低频有效词,忽略语义的作用[1-2],使分类器性能不佳。TF-IDF存在的不足,目前的改进方法信息增益法能够包括预测类别的信息量,但是容易产生数据稀疏问题[3];期望交叉熵法通过计算特征项的交叉熵来实现特征提取,效果要优于TF-IDF,但提取精确度却受到交叉熵值大小的影响[4]。并且,上述改进方法都没有解决其忽略特征词语语义的问题。本文通过LDA算法来实现文本建模,将文档包含的潜在主题作为文档的特性,基于文档-主题以及主题-词语的方式实现特征提取,并将具有相同语义的特征项归为同一类,并对其进行高斯加权。
1 TF-IDF算法
IDF的目的是提高出现频率较低词语的重要程度来提高文档的可区分度。IDF的表达式[5]为
(1)
其中N表示文本集中文档的数量,ni表示文档集中包含某一词语项t的文档数目。
TF-IDF算法通过计算TF与IDF的乘积来确定词语的权重[6],
(2)
其中:TF(tk,d)表示在文档d中词语tk的个数;T表示经过预处理后文档d中词语的总数;ntk表示包含词语tk的文档数量。
TF-IDF进行特征提取时,是通过计算词频来定义词语的权重,进行分类时是通过计算两个文本向量的相似度来实现分类,而且该方法不会考虑词语或者句子的语义,导致具有相同意思或者有因果关系的两个词语或句子被划分为不同类别,而LDA模型却能够识别这两句话的因果关系,从而达到提升特征提取准确率的效果。
2 改进的特征提取算法
2.1 LDA算法概述
LDA算法使用词袋模型表示方法,把每篇文档看作一个词频向量,忽略文本中词语间的顺序,降低了特征提取的难度。其特征提取训练流程如图1所示。
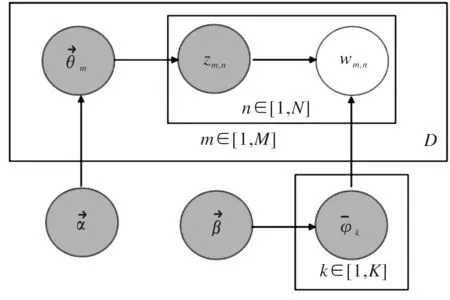
图1 LDA算法的特征提取流程
θm表示文档集中的主题分布。流程α→θm→zm表示生产编号m文档时候,使用参数是α的狄利克雷分布得出该篇文档的主题分布向量θm,再使用该向量得出任意词语所属主题编号:zm,n。φk代表主题下单词分布,数目为K。流程β→φ→wm,n|k=zm,n表示选择主题zm,n为前提的单词分布φk|k=zm,n,在利用φk|k=zm,n获取标号m的文档中任一个词的编号wm,n。
2.2 LDA参数获取
获取LDA参数α和β,需要通过吉布斯采样[7]方法进行迭代来获取,具体步骤如下。
步骤1对整个语料库进行初始化,整个初始化过程都是随机的。对语料中每篇文档中的每个词语随机分配一个主题编号z。
步骤2对语料库实现扫描程序,语料库中的每一个词语w,都要通过吉布斯采样对其进行重新采样。该采样过程实质是在K个主题对应的K条路径上实现采样的,得到该词语的主题,然后对语料库进行更新操作。
步骤3对步骤2进行迭代,当吉布斯采样收敛时停止,得到α和β的值。
步骤4对语料库中的文档-主题矩阵和主题-词语频率矩阵进行统计,上述矩阵即为经过训练的LDA模型。
LDA模型下吉布斯采样的公式为
(3)
2.3 LDA高斯加权
LDA算法经过训练得到的主题分布一般会偏向高频词汇,针对词汇的幂率分布[8]问题,需要对中频词语进行加权。对LDA进行高斯加权(LDAGaussianWeighted,LDA-GW),目的是提高中频词语的权重以及降低高频词语的权重。
对文档中的任一词语m进行加权
(4)
(5)
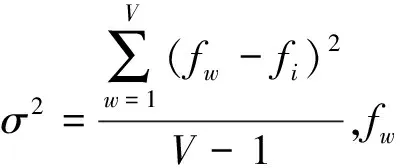
设置训练集的潜在主题数目为10,即K=10,经过训练,获取LDA模型的参数α和β分别为α=0.2,β=0.01。把类别集L,带有类别标签的训练预料集D,以及待分类文本Dnew作为输入交给SVM分类器进行分类获取实验结果。
3 实验结果和分析
3.1 实验环境与语料库
实验环境为一台配备英特尔 i3处理器和4G机身内存,Windows7 32位操作系统的联想笔记本电脑;基于Java 6.0版本,Eclipse3.6编译器。
实验选择的语料库是复旦大学中文语料库[9],分为训练集和测试集。训练集包括环境类(200篇)、计算机类(200篇)、交通类(214篇)、教育类(220篇)、经济类(325篇)、军事类(249篇)、体育类(450篇)、医药类(204篇)、艺术类(248篇)、政治类(505篇)。测试集类别与数目均与训练集保持1:1比例。
每个类别的文档中,特征数为50、75、100、125、150、175、200、225、250的文档数目均占该类别总数的九分之一左右。
3.2 TF-IDF、信息增益法与LDA-GW对比
针对不同的分类目的,自然语言处理领域提出正确率、召回率、F-测度值、微平均、宏平均等文本分类器性能评价方法[10]。本文选取TF-IDF、信息增益法与LDA-GW进行宏平均值和微平均值对比。
3.2.1 宏平均值对比及结果分析
宏平均[10]是每一类文档的分类准确率的算术平均值。TF-IDF、信息增益法与LDA-GW的宏平均值结果如表1所示。
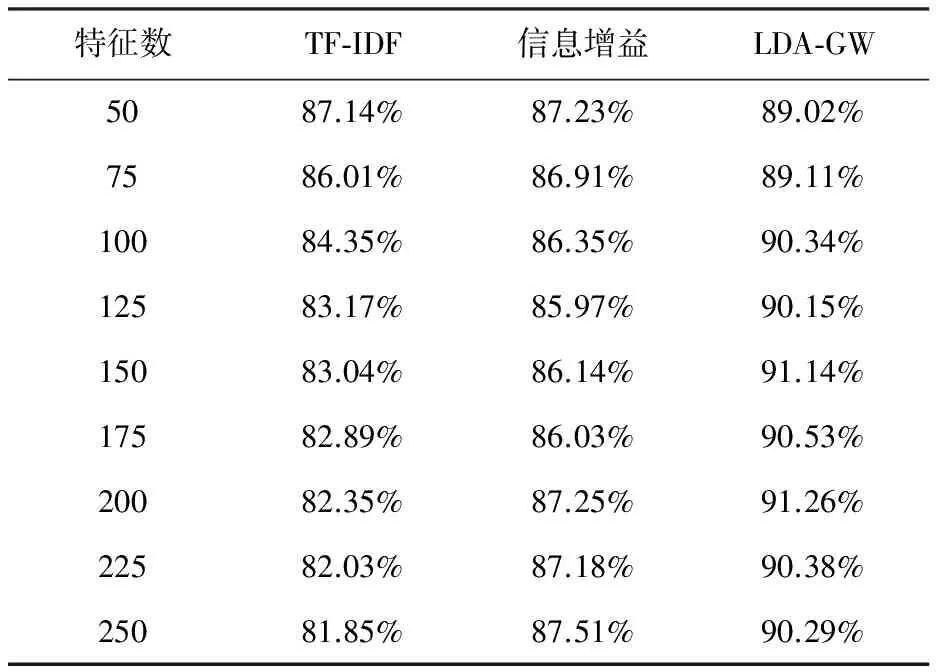
表1 3种特征提取算法的宏平均值
由表1可以看出,特征数的数目与TF-IDF宏平均值呈现反比趋势,基于信息增益法和LDA-GW的分类效果则逐渐趋于平稳,对比可知LDA-GW的效果略好于信息增益法。当特征数为200时,LDA-GW的最大分类宏平均值0.912 6;当特征数为250时,LDA-GW能够达到最优宏平均值0.902 9。
3.2.2 微平均值对比及结果分析
微平均[11]每一个实例文档的分类准确率的算术平均值。TF-IDF、信息增益法与LDA-GW的微平均值结果如表2所示。
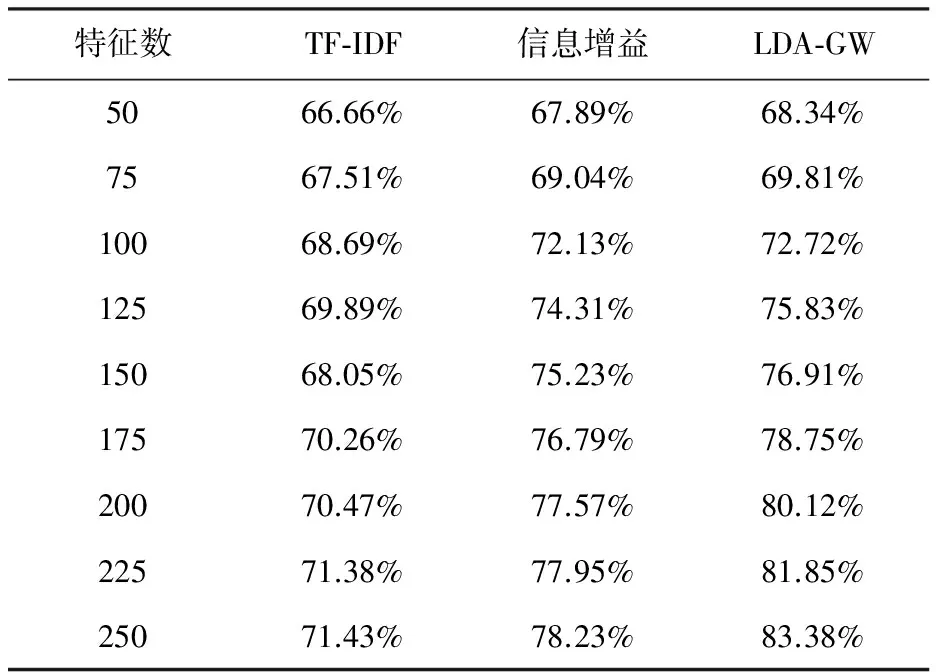
表2 3种特征提取算法微平均值
由表2可知,特征数与3种特征选取方法的微平均值成正比。当特征数增加,3种特征选取方法的正确率均提高;当特征数小于100时,3种方法获取到的微平均值相差不大;当特征数进一步变大时,LDA-GW与信息增益法表现出一定的优势,而TF-IDF则相对显得不够精确;当特征数大于200时,LDA-GW 又优于信息增益法。
LDA-GW在处理特征词较多的文档时,效果与LDA算法相比,并不是很明显,但是在处理特征词语较少的文档,如政治类文档时,效果要好于LDA算法。其原因就在于政治类文档往往包含多种特征词,但是数量都不是很多,因此可以使用LDA-GW进行特征提取。
4 结束语
使用LDA算法进行特征提取,以“文档-主题”和“主题-词语”分布作为基础,将文本表示为其隐含主题的分布,考虑特征词语义的关联性,并使用高斯加权方法对中频特征项进行加权。将通过LDA算法特征提取得到的文本与SVM分类器结合进行分类,测试实验结果表明,通过LDA算法选取的特征更能够代表文本的主题类别,同时对LDA进行特征加权之后,在遇到频数不高但具有代表意义的特征词时,能够将其归为重要特征词类别。
[1] Blei. Probabilistic topic models[J]. Communications of the ACM, 2012, 55(4): 77-84.
[2] Robertson S E, Van R C J, Porter M F. Probabilistic models of indexing and searching[C]//Proceedings of the 3rd annual ACM conference on Research and development in information retrieval.Cambridge:Cambridge University Press,1980: 35-56.
[3] 宗成庆.统计自然语言处理[M].北京:清华大学出版社,2013:343-354.
[4] Lewis. Representation and learning in information retrieval[D]. USA:University of Massachusetts, 2008:18-26.
[5] Fan R E, Chang K W, Hsieh C J, et al. LIBLINEAR: A library for large linear classification[J]. The Journal of Machine Learning Research, 2008, 9(11): 1871-1874.
[6] 路永和,李焰锋.改进TF-IDF算法的文本特征提取权值计算方法[J].图书情报工作,2013,57(3):2-5.
[7] 邱奕飞.基于潜在狄利克雷分配模型的文本分类方法研究[D].西安:西安邮电大学,2014:23-40.
[8] 张小平, 周学忠, 黄厚宽. 一种改进的LDA模型[J]. 北京交通大学学报, 2010, 34(2): 5-6.
[9] 王治和, 杨延娇.对简单向量距离文本分类算法的改进[J]. 计算机科学, 2009, 36(1): 236-238.
[10]李文波, 孙乐. 基于Labeled-LDA模型的文本分类新算法[J]. 计算机学报,2008, 31(4): 7-10.
[11]马力,张娟.基于社团结构的文本聚类算法研究[J].西安邮电大学学报,2013,15(2):7-9.
[责任编辑:祝剑]
Study on the extraction of characteristics of chinese text based on the LDA model
MA Li, LIU Huifu
(School of Computer Science and Technology, Xi’an University of Posts and Telecommunications, Xi’an 710121, China)
A model based on Latent Dirichlet Allocation (Latent Dirichlet Allocation, LDA) feature extraction algorithm is proposed to tackle the problem in which inverse document frequency method (term frequency, inverse document frequency, TF-IDF) ignores feature semantics in feature extraction. The proposed algorithm is based on the underlying theme distribution of document, to convert text to implied themes and theme words collection with a distribution according to certain proportion, and to realize feature extraction according to the key semantics. At the same time the algorithm uses Gaussian weighting to treat all the characteristics of the item as “equality”. Experiments results show that the proposed algorithm can extra more effective features and improve the accuracy of classification compared with TF-IDF and mutual information method.
text classification, feature extraction, potential Latent Dirichlet, SVM
2015-1-24
西安市科技计划资助项目(CXY1437(8))
马力(1961-),男,博士,教授,从事智能信息处理研究。E-mail:mali@xupt.edu.com 刘惠福(1988-),男,硕士研究生,研究方向为自然语言处理。E-mail:458087914@qq.com
10.13682/j.issn.2095-6533.2015.06.017
TP391
A
2095-6533(2015)06-0079-04
