基于偶然性正确测试用例发现的错误定位方法
2015-01-15冯潞潞丁佐华
冯潞潞,丁佐华
浙江理工大学 科学计算与软件工程中心,杭州 310018
1 引言
基于程序谱的软件错误定位方法(CFL)是通过统计分析程序运行时对代码行的覆盖信息以及测试用例运行结果数据来进行软件错误定位的方法。尽管CFL方法提出比较早,但是最近的研究[1]表明,CFL方法在多错误情况下依然有着良好的定位效果。因此,如何能提升CFL的定位效果是很有意义的。
当某一个测试用例运行到了错误行,但是其结果是pass(与标准程序输出相同)时,称这个测试用例为偶然性正确(coincidental correctness)测试用例。很多文献[2-6]的研究都证明了偶然性正确测试用例对CFL有着严重的影响,并且在其文章中都提出了一些判断偶然性正确的方法以及对怀疑度计算公式的修正方法。但是目前的判定偶然性正确测试用例的方法都有一定的局限性,比如误判率(false positive)很高,对于CFL方法的定位效果不一定有提升,或者不具有普遍性,复杂度高。
因此本文针对CFL方法中的“偶然性正确”这个现象进行了研究,发现了一种误判率为0的偶然性正确测试用例的判定方法,并且改进了文献[6]中基于偶然性正确测试用例的软件错误定位方法,最后通过实验验证了方法确实可以改进CFL定位效果。
2 基本概念介绍
2.1 经典的基于谱的错误定位方法介绍
尽管CFL方法有很多[7-10],但是文献[11-13]说明效果比较好的CFL方法有Tarantula[7]和Ochiai[8]等,在文献[1]中也特别说明了这两种方法,并且使用了Ochiai方法做CFL多错误效果实验分析。
这两种方法的定义分别为:

其中符号含义如下:passed(s):通过第s行结果为pass的用例总数;fail(s):通过第s行结果为fail的用例总数;totalfailed:结果为fail的测试用例的总数;totalpassed:结果为pass的用例总数。
使用这两种方法的计算结果见图1。

图1 Tarantula和Ochiai方法计算实例
图1示例子中有6个测试用例,图中的黑点表示这一行被对应的测试用例运行时所覆盖了。空格则表示这一行在测试用例运行时没有被覆盖。最后T_suspiciousness和O_suspiciousness分别为用Tarantula方法和Ochiai方法所计算出来的怀疑度值。Rank为怀疑度从大到小的排序,怀疑度越高则rank值越小。排序之后从rank值为1的行开始检查代码看是否出错,直到找到错误行为止。在找到错误行之前所检查代码的百分比,即定义为score值,用来评判错误定位方法的好坏程度。从本例中可以看到,使用这两种方法所标记的rank值为1的行正好为错误代码行。
2.2 研究动机
在本文第一章中有介绍:当某一个测试用例运行到了错误行,但其结果为pass的时候,这一次测试被称为偶然性正确。
经典的CFL方法的提出是基于2个假设:
假设1:通过某一行,fail数量越多,那么这一行出错的概率越高。
假设2:通过某一行,pass数量越多,那么这一行出错的概率越小。
显然,若每次运行到错误行,测试结果都是FAIL,那么以上假设就可以很好地帮助定位错误行。而偶然性正确例子的存在却使得以上的假设可靠性降低。偶然性正确对于CFL方法的影响在相关研究中也有说明[6]。
经过观察研究发现,在很多情况下,会出现同一种覆盖轨迹(比如例子中的t1和t6,均覆盖了1,2,3,4,6,7,13行),有些测试用例的结果是pass(如t1),但是有的会是fail(如t5)。这种情况下很明显t1的pass是偶然性正确。图1例子中,当偶然性正确这一列(t1)结果设置为fail时,错误语句的怀疑度就可以提升为1,尽管此例中怀疑度顺序没有发生变化(因为错误行已经被准确定位),但是提升了错误行的怀疑度,显然有助于更好地来定位错误行。
3 本文方法
3.1 判定偶然性正确测试用例
基于2.2中的分析,本文提出了一种判定方法:
判定1:当N次测试轨迹相同时,若其中有一次运行失败,则这N次测试中运行结果为pass的测试用例为偶然性正确(MYCC)。
由偶然性正确的定义知道,判定偶然性正确测试用例有两个条件:第一是其测试结果为pass;第二是其运行时覆盖了错误代码行。对于某一种运行轨迹,若其结果为fail,那么它一定运行到了错误代码行。那么当另一次测试中,产生了相同的轨迹,但是测试结果为pass的时候,那么这次测试很明显满足了偶然性正确测试用例所需的两个条件。可以参考图1中t1和t5的轨迹。
因此,判定1是合理的,而且这样的判定是没有误判率的。
接下来需要说明这种情况的普遍性。例如,当某些错误仅仅引起了数值上的错误,却并没有影响到逻辑上的变化,则运行到错误行在某些情况下会出错,但是路径却不会发生改变(如表1中例1所示);或者在循环时,若循环条件出错,那么没有运行到边界值则结果不会出错,但是这些成功的测试用例确实运行到了错误行(如表2中例2所示)。
表1和表2的测试用例部分,覆盖信息都是针对错误程序的,1表示覆盖了这一行,0表示没有覆盖这一行。以上的2个例子均说明了判定1的存在性。

表1 偶然性正确示例一

表2 偶然性正确示例二
基于以上的分析知,在成功的测试用例中,寻找轨迹与某条失败测试用例相同的测试用例,即为本文所判定的MYCC。下面给出判定MYCC的基本算法:

其中fail_trace_file为所有测试中运行失败时的程序的语句覆盖轨迹文件,pass_trace_file为测试中所有运行成功时程序的语句覆盖的轨迹文件。
3.2 基于偶然性正确对CFL的改进方法1
接下来要说明的是,在得到MYCC之后,要如何使用它才可以改进已有CFL方法的定位效果。
在3.1节的分析中给出了一种很直观的修正方法,就是将偶然性正确测试用例作为失败的测试用例使用。具体的操作为将MYCC的测试结果人为地设置为fail。这么做的原因是,CFL定位方法是基于假设1和假设2的,偶然性正确测试用例覆盖了错误行,显然只有将它的运行结果设置为失败,才不会违背假设1和假设2。因此将偶然性正确测试用例作为失败测试用例来使用,才可以提升错误语句的怀疑度。
在文献[11]中对于偶然性正确的现象进行了分析,并且将这种处理偶然性正确的方法用公式来表现。经过其修正后的公式如下:
MyTarantula:

需要说明的是,尽管本文只是用tarantula和ochiai算法对本方法的应用,事实上对其他的CFL方法也可以使用类似的改进公式来处理。因此寻找偶然性正确测试用例对于改进CFL方法有着普遍适用性。
3.3 基于偶然性正确对CFL的改进方法2
以上提出的方法1确实可以提升错误语句的怀疑度,但是在提升错误语句怀疑度的同时,偶然性正确测试用例所覆盖的正确语句的怀疑度也同时被提升了。因此需要分析相关正确语句对于错误语句是否会有影响。
经过实验研究发现,方法1的修正公式对于MYCC并不是单调的。即会有以下现象的存在:尽管sus(s1)>sus(s2),mycc(s1)>mycc(s2),但是sus′(s1)<sus′(s2)。
这个现象表明,即使在寻找偶然性正确测试用例时没有误判率,某些情况下正确语句怀疑度的提高会比错误语句的怀疑度提高的更多,这种情况就会影响到方法1的实际的错误定位效果。
因此,在提升了错误语句怀疑度的同时,还需要考虑如何来降低相关正确语句的怀疑度。
在实验研究中发现,只有当某条语句failed(s)/totalfailed非常小的时候,才会出现正确语句的怀疑度提升比错误语句的怀疑度提升的更多,甚至影响到最终的怀疑度序列。依据假设1,当failed(s)/totalfailed非常小的时候,这一行是错误行的概率也会很小。因此本文对θ进行了分析筛选,希望可以改进以上方法1的定位效果。
令MYCC(i)/MYCC=θ,则由公式所代表的含义知,θ值越小,则这一行是错误行的可能性越小。类似于文献[11]的分析,对于错误行,θ的期望应该属于[0.6 1]。因此首先选定某个θ值,当某一行满足θ=0.8时,才提升s语句的怀疑度,否则不进行提升。通过这样的方法来尽量避免将正确语句的怀疑度提高。以tarantula方法为例,具体修正方法如下:

对ochiai方法以及别的CFL方法也可以用相似的方式改进。
4 实验相关
4.1 实验设计
本文的实验使用了经典的siemens[14]数据集进行实验。siemens数据集可以从 SIR(http://sir.unl.edu/content/sir.html)网站上免费获得,其包含内容如图2所示。本文中实验在错误版本的选择方面与文献[11]是一致的,一共选择了122个可用的错误版本来进行实验。本文的方法对于一般的CFL方法都有效,在本文实验时仅选取了具有代表性的tarantula方法以及ochiai方法进行了分析。

图2 siemens实验集
4.2 实验结果与分析
首先,使用3.1节中提出的判定算法在siemens实验集上对于本文提出的寻找MYCC的方法进行了验证,证明了MYCC的存在性(见表3),验证了此判定方法确实没有误判率(见表4),以及计算了使用方法1之后,对于错误语句怀疑度的提升效果(见表5)。
接下来,使用了3.2节的方法1,对tarantula方法和ochiai方法分别进行了实验,实验结果如表6所示。
从表6中可以看出,方法1确实可以提升错误语句的怀疑度数值。具体分析有如下结论:(1)score值为same的情况有2种。第一种为没有找到偶然性正确测试用例,因此score值不会发生变化;第二种为,尽管找到了偶然性正确测试用例,但是由于相关的正确语句的怀疑度也提升了,并没有引起怀疑度序列的变化,因此此时score值也不会发生变化。(2)score值为better的情况表明,将MYCC设置为FALSE会使得定位效果提升。(3)score值为worse的情况说明,会有某些正确语句怀疑度提升比错误语句怀疑度提升还高。其中,(3)的现象的存在正好印证了3.3节中所说的现象,单纯地寻到偶然性正确测试用例并不能很好地提升错误定位效果。
接下来使用3.3节中的方法2进行实验,分别选择了θ=0.6和θ=0.8两种情况进行实验,实验结果如图3,图4所示。

表3 siemens实验集中MYCC数量

表4 理论MYCC数量与实验MYCC数量比较

表5 错误语句提升效果

表6 使用方法1定位效果分别与tarantula方法和ochiai方法的比较

图3 综合比较图-tarantula
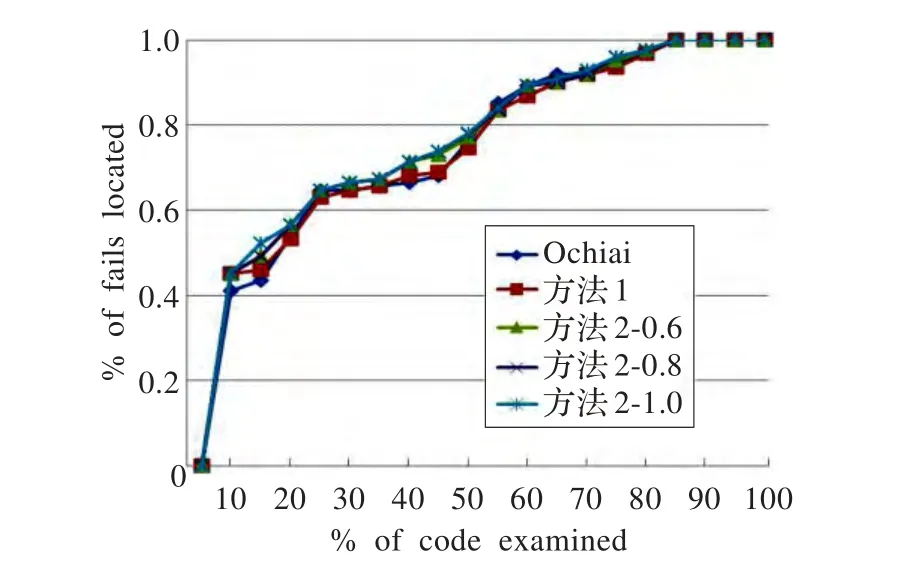
图4 综合比较图-ochiai
从图3可以看出,方法2对于方法1的修正效果还是很明显的,可以有效地提升tanrantula和ochiai的定位效果。
另外还可以看出,尽管对于本文的方法来说,θ=1的时候会取到最优解,但是对于θ=0.6的情况,也可以很大程度上减少正确语句对错误语句的干扰。因此其他寻找偶然性正确的方法也可是使用本方法进行改进。
4.3 算法复杂度分析
从步骤上来说,在运行完成测试用例之后,需要先使用3.1节中的算法对测试用例集进行一个处理,然后再按照公式来进行计算。
从时间上来说,假设fail测试用例有m个,pass测试用例有n个,那么本文中算法复杂度为O(m×n)。对于经典的CFL算法中,不论运行测试用例的时间还是经典算法本身的复杂度都要远高于这个值,因此这点时间基本可以忽略。另外对于公式的修正也没有增加公式本身的复杂度。
从空间上来说,只需要储存少量的数据,也可以忽略。
因此只要搭建好自动化实验框架之后,提出的方法与经典的CFL方法的复杂度一致,并没有提升其复杂度。
5 相关工作
首先与Tanrantula和ochiai方法比较,从以上的结果可以看出来,本文提出的方法可以有效提高怀疑度。因为Tanrantula和ochiai这两种方法本身是没有考虑偶然性正确因素。
文献[4]是通过分析覆盖矩阵,依据“若所有的错误的测试用例中都覆盖了第i行,并且运行正确的测试用例中只有小于等于θ的测试用例覆盖了第i行”,则把这样的行作为CC因子,再通过寻找包含CC因子的测试用例来断定其是否为偶然性正确。与此文章相比,本文寻找偶然性正确的方法误判率为0,而他的文章中误判率在查全率比较高的时候一般有40%的误判率,甚至有些时候会高达100%,因此这点是本文提出的方法的一个很大的优点。但是本文的方法只针对于某种特定类型的偶然性正确,因此查全率不够高,这点比其他方法的最好情况要差一些。从定位效果上看,本文在单错误情况下可以有效提高错误语句的怀疑度,尤其是在经过方法2的处理之后,可以更好地提升错误定位效果。在这点上,CC文章中对于定位效果的实际提升并不好,仅有约不到一半的version定位效果有提升,有少量与tarantula效果相同,还有约一半的情况下比原有方法效果还差。经过试验分析发现,CC误判情况的出现会很容易影响错误定位的效果。
文献[3]是通过概括分析了一系列软件行为,用EFSM生成了一些可以判断偶然性正确的模式,并且使用模型匹配的方法来寻找偶然性正确测试用例。与此文章相比,本文的方法通用性比较高,因为此文章中只提供了某几种模式,若程序中不能完全匹配这些模式,则无法判断偶然性正确。其方法的复杂度要高出本方法很多,并且他的方法不能很好地与现有的CFL方法相结合。
与文献[15]相比较,本文的方法与他的方法同样是通过对test的轨迹进行分析,并且用修正的公式来计算怀疑度。但是本文方法与他的方法的根本区别是,他假定相同的轨迹,若结果为PASS的情况比较多,那么这种轨迹不包含错误语句的可能性更大,因此在计算的时候给它更高的正确权重,从而减少正确语句的怀疑度。本文则是通过程序轨迹来分析出一种很好的寻找偶然性正确的方法,对公式进行修正,从而提高错误语句的怀疑度。由于本文方法的目的是提升错误语句怀疑度,而他的目标是降低相关错误语句怀疑度,并且都是基于轨迹的分析,因此有着很好的互补作用。但是很可惜,他提出的方法对于Lower Threshold和Upper Threshold这两个值的依赖比较高,尽管在最优的情况下可以对ochiai方法进行改进,但是对于某一对特定的L和U值并不能很好地提升定位效果。由于其不稳定,所以本文在尝试结合后发现某些情况会影响本方法的定位效果。若有更好的减少正确语句怀疑度的方法与本文方法结合起来应该会有更好的效果。
6 结束语
本文最大的贡献为提出了一种没有误判率的寻找偶然性正确测试用例的方法并且提出了一种效果不错的改进CFL效果的软件错误定位方法。
但是本文方法也有不完善的地方,例如对于偶然性正确测试用例的查全度并不高,只是某一些类型的偶然性正确测试用例,以及对于如何降低正确语句的怀疑度还需要进一步考虑。
本文提出的寻找偶然性正确测试用例的方法因为没有误判率,所以对于已有的寻找偶然性正确测试用例方法有着很好的意义,如果可以提升其查全率,应该会有更广泛的应用并且可以更好地提升软件错误定位效果。另外本文提出的改进CFL定位效果的方法可以普遍适用于已有的CFL方法,对其定位效果进行提升。
因此,有待进一步研究的方向为:第一,本文方法二中对于MYCC(s)/MYCC的处理比较简单,单错误情况下θ值比较容易选择,但是多错误情况下可能会需要考虑更多的因素来寻找合适的值;同时,还可以结合考虑fail/Tfail的比例入手,来判断是否使用修正后的语句怀疑度;第二,可以考虑提出新的合理的假设,并且分析程序谱,找出偶然性正确测试用例所表现出的其他的特点,来更好地提升错误语句的怀疑度;第三,可以重点研究如何减少正确语句怀疑度的方法,例如在文献[15]方法基础上来寻找稳定提升CFL定位效果的方法。
[1]DiGiuseppe N,Jones J A.On the influence of multiple faults on coverage-based fault localization[C]//Proceedings of the 2011 International Symposium on Software Testing and Analysis.ACM,2011:210-220.
[2]Wong W E,Debroy V.A survey of software fault localization[R].Dallas:University of Texas at Dallas:Department of Copmputer Science,2009.
[3]Wang X,Cheung S C,Chan W K,et al.Taming coincidental correctness:Coverage refinement with context patterns to improve fault localization[C]//Proceedings of the 31st International Conference on Software Engineering.IEEE Computer Society,2009:45-55.
[4]Masri W,Assi R A.Cleansing test suites from coincidental correctnessto enhance fault-localization[C]//2010 Third International Conference on Software Testing,Verification and Validation(ICST).IEEE,2010:165-174.
[5]Masri W,Podgurski A.An empirical study of the strength of information flows in programs[C]//Proceedings of the 2006 International Workshop on Dynamic Systems Analysis,ACM,2006:73-80.
[6]Masri W,Abou-Assi R,El-Ghali M,et al.An empirical study of the factors that reduce the effectiveness of coveragebased fault localization[C]//Proceedings of the 2nd International Workshop on Defects in Large Software Systems:Held in conjunction with the ACM SIGSOFT International Symposium on Software Testing and Analysis(ISSTA 2009).ACM,2009:1-5.
[7]Jones J A,Harrold M J,Stasko J.Visualization of test information to assist fault localization[C]//Proceedings of the 24th International Conference on Software Engineering.ACM,2002:467-477.
[8]Abreu R,Zoeteweij P,van Gemund A J C.An evaluation of similarity coefficients for software fault localization[C]//12th Pacific Rim International Symposium on Dependable Computing,2006.PRDC’06.IEEE,2006:39-46.
[9]Wong W E,Debroy V,Xu D.Towards better fault localization:A crosstab-based statistical approach[J].IEEE Transactions on Systems,Man,and Cybernetics,Part C:Applications and Reviews,2012,42(3):378-396.
[10]Liu C,Fei L,Yan X,et al.Statistical debugging:A hypothesis testing-based approach[J].IEEE Transactions on Software Engineering,2006,32(10):831-848.
[11]Jones J A,Harrold M J.Empirical evaluation of the tarantula automatic fault-localization technique[C]//Proceedings ofthe20th IEEE/ACM InternationalConferenceon Automated Software Engineering.ACM,2005:273-282.
[12]Abreu R,Zoeteweij P,Golsteijn R,et al.A practical evaluation of spectrum-based fault localization[J].Journal of Systems and Software,2009,82(11):1780-1792.
[13]Abreu R,Zoeteweij P,Van Gemund A J C.On the accuracy of spectrum-based fault localization[C]//Testing:Academic and Industrial Conference Practice and Research Techniques-mutation.IEEE,2007:89-98.
[14]Hutchins M,Foster H,Goradia T,et al.Experiments of the effectiveness of dataflow-and controlflow-based test adequacy criteria[C]//Proceedings of the 16th International Conference on Software Engineering.[S.l.]:IEEE Computer Society Press,1994:191-200.
[15]Bandyopadhyay A,Ghosh S.Proximity based weighting of test cases to improve spectrum based fault localization[C]//2011 26th IEEE/ACM International Conference on Automated Software Engineering(ASE).IEEE,2011:420-423.
