三种GPU并行的自适应邻域模拟退火算法
2015-01-15钟一文
林 敏,钟一文
福建农林大学 计算机与信息学院,福州 350002
1 引言
模拟退火算法是一种启发式的全局最优化算法,但其有两个缺陷:(1)容易陷入局部最优解;(2)需要花费较多的时间以求得一个较优的解[1]。为克服这些缺陷,学者们提出了各种方法以加速退火算法的收敛速率。这些算法主要有:依赖温度的快速退火方案,如Guassion分布退火算法,Cauthy分布的退火算法[2],ASA[3];与其他智能算法相结合的退火方案,如遗传算法[4],粒子群算法[5],神经网络[6];并行的退火算法,如 PSA[7-9]。
这些算法在不同方面提高了退火算法的效率,但在实际应用中仍需较大的计算量。近年来,随着GPU技术的发展,GPU并行计算的研究掀起了一个热点。文中提出了新的基于GPU并行的自适应邻域的模拟退火算法,并借助了nonu-SA[10]算法的状态生成函数,结合GPU并行的特点,提出了三种GPU并行的算法。算法通过产生大量的并行线程加快搜索进程,并使邻域的选择可以从多个位置出发,即每个位置被限制在局部范围搜索下一个解,而多个位置的组合使其在寻找下一个解时可以有选择地“长跳”,不易陷入局部最优解。
2 自适应邻域的模拟退火算法
邻域的分布一直是模拟退火算法的一个研究重点,Gaussian分布较适于局部搜索,而产生大扰动的概率几乎为零,难以脱离平坦区和多峰区[11],所以Gaussian分布极易陷入局部最优解。Cauchy分布在原点处的峰值比Gaussian分布小,而两端长扁平形状趋于零的速度比Gaussian分布慢,因此更容易产生大步长扰动,使得SA更容易跳出局部极小,但其产生小幅度扰动的能力相对减弱,从而局部趋化性搜索的能力下降。Cauchy分布的特点使其维持在半局部的范围内进行搜索,并时不时来一个“长跳”,“长跳”使其不易陷入局部极小值,但当最小值与局部极小值的距离很近的时候,“长跳”会使其容易远离极小值。
文献[10]提出了nonu-SA算法(自适应邻域的退火算法),其性能优于Guassion的邻域半径随着迭代次数的增加,而呈现递减状态,当温度很高的时候邻域半径可覆盖整个解空间,随着迭代次数的增加搜索范围将随之收窄到很小的范围。假设当前解X={x1,x2,…,xk,…,xm},元素xk随机扰动得到xk'和新解X′={x1,x2,…,xk',…,xm},nonu-SA采用如下扰动公式:

由递减函数的性质可知邻域半径随迭代次数n的增加,而逐渐缩窄,不像Guassion分布和Cauthy分布邻域依赖于温度。
nonu-SA算法收敛速度与迭代次数n有关,在数据量大的时候需要较多的迭代次数,这样降低了其收敛速度,且随着迭代次数的增加,邻域半径收敛到很小的范围,这时如果全局最小值与局部最小值相隔较远的距离,那么算法极易陷入局部最小值。
3 基于GPU并行的自适应邻域退火算法
并行算法主要有几种实现方式,一是基于多核CPU并行的,二是基于集群架构的,三是基于GPU并行[12]的。基于CPU并行的方式由于CPU核心数量的限制,并行的规模非常有限;而基于集群的方式其成本较高,且数据的传输较慢;GPU具有大量的核心,可以同时运行几千几万个线程,GPU拥有最高的浮点计算能力,甚至超越了最先进的高性能计算(HPC)中心的设备。许多前沿研究才能申请试用这种每秒万亿次浮点计算的超级计算机,如今由带有若干GPGPU与快速冗余独立磁盘阵列的工作站即可实现。本文提出的GPU并行的退火算法是根据GPU及CUDA框架的特点进行设计的,并利用了nonu-SA生成邻域的方法,使算法的精度和收敛性大大提高。
3.1 GPU与CUDA
CUDA是一种基于新的并行编程模型和指令集架构的通用计算架构,CUDA能够利用Nvidia GPU的并行计算引擎比CPU更高效地解决许多复杂计算任务,它包含一个让开发者能够使用C作为高级编程语言的软件环境。
运行在GPU上的CUDA并行计算函数称为kernel(内核函数),内核函数并不是一个完整的程序,而是整个CUDA程序中的一个可以被并行执行的步骤。每一个内核会被N个CUDA线程执行N次。每个kernel函数以线程网格(Grid)的形式组成,每个Grid有许多同样大小的线程块Block组成,每个线程块又由若干个线程(Thread)组成,如图1所示。例如BLOCK为16,thread为256,则总的线程数为16×256,在进行CUDA程序设计时,需要考虑合理的BLOCK数和块内线程数Thread。
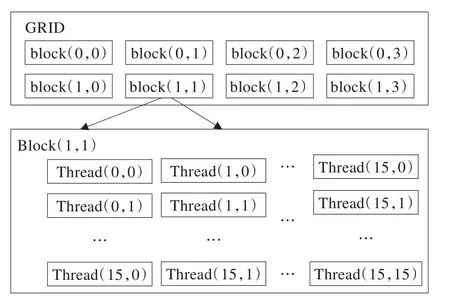
图1 CUDA的kernel结构
3.2 解空间的存储结构
GPU及CUDA框架的特点,决定了GPU并行程序计算中需要在GPU端产生大量的解,选择合适的存储结构将大大减少GPU端访问存储器的开销。假设要求解的函数的其中一个解表示为Xi=(x1,x2,…,xm),而并行计算中有n个线程则有X1,X2,X3,…,Xi,…,Xn个解,如图2所示,每一列表示一个解,之所以选择这种结构将在4.1节中解释。图2中所示的结构可以用二维数组或一维数组存储,本文中使用一维数组存储。同时定义变量X_Valuei表示每个解Xi的函数值,即X_Valuei=f(Xi),用一维数组X_Value[n]存储所有f(Xi)的值。为了区分GPU端存储空间,下文中将用GPU_Xi表示存储在GPU端的解向量,GPU_X_Valuei表示对应的函数值。
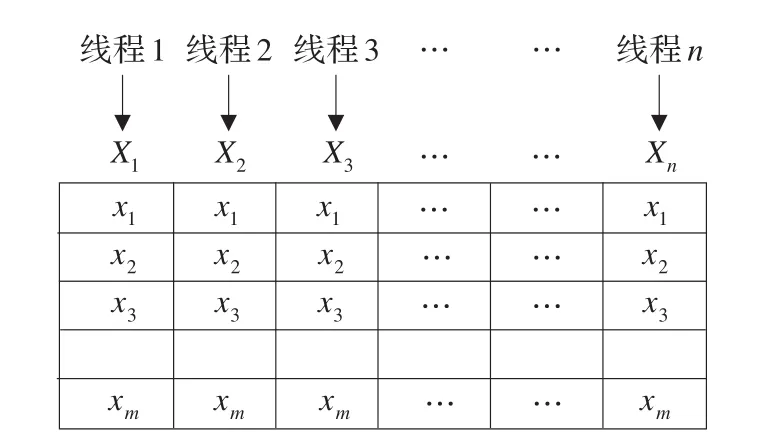
图2 解空间的存储结构
运算中需要产生大量的随机数,传统的做法是在主机端先生成大量的随机数,并将其复制到GPU的全局内存中,这种做法虽然简单,但需要占用大量的GPU存储空间。本文的作法是在GPU端动态的并行生成随机数,既可以节省大量的存储空间,又可以提高执行效率。
3.3 基于多条马尔可夫链的GPU并行算法
GPU的每个线程独立运行一条马尔可夫链[13],直到满足停止条件。这时在GPU端并行计算出每个BLOCK内的最优解,然后再从这些最优解并行计算出最优解,最后将最优解传送给CPU端。以下是本算法的伪代码表示:

GPU端产生了BLOCK_NUM*THREAD_NUM个线程,每个线程都执行相同的Markov_SA()过程,每个Markov_SA()过程相当于负责一条独立的马尔可夫链,Markov_SA()过程的伪代码如下:

m个线程将产生m个解决方案,最终要从这m个解决方案中找出最优解,一般的做法是由CPU端完成这个过程,但当数据量较大的时候,将花费比较多的时间。所以本算法采用归约法在GPU端完成最优值的比较查找。SeleBest过程以块作为单位,块内每个线程负责两个数的比较,每个块的最优解保存到块的第一个元素,然后将结果传输给CPU端,由CPU端在剩余的最优解中找出最优解。

3.4 基于GPU并行的遗传-模拟退火算法
遗传算法[14]是一种基于自然选择和群体遗传机理的寻优算法,它具有三个基本算子:选择、交叉和变异。遗传算法具有天生的并行性,但它极易陷入“早熟”,本算法利用遗传算法的交叉算子与退火算法相结合,既可避免其过早进入“早熟”,又可加快退火算法的搜索进程。
算法的主过程描述如下:


算法Cross采用遗传算法的交叉算子,按一定的交叉概率从所有解中选出部分解,对这些解随机地进行两两交叉。经过交叉会产生两个新解,加上原来的两个解总共有四个解,在这四个解中选择最好的一个解,并将其复制给另外一个解做为新解以进行下一步的计算。其算法描述如下。交叉运算的过程表示如下:

3.5 基于BLOCK分块的并行算法
GPU中的线程以BLOCK进行划分,块内线程可通过共享存储器和同步执行协作。每个BLOCK内的所有线程计算出下一个解后,通过归约法选出该BLOCK中的最优解,将其作为此BLOCK内所有线程的下一个解。其主过程与4.2节中类似,每个线程的执行过程表示如下:

算法中__shared__表示存储类型是共享内存,共享内存是接近核心的内存,所以访问速度很快。算法中在计算块内最优解时,需要比较最优解,并将最优解所处的线程号记录下来,以便计算最优解在全局内存中的对应位置。所以定义了mysharenode这个结构体类型,mysharenode包含min和tx两个数据成员,min表示最优解,tx表示块内线程号。
4CUDA程序的优化
GPU并行计算,要在多种存储器之间进行数据传输,不同存储器的使用方法和传输速率有很大差异,在理想的情况下,GPU端运行足够多的线程,在所有存储器传输进行的时候,GPU的各个核心始终在计算着,这样能很好地隐藏各种访存延迟。
GPU中的存储结构主要有全局内存、共享内存、常量存储器、寄存器、纹理存储器[15],不同的存储器有各自的优势,需要采用不同的访问方式和存储结构。本文中主要用到了全局存储器,共享内存,对于使用全局存储器要尽量满足合并内存访问的要求,对于共享存储器要尽量避免bank conflict。
4.1 全局内存的合并访问
访问一次全局存储器需要几百个时钟周期,对全局内存的访问是否满足合并访问条件时对CUDA程序性能影响最明显的因素之一。如果warp内的32线程所有访问地址都位于一个128 Byte的段内,则只会进行一次合并访问,否则要分成多次访问,如图3所示。
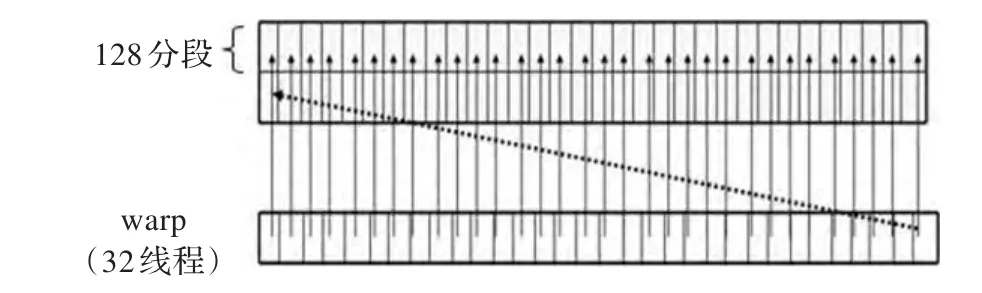
图3 全局内存的合并访问
本文设计的存储结构一列为一个解向量,当计算函数值时,GPU可以通过二次合并访问即可读出所需的数据,并可通过大量的线程隐藏延时,如果数据是float型,则仅需一次合并访问,但double型数据量更大,所以其吞吐量是相同的。
4.2 处理bank conflict
共享存储器位于GPU内,速度比全局内存快很多,在不发生bank conflict的情况下,共享内存的延迟几乎只有局部存储器和共享存储器的1/100。
在计算最优解时,分别先计算每个block内的最优解,然后将数据从全局内存加载到共享内存,计算完最优解再将数据传输给全局内存。这里共享内存中的数据可能会产生bank conflict,为了避免这个问题,算法中专门设计了相应的存储结构。
5 实验与分析
算法中选用了11个基准函数,如表5所示,在GTX650TI BOOST,Intel G630平台上进行了实验,b为5,马尔可夫链长k为3,BLOCK数为16,Thread数为256,其中迭代次数N为2 000,每一次迭代表示运行的时间为单位1,则2 000次迭代运行的时间为2 000。对每个函数分别运行30次,其结果如表1至4所示。
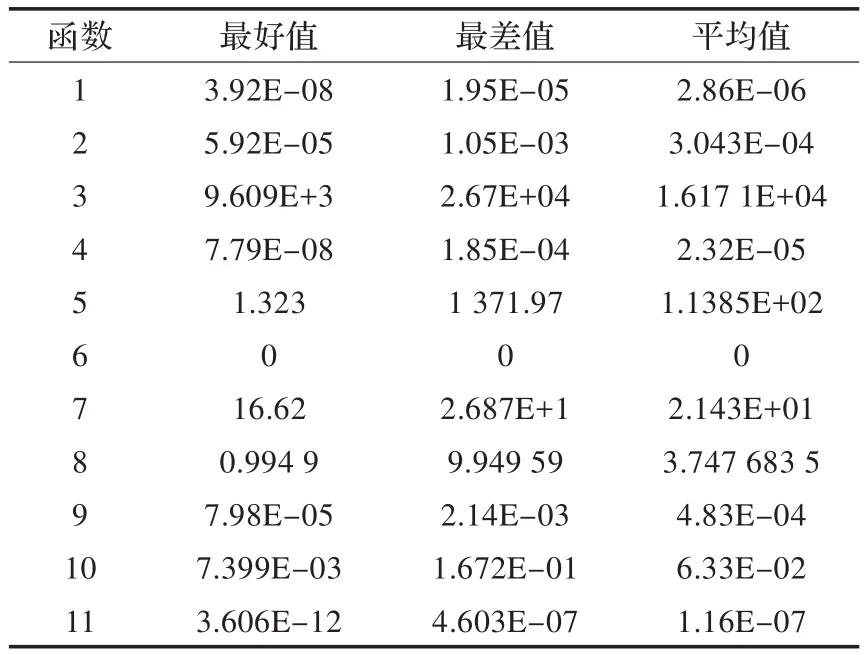
表1 nonu-SA算法
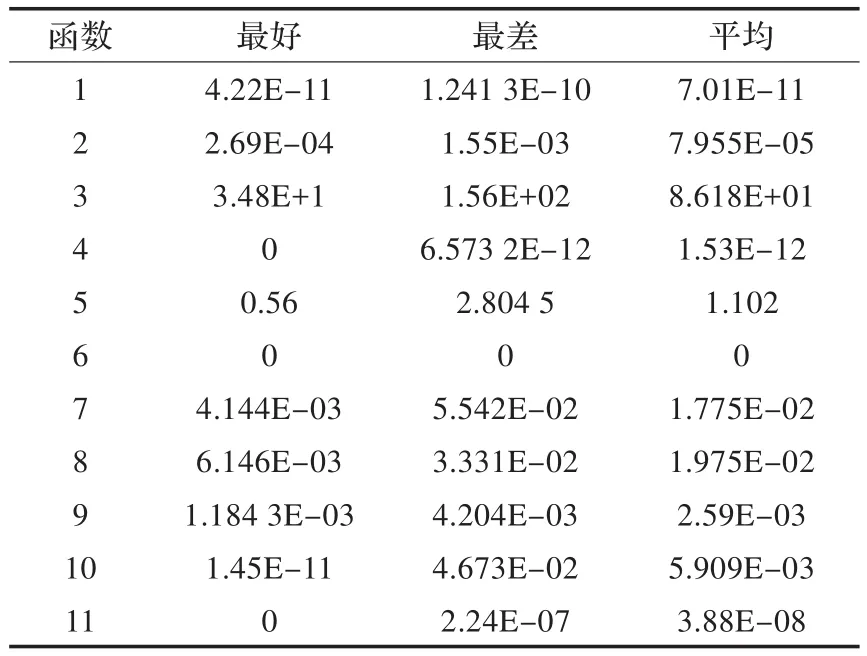
表2 基于GPU并行的遗传-模拟退火算法
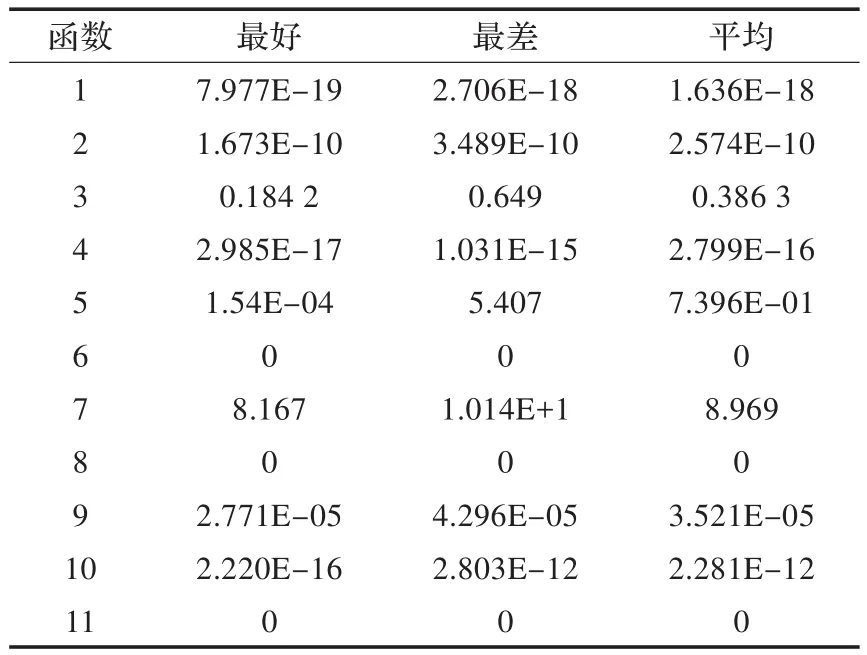
表3 基于BLOCK的GPU并行算法
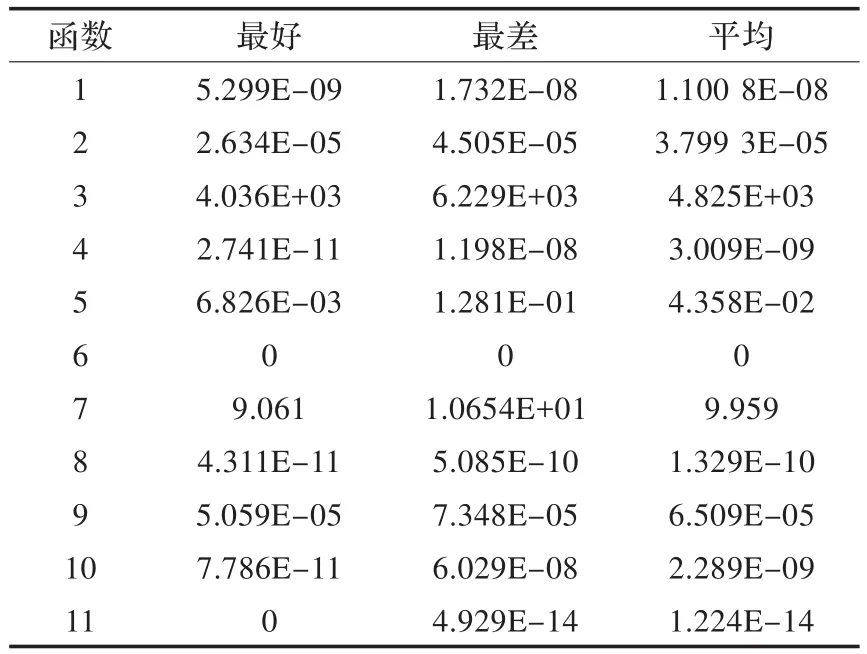
表4 基于多条马尔可夫链的GPU并行算法
从实验可以看到基于BLOCK的GPU并行算法收敛速度最快,基于GPU并行的遗传-模拟退火算法在某些方面优于基于BLOCK的GPU并行算法,如函数4和函数7。这是由于遗传算法的特性,使其更适合于这两个函数,并且当调高交叉率PC将进一步提高该算法的性能。基于GPU的多路并行算法,其算法性能整体上不如其他两种并行算法,但其设计非常简单占用空间小,大部分情况表现比nonu-SA出色,且随着线程数的增加更加明显。对于函数9结果比较特殊,几种算法的结果都比较接近,甚至nonu-SA结果更好。

表5 基准函数
为了进一步检验算法的收敛速度,分别在迭代次数为100,500,1 000,2 000,4 000的情况下进行了实验,结果如表6至9所示。从实验数据看并行算法表现出了较好的稳定性,并且随着迭代次数的增加,多数函数的收敛速度大大优于nonu-SA算法。
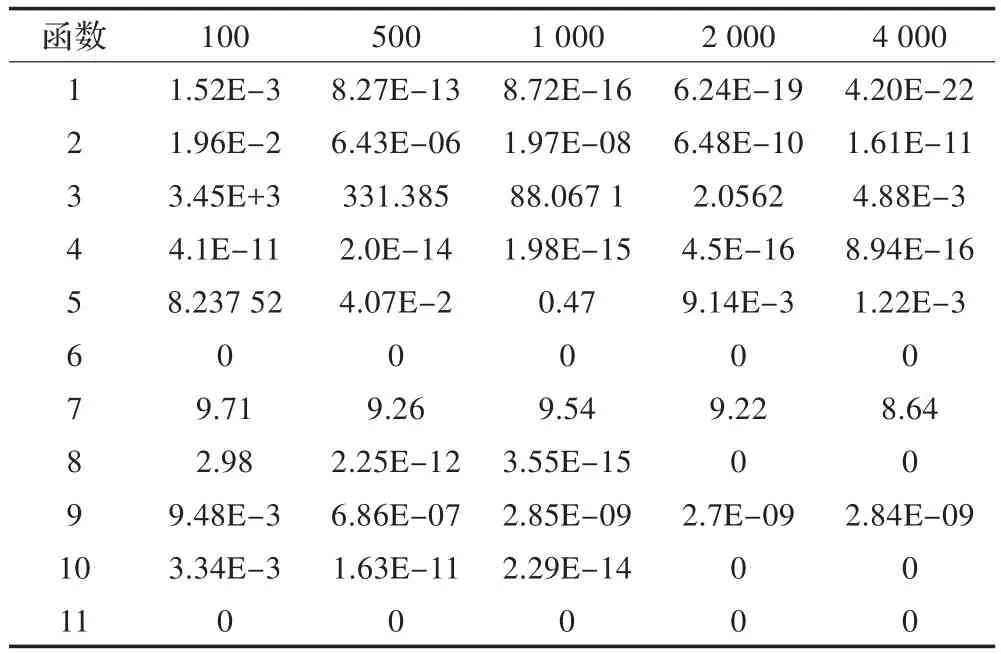
表6 基于BLOCK的GPU并行模拟退火算法
为了在运行时间上做进一步的论证,将三种并行算法在所取得结果与nonu-SA相近或者更优的情况下所耗费的机器时间进行了比较,得到表10的结果。从结果也可以更加证实三种并行算法的收敛速度优于nonu-SA算法,其中3.3节中算法与nonu-SA算法相对比较接近,但还是优于nonu-SA算法几倍,其他两种并行算法大大优于nonu-SA算法。
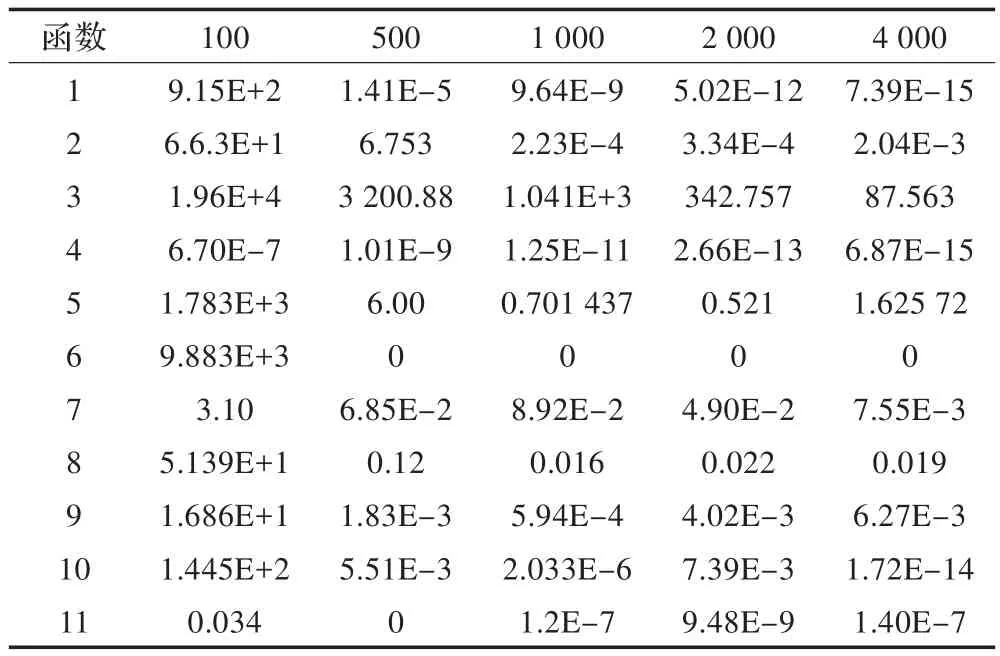
表7 GPU并行的遗传模拟退火算法
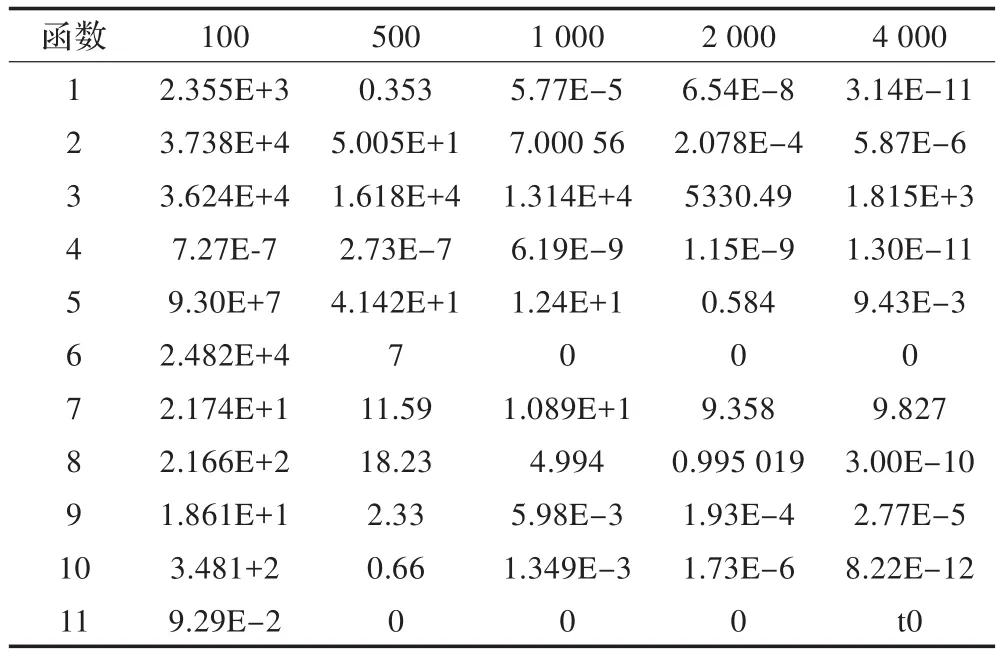
表8 多条马尔可夫链GPU并行的退火算法
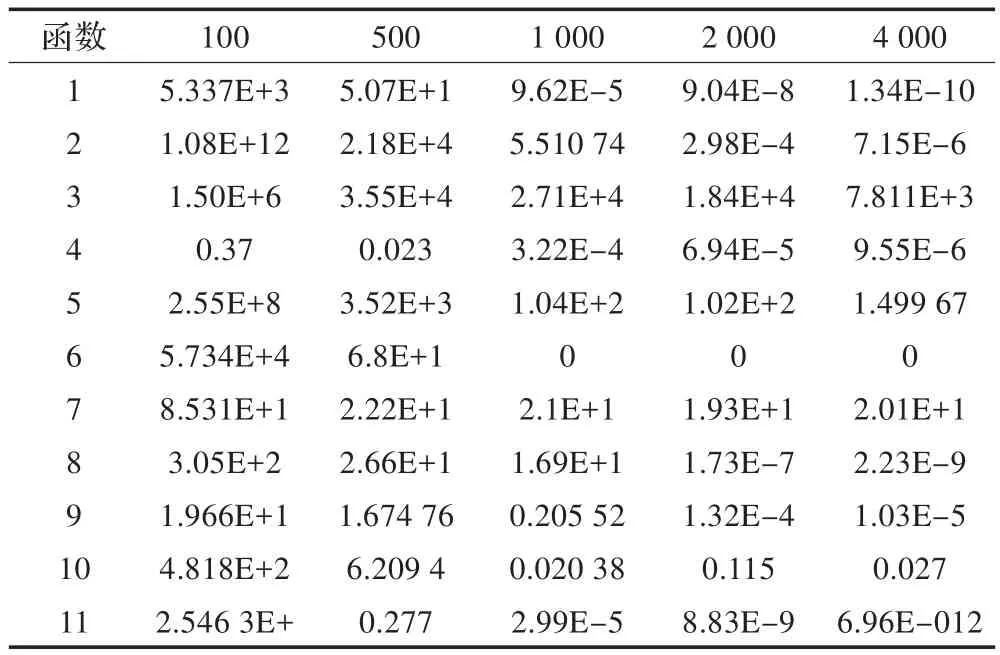
表9 nonu-SA
6 结束语
根据GPU并行的特点和优势,提出了三种GPU并行的自适应邻域的模拟退火算法,并通过11个基准函数对这三种并行算法加以比较。这三种算法各有优势,基于GPU多路并行算法实现简单,所需存储空间最小,并且对个别函数效果比较好;基于GPU并行的遗传-模拟退火算法结合了遗传算法的特点,而基于BLOCK分块的GPU并行模拟退火算法,利用了CUDA中的BLOCK概念使线程以BLOCK为单位进行共享,对大部分函数来说此算法收敛速度最快。这三种算法具有较好的通用性,不仅仅可以应用于本文中的邻域结构,还可以将其移植到采用其他邻域生成函数的模拟退火算法中。
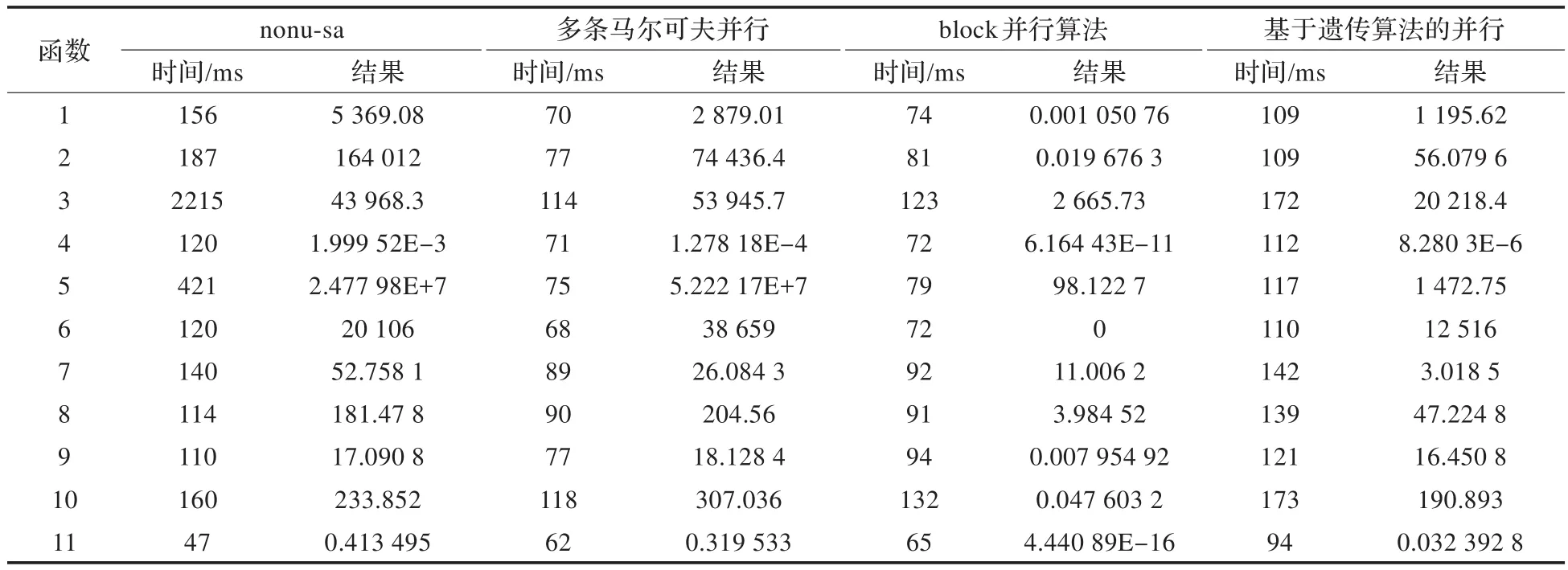
表10 算法的运行时间比较
[1]张霖斌,姚振兴,纪晨,等.快速模拟退火算法及应用[J].石油地球物理勘探,1997,32(5):654-660.
[2]Szu H,Hartley R.Fast simulated annealing[J].Physics letters A,1987,122(3):157-162.
[3]Ingber L,Petraglia A,Petraglia M R,et al.Adaptive simulated annealing[M]//Stochastic Global Optimization and its Applications with Fuzzy Adaptive Simulated Annealing.Berlin Heidelberg:Springer,2012:33-62.
[4]Cordón O,Moya F,Zarco C.A new evolutionary algorithm combining simulated annealing and genetic programming for relevance feedback in fuzzy information retrieval systems[J].Soft Computing,2002,6(5):308-319.
[5]Soleymani S.Bidding strategy of generation companies using PSO combined with SA method in the pay as bid markets[J].InternationalJournalofElectricalPower&Energy Systems,2011,33(7):1272-1278.
[6]Salcedo-Sanz S,Yao X.A hybrid Hopfield network-genetic algorithm approach for the terminal assignment problem[J].IEEE Transactions on Systems,Man,and Cybernetics,Part B:Cybernetics,2004,34(6):2343-2353.
[7]Boissin N,Lutton J L.A parallel simulated annealing algorithm[J].Parallel Computing,1993,19(8):859-872.
[8]Ram D J,Sreenivas T H,Subramaniam K G.Parallel simulated annealing algorithms[J].Journal of Parallel and Distributed Computing,1996,37(2):207-212.
[9]Aarts E H L,Korst J H M.Boltzmann machines as a model for parallel annealing[J].Algorithmica,1991,6(1-6):437-465.
[10]Xinchao Z.Simulated annealing algorithm with adaptive neighborhood[J].Applied Soft Computing,2011,11(2):1827-1836.
[11]王凌,郑大钟.基于Cauchy和Gaussian分布状态发生器的模拟退火算法[J].清华大学学报:自然科学版,2000,40(9):109-112.
[12]张庆科,杨波.基于GPU的现代并行优化算法[J].计算机科学,2012,39(4):305-310.
[13]Hastings W K.Monte Carlo sampling methods using Markov chains and their applications[J].Biometrika,1970,57(1):97-109.
[14]Mahfoud S W,Goldberg D E.Parallel recombinative simulated annealing:a genetic algorithm[J].Parallel Computing,1995,21(1):1-28.
[15]Farber R.高性能CUDA应用设计与开发:方法与最佳实践[M].于玉龙,译.北京:机械工业出版社,2013:94-114.
