基于信息熵的流线质量评估和布局算法
2015-01-15解利军桂立业
张 沙,解利军,桂立业,郑 耀
浙江大学 航空航天学院,杭州 310027
1 引言
矢量场可视化是科学可视化的一个经典分支,在气象分析、航空航天等众多领域具有无可替代的作用。矢量场可视化的目的是将矢量场仿真数据以一种视觉可见的方式正确表达出来,同时这样表达出来的信息必须便于人们理解和分析矢量场的特征。流线可视化,能够直观地反映矢量场的特征,同时计算相对简便快捷,一直是矢量场可视化分析中最重要的方法之一。
流线是从某个种子点出发,沿着该点流向的正向和反向,通过矢量场积分计算得到的曲线。种子点的选取对流线的质量具有非常关键的作用。流线种子点选取不当可能会引起视觉混乱、特征不明显等一系列问题。
近年来,矢量场种子点布局算法呈现百家争鸣的局面。2D流场中,Jobard等提出等距离种子点放置方法[1],并经过多次改进[2-4]。等距离种子点放置方法的目的是在矢量场中等距离地放置流线以避免视觉聚类。但这种方法不对矢量场结构进行分析,可能会造成矢量场中重要特征不明显的问题。最远种子点放置算法[5]在距现有流线最远的地方放置种子点,保证矢量场中不会出现大块空白的区域。这个算法的缺点与等距离种子点的缺点类似,不对矢量场结构进行分析可能错过某些重要特征。基于特征的可视化方法主要关注矢量场中的主要特征提取,Helman等人[6]对2D 矢量场的拓扑进行分析,对临界点进行检测和分类,并以此作为基础执行可视化算法。Verma等人提出了基于拓扑的种子点放置方法[7],这个算法首先分析矢量场得到关键点,然后利用预先定义的模板在关键点周围进行布点,这样可以保证重要特征的突出显示。本文后面初始布点时用到的模板就与Verma等人的模板相同。3D流场中,Ye等人在[8]中将Verma等的方法扩展到三维流场中,并定义了三维流场的模板。Li和Shen提出了基于图像的三维矢量场种子点布置方法[9],有效地避免了流线杂乱和视觉的混乱。Xu等人提出了矢量场信息化的信息框架,以独特的视角诠释了流线生成的信息意义。国内的王少荣等人[10]提出了一种基于出入度的种子点布局算法。
在已经有了如此多的种子点选择算法后,对种子点的质量评估算法却寥寥无几。本文提出了一种基于信息论的矢量场种子点评估和布局算法,并利用CUDA(Compute Unified Device Architecture,计算统一设备架构)对其做了不错的性能加速[11]。
本文的核心思想是:矢量场中矢量变化越大的区域,其局部熵值越大,拥有重要特征的可能性越大(详见2.1节)。初始布点,选择拥有极大局部熵值的网格点,对其周围进行模板布点,突出显示矢量场的重要特征。然后利用现有流线扩散出一个中间矢量场,求解中间矢量场与初始矢量场的条件熵,来衡量初始矢量场中除中间矢量场中的共有信息外的未知信息的熵值,确定现有流线是否已经能够展示出初始矢量场中的足够信息,从而确定是否要继续在矢量场中加入新的种子点。新的种子点的放置采取基于重要性取样的方法。本文提出的算法最终目的是以较少的流线展示出矢量场中大部分信息。
2 基于信息熵的流线评估和布局算法
2.1 程序流程
图1给出了本文算法的程序流程图。算法包括三个比较大的模块,分别为基于信息熵的初始种子点布置、流线质量评估以及基于重要性种子点取样。基于信息熵的初始种子点布置模块对矢量场特征进行分析,找到其主要特征并生成流线。流线质量评估模块对现有流线进行质量评估,以确定现有流线是否已经展示出矢量场中足够的信息,是否需要继续添加流线。基于重要性种子点取样的目的是根据条件熵向矢量场中添加新的种子点。
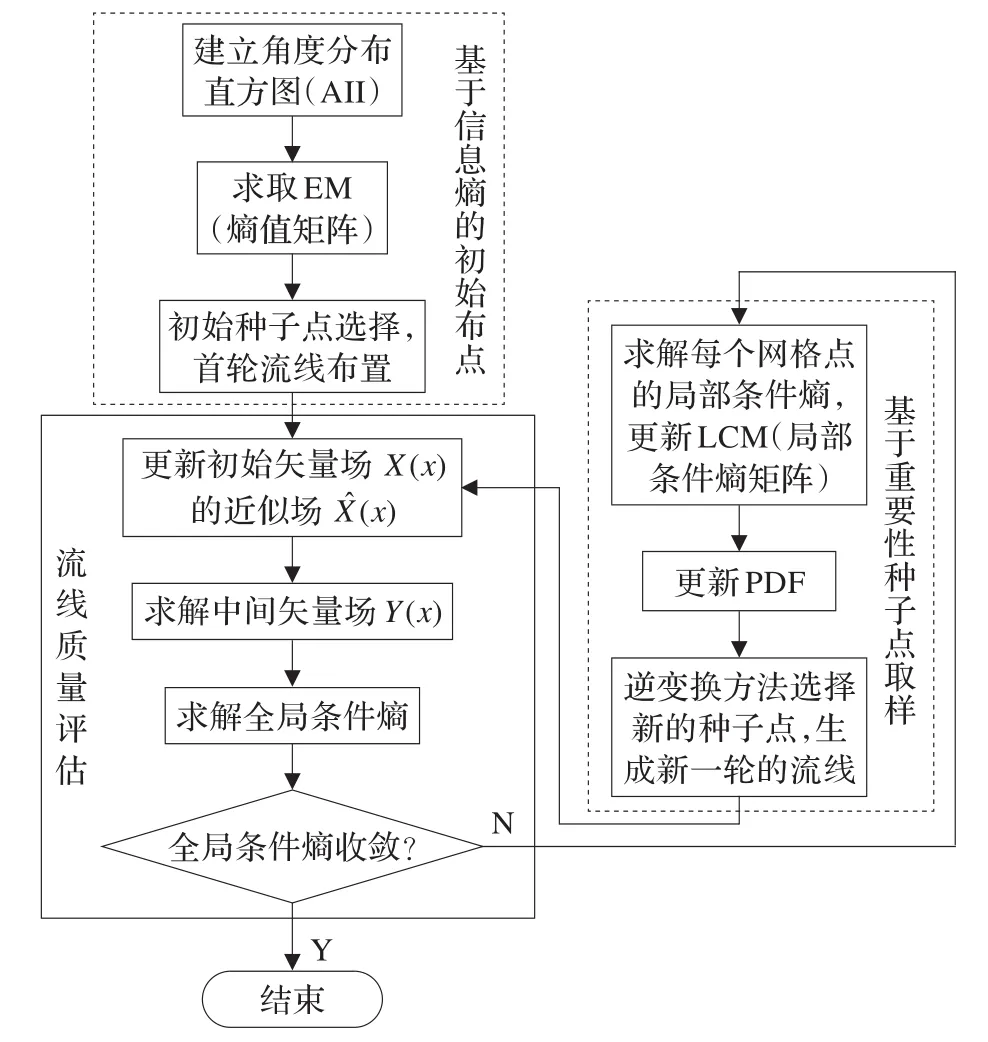
图1 基于信息熵种子点评估和布局算法流程图
后续的章节中,将对各模块的具体算法实现进行介绍。
2.2 基于信息熵的初始布点

在本文中,将矢量及其所有邻近网格点(本文网格点的邻近点规模:2D数据为132个,3D数据为133个)作为一个随机系统并求解该系统的熵值。矢量变化越大即矢量越混乱的系统,其熵值越大,含有重要特征的可能越大。利用这个方法选取的种子点,可以很好地抓住矢量场的主要特征。
2.2.1 概率分布函数求解
要求解网格点的局部熵值,首先要统计网格点及其所有邻近点的方向区间直方图,得到该矢量场的概率分布函数p(xi)。
对所有矢量,先按方向进行量化,将其分为若干个方向区间。
对于2D矢量,先将矢量表示为角度θ∈[0,360),角度空间被划分为60个区间,每个区间6°。对于矢量为(a,b)的网格点,如果a,b均不为0,则该矢量角度区间求法如式(2):
1948年,信息论之父C.E.Shannon在论文[12]中提出了信息熵的概念,用来解决信息的量化度量问题。信息熵描述了随机系统的不确定程度,越有序的系统,其熵值越小,不确定的信息也越少;反之越混乱的系统,熵值越大,不确定的信息越多。
对于一个离散变量X,有n个可能的值(x1,x2,…,xn)每个值出现的概率为(p1,p2,…,pn),则X的离散熵为:
对于3D矢量,为了简化计算,本文将z轴单独划分为6个区间,x轴和y轴的划分与2D矢量相同。z轴区间值的计算方法为z×3/r+3其中,3D矢量的角度区间为z轴的区间值乘以xOy平面的区间值。3D数据的角度区间共有360个。
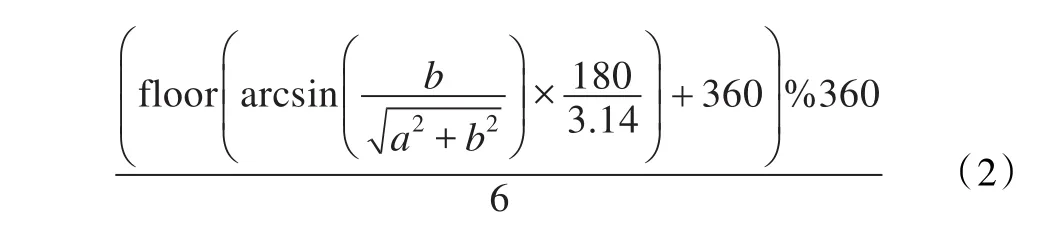
统计网格点及其所有邻近点矢量的方向区间。假如落在某区间Ci内的矢量个数为ni,邻近点的总个数为N,则该角度区间出现的概率为pi=ni/N。
2.2.2 基于模板的种子点布置
按照2.1节所示,求取每一个网格点的熵值,所有点的熵值构成EM(熵值矩阵),选取所有局部熵值大于0.7倍熵最大值的极值点,作为初始布点的模板中心。本文采用的模板是由Verma等人在文[7]中首先提出来的所有模板的综合体。对于2D数据,采用了菱形模板,共9个点,分别为4个顶点,4条边的中点及1个中心点。对于3D数据采用了八面体模板,共27个点:1个中心点,6个顶点,8个面的中心点,12条边的中点。
图2(a)是Isabel的某个时间片的切片矢量图,图2(b)展示了根据本文的算法对该数据求解熵矩阵,并对熵极值进行模板布点后的流线。

图2 Isabel数据切片的矢量图及其对应的熵图1)
2.3 流线质量评估
这一模块主要包括两个步骤:首先根据现有流线生成中间矢量场,然后根据初始矢量场与中间矢量场的条件熵量化评估流线对矢量场信息的反映程度。
2.3.1 条件熵
条件熵反映的是两个随机变量之间的不确定性。在本文中初始矢量场和中间矢量场的条件熵描述的是:在完全已知中间矢量场Y(x)的情况下,初始矢量场X(x)中除了与Y(x)共享的信息之外的信息的熵值。也就是,Y(x)中剩余信息的不确定性。
条件熵有两种计算方法,如公式(3)和公式(5):

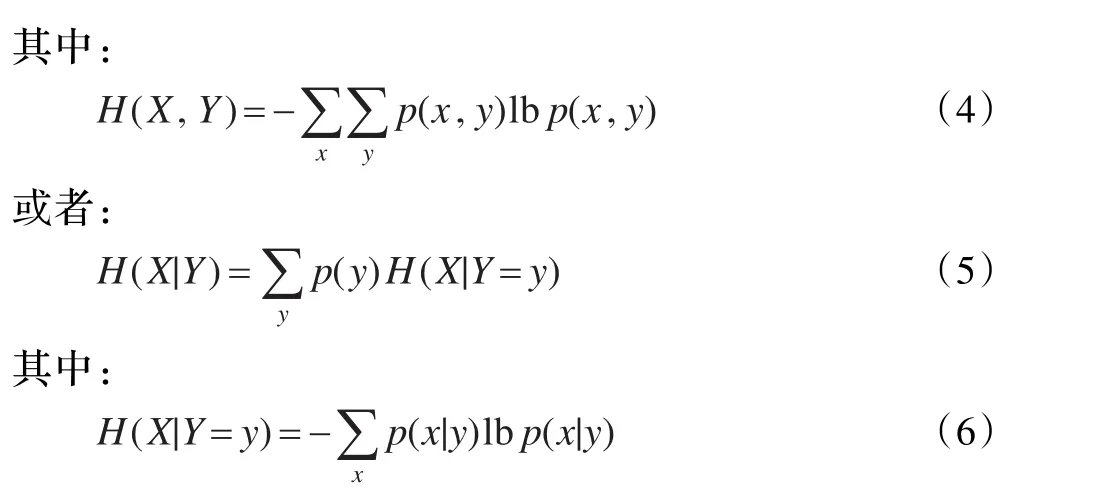
本文中,全局条件熵的计算直接放置CPU中进行,没有空间限制,采用公式(5)只需对所有网格进行一次遍历,能获得较高的时间性能。而在基于重要性布点过程中求解局部条件熵时,算法需要求解每一个网格点及其所有邻居点的条件熵。如果采用串行算法,将面临高昂的时间代价,所以将这一部分移动到GPU中利用CUDA进行加速计算。实验表明,此时采用公式(3)将取得更好的时间性能。
2.3.2 求解中间矢量场
本文通过最小化能量方程(7)的方法来求解中间矢量场Y(x)。这种方法能够保证整个矢量场被恰当覆盖,同时,还能保证中间矢量场经过光滑处理,并且光滑后流线上的点的中间值与真实值之间的差异最小。
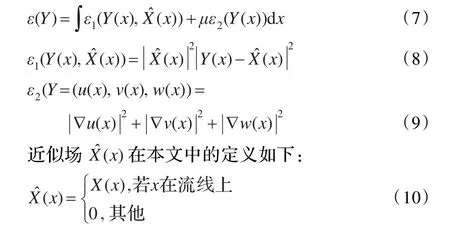
本文应用的能量方程与参考文献[13]中提出的外部力相同。具体的求解过程参见文献[13]。上述能量方程的求解结果为:
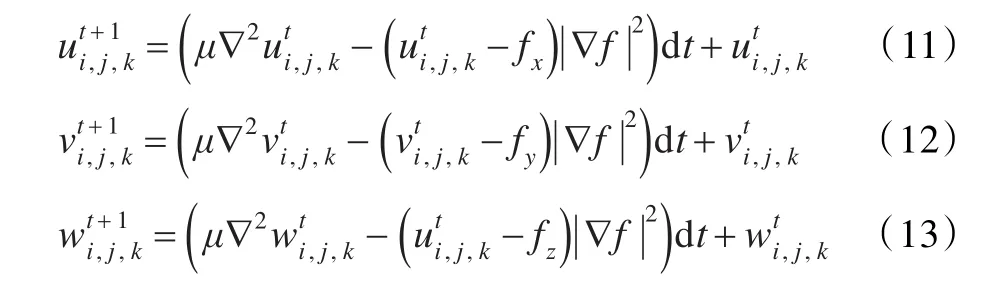
其中μ=0.1(经验值),∇f(x)=ˆ(x),dt自己设定,但须满足CFL约束条件[14]。
图3展示了经过若干次的迭代后求解出的中间矢量(蓝色)与初始矢量(红色)的比较结果。只有蓝色矢量的网格点表示初始矢量与中间矢量相同,在显示时被覆盖了。图3(d)中,中间矢量场中绝大部分的网格点或者因为被流线覆盖或者因为有效的矢量恢复,得到了与原始矢量近似或者相同的结果。
对于大规模的数据,此模块耗费的时间非常长。为了减少此模块的时间,本文将这一模块放到了GPU上进行并行计算。
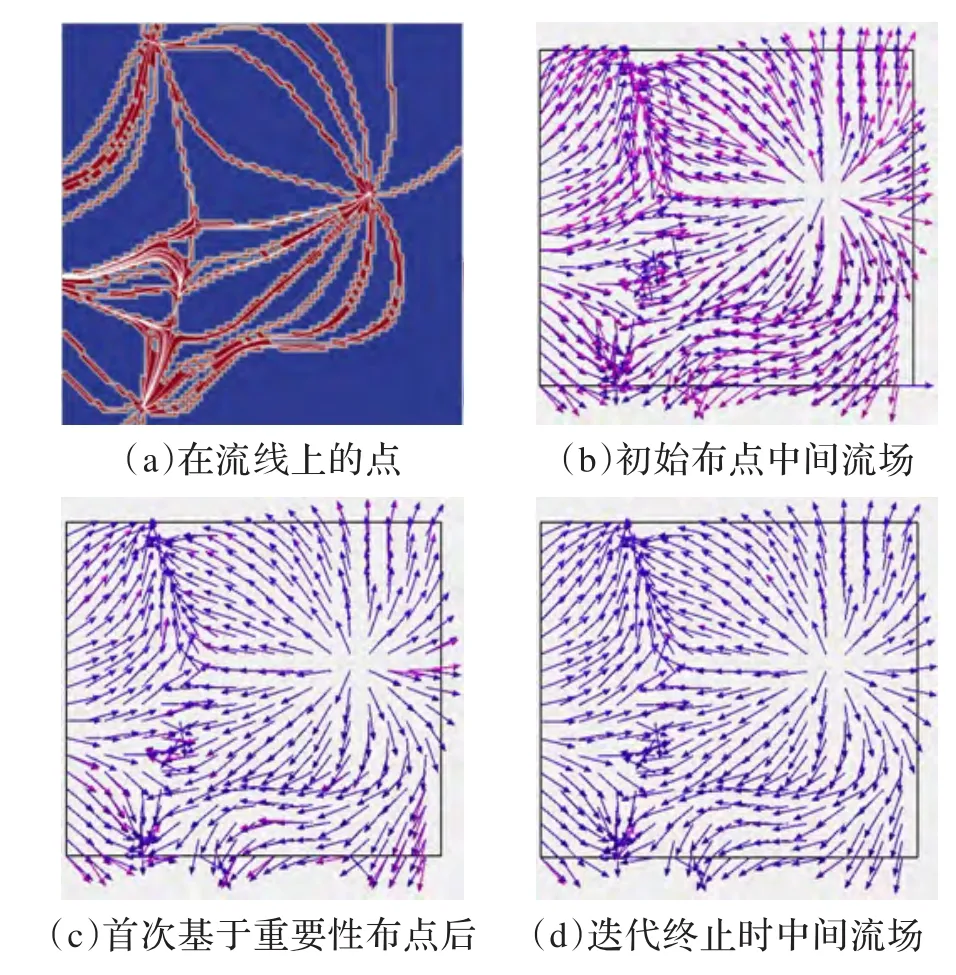
图3 各步骤流线恢复出的中间矢量场
图3中图(a)显示判断网格点是否在流线上,其中红色的网格点表示在流线上,在建立近似矢量场时,这些网格点的矢量值将等于初始值,其他蓝色点均为0。图(b)展示了根据(a)中流线生成的中间矢量场与初始矢量场的比较。图(d)为迭代终止后的中间矢量场。图(b)(c)(d)三幅图反映了中间矢量场逐渐与原始矢量场重合的过程。
2.4 基于重要性取样
初始布点完成以后,矢量场中大部分的重要特征已经显示出来。后续迭代的重要性取样是为了更加强调这种特征显示同时填充矢量场中的空白区域。这个迭代过程的结束条件是矢量场中所有的信息可见,即:矢量场的全局条件熵趋于收敛。
根据求解出的中间矢量场Y(x)和初始矢量场X(x)求解每个网格点的条件熵,更新CEM。对于某个网格点来说,该处的条件熵越大,则成为新一轮种子点的可能性也越大。新一轮的布点过程中,网格点(x,y)被选中的概率为:

其中,h(x,y)为点(x,y)处的条件熵。
所有网格点的布点概率构成了概率分布函数(PDF),然后利用反变换的方法选取新一轮的网格点。
2.5 终止条件
重要性取样迭代进行,在每次循环中,将一定数量的种子点布置到矢量场中,直到初始矢量场与中间矢量场的条件熵值趋于收敛。对于不同的数据,每次循环放置的种子点个数也不相同,通常情况下,每次循环放置的种子点数为网格点数的平方根。
3 结果和讨论
测试算法在64位Windows 7系统,Lenovo ideapad Y470,Intel core i5,3 GB内存机器上运行。机器配备的显卡为Nvidia GeForce GT525。
3.1 飓风Isabel矢量场切片
图4展示了两种不同的算法对Isabel数据集切片的可视化结果。图4(a)是本文算法执行基于信息熵的初始布点的结果。由图中可以看出即使此时流场中只存在较少数量的流线,流场中的特征区域已经被全部显示出来。图 4(a)中III部分存在显著源或汇,结合图 2(a)点图标矢量方向,可知此处存在源,II和V部分存在比较明显鞍面,II、IV和VI部分存在需要用户重视的特征区域。这证明了本文的算法在初始布点后能够很好地捕获流场中主要特征区域。图4(b)算法经过两次迭代后的中间结果。
图4(c)展示算法最终结果图。图中,各个特征区域周围的流线数目更多,特征区域得到加强显示;而非特征区域流线数目相对较少但不影响用户对流场的理解。图4(d)是最远种子点算法生成的流线。图中几个特征区域并不明显且短流线较多,尤其对应于图4(a)I区域位置的特征区域很难识别出来。与最远种子点算法相比,本文提出的算法能够更好的捕获流场中的特征区域,并予以突出显示。
图(e)显示了在算法迭代过程中,中间矢量场与初始矢量场的条件熵逐渐趋于收敛,矢量场中未被显示的信息逐渐减少。
3.2 Rayleigh-Bénard数据集
图6展示的是本文算法应用于Rayleigh-Bénard数据集的实验结果。Rayleigh-Bénard对流现象(RBC)是指当流体的Rayleigh数达到某一特定数值时产生对流的现象[15]。RBC现象是一种在自然界和工业中普遍存在的热流动现象。本文获取矢量场数据的方法是利用CFD模拟计算两无限平行板间的RBC对流。图5是模拟采用的几何模型示意图。模拟网格采用127×34×40的结构网格。
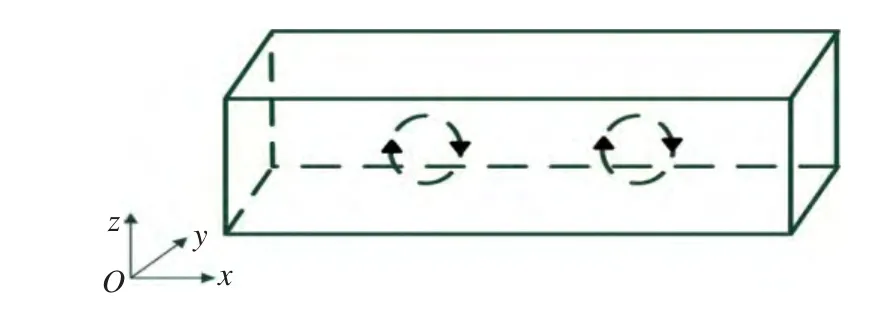
图5 Rayleigh-Bénard对流模拟的模型
图6(a)中红色线条是通过李明等人提出的算法提取的涡核[16]。
图6(b)展示的是对矢量场经过初始布点以后的流线图。图中可以看出,流线大多缠绕涡核,很好地完成了抓取特征区域的任务。
图6(c)是流线最终放置结果。最终的结果图中,在初始布点生成流线的基础上增加了流线,特征区域得到进一步加强显示,非特征区域也适当增加了较少流线,具有全局性。
图6(d)显示随着流线数目增多,初始矢量场与中间矢量场的条件熵逐步减少直至收敛,最终完成整个评估。
3.3 算法性能分析
上面两个算例中,Isabel单次评估和生成流线需要9.26 s,Rayleigh-Bénard数据需要46.88 s,算法的速度当前还达不到交互式可视化的要求。
本文算法主要分为3个模块,分别为基于信息熵的初始布点、流线质量评估以及基于重要性取样。以RB对流数据为例,算法各模块的时间效率如表1。其中,更新LCM时,需要对每个网格点扫描邻域,且计算过程中需建立一个360×360的矩阵,这远远超出了GPU 16K的共享内存存储范围,需要采取以时间换取空间的手段,加大了计算量,耗费了大量的时间。
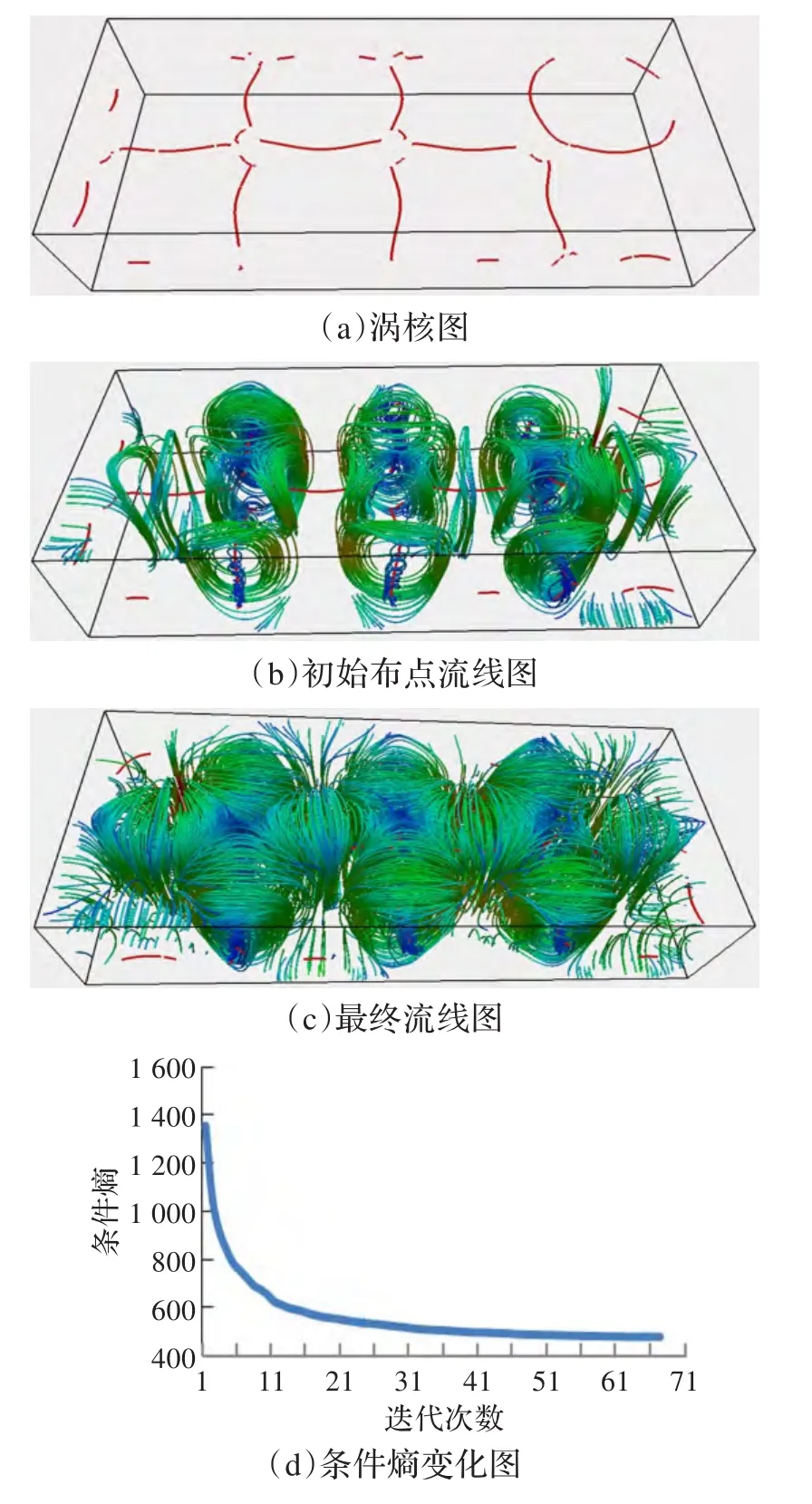
图6 对流数据的可视化结果
4 结论
本文提出了一种种子点布局及流线评估方法。矢量场中熵值越大的区域,其含有特征点的可能性越大。初始布点中,选取了矢量场中若干个极值点进行基于模板的布点,最终生成的流线能很好地抓住矢量场的主要特征。利用初始矢量场与流线生成的中间矢量场的条件熵对现有流线进行质量评估,条件熵值越小说明矢量场中未被现有流线挖掘出的信息越少,流线质量越好,需要添加的新流线也越少。加入新的种子点采用基于重要性取样的方法,保证了矢量场特征区域的显著加强显示。当评估结果收敛时终止迭代过程,此时初始矢量场中大部分的信息已经被现有流线显示出来。
实验结果表明,基于信息熵的初始布点能够有效地捕获流场中的主要特征。当需要流线数量少的时,仅通过初始布点也能得到很好的效果。初始布点结束时,矢量场主要特征虽然被捕获,但矢量场中仍有大量信息被隐藏,此时条件熵值也是比较大的。随着新的流线的不断加入,流场中隐藏的信息逐渐减少,条件熵值也逐步减小直到收敛于一个较小的值。整个评估过程有效地量化评估了现有流线对矢量场的反应程度,即量化评估了流线的质量。

表1 算法各模块的运行时间
目前,本文算法只能支持结构化网格,网格种类比较单一,算法性能仍需进一步提升。未来将研究本算法应用于非结构网格的方法。
[1]Jobard B,Lefer W.Creating evenly-based streamlines of arbitrary density[C]//Proceedings of Eighth Eurographics Workshop on Visualization in Scientific Computing,1997:45-55.
[2]Liu Z,Moorhead R,Groner J.An advanced evenly-spaced streamline placement algorithm[J].IEEE Transactions on Visualization and Compute Graphics,2007,13(3):630-640.
[3]Spencer B,Laramee R S,Chen G,et al.Evenly spaced streamlines forsurfaces:An image-based approach[J].Computer Graphics Forum,2009,28(6):1618-1631.
[4]Wu K,Kao D,Pang A.Strategy for seeding 3D streamlines[C]//Vis’05:Processing of IEEE Visualization 2005,2005:471-478.
[5]Mebarki A,Alliez P,Devillers O.Farthest point seeding forefficientplacementofstreamlines[C]//Vis’05:Proceedings of the IEEE Visualization 2005,2005:479-486.
[6]Helman J L,Hesselink L.Visualizing vector field topology in fluid flows[J].IEEE Computer Graphics and Applications,1991,11(3):36-46.
[7]Verma V,Kao D T,Pang A.A flow-guided streamline seeding strategy[C]//Vis’00:ProceedingsoftheIEEE Visualization 2000,2000:163-170.
[8]Ye X,Kao D T,Pang A.Strategy for seeding 3D streamlines[C]//Vis’05:Proceedings of the IEEE Visualization 2005,2005:471-478.
[9]Li L,Shen H W.Image-based streamline generation and rendering[J].IEEE Transactions on Visualization and Computer Graphics,2007,13(3):630-640.
[10]王少荣,吴迪,汪国平.一种流线放置方法[J].软件学报,2012,23(S(2)):42-52.
[11]Nvida.CUDA programming guide[M/OL].(2013).http://docs.nvidia.com/cuda/pdf/CUDA_C_Programming_Guide.pdf.
[12]Shannon C E.A mathmatical theory of communication[J].Mobile Computing and Communication Reviews,5(1).
[13]Xu C,Prince J L.Snakes,shapes,and gradient vector flow[J].IEEE Transactions on Image Processing,1998,7(3):359-369.
[14]Ames W F.Numerical methods for partial differential equations[M].3rd ed.New York:Academic,1992.
[15]Lohse D,Xia K.Small-scale properties of turbulent Rayleigh-Bénard convection[J].AnnualReview of Fluid Mechanics,2010,42:335-364.
[16]李明.非定常三维流场涡结构分析方法研究[D].杭州:浙江大学,2011.
