基于高光谱图像技术的番茄叶片氮素营养诊断
2014-12-23朱文静毛罕平张晓东
朱文静,毛罕平,周 莹,张晓东
(1.江苏大学现代农业装备与技术省部共建教育部/江苏省重点实验室,江苏镇江212013;2.泰州机电高等职业技术学院,江苏泰州225300)
植物生理学原理认为,叶片是对氮素营养状况反映最敏感的部位之一,氮素的多寡都会导致番茄叶片灰度、纹理等特征发生变化,所以以作物叶片为研究对象判断氮营养状况也成为近年来研究的热点[1-4].目前,基于光谱技术的无损诊断方法,受背景和环境因素影响较大,通常采用点源采样方式,难以体现整个叶片区域的光反射特性差异,且无法充分表征作物营养亏缺时叶片丰富的外在特征信息.基于计算机视觉技术的诊断方法虽能很好地表征叶片的外在特征,但是无法获取反映叶片内部组织生理生化特性的信息.因此,无论光谱检测技术还是计算机视觉技术,在进行作物营养检测时,精度较低,不少研究主要是对某种营养元素缺或不缺的识别,很难实现养分胁迫的准确定量评价[1-2].
高光谱图像不仅包含样本在每个波段下的二维图像信息,还包含样本每个像素点的光谱信息.因此,高光谱图像技术是集图像与光谱信息于一身的新技术,兼有这两种技术的优势,既能对番茄氮素亏缺引起的灰度、纹理变化等特征进行可视化分析,又能对番茄叶片光谱特性的各向异性分布进行评价.因此本研究提出基于高光谱图像技术的番茄氮素营养诊断方法以提高番茄氮素营养诊断的全面性、可靠性和灵敏度,为氮营养水平快速诊断提供参考.
1 材料与方法
1.1 样本准备
试验于2011年3月至2011年8月在江苏大学现代农业装备与技术教育部重点实验室Venlo型温室进行,供试番茄品种为美国朗姆斯.为保证样本培养不受土壤等因素的影响,采用珍珠岩盆栽的方式进行样本培育.在保证其他营养元素均衡的情况下,对氮素进行精确控制,以获取不同氮素胁迫的样本.营养液采用山崎配方,按4个氮素水平(N1,N2,N3,N4)处理,每 20 株为 1 个水平组,4 个水平组氮元素的质量分数依次为正常配方的0%,50%,100%,150%,其中100%是番茄正常生长所需要的量.
1.2 全氮质量分数测定
叶片样本全氮测定采用凯氏定氮法.称取80℃恒温烘后的样本1 g,加入5 mL浓硫酸加热至380℃消煮4 h,采用英国 SEAL公司AutoAnalyzer3
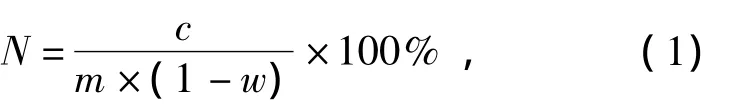
式中:N为测试样本的全氮质量分数,%;c为样品液仪器观测值,mg;m为测试样本的质量,mg;w为测试样本的含水率,%.
1.3 试验装置
利用高光谱成像系统采集番茄叶片高光谱图像,系统主要由基于图像光谱仪的高光谱相机、150 W卤钨灯直流可调光源、二分支光纤线光源、位移台、控制器和计算机等部件组成.
1.4 图像采集与处理
在高光谱图像数据采集前,预先确定可见-近红外相机的曝光时间以保证图像的清晰,确定位移台的速度以避免图像尺寸和空间分辨率的失真.经过分析比较确定曝光时间为20 ms,位移台的移动速度为1.25 mm·s-1.数据采集时,首先进行黑场和白场标定,设定反射率范围,进而利用二阶巴特沃茨滤波器进行数字滤波,去除噪声干扰.
高光谱图像数据的采集基于Spectral Cube软件平台;采集的光谱范围为390~1 050 nm,光谱分辨率为2.8 nm,采样间隔为1.2 nm,一次采集可获取512幅独立的高光谱图像.高光谱图像的处理基于 ENVI V.4.5 和 Matlab V.7.10.0 软件平台进行.型连续流动分析仪对测试样本进行分析.按照下式计算样本全氮质量分数:
2 结果与分析
番茄叶片在390~1 050 nm范围内的光谱曲线在450 nm以下和900 nm以上区域存在着明显的噪声,因此在后期的数据处理过程中,选取450~900 nm范围内的高光谱图像进行分析.
高光谱图像数据立方体是由波长390~1 050 nm范围的512幅图像构成.如图1a所示,x和y轴代表图像的空间位置,λ轴代表光谱的波长.当λ取某一固定值,可以得到λ波长下的图像,如图1b所示.高光谱图像数据包含的数据量比二维图像和一维光谱的数据量都要大得多.数据量过大影响后期数据处理的速度.因此,必须对其进行降维.提取λ轴上所有图像的灰度、纹理特征,并与对应的λ值表示成散点图,得到灰度特征曲线图1c和纹理特征曲线图1d,这样就将三维的数据立方体转化为二维特征曲线,从而实现降维.
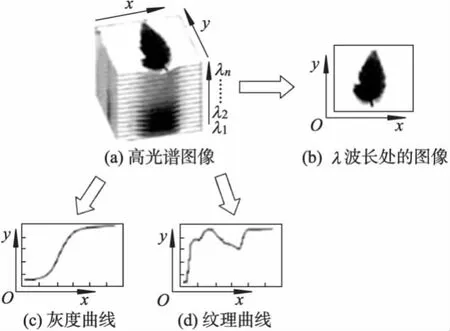
图1 高光谱图像数据块
2.1 特征提取
2.1.1 灰度特征
叶片作为光合作用的主要器官,氮素的多寡导致番茄叶片灰度特征发生变化.当植株缺氮时,直接影响植株叶绿素的合成,使叶色褪淡,呈淡绿、黄绿.当植株氮素过剩时,叶片大而深绿,柔软披散,植株陡长[5].因此由植株叶片颜色的变化而直接导致的图像灰度值的变化是表征作物营养水平的重要信息,并且具有一定的稳定性,对大小、方向都不敏感,表现出相当强的鲁棒性.
不同氮素胁迫水平下的灰度特征曲线见图2,由图可知,在可见光区域内随着氮素水平的提高,灰度均值下降,而在近红外区域灰度均值的变化规律与可见光区域恰恰相反.这一结论与中国农科院的王克如等[6]对棉花叶片的研究结果一致.
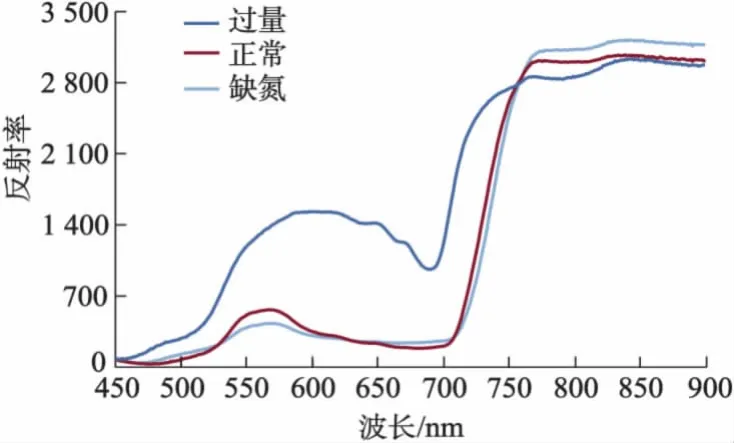
图2 不同氮素胁迫下番茄叶片灰度特征曲线
2.1.2 纹理特征
番茄生长过程中,不同氮素胁迫会对番茄叶片的叶脉纹路粗细和深浅、灰度分布等产生影响,叶片上这种有规则的纹路和颜色变化形成了纹理现象,正常与非正常营养状态叶片在纹理的粗细、分布走向上有较大差别.纹理特征是反映宏观意义上灰度变化规律的重要特征,是对图像象素灰度级在空间上分布模式的描述[7].纹理特征作为高光谱图像分析的一个重要辅助信息源,能更好地兼顾图像宏观性质与细微结构2个方面,识别准确率更高.本研究采用灰度共生矩阵提取叶片图像区域的纹理特征,熵、二阶矩、协同性、相异性、对比度以及相关性,见图3.
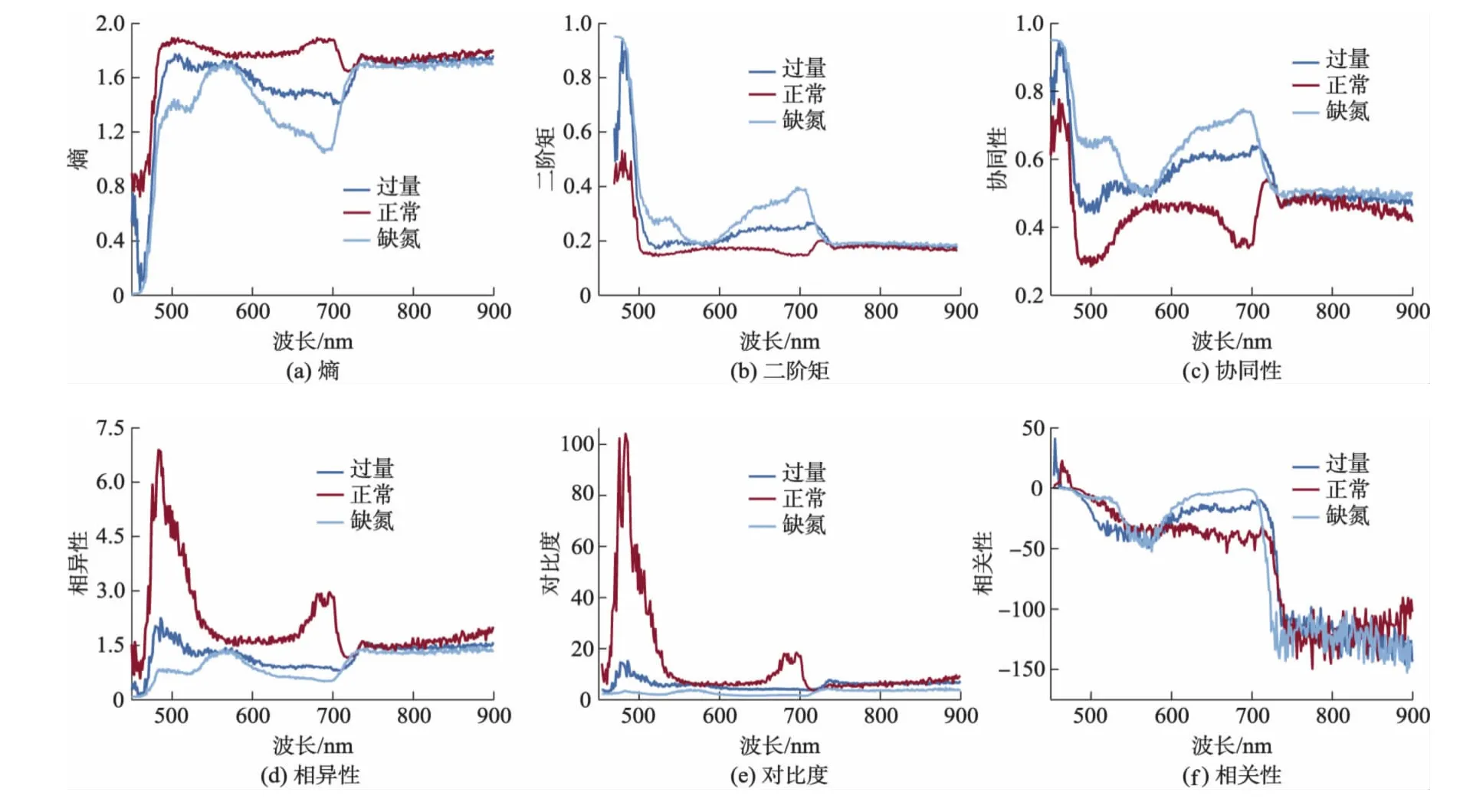
图3 不同氮素胁迫下番茄叶片纹理特征曲线
由图3可知,在可见光区域内熵、二阶矩、协同性、相异性的特征曲线对不同氮素胁迫的番茄叶片的区分度较好,有利于识别,而对比度和相关性的区分度相对较差,提取特征时不予考虑.而在近红外区域内纹理特征对氮素营养水平的区分均不明显.因此,在后期的处理中选取前4个纹理特征的可见光波段区域进行分析.
2.2 特征波长的提取
由灰度、纹理特征曲线(图2,3)可知,不同波长下的灰度、纹理特征值对不同氮素胁迫番茄叶片的区分度不同,且相邻波段的特征值之间具有较强的相关性,会造成大量的冗余信息.因此,对所有波长进行筛选,在不影响分类精度的前提下,去除多余特征,并选出最利于区分番茄叶片氮素胁迫的特征波长,以提高后期数据处理速度.
特征选择方法(CFS)是根据基于相关性的启发式评价函数来选择属性子集,CFS不仅能过滤掉与类别相关性差,对预测结果无关联的特征,又能根据特征之间的高度相关性,剔除子集中冗余的特征.Merit是根据属性间相关测度对属性子集进行评价的函数,在特征选择过程中,作为子集的评价标准[3],计算公式如下:
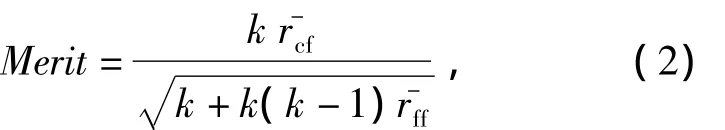
式中:Merit值是包含k个特征的子集的评分是特征与类别之间的平均相关系数是特征与特征之间的平均相关系数.
利用CFS方法并配合分散搜寻Scatter Search搜索方法分别提取灰度、纹理特征的特征波长,结果见表1.

表1 CFS法提取灰度、纹理特征的特征波长
在表1列出的特征波长子集中,482,549 nm属绿光区域,669,684 nm属于红光区域,830 nm属于近红外区域.这主要由于叶绿素是含氮化合物,植株缺氮必然引起叶绿素减少,其他色素增多,叶片不同部位的颜色差异加剧,引起绿光区域的反射率发生变化,直接影响叶片高光谱图像灰度值的变化;同时叶绿素的分子结构又决定了对红光的强烈吸收作用,导致红光区域的反射率也发生变化;而缺氮致使叶片内部栅栏组织、海绵体退化,表面产生不均匀非线性分布的纹理,叶片内部结构多次散射,近红外区域反射率相对较高[8].
2.3 模型建立与结果
支持向量机是目前应用比较广泛的分类方法,兼顾训练误差和泛化能力,在解决小样本、非线性、高维数、局部极小值等模式识别问题中表现出许多特有的优势[9].本研究采用支持向量机对番茄氮素营养水平进行识别.
根据所提取的特征波长,每个样本共有12个特征变量.这些特征变量之间存在一定的相关性,并且过多的特征变量也会影响支持向量机的学习速度.首先采用主成分分析对特征变量进行压缩,前9个主成分所对应的累积方差贡献率已到达99%,能解释原始数据99%的信息,且它们之间相互独立,消除了冗余信息,提高了模型的稳定性,因此,将提取的前9个主成分因子作为模型的输入变量.
SVM的分类性能受到下面2个因素影响:①核函数形式;② 误差惩罚参数C以及核函数参数g.而误差惩罚参数以及核函数参数对分类结果的影响尤为突出[10].
常用的核函数有线性核函数、多项式核函数、径向基核函数和Sigmoid核函数.线性核函数只有在样本数据线性可分的情况下才能得到较好的分类效果;多项式核函数当其阶次较高时会导致数值计算困难,耗费大量时间和资源;Sigmoid核函数收敛速度很慢.而在没有先验知识指导的情况下,采用径向基核函数往往能够得到较好的分类结果[10-11],因此本研究选用径向基函数作为核函数.
确定径向基核函数为核函数后,此时需要确定最重要的2个参数即惩罚因子C与核函数参数g.文中选用网格搜索法、基于遗传算法的寻优算法和基于粒子群算法的寻优算法选取最佳参数,见表2.
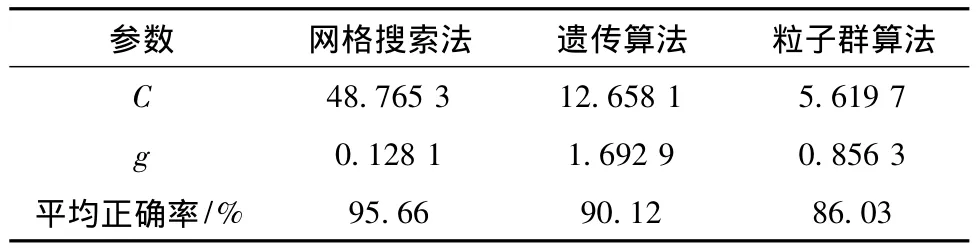
表2 不同参数寻优方法选取的最优参数
由表2可以看出网格搜索法参数寻优效果最佳,与另2种方法相比其避免了陷入局部最优.惩罚因子为 48.765 3,核函数参数为 0.128 1.
选取200个不同氮素胁迫的番茄叶片样本,将其中的100个样本作为训练集,其余的100个样本作为测试集,根据前文的讨论结果,设置模型参数,利用SVC法对样本集进行训练和模型预测精度分析.表3为番茄各氮素营养水平的预测结果,从中可以看出,总识别率为92%,番茄各氮素营养水平的正确识别率分别为96%,88%,92%,92%.

表3 不同氮素胁迫番茄叶片的预测集识别结果
如表3所示,N1水平的样本最容易辨别出来,说明N1与其他3个水平的特征差异性最大,即极缺氮状态下的番茄叶片的特征性最强,其次是N3和N4,而N2水平样本的识别率相对较低,较容易被误判为N1.
3 结论
1)利用高光谱成像技术获得番茄叶片高光谱图像,提取高光谱图像的灰度、纹理特征,将高光谱数据立方体转化成二维特征曲线,再通过特征选择方法CFS对所有波长进行筛选,选取了4个灰度特征的特征波长和2个纹理特征的特征波长,实现高光谱数据的有效降维.
2)根据所提取的特征波长,每个样本共有12个特征变量,对这12个变量进行主成分分析,提取前9个主成分因子数作为模型的输入向量,利用支持向量机建立番茄氮素营养水平诊断模型,模型的总识别率为92%,N1,N2,N3,N4正确识别率分别为96%,88%,92%,92%,说明利用高光谱图像技术对番茄氮素营养水平进行诊断是可行的.
3)文中只对番茄氮素营养水平进行了诊断,今后将进一步利用高光谱图像技术对氮素含量进行无损检测,建立数学模型,给出番茄氮素营养水平综合评价,为作物营养水平快速诊断仪的开发提供参考.
References)
[1]Graeff S,Claupein W,Schubert S.Use of reflectance measurement for the early detection of N,P,Mg and Fe deficiencies in Zea mays[J].Plant Nutr Soil,2001,164:445-450.
[2]Pagola M,Ortiz R,Irigoyen I,et al.New method to assess barley nitrogen nutrition status based on image color analysis:comparison with SPAD-502[J].Computers and Electronics in Agriculture,2009,65(3):213-218.
[3]Hall Mark A.Correlation-based feature selection for machine learning[D].Hamilton,New Zealand:The University of Waikato,1999.
[4]石媛媛.基于数字图像的水稻氮磷钾营养诊断与建模研究[D].杭州:浙江大学环境与资源学院,2011.
[5]祝锦霞,邓劲松,石媛媛,等.基于水稻扫描叶片图像特征的氮素营养诊断研究[J].光谱学与光谱分析,2009,29(8):2171-2175.Zhu Jinxia,Deng Jinsong,Shi Yuanyuan,et al.Diagnoses of rice nitrogen status based on characteristics of scanning leaf[J].Spectroscopy and Spectral Analysis,2009,29(8):2171-2175.(in Chinese)
[6]王克如,潘文超,李少昆,等.不同施氮量棉花冠层高光谱特征研究[J].光谱学与光谱分析,2011,31(7):1868-1872.Wang Keru,Pan Wenchao,Li Shaokun,et al.Different nitrogen cotton canopy spectral characteristics[J].Spectroscopy and Spectral Analysis,2011,31(7):1868-1872.(in Chinese)
[7]甘露萍,谢守勇,邹大军.基于计算机视觉的烤烟鲜烟叶含水量无损检测及Matlab实现[J].西南大学学报:自然科学版,2009,31(7):167-170.Gan Luping,Xie Shouyong,Zou Dajun.Computer visionbased non-destructive determination of water content in fresh tobacco leaves of flue-cured tobacco and its implementation in Matlab[J].Journal of Southwest Agricultural University:Natural Science Eidtion,2009,31(7):167-170.(in Chinese)
[8]潘瑞炽.植物生理学[M].北京:高等教育出版社,2001.
[9]边肇祺,张学工.模式识别[M].北京:清华大学出版社,2002.
[10]奉国和.SVM分类核函数及参数选择比较[J].计算机工程与应用,2011,47(3):123-124.Feng Guohe.Parameter optimizing for support vector machines classification[J].Computer Engineering and Applications,2011,47(3):123-124.(in Chinese)
[11]彭彦昆,黄 慧,王 伟,等.基于 LS-SVM 和高光谱技术的玉米叶片叶绿素含量检测[J].江苏大学学报:自然科学版,2011,32(2):125-128.Peng Yankun,Huang Hui,Wang Wei,et al.Rapid detection of chlorophyll content in corn leaves by using least squares-support vector machines and hyperspectral images[J].Journal of Jiangsu University:Natural Science Edition,2011,32(2):125-128.(in Chinese)
