基于病毒吸附机制的制造知识与设计需求匹配研究
2014-12-19王克勤刘天航同淑荣张新卫
王克勤,刘天航,同淑荣,张新卫
WANG Ke-qin, LIU Tian-hang, TONG Shu-rong, ZHANG Xin-wei
(西北工业大学 设计管理研究所,西安 710072)
0 引言
可制造性是产品设计需要考虑的重要因素之一[1]。产品设计作为知识密集型活动,在考虑产品的可制造性问题时,需要制造知识的支持,以确保产品的可制造性。研究发现,设计人员依赖与人的接触获取知识的比例呈下降趋势,对知识系统的依赖则逐渐递增[2]。但目前存在的制造知识系统普遍存在着知识供需匹配程度不高的问题:当设计人员进行某一设计活动时,查询制造知识往往存在查全率有余、查准率不足的现象,需要花费大量时间来甄别其真正需要的知识,增加了设计人员的工作量。
实践证明,设计活动需要制造知识时却找不到知识的主要原因是知识定位不明确,未将知识与具体的设计活动精确挂钩。不同背景设计人员开展不同设计活动时需要不同的知识,只有充分了解设计人员的知识需求,将制造知识与详细的设计活动精确匹配,才能最大程度的发挥知识效力。
目前国内知识匹配相关领域的研究,主要先根据特定原则建立信息模型或者语义模型,从而建立相应的数据结构,通过文本或语义相似度的计算,实现供需双边的匹配。茅健等人提出了一种产品设计过程中基于语义距离的设计质量知识的表示及匹配方法,以任务元、对象元、信息元来构建三者的形式化描述体系,并建立其数据结构。利用HNC(概念层次网络)知识库,基于语境框架文本相似度计算,实现设计质量信息的实时有效匹配[3]。浙江大学的王生发等人根据知识主动匹配算法分析了设计任务、设计子任务、设计人员、设计知识及其数据结构,提出了基于设计对象的文本相似度计算方法[4]。蒋翠清等人基于概念语义扩展的设计知识检索方法,给出了面向产品设计人员的知识服务层次模型和需求驱动的产品设计知识服务运行模式[5]。王士凯等人采用本体描述语言,建立领域知识与情境知识本体模型、情境-知识关系模型,以及情境相似度算法设计,构建出仿真过程知识领域本体模型[6]。
病毒感染宿主细胞是通过精确吸附达到目的,制造知识与设计活动之间的供需关系与病毒和宿主细胞之间的特异性吸附机制非常类似。若借鉴此原理,将制造知识对应为病毒,将设计需求对应为宿主细胞,找出制造知识在支持设计方面的病毒性特征,以及设计活动的制造知识需求意图所具有的病毒受体蛋白质特征,建立基于二者蛋白质关键位点契合原理的制造知识匹配方法,能够明确地表达设计需求,则可向设计人员匹配所需知识。
1 病毒吸附原理
病毒由基因组和包容它的蛋白质以及若干功能性蛋白质共同组成的颗粒状物。如图1所示为HIV病毒的形态模式图。
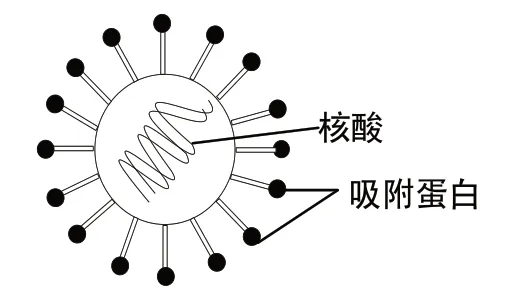
图1 HIV病毒形态模式图
病毒结构简单,一个简单病毒仅由核酸(DNA或RNA)和蛋白质外壳——衣壳组成[7]。病毒表面上能够识别特异宿主细胞受体的结构蛋白,称为病毒吸附蛋白。
宿主细胞即为病毒攻击的对象。存在于宿主细胞表面上能被病毒吸附蛋白特异性地识别并与之结合,使病毒侵入细胞和启动感染发生的细胞表面组分称为病毒的细胞受体。病毒受体是引发病毒感染宿主细胞的主要决定因素,也是影响病毒宿主特异性的决定因素之一[7]。通常来讲,细胞受体即为宿主细胞膜表面的蛋白质。
病毒基因若要进入细胞内环境,首先要与细胞表面的特异性受体结合,即病毒吸附。病毒吸附蛋白与宿主细胞表面结合后,能够启动病毒粒子或病毒核酸进入宿主细胞的过程。完成吸附过程的关键即病毒利用其表面病毒配体蛋白质结构上的特异性位点,主动、精确识别和吸附敏感宿主细胞表面的病毒受体蛋白质位点,并通过成功逃避宿主细胞的免疫防御反应,使宿主细胞受到感染。病毒吸附宿主细胞机制如图2所示。
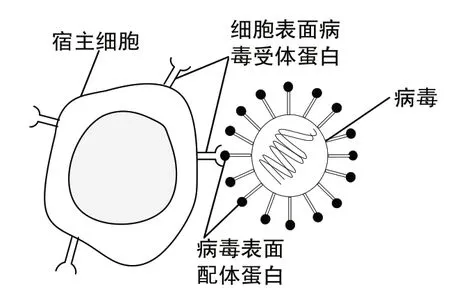
图2 病毒吸附宿主细胞机制
2 制造知识仿病毒模型和设计需求仿宿主细胞模型构建
将病毒吸附宿主细胞机制映射至制造知识与设计人员之间的供需关系,描述如下:
病毒是一个高度致密的颗粒(对应制造知识),表面有特定的蛋白质关键位点(对应制造知识的特征),宿主细胞(对应设计需求)表面的蛋白质关键位点(对应知识需求的特征)能与其特异性的吸附(制造知识与设计需求的准确匹配)。当病毒完成吸附过程中后,会将其遗传物质DNA或RNA注入到宿主细胞中(制造知识本身的详细内容到达设计人员)。在一系列过程之中,两者结构与内容上的共性是完成相互识别的关键之处。
根据制造知识和设计需求之间的病毒配体和受体的特异识别性,建立两者之间的特征匹配模型,准确表述两者之间的共同特性,为实现知识匹配提供基础。
基于病毒吸附机制和制造知识与设计需求两者之间关系的分析,以及领域内已有知识匹配模型的优缺点比较,从支持设计的角度分析制造知识的类别、表现形式及特征等,将制造知识按照病毒的形式表示,构建制造知识的仿病毒模型。模型表示如下:
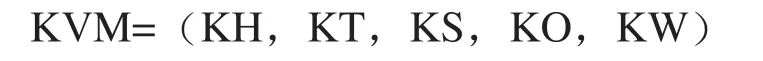
其中,KVM代表制造知识的仿病毒模型,KH,KS,KT,KO,KW即为仿病毒模型中的各蛋白质关键位点。其中:KH代表制造知识文档的标题;KT代表制造知识的类别;KS代表制造知识的应用阶段;KO代表该制造知识所适用具体设计对象;KW代表制造知识的关键词。而仿病毒模型中的“DNA”即为制造知识的具体内容描述。模型映射过程和制造知识的仿病毒模型的结构示意如图3所示。
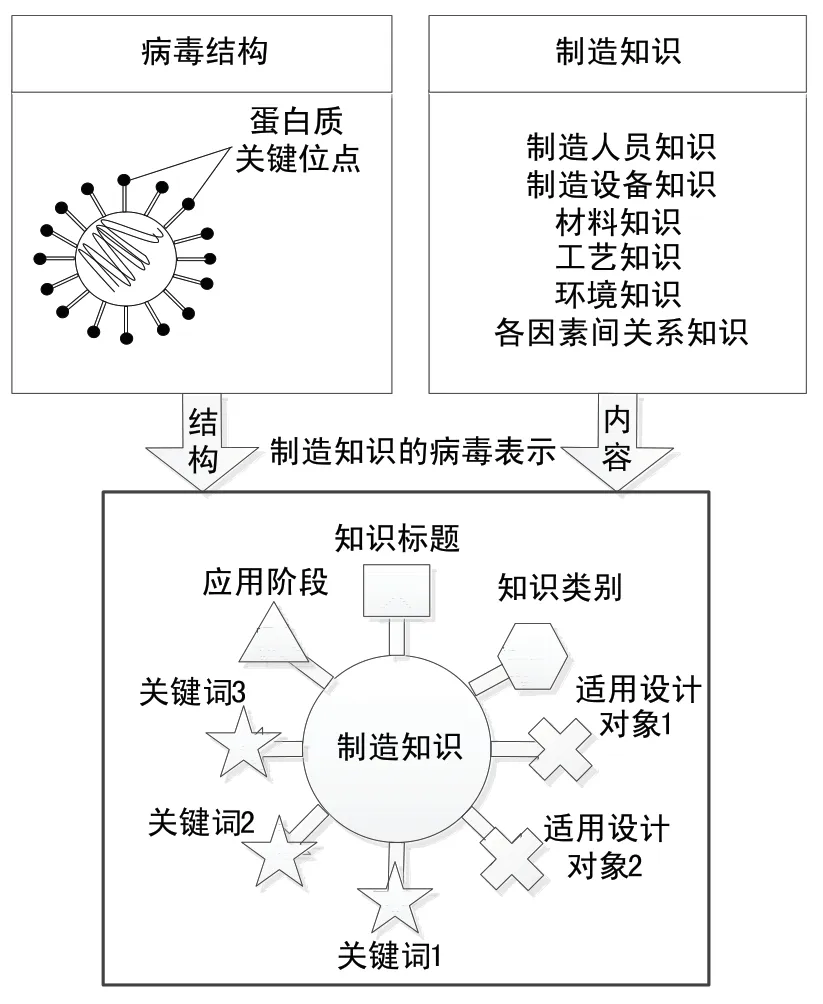
图3 制造知识的仿病毒模型表示
针对上述知识的不同类别、表现形式及特征等,结合知识的病毒化模型,为了与其匹配,设计相应的设计需求宿主细胞模型DHM=(DH,DT,DS,DO,DW)。构建的设计需求仿宿主细胞模型结构如图4所示。
以“铝合金严格热处理工艺的制造知识”为例,将制造知识按照仿病毒模型进行封装,以体现制造知识特异性,如表1所示。若按此模型将已有全部制造知识进行封装,则可形成制造知识病毒库。
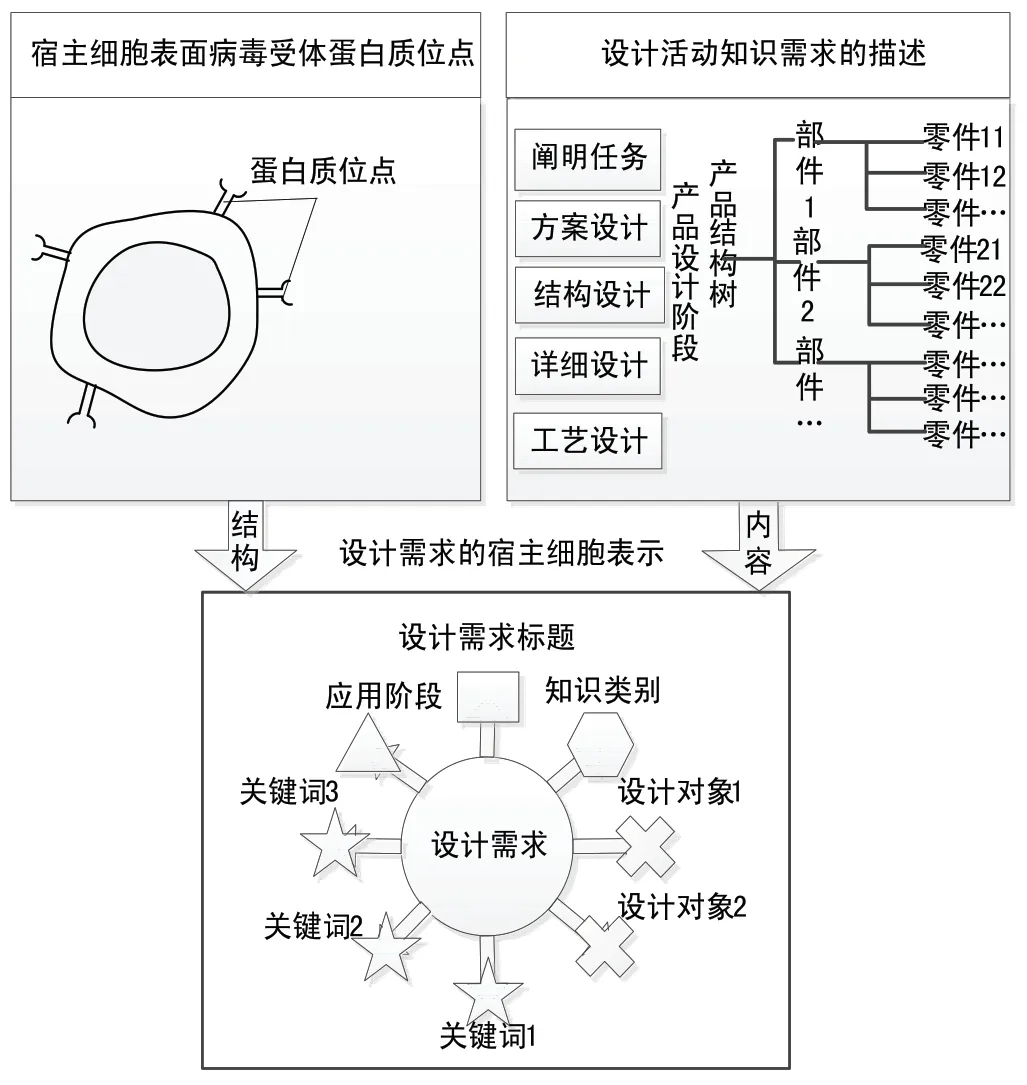
图4 设计需求的仿宿主细胞模型
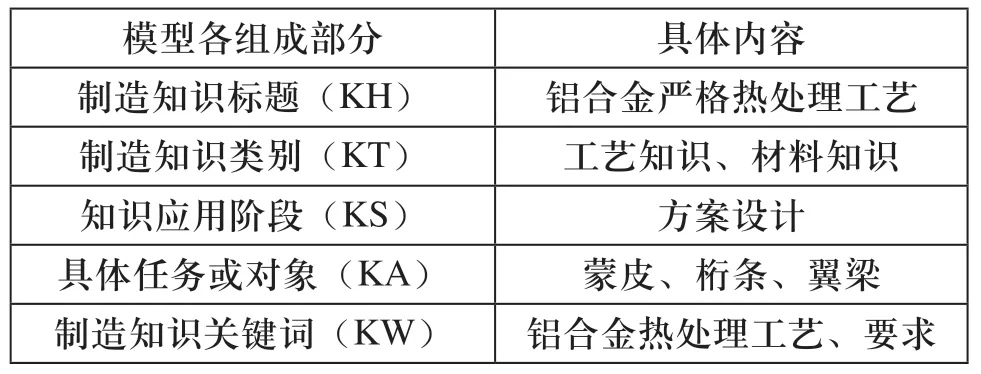
表1 制造知识的仿病毒模型封装示例
此条制造知识的具体描述是:加热温度精确控制,要求热处理加热炉炉温均匀性≤±5℃;限制淬火转移时间,我国航空标准规定,铝合金淬火转移时间≤15秒;限制包铝铝合金热处理加热速率和固溶处理次数;淬火后时效前的冷变形和冷冻,铝合金冷冻处理温度一般≤-18℃。
以飞机翼梁在进行翼梁的方案设计时,需要了解翼梁所用材料的一些特性为例,可以提出一个具体的设计需求,按照设计需求的仿宿主细胞模型进行封装,以体现设计需求的特异性,如表2所示。若按照此模型将所有的设计需求进行封装,则可形成设计需求的宿主细胞库。
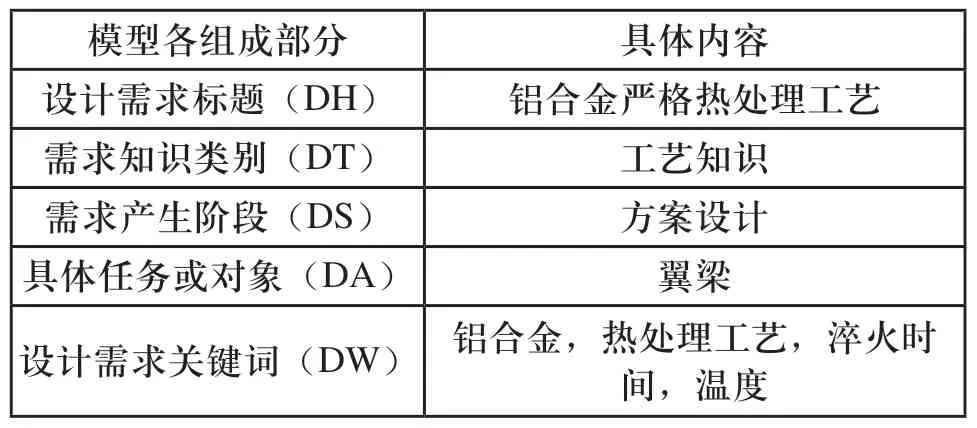
表2 设计需求的仿宿主细胞模型封装示例
此条设计需求的具体描述为:在进行翼梁设计时,需要了解其铝合金材料在热处理工艺过程中需要注意的问题,如温度控制,淬火转移时间等。
3 知识匹配算法与实现
向量空间模型(VSM)是近年来使用较多且效果较好的一种信息检索模型,其核心思想是用向量表示文档,将一个文档映射至n维向量空间。
基于上述概念,向量空间模型对文本进行数学建模的思路为:忽略各个特征项在文本中出现的先后顺序,并假设所有的特征项之间是互不相干的,将文本视为若干相互独立的特征项的组合。以不同的特征项构造一个高维空间,每个特征项为该空间的一个维,文本则被看作这个空间中的一个向量。
向量空间模型是把文档中的每个关键词看成一个维度,把词对于文档的重要程度作为其值,一般做法是一个概念相对于一个文档的重要程度[8]:
1)与它在该文档中出现的次数成正比;
2)与该概念在所有文档中出现过的文档数成反比。
由此每篇文章的词及词的频率就构成了一个多维向量空间,两个文档的相似度就是两个向量的接近度。
将制造知识表示为:
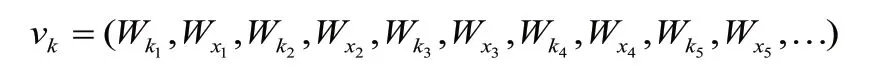
并把设计需求表示为:
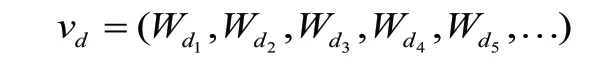
制造知识文档中的概念词可能出现在文档中的不同描述区间中,如知识标题、关键词等。在不同的描述区间中,概念词相对于知识文档的重要程度可能不一样,因此,需要对每个描述区间的重要程度进行设定,以提高查准率,从而提出知识匹配的模型:
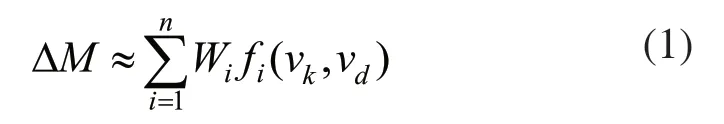
其中,ΔM 代表制造知识与设计需求的匹配结果最终值,Wi表示匹配特征项和描述区间的综合权重,vk,vd分别代表制造知识和设计需求的对应的特征向量,fi(vk,vd)是计算两个特征向量的匹配程度的函数。
设Wki为概念词在制造知识源文档中的特征权重,n为Ki在这个文本中出现的个数,m为其他所有文本中含有Ki的文档的个数,M为文档的总数。概念相对于设计知识源文档的特征权重计算方法:
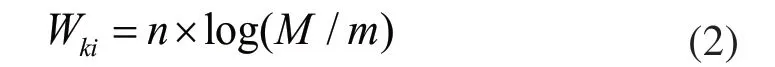
相似度计算公式如下:
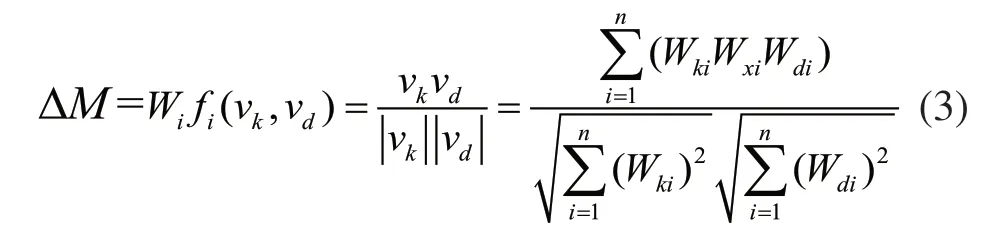
其中,Wki为制造知识文档中概念词Ki的特征权重;Wxi为概念词Ki的描述区间权重,Wdi代表设计需求概念词Di的特征权重,Wxi和Wdi一般由经验确定。
经过计算,从而得出制造知识和设计人员知识需求之间的相似度ΔM,若ΔM(vk,vd)大于阈值,则匹配成功。此时,输出所有大于阈值的制造知识,即为满足设计人员需求的知识。
4 实例应用
假设,某型号飞机在进行机翼蒙皮方案设计的过程中,设计人员需要了解7xxx系铝合金热处理工艺过程中涉及到的一般知识。结合上文中建立的知识匹配模型,首先将设计人员的设计需求模型化,DHM=(7xxx系铝合金工艺热处理;工艺知识;方案设计;机翼蒙皮;7xxx系铝合金)
在某制造知识系统中,列举部分有关7xxx系铝合金热处理工艺的制造知识如下:
在本例中,为了计算简便,均将设计需求及各制造知识的模型向量空间封装为5维向量空间。
根据向量空间模型的表示方法来表示设计需求时,各向量值(即Wdi)的含义即为概念词在设计需求中的特征权重,一般由经验确定。本例中,DHM=(7xxx系铝合金工艺热处理;材料知识;方案设计;机翼蒙皮;7xxx系铝合金),设计需求的向量模型为:vd=(1,2,2,1,2),即标题和设计对象的概念特征权重较低,其余则较高。
下面进行制造知识的向量表示,因为制造知识的向量模型表示为:

为制造知识各概念描述空间的权重值,一般由经验确定。为计算简便,设本例中各制造知识的Wxi值均为:
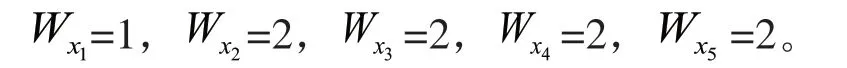
根据以上数据,可以计算出匹配值ΔM 的大小,如表3所示。
设在此类情况下,知识匹配结果的阈值为1.25,大于匹配阈值的制造知识按照匹配结果值的降序排列是,从整体上看,匹配结果较为合理。
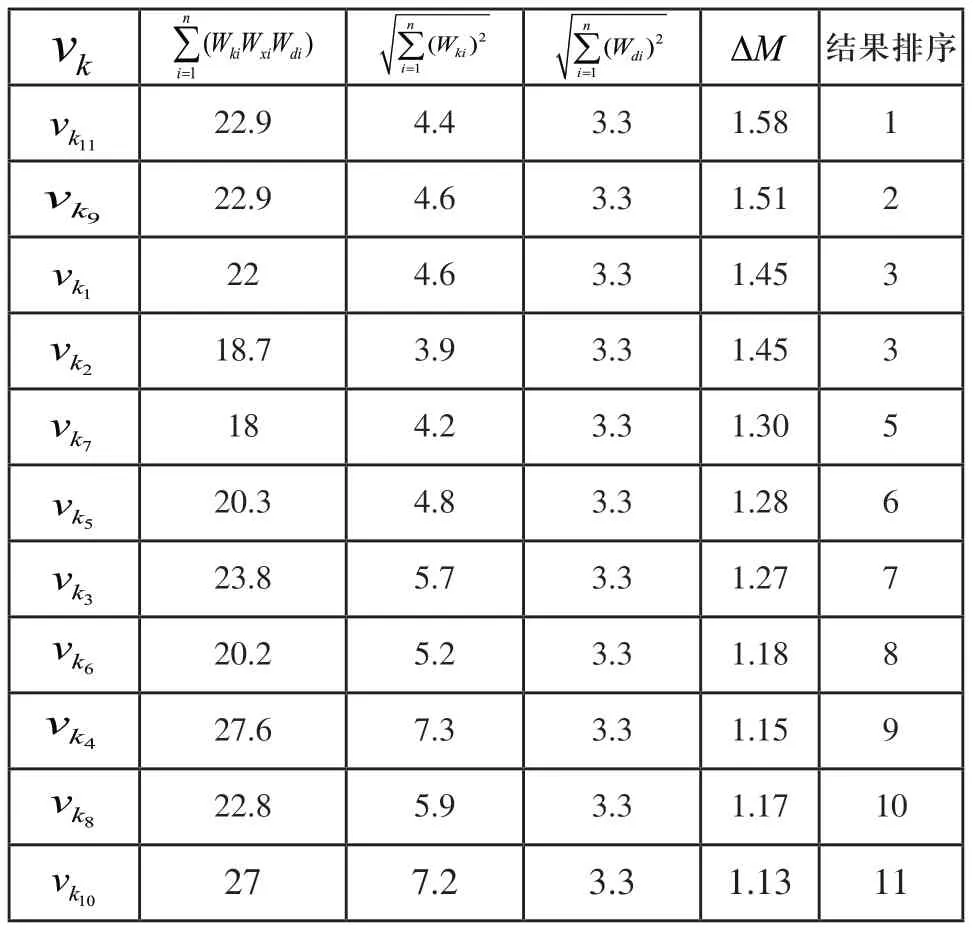
表3 ΔM 值
5 结论
针对目前制造知识与设计需求匹配程度低的问题,借鉴病毒吸附宿主细胞机制,构建了制造知识的仿病毒模型和设计需求的仿宿主细胞模型,提出算法实现了知识匹配过程,以某型号飞机在进行机翼蒙皮方案设计的过程中,设计人员需要了解7xxx系铝合金热处理工艺过程中涉及到的一般知识为例,完成了某制造知识系统内制造知识与该设计需求的匹配过程的实现。
研究借鉴病毒吸附机制为设计过程中设计人员精确获取所需制造知识提供了一种参考方法,需要进一步研究的工作包括:1)匹配后知识的主动推送;2)知识匹配算法改进;3)知识匹配阈值的合理确定。
[1]Boothroyd G.,Dewhurst P.Product Design for Manufacture and Assembly(Third Edition)[M].Florida:CRC Press,2010.
[2]Aurisicchio M.,Bracewell R.,Wallace K.Understanding how the information requests of aerospace engineering designers influence information-seeking behaviour[J].Journal of Engineering Design,2011,21(6):707-730.
[3]茅健,曹乃亮,曹衍龙,等.产品设计过程中质量知识的匹配方法[J].农业机械学报,2012,43(1):197-201.
[4]王生发,顾新建,郭剑锋,等.面向产品设计的知识主动推送研究[J].计算机集成制造系统,2007,13(2):234-239.
[5]蒋翠清,高家飞,李斌生.面向产品设计人员的知识推送服务研究[J].合肥工业大学学报(自然科学版),2012,35(3):392-397.
[6]王士凯,王力,江平,等.基于情境的知识推送技术研究[J].计算机技术与发展,2013,23(2):131-134.
[7]王小纯.病毒学(第1版)[M].北京:中国农业出版社,2007.
[8]刘宏哲.文本语义相似度计算方法研究[D].北京交通大学,2012.
