基于聚类蚁群算法的虚拟机资源分配算法研究
2014-12-17蒋茜,何嘉
蒋 茜,何 嘉
(成都信息工程学院 计算机学院,四川 成都610225)
0 引言
云计算是建设智慧城市的重要支撑技术,它以互联网为媒介,博取分布式结构、网格技术和并行计算概念的长处,与以往的服务模式相比,更具有商业价值.[1-2]云计算的关键技术有实现硬件资源抽象的虚拟化技术、海量数据的存储管理技术、SOA框架与新型Web服务模式、MapReduce等并行编程模型.[3]
云计算环境下的虚拟机资源分配技术是云计算得以大规模应用和提供系统性能、兼顾节能减排的关键技术.[4-5]通过深入系统学习和研究而提出的先进的资源调度技术,对于提高学校、政府、研究机构和企业硬件资源的有效利用率、节约水电等能源、扩大资源共享范围和降低运营成本都具有重要意义.
1 云环境下的虚拟机资源管理
1960年前后,IBM大型计算机系统引入虚拟化概念.[6]随着虚拟化的发展,在云计算环境中,虚拟化的产物除了虚拟机、虚拟网络等概念,还可以代表云计算环境中各种硬件资源的抽象.
虚拟化技术可以将底层的CPU、内存、网络带宽等硬件资源进行抽象,使得云服务使用者无须顾及底层的差异性和兼容性,可以统一管理利旧或其他方式得到的各种不同的底层硬件资源.[7]在虚拟化技术的帮助下,云计算环境中的用户可以通过网络使用任意终端获取来自于“云”中的各种云服务,不需要了解应用运行的具体位置,云服务就像供应日常生活中水电的服务一样.[8]
本文使用的虚拟机资源分配的调度参考结构如图1所示.[9-10]
(1)用户任务请求:以Internet(比如客户端程序、云服务商的主页)为入口,用户提交作业,发起任务请求;
(2)总调度管理:调度中心Controller依据用户的身份特征(比如地理位置等)和请求的业务特征(数量和质量要求),将请求提交给合适的服务器域的任务管理程序Master节点;
(3)各区Master节点调度资源:Master节点执行某种调度算法将可用的实际资源信息反馈,对该资源请求分配;
(4)分配资源:Master节点执行调度,用户任务开始使用虚拟机资源;

图1 云环境下的资源调度体系
(5)后台优化:调度中心在后台同时执行优化操作,将不同数据中心的资源按照优化目标函数和空闲及配置等信息排序优化,以备后来者使用.
2 云环境下虚拟机资源分配策略
2.1 问题建模
用户提交任务,任务被放置在虚拟机上,虚拟机共享物理机资源,由此可将虚拟化资源调度分为两个阶段:① 微观上的调度重点在于物理机的CPU、内存和带宽资源在虚拟机之间使用共享;②宏观上的调度为虚拟机和物理机之间的合理映射,涉及负载均衡等原则.本文将虚拟机资源分配的过程抽象为如图2所示.
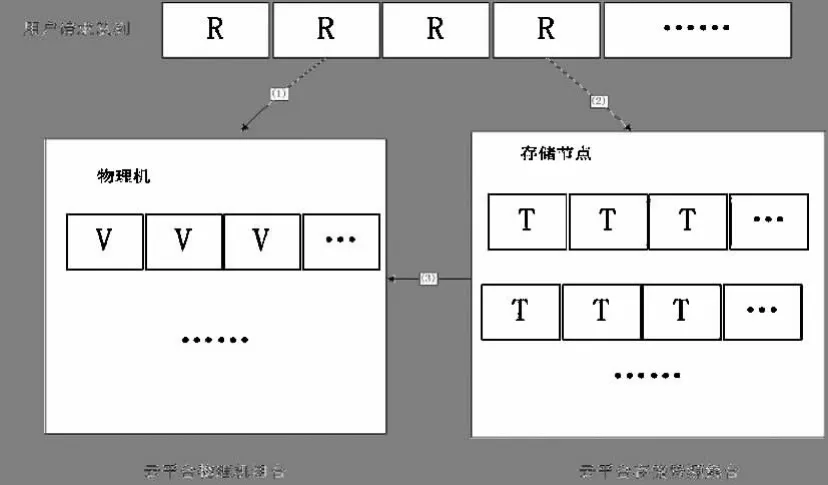
图2 虚拟机调度的抽象模型
可将调度函数描述为如下的四元表:大的调度长度
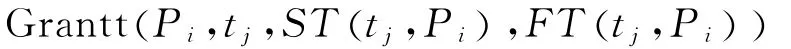
其中:Pi(i=1,2,…,m)为处理单元;tj(j=1,2,…,n)为分配到Pi上的任务;ST(tj,Pi)为tj在Pi上的开始时间;FT(tj,Pi)为tj在Pi上的结束时间.最小化最是任务调度的目标.
用矢量装箱问题(vector bin-packing problem)来求解虚拟机的分配调度,则将虚拟机当做物品,装入物理服务器(箱子).[11-13]
用遗传算法模型来描述该问题:把解看成个体,个体的染色体N为虚拟机的个数,物理服务器的个数为M,将第i个元素的值取为h,解释为“物理服务器h上运行着第i个虚拟机”.[14]通过改变两个染色体的基因片段进行组合杂交,变异则是虚拟机从当前物理机随机放置到另一台物理机上的过程.[15-16]
基因算法和简单装箱算法各有优劣,而蚁群算法[17-19]有鲁棒性、分布式并行计算等更合适于搜寻虚拟机节点的优点.
2.2 算法描述
基于聚类和蚁群算法的虚拟机资源分配算法,主要包括4个关键步骤.
2.2.1 物理服务器分组
将服务器按地理位置分组,每一组设置一个Master节点.从用户任务提交的总调度中心Controller节点出发,遍历每个Master节点,按照其距离对每个区域进行编号,用 D=D1,D2,…,Ds{}表示s个地区的集合2.2.2 用户任务聚类
假设用户任务之间相互独立,用T=T1,T2,…,Tn{}表示n个任务的集合,用一维向量 Ti= tif,tir,tih,tik,tit
{}来表示任务Ti,分别表示完成任务所需要CPU计算能力、内存容量、硬盘大小、带宽容量和预计完成所需时间.
在对用户任务计算任务相似度时,选用欧式距离计算,只考虑用户预计完成所需时间属性tit,故任务Ti和Tj的相似度公式为:

利用K-means聚类算法,将分组后的任务提交给Controller节点,由Controller根据任务所在的物理位置,分发给对应服务器域的Master节点.
2.2.3 利用蚁群算法进行虚拟机分配
(1)信息素定义
我们用虚拟机的硬件资源来衡量一个节点的信息素,包括CPU个数m及处理能力ρ(MPIS)
,内存容量r,硬盘大小h,带宽b.并按以下公式为每个参数设置一个阈值,并初始化各种信息素.

CPU计算能力的信息素:

内存的信息素:

硬盘的信息素:

带宽的信息素:

各个信息素的带权和就是节点i上的信息素值,公式如下所示.
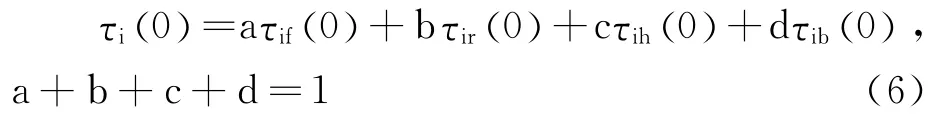
(2)信息素修改
将蚂蚁发现的可用的虚拟机节点称为有效节点.当有新任务分配到有效节点上时,CPU利用率会增大,信息素值反而变小.本文便要增加完成任务的节点的信息素浓度,减少任务失败的节点的信息素.
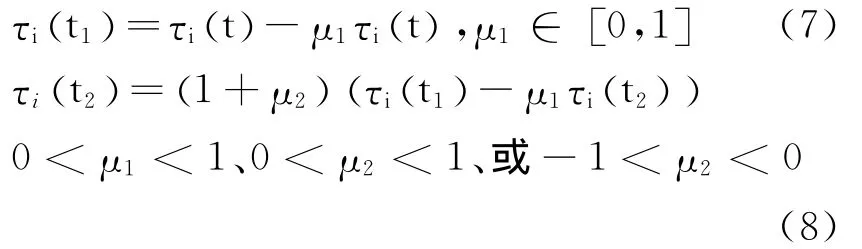
τit()为节点i在时刻t的信息素浓度,t1为新任务到达时间,t2为任务运行成功或失败的时刻.
(3)虚拟机完成任务所需时间的估计
云环境下,Master趋于将任务分配给效率最高的节点,而确定其是否为有效节点,则需要给新任务的预计执行时间设置一个阈值,当其预计执行时间小于或等于这个阈值,这个节点才是.用以下时间模型来预测新任务在节点上的所需执行时间.

(4)蚂蚁选择下一个虚拟机节点的概率
按照公式,蚂蚁选择概率最大的下一个虚拟机节点:

其中:Aj=ETjnpredict(Jpredict(t));Ns为蚂蚁路径节点集;k为i的相邻节点;α,β表示τj和Aj的重要性.
2.2.4 相邻服务器域间任务调度
在服务器域 Dp内,即 CPU、内存、硬盘、带宽任意一项使用完后,就表示物理服务器资源不足.Dp域内Master节点即与相邻距离最近的Dq域内Master节点通信,将剩余任务交由区域Dq的Master节点进行分配.当mmax=∑i∂Nsmi,就从该区域Dp出发,寻找相邻距离最近的Dq,将剩余任务交由区域Dq的Master节点进行分配.
3 算法实施及评价
设用户提交的主要是计算任务,算法中的a,b,c,d分别表示了虚拟机的CPU,内存、外存及带宽的重要性,将a,b,c,d的值分别设为0.4,0.3,0.2,0.1.α,β为调节因子,分别代表了信息素和任务预计执行时间的重要性.m是一个参数,其决定了产生蚂蚁的数量.我们将通过实验来获得α,β,m的最优组合.μ,μ1,μ2为调节信息素改变的因子,设置为0.2,μ2在任务执行失败时为-0.2.ρ为时间估计的调节因子,设为0.4.
随机生成100-400个用户任务预计完成所需时间属性值在区间[1000,11000](单位:毫秒)内的计算任务,虚拟机节点设置为100个,处理能力为200MIPS-400MIPS,处理器为单/双核,内存为100M-200M,带宽为1M/s-2M/s,外存为1G-2G.物理机的聚类算法设其初始分组为2,实验中暂不涉及跨区域的调度.
通过多次实验,参数最终设置为α=2,β=1,m=1.5,对100个任务构成的作业,普通蚁群算法、随机分配算法与基于聚类和蚁群算法的虚拟机资源分配算法(新算法)在任务分配时间方面的比较如表1.
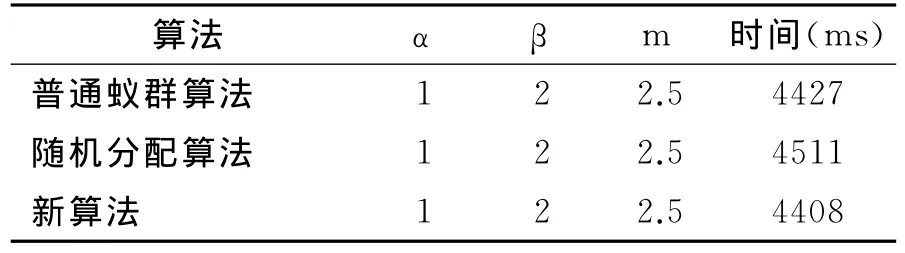
表1 任务分配时间变化统计
当α=1,β=2,m=2.5时,三种算法在任务分配时间、任务执行时间跨度方面的比较如图3、图4所示.
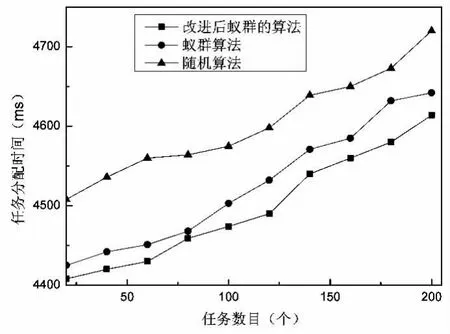
图3 资源分配算法的任务分配时间
由图3、图4可以看出在任务分配时间上,新算法优于蚁群算法和随机算法,但在执行时间跨度方面性能却差不多.

图4 资源分配算法的任务执行时间跨度
4 小结
虚拟机的分配要保证虚拟机的性能,也要使运营商利润最大化.基于聚类蚁群算法的虚拟机资源调度分配算法可增加可用虚拟机节点的发现率,并兼顾算法的收敛性.通过实验,将新算法与随机分配算法、普通蚁群分配算法对比,其任务分配时间较短,任务执行时间跨度体现出降势,能更好地保证用户任务按时完成,满足服务等级协议(SLA).
[1]Armbrust M.Above the Clouds:ABerkeley View of Cloud Computing[R].2009.
[2]《虚拟化与云计算》小组.虚拟化与云计算[M].北京:电子工业出版社,2009:135.
[3]张 兵.云计算的起源、应用与发展方向[J].信息与电脑:理论版,2011(9):37-39.
[4]陈 康,郑纬民.云计算:系统实例与研究现状[J].软件学报,2009(5):1337-1348.
[5]Genaud S,Gossa J.Cost-wait Trade-offs in Clint-side Recource Provisioning with Elastic Clouds[C].New york:IEEE,2011:1-16.
[6]Introduction Cloud Computing architecture White Paper,1st Edition,June 2009.
[7]鲁 松.计算机虚拟化技术及应用[M].北京:机械工业出版社,2008:357.
[8]Garfinkel S.An Evaluation of Amazon’s Grid Computing Services:Ec2,S3 and SQS,Technical Report,TR-08-07.
[9]田文洪,赵 勇.云计算-资源调度管理[M].北京:国防工业出版社,2007:195.
[10]Barroso LA,Dean J,Holzle U.Web search for a planet:The Google cluster architecture[J].IEEE Micro,2003(2):22-28.
[11]Karve A.T,Kimbrel,G.Pacifici,et al.Dynamic placement for clustered web applications[C].Edinburgh:UK,2006(6):23-26.
[12]Chandra Chekuri,Sanjeev Khanna.On multi-dimensional packing problems[J].SIAM,2004(4):837-851.
[13]Leinberger,W.G.Karypis,K.Vipin.Multi-Capacity Bin Packing Algorithms with Applications to Job Scheduling under Multiple Constraints[C].New York:IEEE,1999(9):21-24.
[14]Qi Zhang,Eren Gurses,Raouf Boutaba.Dynamic Resource Allocation for Spot Markets in Clouds[J].IT Convergence Engineering,2010(8):987-1012.
[15]Mark S.David S,Frederic V,et al.Resource Allocation Algorithmsfor Virtualized Service Hosting Platforms[J].Parallel and Distributed Computing,2010(9):962-974.
[16]李建锋,彭 舰.云计算环境下基于改进遗传算法的任务调度算[J].计算机应用,2010(1):184-186.
[17]Dorigo M,Gambardella L M.Ant colony system:A cooperative learning approach to the travelingsalesman problem[C].New York:IEE,1997(1):53-66.
[18]Lingyun Yang,Ian Foster,Jennifer M Schopf.Homeostatic andTendency-based CPU Load Predictions[J].Proceedings of IPDPS,2003(12):1-9.
[19]王 刚,钟志水,黄永青.基于蚁群遗传算法的网格资源调度研究[J].计算机仿真,2009(4):79-82.
