基于Lucene的文献资料全文检索系统的设计与实现
2014-12-14胡宏伟
胡宏伟,虞 萍,周 南,乔 军
(中国农业大学网络中心,北京 100083)
近年来,随着文献资料数量的持续增长及其影响力的日益扩大,文献资料的重要性也在逐渐增加。有鉴于此,许多单位建立了专门的内部文献管理系统,实现了内部文献资料的集中存储和管理,促进了文献资料的应用和推广。
然而,由于现有的文献管理系统多采用目录检索或数据库查询方式,使得其在为用户提供丰富文献资料的同时也给用户的文献查询带来了新的问题,即用户很难采用常规的检索方式实现文献的快速准确查询。因此,如何建立一种能从海量的文献资料中快速、准确查找所需文献的检索系统,就显得很有必要。
研究表明,实现海量电子资料快速、准确检索的核心技术是全文检索[1]。全文检索可以按照一定的策略对电子信息进行组织和处理,并能通过特定的方法实现信息的快速、准确检索。现阶段,实现全文检索的工具很多,其中Lucene是当今最为流行的开源全文检索工具包之一[1-2]。
1 关键技术研究
1.1 全文检索介绍
全文检索是一种实现电子资料中的信息与检索项快速匹配的检索方法[3],它以各种计算机数据(包括文本、图像、音视频等)作为处理对象,通过扫描其内容,为每一个词建立索引;在用户查询时,检索程序则根据已建立的索引进行查找和匹配,并将查找结果反馈给用户[4-5],从而实现电子资料的快速查找。
全文检索一般包括信息获取和存储、信息索引创建、信息检索和用户搜索界面4个部分:
1)信息获取和存储。全文检索的信息获取方式一般有2种:一是通过网络爬虫方式获取互联网中其他网站中的信息,类似于百度、google等全文检索引擎;二是在信息产生过程中直接获取信息,如企业级网站全文检索的信息获取。获取后的信息一般存放到系统的存储设备中,为了检索和查阅的方便,信息的存储一般按照固定的格式,例如标题、内容、作者和发布日期等。
2)信息索引创建。索引创建是指在信息获取后,通过扫描信息中的每一个词,建立一个能精确定位到每个词的索引,然后将该索引添加到索引文件中,从而完成索引的创建。
3)信息检索。信息检索一般由用户发起请求,检索程序根据用户提交的关键字对索引文件进行检索,并通过一系列的计算、合并和筛选等操作获得查询结果,最后将查询结果返回给用户,完成检索过程。
4)用户搜索界面。用户搜索界面主要实现用户检索词的输入、查询结果显示等功能。
1.2 Lucene介绍
Lucene是一个完全开放源代码的全文检索工具包[6]。它最初由Doug Cutting开发并于2010年捐献给Apache软件基金会,Lucene目前是Jakara项目组的一个子项目。Lucene最初是用Java开发的,随着项目的发展和应用的不断推广,Lucene逐渐被翻译成了C、C++、C#、Perl等多种语言。
Lucene不是一个完整的全文检索引擎,而是一个提供了完整的索引引擎和查询引擎的架构。它为数据的访问和管理提供了简单的函数调用接口,可以方便地嵌入到各种应用中实现针对应用的全文索引/检索功能。目前Lucene已被许多项目作为开发引擎,如 Eclipise、Jive、Conoon和 Eyebrows等[7]。
Java版Lucene的体系结构由基础结构封装、索引核心和对外接口3部分组成,分为7个JAR包[8],如图1 所示。

图1 Lucene体系结构
索引核心部分包含org.apache.lucene.index和org.apache.lucene.store 2个JAR包:index包提供了索引的创建接口,实现了索引记录的增加、更新、删除及读取记录等功能;store包提供了底层I/O的存储结构,负责索引的读写等数据存储管理。
基础结构封装部分包含org.apache.lucene.document和 org.apache.lucene.utit 2个 JAR包:document包提供了索引文档需要的类,包括Document和Field等;util包含了一些公共的数据结构。
对外接口部分包括org.apache.lucene.search、org.apache.lucene.queryPaser和 org.apache。
lucene.analysis含3个JAR包:search包是lucene的检索接口,它提供了在索引文件上进行查询所需要的类。常用的包括IndexSearcher和Hits 2个类,其中IndexSearcher类定义了在指定的索引上进行搜索的方法;Hits类则用来保存搜索得到的结果。queryPaser包是查询分析器接口,负责语法分析,实现关键词间的与、或、非等运算操作;analysis包是语言分析器,主要用于切分词。lucene提供了针对不同语言的分词,开发人员也可以在此基础上进行不同语言分词器的开发。
作为一个开源的全文搜索引擎,Lucene有以下特点:
1)Lucene是完全开放源代码的搜索引擎工具,开发者不仅可以充分利用其现有的功能,还可以在此基础上根据实际需要进行针对性的开发,满足不同程度用户的需求。Lucene面向对象的系统架构也使得其具有良好的可扩展性,易于进行新模块的开发。
2)Lucene采用独立于应用平台的索引文件,使不同平台的项目能够共享索引文件。它还设计了独立于语言和文件格式的文本分析接口,能够方便地实现不同语言和文件格式的扩展。
3)Lucene采用了分块索引模式,在进行索引更新时,可以通过建立小的索引文件提升索引速率,然后再通过与原有文件的合并达到效率优化的目的。
2 系统架构与功能分析
2.1 系统软件架构
本文采用J2EE架构进行文献资料全文检索系统的开发。系统采用Struts,Hibernate和Spring框架的5层软件开发架构[9]。系统整体框架包括WEB浏览器上的用户层、J2EE服务器上的WEB层、业务逻辑层、数据持久层以及数据库服务器上的数据层,系统架构如图2所示。

图2 系统开发架构
各层的功能如下:用户层主要是指用户浏览器上的HTML页面,用户通过其向WEB层发起应用请求,实现用户的需求;WEB层主要采用JSP和Struts对用户的请求进行呼应;业务逻辑层采用Spring框架,它是一种控制反转和面向容器轻量级的容器框架;数据持久层采用Hibernate框架,实现了对象、关系之间的映射和数据的持久化;数据层采用Mysql数据库和索引文件库,实现对文献数据及文献索引的增、删、改、查等操作。
2.2 系统功能分析
文献资料全文检索系统主要实现了文献资料的收集和全文检索两大主要功能。其中,文献资料收集部分主要实现文献资料提交、存储和审核管理等功能;而全文检索部分实现文献资料的索引和数据检索等功能。
本文将完整的文献资料设计为属性信息和对象文件两部分:文献的属性信息包括文献标题、作者、出版或收录单位、文献摘要、关键字等信息;而文献的内容则存储在对象文件,对象文件由txt、html、word、pdf、ppt、excel等多种格式。本文对文献资料的收集、索引和检索操作也基于这两部分开展。
根据系统的功能分析,本系统的设计思路分为4个步骤,其流程如图3所示。首先,由用户通过文献资料提交系统提交文献资料,文献资料提交成功后将存放到存储系统中;第二,由管理员审核用户提交的文献资料;第三,系统对通过审核的文献资料进行转换、清洗和全文索引创建;第四,用户通过检索页面提交检索请求,由Lucene检索引擎进行检索操作并向用户返回检索结果。

图3 文献资料全文检索流程
根据系统分析和设计思路,本文将校内文献全文检系统划分为5个模块,包括文献资料管理模块、数据存储模块、数据解析与转换模块、文献索引模块、文献检索模块。各模块的功能如下:
文献资料管理模块:实现用户文献资料的提交、编辑以及管理员对文献资料的审核、编辑和管理等操作。
文献资料存储模块:存储用户提交的文献资料属性信息和对象文件,并建立属性信息和对象文件的1-1对应关系。
数据解析与转换模块:从关系数据库中读取文献资料的属性信息并从对象文件抽取文件内容,通过转换和清洗操作将文献资料的属性信息和对象文件内容转变为可被Lucence索引的数据格式。
文献索引模块:利用Lucence搜索引擎对文献资料进行全文索引,实现索引的建立、更新和删除等操作。
文献检索模块:通过检索页面对被索引的文献资料进行全文检索,包括对各个字段关键词的逻辑操作后的综合检索等。
其中文献资料存储、数据解析与转换、文献索引和检索4个模块是系统的核心技术部分,本文的实现部分也针对这4个模块开展。
3 系统实现
3.1 文献资料存储
根据校内文献资料的特点,本文文献资料的存储将采用数据库和文件系统2种方式。文献资料的对象文件存放到文件系统,对象文件提交成功后,系统按照上传日期和随机数重命名对象文件,确保对象文件名称的唯一性;文献资料的属性信息和对象文件的路径及名称则存放到Mysql数据表中并与对象文件形成1-1对应关系。数据库中文献资料的表结构如表1所示。

表1 文献资料表结构
3.2 数据解析与转换
由于 Lucene只支持对 Document对象的索引[10],因此文献资料的信息需要转换成Document支持的数据格式。根据Document的格式特点,数据库中的属性信息一般可以直接进行索引,而存放到文件系统中的对象文件则需要通过读取、清洗等操作转化为文本格式。本文中对象文件有txt、html、word、pdf、ppt、excel等多种不同格式。为了读取对象,本文设计了不同对象文件的读取方式,并基于不同的Java包实现了对象文件的读取,其过程如图4所示。
实现对象文件内容抽取与解析的核心代码如下:


本文利用apache的poi包读取word内容的核心代码,实现word文件读取的核心代码如下:


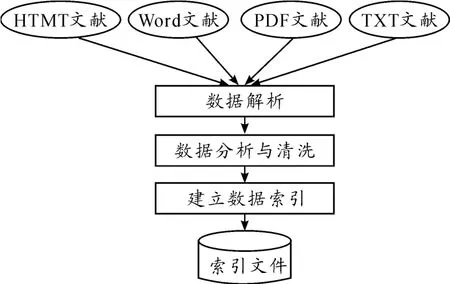
图4 对象文件解析与转换
3.3 文献资料索引
文献资料信息被解析和转换后就可以进行索引操作了。文献索引就是利用Lucene全文索引技术将解析和转换后的文献资料生成一条条的索引记录并将其添加到索引文件的过程。文献索引实现了全文索引记录、文献属性信息和对象文件三者间的关联。
Lucene搜索引擎的全文索引主要由写索引器(IndexWriter)、文档(Document)和域(Field)3个类来实现[11-121。在Lucence中,索引建立分为4个步骤:第一步,首先要创建索引文件目录(Directory),它负责存储索引记录,索引文件的存储有内存、文件系统和数据库3种方式,本文的索引文件的存储采用文件系统方式;第二步,创建 IndexWriter索引器,它接受新的Document文档,并将其写入索引文件中;第三步,建立Document文档,并为其添加Field对象,每个Document文档对应着一个文献资料对象,Documet通过Filed对象存储了文献资料的各类信息(包括文档id、标题、作者、内容等);第四步,利用IndexWriter索引器对Document进行索引,并将其写入索引文件,完成索引。文献资料的索引过程如图5所示:
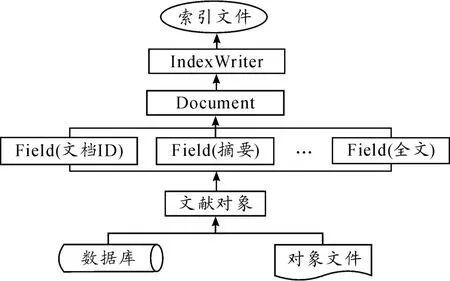
图5 文献资料索引过程
实现资料全文索引的核心代码如下:


3.4 文献检索
文献检索是指利用Lucene的全文检索引擎实现文献资料的查询功能[13-14],它根据用户输入的查询语句将符合条件的索引信息从索引文件中提取出来,并将结果返回给用户。文献检索一共包含以下几个过程:首先,用户通过查询页面输入查询语句;其次,利用Query对象封装查询语句并利用Analyzer对象分析查询语句;第三,打开索引文件,通过SearcherManage获得IndexSearcher对象;第四,利用IndexSearcher对象进行查询,并将查询结果返回到Hits结果集中;第五,将查询结果展现在查询页面中。
利用Lucence实现文献材料全文检索的核心代码如下:


除了基本查询之外,本文还利用BooleanQuery实现了对文献作者、关键词、出版单位等多条件的布尔查询,并基于RangeQuery实现了出版时间的范围查询。
4 系统测试分析
系统开发完成后,本文分别利用Lucene和关系数据库Sql Server 2005对10万条文本数据进行了检索测试。系统试验环境中CPU为Intel Xeon 1.86 GHz,内存为三星4GB DDR3 ×2,操作系统为redhat 6.2 linux。测试选取100 000条文献资料,在1 000、10 000、100 000数据规模下对Lucene和数据库检索分别进行了20次测试,取其平均值作为测试结果,结果如表2所示。

表2 Lucene与Sql Server性能对比
测试结果表明:基于Lucene的文献资料全文检索系统具有较好的时间和资源优势,并且随着文献记录数的增多,其优势更加明显。
5 结束语
本文在研究文献全文检索技术和Lucene系统架构的基础上,设计了基于Lucene技术的文献资料知识库检索系统,并进行了实际应用。研究结果表明:Lucene开放的体系架构使得其能够方便地应用到文献知识库系统中;Lucene基于字典和倒排技术的索引和检索技术使得系统能够实现文献资料的快速、准确检索。相比于传统的数据库检索方式,Lucene在性能和效率上具有明显的检索优势。
[1]钱爱兵.全文检索算法设计及全文检索系统概述[J].现代图书情报技术,2003(2):42-44.
[2]管建和,甘剑峰.基于Lucene全文检索引擎的应用研究与实现[J].计算机工程与设计,2007(2):489-491.
[3]曹元大,贺海军,涂哲明,等.全文检索字索引技术的研究与实现[J].计算机工程,2002(6):260-262.
[4]孙西全,马瑞芳,李燕灵.基于Lucene的信息检索的研究与应用[J].情报理论与实践,2006(1):125-128.
[5]肖创柏,李玉鉴,郑广顺,等.基于全文检索技术的商业信函处理系统的设计与实现[J].计算机应用研究,2004(1):150-152.
[6]苏潭英,郭宪勇,金鑫.一种基于Lucene的中文全文检索系统[J].计算机工程,2007(23):94-96.
[7]唐铁兵,陈林,祝伟华.基于Lucene的全文检索构件的研究与实现[J].计算机应用与软件,2010(2):197-199.
[8]高磊.基于LUCENE的搜索引擎研究与实现[D].武汉:武汉理工大学,2007.
[9]王海涛,贾宗璞.基于Struts和Hibernate的Web应用开发[J].计算机工程,2011(9):112-114.
[10]郎小伟,王申康.基于Lucene的全文检索系统研究与开发[J].计算机工程,2006(4):94-96.
[11]赵珂,逯鹏,李永强.基于Lucene的搜索引擎设计与实现[J].计算机工程,2011(16):39-41.
[12]夏天,黄文,马骏涛,等.Lucene全文检索软件及其在学科信息服务平台中的应用[J].图书情报工作,2011(21):106-109.
[13]黄杰.基于Lucene的全文检索系统模型的研究[D].广州:暨南大学,2007.
[14]李晓丽,杜振龙.基于Lucence的个性化搜索引擎研究[J].计算机工程,2010(19):258-260.
