高校图书馆图书推荐系统中的稀疏性问题实证探析
2014-12-06张闪闪黄鹏
□张闪闪 黄鹏
1 引言
在信息爆炸的时代,移动设备已成为人们获取信息的重要工具。据移动互联网第三方数据研究机构Gartner发布的《2014年全球设备总销量预测》,截止2013年12月,中国智能手机用户数突破10亿人[1]。智能移动设备日渐普及的同时,我国对电信基础设施的投入不断加大,3G网络已经普及,以中国移动领衔的4G网络也开始试运行,移动网络带宽不断加大,之前必须通过有线网络才能实现的服务如今在移动网络中就可以完成,移动信息服务成为可能。
面对图书馆用户阅读行为的转变,即便图书馆拥有再丰富、再优质的资源,若不思索新的服务模式,也将难以更好地为用户服务。在这样的条件下,图书馆如何将正确的信息推送给正确的用户是未来图书馆的一项重要课题,而个性化信息服务则可能是这道命题的答案。个性化信息服务是根据用户使用偏好、个人特征以及其提出的明确要求等,满足用户对个体信息需求的一种服务方式。
2 图书馆个性化推荐系统的需求
图书馆虽然有良好的学习条件、丰富的印本资源,但是却没有为用户提供与图书相关的信息和建议。用户在不知道该选择何种图书满足自我的信息需求时,可能会根据自己所需要的类别在书架前寻找,也可能会在书目系统中搜索某一主题下的图书并根据书名和作者进行选择,这样既浪费宝贵的时间,而且搜集到的图书也可能并非是用户所需要的。目前,虽然图书馆的网站上有各种图书推荐服务(如“新书推荐”、“一周借阅排行榜”、“季度借阅排行榜”等),试图达到帮助用户寻找合适图书的目的,但是在Web2.0环境下,用户的需求越来越个性化和多样化,而传统的图书馆推荐系统是“把一类图书推荐给所有用户”,往往不能达到令用户满意的效果.用户希望的是图书馆系统能够提供“量身定做”的推荐,而不是“一揽子”推荐,这就要求图书馆的推荐系统更具有针对性、主动性、甚至是智能化。据不完全统计,亚马逊网站上有35%的销售额是得益于个性化推荐,有60%的销售额间接受到推荐的影响[2]。学者玛丽亚·索莱达·佩拉和尼科尔·康蒂等利用社交媒体数据构建了基于社会互动和个人兴趣的个性化图书推荐系统(Personalized Book Recommendations System),通过分析相似用户从而有针对性地为用户推荐图书,实验证明该系统的精确度超过了亚马逊[3]。由此可见,个性化推荐可以作为一种重要的方式应用到图书馆信息服务过程中,但是,目前它主要是在电子商务领域取得了巨大进展,在图书馆领域应用的还比较少。笔者试图针对图书馆现有个性化推荐中存在的问题,提出一种具有图书馆特色的推荐方式,以期缓解目前推荐过程中的一些窘境。
3 图书馆个性化推荐服务中存在的问题
高校图书馆作为信息资源的集散地,在不断满足科研学者的信息需求的同时,也存在着信息量庞大和用户特定需求难以匹配的矛盾。用户如果想要搜索某一专题或领域的图书,往往需要耗费大量的时间和精力。而现有的图书馆管理系统中已有一些可提供个性化信息服务,用户可选择自己关注的领域,一旦该领域有新到图书,便会收到通知。比如美国康纳尔大学的“我的图书馆”系统,包括个性化链接、个性化更新、个性化内容、个性化目录和文献传递服务,用户可以定制图书馆资源及其他网络资源,也可以接受最新资源通告、进行目录查询等,这都为用户使用信息带来了很大便利。
虽然图书馆的个性化推荐系统在图书馆已经得到应用且为用户带来了一定的便利,也在一定程度上提升了图书馆的服务质量,但是仍然存在一些问题:比如有一些系统是以充分挖掘用户特征或信息资源特征为基础的,在使用之前都需要用户填写个人兴趣爱好方面的信息[4][5],不能根据用户的特征主动地、动态地提供个性化推荐服务。而目前常用的个性化推荐系统多采用协同过滤技术,虽然无需获取用户的个人信息,但是可能会产生自动化和稀疏性问题。
3.1 自动化问题
百度文库、豆瓣等都会在其页面上设置一个用户评分区域,一般包括“力荐、推荐、还行、较差、很差”等几个不同级别。用户必须积极主动地进行评价,推荐系统才能了解用户的特征,从而进行相似性推荐。然而用户往往属于利益驱动者,所采取的行动一般都是和自己的利益挂钩,如百度文库,作者为文章评分便可获得一定财富值,而财富值可以使其在该网站上下载更多的资料。但是图书馆属于非盈利性机构,缺乏相应的利益驱动机制,在这种情况下,读者评价图书往往会缺少动力,这就造成评价信息过少,不利于图书馆收集用户的信息[6]。如果能够提高系统评价的自动化程度,那么可以在一定程度上解决用户评价不足的问题。
3.2 稀疏性问题
在电商平台中我们常常见到商家利用评价返现、评价返积分的方式鼓励用户对所购买的产品或服务进行评价,据调查,在缺乏物质奖励的情况下,电商销售出的产品/服务所收到的评价还不足整体销售总量的1%。用户评价的主动性不高是造成数据稀疏性的一个重要原因。除此之外,畅销书的借阅用户往往较多,而非畅销书的借阅相对较少,借阅数据存在大量的交错,这两个问题导致协同过滤系统寻找到的相似用户不太可靠,计算出的待推荐项目评分也不太准确。大多数系统在处理数据稀疏性问题时,都以0或用户平均分填充的方法来评价缺乏评分的项目,但这些做法在用户兴趣偏好描述方面有所失真。另外,若以图书馆的图书评分矩阵作为寻找相似用户的依据,运算复杂度将会很大。
4 解决高校图书馆稀疏性问题的设计思路
目前,已经有很多学者针对上述问题提出了不同的解决对策,包括降维的方法[7]、项目聚类方法[8]等。如学者邹永贵[9]利用项目及项目类别包含的评分次数来计算不同项目之间的兴趣度,并结合传统的相似度算法有效地减少了评分数据稀疏的负面影响。学者王桂芬[10]提出一种基于项目层次偏好的协同过滤推荐,减轻了数据稀疏性问题。欧文·金等人[11]通过结合用户和项目两方面的共同信息来对缺失评分进行预测,一定程度上解决了稀疏性问题。托恩·奎尔·李(Tong Queue Lee)[12]认为在预测时可以对那些没有打分的产品赋予一些缺省的分值,这样就会使得预测分数的准确性大幅度提升。如黄昝等[13]通过协同检索框架及扩散算法来分析用户之间的关联性,解决打分稀疏性问题,实验结果表明所提出的方法在推荐准确度、召回率、综合评价指标和得分排名等方面都明显优于传统的协同过滤方法;托恩·奎尔·李等[14]借助伪打分信息,安等[15]借助启发式算法来分析用户之间的相似性,他们指出,系统中的打分项目往往比较多,而如何根据现有已打分项目对未打分的项目做出预测,则变得非常重要。
缺乏用户的主动评价是造成图书推荐计算障碍的重要问题之一,而用户评分的主动性不高及借阅行为的交错性是导致数据稀疏性的两大主要因素。要解决稀疏性问题,首先需要解决自动化评分问题;此外,正如科恩所提出的,我们还需要解决用户主动评价所造成的打分不一的问题。而对于用户借阅行为的交错性所产生的稀疏性问题,可以通过一定的方法对未评分项目进行分值填充。本文结合图书馆的特点,提出通过用户的借阅记录形成自动化的评分标准,同时借助中图法类目形成新的书目数据库,把通过每本书寻找相似用户转换为通过“某一类”图书寻找相似用户,从而简化计算流程,降低计算维度。以下就这些思路给予一一说明。
4.1 建立自动化评分体系
人工评分系统是个性化推荐系统的羁绊。根据齐普夫省力法则,人们总是会采取比较省力的方式来指导自己的行为,除非对某本书非常热爱,用户大都不会对借阅的图书进行评价。因此,我们可以看到,大多数电商网站例如京东、易迅及当当等都是通过给用户返利的方式鼓励用户评价,而公益性的图书馆没有这笔经费预算,采用付费模式鼓励用户评价是不现实的,必须针对图书馆自身的特点,设计一种能够适合图书馆的自动化评分体系。综合以上因素,图书馆可以利用用户借阅记录的特点设计一种标准化的评分体系,根据借还书记录自动实现用户对所借阅图书的评分。
××大学的借阅日志主要包含借阅、续借、预约三项操作,以下根据这三项操作设定评分系统。通过查阅大量文献以及进行专家访谈,最终根据文献的对比分析并结合专家意见,得出三种不同操作的分值如下:
借阅:用户只有对某本书感兴趣或者因为客观原因对其有需求,才会去借阅该书,可以分为首次借阅与非首次借阅。首次借阅虽然表明用户对该书感兴趣,但因为用户并没有详细阅览图书的内容,因此该书对用户的作用可大可小。综上所述,用户初次借阅某本书的评分不能太高,可以将首次借阅的分值设为1。而非首次借阅,我们认为该书对用户的用途较大,所以才会被多次借阅,同时为拉大分差强调再次借阅的重要性,因此可将分值设定为4。
预约:××大学图书馆对已经借出的图书提供预约服务,用户可以通过申请该服务,对借出图书归还后享有优先借阅权。同样根据省力法则分析,若非用户有非常大的意愿去阅读该本书,是不会通过账号登陆系统去预约的,所以用户申请预约服务,我们可以认为用户已经了解该书的详细内容并认为该书有用,分值可以比初次借阅该图书高,但我们还要考虑到用户也可能并没有深入阅读该书,可能会存在阅读后感觉与自己之前的想法有所差距的情况,因此,分值不应该比再次借阅高。综上,我们将预约行为的分值设定为2。
续借:关于续借情况的分析也应该分为两种。一般来说,我们认为用户在觉得该书有用同时又没有读完的情况下才会续借。另外,图书馆的借阅规则中有惩罚条款,图书借阅超期会产生罚金,若用户借阅的书到期,但凑巧这几天没有时间去还书,又不想被罚款,这时就会产生续借行为。综合这两种情况,续借的分值应该高于初次借阅,但是要低于非初次借阅,因此将分值设定为2。

表1 图书评分表
表1是某本图书的评分表,每一行的2,3,4,5列是对某位同学借阅行为的统计,第6列是系统依据上述评分体系针对该同学的借阅行为所计算出来的图书得分。例如:A同学对该本图书的评分为1×1+2×4+0×2+2×2=13;B同学对该本图书的评分为1×1+1×4+1×2+1×2=9;C同学对该本图书的评分1×1+0×4+1×2+1×2=5;D同学对该本图书的评分0×1+0×4+1×2+0×2=2。
4.2 借鉴中图法目录降低运算维度
对于借阅行为的交错性问题,我们还应考虑图书馆自身特点:图书馆开架借阅的图书都是专业人员编目过的图书,其分类较为准确。我们可以借助书目数据对其进行合并处理,将通过对某本图书的兴趣度寻找相似用户的问题转化为通过对某一类图书的兴趣度寻找相似用户的问题。即先根据借阅记录计算用户所借各书的分值,然后根据书目信息中该书所属的类目,计算各“类”的分值,然后通过各“类”的分值寻找相似用户。
下面以××大学图书馆文学库图书为例具体说明处理过程:
a)调研分析××大学依据中图法编制的类目,对已有类目进行重新归并。图1以图书最多的中国文学I2为例进行类目的重新划分,比如“中国文学”类目下包含9类,根据收集文献数量及相近性,将戏剧文学与诗歌、韵文合并为一类,以此类推将原来的九类重新整合为六类。另外,I3中由于日本文学的馆藏数量占多数,因此将其重新划分为日本文学与亚洲其余各国文学;同理,将I7美洲各国文学重新划分为美国文学与美洲其余各国文学。在重新划分后,把原来的下级类目提前,替换原有上级类目,将文学库重新划分为18个类目(表2);
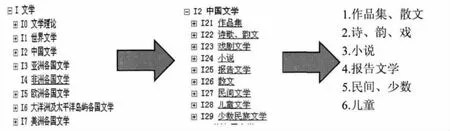
图1 ××大学图书馆文学库分类举例

表2 文学库重新构建的分类体系
b)根据用户的借阅行为,计算用户对图书的评分;
c)将图书依照条目信息归类到新的类目体系中,并将计算出来的各种图书的分值导入公式1中,得到各类目的分值。公式中P代表某用户对某类图书的打分,n为该类目下用户借阅了n本书,Ri表示用户借阅该类图书中第i本图书的得分。
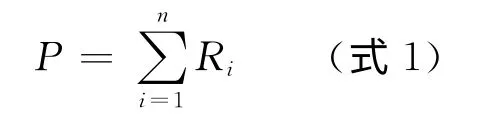
d)将计算出的每一类的分值当做一“本”书的分值带入公式2中,计算用户的相似性,将与每位用户最为相似的前10位用户挑选出来。R(u,i)及R(v,i)分别代表用户u及用户v对i类图书的评分及分别表示用户u及用户v对文学库18类图书评分的平均值,sim(u,v)表示两位用户的相似性。
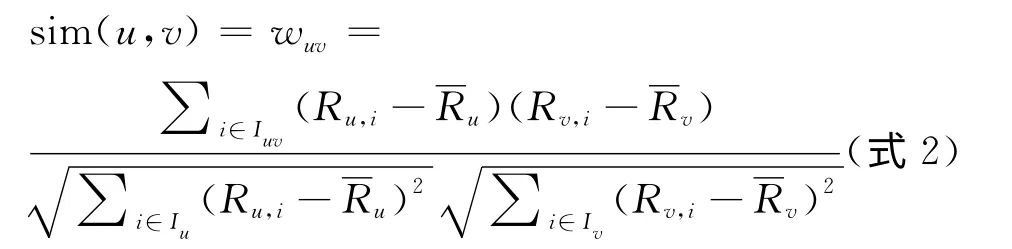
e)根据d)中计算出的相似用户集合U及其所属的用户评分集合(每本书),对未评分的图书进行预测,将预测分值排名前十的图书列出,若出现得分相同的情况,则根据借阅记录将相同得分的图书按照借阅次数进行排列,如若仍出现相同的情况则全部进行推荐。P(u,k)表示预测用户u对图书k的评分,及代表用户u和v对所有已评图书的平均分,R(v,k)表示用户v对图书k的评分。

采用这种归类转化模式能够有效降低借阅交叉造成的数据稀疏问题,将通过图书组合寻找相似用户的问题转化为通过“类”的组合寻找相似用户的问题。寻找相似用户的本质其实就是寻找对某一图书组合都感兴趣的用户,而实际上我们可以将这一类图书组合看成一类图书,相似用户是对某一类图书感兴趣而找到共同点的。在电商领域中,由于物品项目没有经过专业分类或聚类,需要以物品项目为单位采用传统的协同过滤模式,而高校图书馆的馆藏是经过专业编目的图书,直接采用“类”寻找相似用户在理论上是合理的,而在后续的实验中也证明了该种做法是可行的,采用“类”寻找相似用户所推荐图书的准确率比直接采用单位图书寻找相似用户进行推荐的准确率有明显提升。同时还需注意在该步骤中对于每本图书的预测采用的是相似用户对于具体图书的评分集合,而非相似用户对于“某一类”图书的评分集合。
5 个性化推荐数据实验
5.1 研究假设
为了能够更快更准确地给用户推荐符合其需求的图书,本研究假设系统只能为目标用户推荐其所在书库的图书,即用户到达文学库时,系统会测算出用户目前处于文学库,并只为用户推荐文学库中的图书。实验将重点考察在推荐同一书库中的图书时,传统的协同过滤与结合中图法编目数据的协同过滤的推荐效果。
5.2 推荐数据来源及实验设计
为了验证以上所提出的设计思路的可用性,本文选取XX大学图书馆后台借阅数据进行数据试验,将数据的范围尺度定位为文学库的借阅记录,样本设定为以文学院为主的300名研究生的借阅记录,数据的时间跨度从2011年9月至2013年12月,共37509条记录,涉及7127本书。系统的操作流程如下:
(1)将得到的数据进行预处理,使之符合运算模式;
(2)通过设计的推荐体系进行数据处理;
(3)将数据集分别代入传统协同过滤模式和加入编目体系的推荐模式进行对照实验;
(4)根据计算得出评分集合A与B;
(5)将两种方式得到的推荐集合进行合并处理,并编制用户推荐书目,通过校园邮箱向用户进行推荐调研;
(6)根据用户反馈的信息,结合推荐集合处理反馈结果;
(7)比较推荐集合的准确性,并作出分析。
5.3 数据实验
(1)数据预处理。
系统的后台日志仅是对借阅行为进行记录,每一条目包括题名、索书号、学号、操作日期,其中部分后台日志如表3所示。
从表3可以看出,数据是以时间序列进行排布的,而本文主要是通过借阅信息来分析相似用户,并对其进行个性化推荐,因此需要将数据进行预处理,形成以用户为单位的数据集合,包括用户的初次借阅、续借、非初次借阅及预约行为的统计处理,形成如表4的数据。以图书《诗性正义》为例,通过查询原始后台日志,发现学号尾号为220的用户于2012年11月13日首次借阅该图书,于2013年4月2日和2013年5月2日分别进行了两次续借,并在2013年3月7日、5月22日和12月21日对该图书又进行了三次借阅。
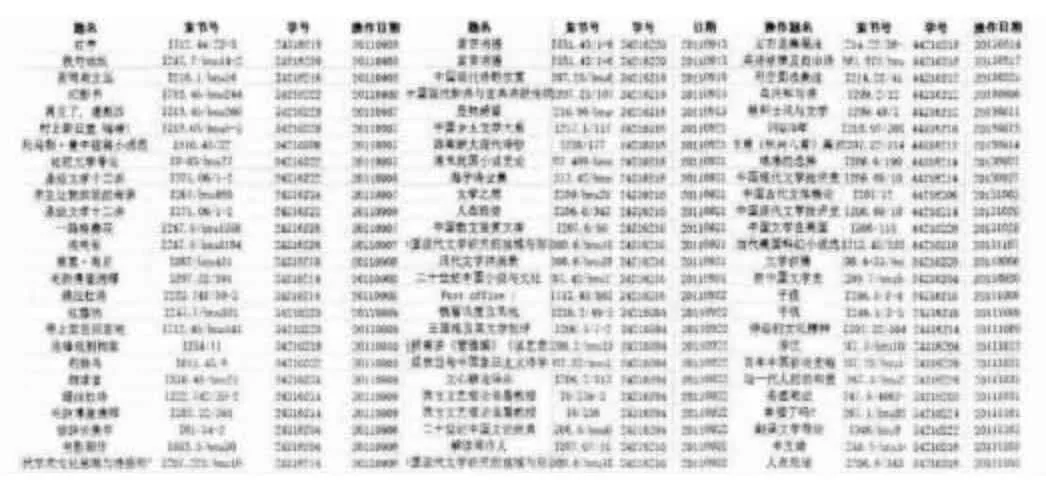
表3 ××大学图书馆文学库借阅日志

表4 学号尾号为220学生的借阅记录
(2)使用matlab进行推荐实验。
根据处理步骤编写matlab代码(如图2),将预处理数据矩阵代入进行运算,得到向用户推荐的图书集合A。同时,为了进行对照,不进行图书的归类处理,以每本书为单位采用传统协同过滤的模式对数据集合进行处理,矩阵中的缺失值采用常用的处理方法以0填充,得到向用户推荐的图书集合B。

图2 协同过滤matlab代码片段
5.4 结果检验
(1)推荐邮件设计。

图3 发送给学号尾号为046学生的推荐邮件

图4 为学号尾号为046学生推荐的书目表片段
根据以上形成的推荐图书集合A、B,可以得到每一位用户的不同推荐书目。为方便用户填写反馈,将这两个集合中相同的书目记录进行去重合并,形成推荐书目表,将经过计算且合并后的图书以图书馆书目调研的名义发送至用户的校园邮箱中。当然,在进行图书推荐时,我们除了提供传统的书目信息外,还会将索书号、图书的基本信息以及本书的链接一并发送至用户的邮箱,用户打开链接后可直接查看到此书,同时网页中还会呈现出其他用户对该书的评价,以提供一定的参考。同时,考虑到数据的时滞性问题,需要用户反馈的是选择感兴趣或已看过的书。因此,调研的问题是:假设你来到文学库,以下文学类图书你是否感兴趣或是否看过,选出你感兴趣或看过的图书。推荐邮件如图3所示。
为了测试推荐邮件的设计是否清晰明确,本研究先选择5名同学进行小范围测试,针对每位同学分别推荐两种算法中排名前10的图书,如对于学号尾号为046的学生,去重后,我们一共为其推荐14本书,具体书目列表如图4所示。在其后的反馈邮件中,该同学选择了《文学的邀请》、《锁孔里的房间》、《徐志摩全集》、《莫言演讲新编》、《鲁迅杂文全编》和《张爱玲典藏全集》等书。
(2)推荐反馈处理。
使用上述方法,根据不同用户得到的推荐书目集合分别编辑推荐邮件,然后向300名学生发送,共收到217份回复,回收率为72.3%。我们将用户的反馈和两种推荐集合中的推荐书目进行对比,分别计算两种推荐方法的准确性,最后汇总计算各个集合的平均准确率(如表5所示):
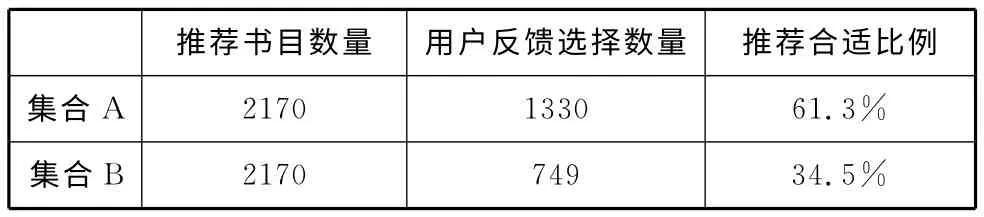
表5 两种推荐方法的实验结果对比
从表5所列出的两种不同实验结果我们可以看出,集合A中,有1330本是用户反馈回来感兴趣或者是已经看过的图书,推荐符合率为61.3%(1330/2170),集合B共有749本是用户反馈回来感兴趣或者是已经看过的图书,推荐符合率为34.5%(749/2170),该比例几乎仅为集合A的1/2,这在一定程度上证明了结合图书馆编目数据的过滤推荐优于传统的过滤推荐。
通过该实验可充分看出,相对于传统协同过滤推荐来说,本文基于图书馆编目数据的协同过滤方法从推荐合适比例来说更加有效。
6 总结
本文分析了传统协同过滤中存在的自动化和稀疏性问题,并提出了稀疏性问题的解决对策。通过借阅日志中的借阅、续借、预约三项操作设计了一个标准化的评分体系,根据借还书记录自动实现用户对所借阅图书的评分,有效地解决了其评分主动性不高的问题;借鉴图书馆特有的编目体系,对图书馆现有文学库中的图书进行了重新归类,将通过图书组合寻找相似用户的问题转化为通过“类”的组合寻找相似用户的问题。最后,以××大学图书馆文学库为例,对本文中所提出的结合中图法编目数据的协同过滤推荐算法进行了验证,结果表明该方法较传统的协同过滤具有更好的推荐效果。
1 Gartner.预计2014年全球设备总销量.[2014-06-28].http://www.199it.com/archives/205633.html
2 亚马逊公司(Amazon):世界上销售量最大的网上书店.[2014-07-13].http://wiki.mbalib.com/wiki/Amazon
3 Pera M S,Condie N,et al.Personalized Book Recommendations Created by Using Social Media Data.WEB INFORMATION SYSTEMS ENGINEERING-WISE 2010 WORKSHOPS,2011,6724:390-403
4 唐秋鸿,曹红兵.高校图书馆个性化专题推荐研究.图书馆学研究,2012,(13):53-59
5 李微娜,马小琪.基于MADM方法的个性化推荐研究.现代情报,2011,31(4):20-23
6 李炎.电子商务推荐算法的研究与实现,上海:复旦大学,2002
7 Leskovec J,Rajaraman A,Ullman J.Mining of Massive Data-sets,Cambridge University Press,2011
8 邓爱林,左子叶,朱扬勇.基于项目聚类的协同过滤推荐算法.小型微型计算机系统,2004,25(9):1665-1670
9 邹永贵,望靖,刘兆宏,等.基于项目之间相似性的兴趣点推荐方法.计算机应用研究,2012,29(1):116-118,126
10 Wang G F,Ren Y,Duan L Z,et,al.An Optimized Collaborative Filtering Approach with Item Hierarchy-Interestingness.in:International Conference on Business Computing and Global Information(BCGIN),2011:633-636
11 Ma H,King I,Michael R.Lyu.Effective Missing Data Prediction for Collaborative Filtering.in Proceedings of the 30th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval,New York:ACM,2007,39-46
12 Lee TQ,Park Y,Park YT.A Time-Based Approach to Effective Recommender Systems Using Implicit Feedback.Expert Systems with Applications,2008,34(4):3055-3062
13 Huang Z,Chen H,Zeng D.Applying Associative Retrieval Techniques to Alleviate the Sparsity Problem in Collaborative Filtering.IEEE Trans Information Systems,2004,22(1):116-142
14 同12
15 Ahn HJ.A New Similarity Measure for Collaborative Filtering to Alleviate the New User Cold-Starting Problem.Information Sciences,2008,178(1):37-51
