基于改进决策树的入侵检测算法
2014-12-03平寒
平寒
(山东职业学院信息工程系,山东济南250100)
假如有预谋的、潜在的、未经授权的操作信息和访问信息造成系统无法使用或者使系统不可靠,那么发觉这样的企图或行为被定义为入侵检测[1]。在入侵检测系统中使用数据挖掘技术已越来越普遍[2],而基于决策树的数据挖掘技术,其分类检测模型具有高效、分类准确率高和易于理解等优点,因而备受欢迎。但该技术也存在缺点[3],一是算法效率低;二是训练集的选取问题,如果超出内存容量将无法运行。
本文尝试使用基于多变量综合策略剪枝算法,使算法效率有所提高,同时提高训练集选取的有效性。
1 基于改进决策树的入侵检测算法的设计
1.1 信息增益ID3算法
ID3算法以信息论为基础,采用划分后的样本集的不确定性作为衡量划分优劣的标准,利用信息熵和信息增益度进行度量。信息增益度越大,不确定性越小。因此,信息增益ID3算法的设计首先要计算每个属性的信息增益,然后选取信息增益最大的属性作为测试属性。
信息增益度ID3算法[4-5]描述的公式如下:
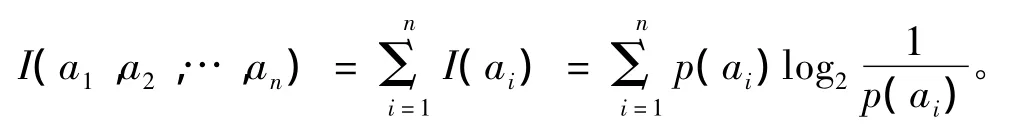
在决策树分类中,假设S是训练样本集合,|S|是训练样本数,样本划分为n个不同的类C1,C2,…,Cn,这些类的大小分别标记为|C1|,|C2|,…,|Cn|。则任意样本 S属于类 Ci的概率[1-2]为
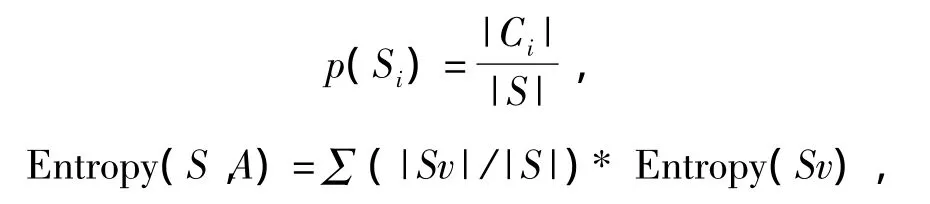
其中,∑是属性A的所有可能的值,Sv是属性A有v值的S子集;|Sv|是Sv中元素的个数;|S|是S中元素的个数[4-5]。
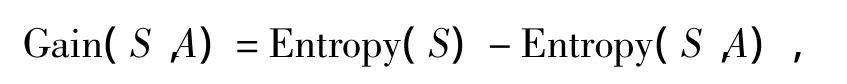
Gain(S,A)是属性A在集合S上的信息增益。若Gain(S,A)越大,则表明选择测试属性对分类提供的信息就会越多[4-5]。
1.2 独立性检验算法[6]
卡方独立性检验用于确定两个分类变量之间是否存在关系,而本文要研究的是两种算法结果的关系比较,因此本文在独立性检验之中选择卡方检验。卡方检验计算公式[6]为
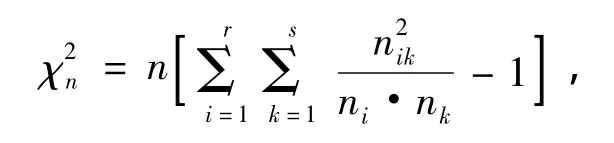
其中,nik代表第i个属性的第k个属性值;ni,nk为这一行或列中属性取值的和,表示的是该属性与决策属性的相关性。
1.3 独立性检验与信息熵相结合的分类算法
具体的算法[7]如下:
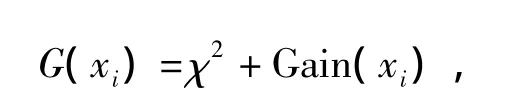
其中,G(xi)为分类选择属性,Gain(xi)表示信息增益的大小。
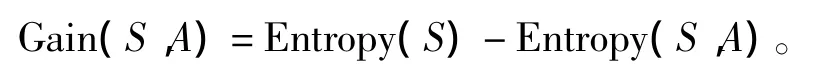
对所有属性都运用上式,最后选择分类选择属性G(xi)最大的那个属性进行分裂。改进的决策树算法伪代码如下:

刚刚生成的决策树由于分类过细,会出现过度拟合现象,使检测结果下降,而目前避免过度拟合的主要的方法是对决策树进行剪枝。
2 实验与性能分析
2.1 KDD CUP99数据集的介绍
本次实验的数据集采用的是KDD CUP99入侵检测数据集,该数据集为入侵检测系统提供统一的性能评价基准,可以仿真各种用户的类型、模拟各种不同的网络流量及攻击手段,使之就像一个真实存在的网络环境。
每一个网络连接被标记为Attack(异常)或Normal(正常),Attack(异常)类型被细划为四个大类,共39种攻击类型。其中17种Unknown(未知)攻击类型出现在KDD CUP99(测试数据)集中;22种攻击类型出现在训练数据集当中。
2.2 实验与分析
本算法在Windows 7操作系统实验平台、Microsoft Visual Stdio C++6.0环境下实现基于KDD CUP99数据集、采用信息增益与卡方检验方法结合的入侵检测。算法实现主要包括数据集读入用规格化、采用信息增益结合卡方检验方法训练生成决策树、采用后剪枝算法对生成的决策树进行剪枝、测试。
本实验对数据集的处理采用的是数据文件的形式。实验数据来自KDD CUP99数据集中的kddcup.data,其大小约为 743 MB,为了使用方便,我们使用 KDD CUP99自带的 10%的数据集 kddcup.data_10_percent,本文随机从中提取了6 080个数据。
本文所使用的测试集来自KDD CUP99中的数据集corrected,我们从中提取测试子集,共提取7 009条数据,其中1 009条为攻击数据。
2.3 训练过程
具体训练过程如下:
(1)生成一个决策树结点,分析当前工作数据表和属性列表,如果当前决策属性只有一个值,则该结点为叶结点,其分类为当前属性列表中决策属性的值。
(2)如果当前属性列表中只有决策属性,则该结点也是叶结点,其分类为当前工作数据表中占多数的决策属性值。
(3)否则,该结点为中间结点,对工作数据表计算每个属性的卡方值和信息增益值,然后选择卡方值与信息增益值之和最大的属性作为最佳分类属性,最后以最佳分类属性标记该结点。
(4)为最佳分类属性的每个值划分数据子集、生成一个新的决策树结点,并生成对应每个最佳属性值的子工作表和子属性列表,新生成的结点作为该结点的子结点。
(5)递归调用此过程,最终生成决策树。
具体训练结果如图1所示。
其中属性数42是由41个基本属性和1个决策属性所构成。
训练结果成功地计算出信息增益与卡方值的大小,并以此作为分类建树的标准,成功地建树分类,从结果看,完成了建树的目的,并为测试做了准备。
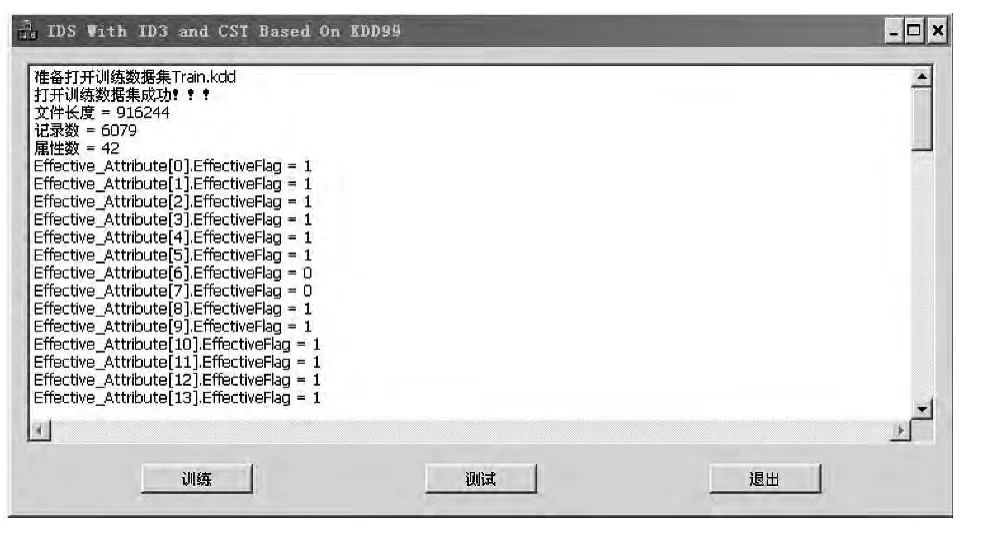
图1 训练过程Fig.1 The training process
2.4 测试过程
当数据训练结束之后,我们将测试数据集导入,具体测试过程如下:
程序在读入测试数据集后立刻对测试数据集进行预处理,首先经过对数据集各个数据的完整性检查清除无效记录,然后将决策树根结点的属性值与测试数据数组相应的属性值比较决定进入下一个分枝,判断该节点是否是叶节点,如果该结点是叶结点,则将该结点的分类值与该记录的分类值比较;再连续的进行此类比较,当全部记录比较完成后生成统计数据,包括检出率、误检率等数据。而后,对上述数据进行统计分析。将统计信息通过对话框显示出来。
测试集读入后属性输出结果如图2所示,检测结果输出如图3所示。
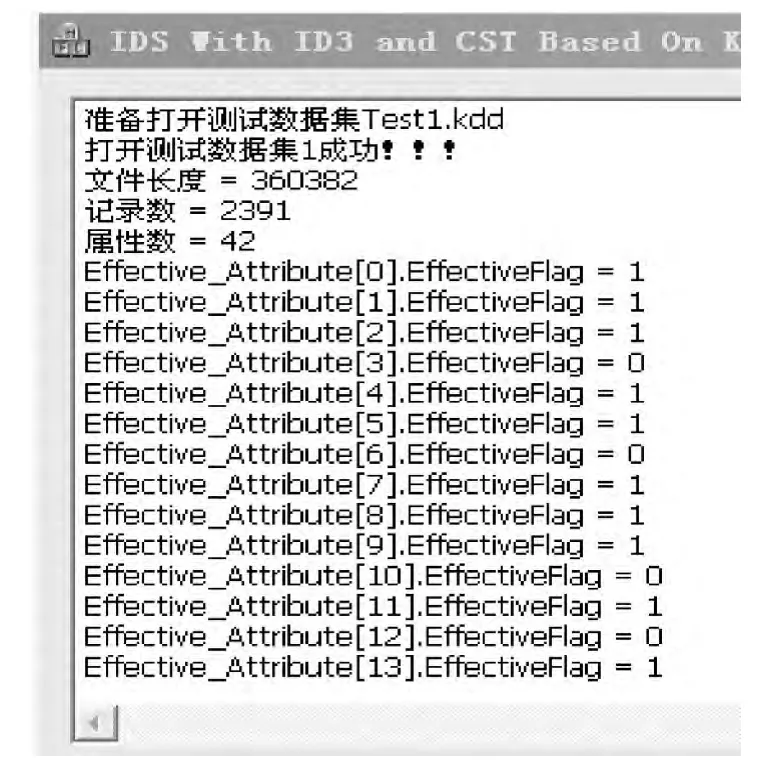
图2 测试集读入后属性输出结果Fig.2 Attribute output result after test set reading

图3 检测结果输出Fig.3 Detection results output
对数据集2和数据集3的操作同理。经过整理,数据集1,2,3的测试结果如表1所示。

表1 数据集1,2,3的测试结果Table 1 Test results of data set 1,2 and 3
为了对比,将只使用信息熵增益方法的决策树成树算法与本文算法相比较,得到结果如表2所示。
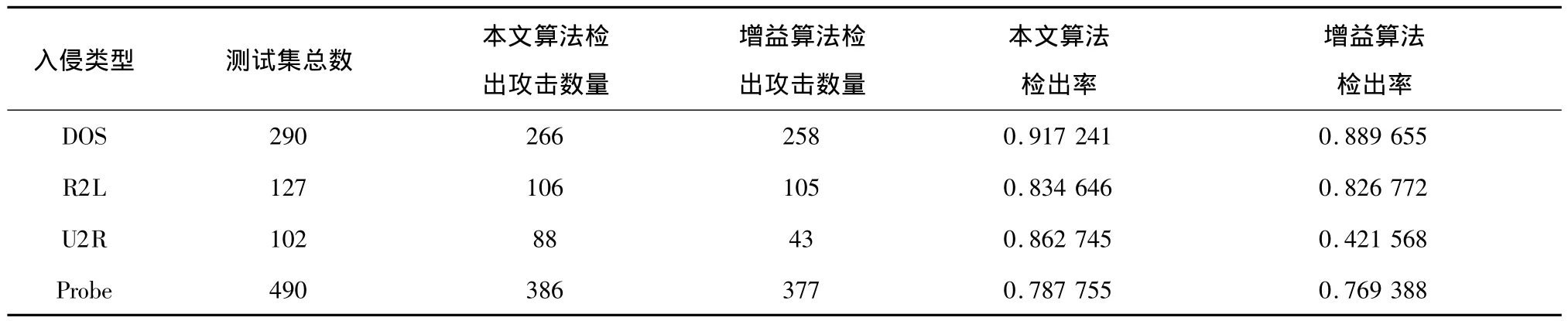
表2 传统算法与本文算法结果比较Table 2 Result comparison between traditional algorithm and the presented algorithm
由表1和表2可知,本文算法一共检出846次攻击,而只基于信息增益算法只检出783次攻击,特别是在本算法面对U2R攻击时,本算法的检出率比只基于信息增益的方法提高了1倍多,检测性能更是有了质的提高。
2.5 决策树的剪枝[8]
(1)用训练数据集和某一测试数据集对生成的决策树进行测试,取得测试统计数据,计算未剪枝决策树的预期分类错误率PT值;
(2)遍历决策树,一次剪掉找到的一个叶结点,如果剪掉叶结点后,结点t的子结点全部已剪掉,则t为叶结点,t的分类属性为其数据集中占多数的决策属性值,计算剪掉一个叶结点后的决策树预期分类错误率PC;
(3)如果 PT≥PC,则结束,生成剪枝后的决策树,否则PT=Max(PC),递归完成剪枝过程。
进行剪枝之后的测试集1的检测结果如图4所示。
与未剪枝前的决策树处理结果(图3)对比我们可以看到,由于存在着过度拟合现象,导致未剪枝的决策树的性能比已剪枝的决策树较差,特别是在误报率方面,采用本综合策略剪枝算法生成的决树与未剪枝决策树相比有了较大提升。而且对决策树的剪枝还可以大规模降低整棵树的复杂性,使所生成决策树的可用性和性能得到提高。

图4 进行剪枝之后的测试集1的检测结果Fig.4 Test results of test set 1 after pruning
2.6 面对未知攻击时的判断能力
在训练集不变的情况下,更改测试集,测试集中的攻击类型是之前决策树不曾遇见过的,为了贯彻这一思想,我们选取在训练集kddcup.data_10_percent数据集中从未出现的一些攻击类型组成测试集。对未知攻击的测试结果如图5所示。
图5所示的检出率实际上是攻击类型的误检率,因为这些数据的攻击类型从未在训练集中出现,所以我们希望得到的结果是Uknown,而不是上面任何一个具体分类结果,而真正检测错误的数据只有检测结果为Normal那些数据,由此我们可得到,本文所述算法对上述未知攻击数据集的检测率为0.919。
由实验结果可知,由于训练集所包含攻击类型的不完整,本文决策树在面对未知攻击时并不能准确地对各类攻击进行十分准确的分类,有一些数据在攻击类型的判断上出现了错误,但是可以看到,如果就检出未知攻击能力这一点来说,本算法继承了异常检测算法对未知攻击的高分辨能力,对未知攻击的检测率还是相对不错的。
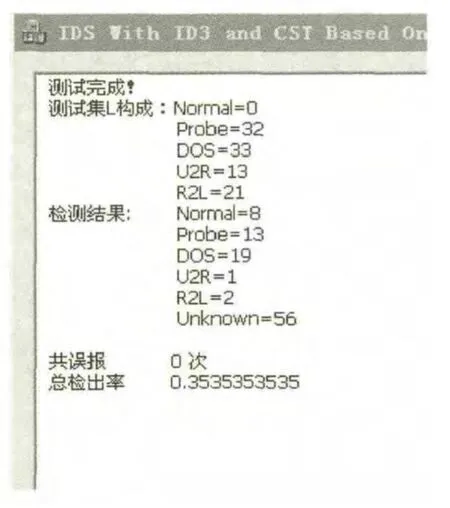
图5 对未知攻击的测试结果Fig.5 Test results of unknown attacks
3 结论
本算法对原有单纯基于信息熵增益算法进行了改进。实验证明,该算法可以对已知攻击进行判断,取得了较好的预期效果。本算法不但在检测率和误检率上与原算法相比有了较大提高,而且通过结合综合策略的剪枝算法避免了过度拟合对检测结果的影响,同时对现有的检测进行了优化,使检测结果得到提升。另外,本算法还可以对未知的攻击进行鉴别,解决了常规算法在异常检测中的误报率偏高的问题。从结果来看,本算法与原有算法相比在入侵检测的性能上得到了大幅度的提高,达到了实验目的,得到了预期的结果。
[1]JANES P,ANDERSON W.Computer security threat monitoring and surveillance[EB/OL].[2014 -02 -10].http://www.docin.com/p -567457508.html.
[2]LEE W,STOLFO S J,MOK K W.Mining audit data to build intrusion detection models[C]//Proc Conf Knowledge Discovery and Data Mining(KDD'98),1998:66 -72.
[3]LIU H,HUSSAIN F,TAN C L.Discretization:An enabling technique[J].Data Mining and Knowledge Discovery,2002,6(4):393-423.
[4]孙超利,张继福 . 基于属性-值对的信息增益优化算法[J].太原科技大学学报,2005,26(3):199-202.
[5]张春丽,张磊.一种基于修正信息增益的ID3算法[J].计算机工程与科学,2008,30(11):46-47.
[6]叶慈南,曹伟丽.应用数理统计[M].北京:机械工业出版社,2009.
[7]孔祥南,黎铭,姜远,等.一种针对弱标记的直推式多标记分类方法[J].计算机研究与发展,2010,47(8):1392-1399.
[8]钟慧玲,章梦,石永强,等.基于剪枝策略的改进TDCALT算法[J],同济大学学报:自然科学版,2012,40(8):1197-1203.
