基于网页去噪Hash的增量式网络爬虫研究*
2014-11-23
(海军工程大学信息安全系 武汉 430033)
1 引言
在互联网高速发展的今天,网站以前所未有的速度发生着变化,新网页不断地添加进来,旧网页内容不断地更新,这给搜索引擎中的网络爬虫带来了巨大的挑战。由于并没有机制能够将网站发生的变化主动地推送给搜索引擎,网络爬虫必须实现增量抓取,以保证搜索引擎提供信息的实效性,无论是百度、Google这样的广泛搜索引擎,还是现在的垂直搜索引擎,增量抓取都是网络爬虫最需要考虑的问题。增量式抓取的目的在于保持本地数据的新鲜度,只对新产生的网页或变化的网页进行抓取,对没有变化的网页不进行抓取,因此网页更新判断是首先要考虑的问题。可以依据http协议在http的请求中加入一个If-Modified-since属性请求网页对已下载过的网页进行更新[1],如果网页自上次采集后发生了变化则进行抓取,这种方法的缺点是对于动态网页没有任何作用,而且互联网上有许多的静态网页是由动态转化而来,这些表态网页几乎每天都有一些细微的变化。因此仅仅根据If-Modified-Since属性来判断网页是否变化是不准确的[2]。通常的做法是保存网页内容更新前的Hash值与更新后的Hash值,通过对比判断网页是否发生变化。
经典的Hash算法有MD5和SHA1[3],在实验过程中发现用Hash算法定义网页的变化过于严格,Hash值产生敏感度高,微小的网页变化,例如:网页中与主要内容无关的广告、图片、版权信息、分割条、导航链接、搜索服务和版权信息等,都会导致Hash值的很大变化,网络爬虫仍然会将大部分正文内容没有变化的网页抓取下来,达不到增量抓取的预期效果。
针对上述问题,本文将网页去噪与Hash算法结合起来,提出去噪后的Hash 产生方法,即在对网页Hash值产生前去掉网页中的微小变化内容,称之为噪声,然后对网页正文部分产生Hash值并保存到Hash表中,基于去噪后的Hash值来判断网页是否发生变化。在开源网络爬虫Heritrix进行实验后,结果表明,去噪后的网页Hash 值能较好的反应网页正文的变化情况。
2 相关研究
增量式网络爬虫一般用于更新本地数据。其基本思想:增量式爬虫不抓取没有变化的网页,只抓取新产生的网页或者己经发生变化的网页。增量式抓取的理想状况是抓取到的信息与网络中的信息完全一致,但这仅仅是理想状况,由于Web的异构性、动态性和复杂性使得抓取到的网页有可能在相当短的时间内就发生了变化,所以在现实中是不可能实现的,能做的就是抓取一切办法尽量逼近这种理想状况。增量式抓取能提高网页采集的效率,由于不抓取没有变化的网页,因此极大地减少了数据抓取量从而减少了抓取的时间和存储资源的浪费。其缺点是增量式抓取带来了算法复杂性和难度的增加。
目前在实现增量式抓取方面的研究有很多,文献[4]为了检测页面变化的情况,通过记录并对比每次抓取时URL 对应页面的最后修改时间Last-Modified来判断该页面是否进行了修改。文献[5]针对传统的周期性集中式搜索(Crawler)的弱点和增量式Crawler的难点,给出了判别网页更新的MD5算法。文献[6]在基于Hash函数“判断待采页面是否在已采页面集合中”方面,对Hash 函数Tianlhash、ELFhash、HfIp、hf和Strhash的性能进行了比较。文献[7]中提到去掉网页中标签信息、标签内部信息、注释信息和脚本代码的网页摘要获取方法,但没有给出具体的网页摘要获取过程。文献[8]中采用基于网页框架和规则的方式对网页噪声进行划分,然后获取网页的MD5值对网页进行增量采集。目前的增量抓取系统主要有IBM Almaden研究中心开发的Web Fountain Crawler,智利大学开发的一个增量搜集系统Univ.Chile Crawler和天网增量搜集系统。
3 增量抓取模块
3.1 Hash算法模块
Hash函数是密码学中一个重要的分支,由于它是一种单向函数,是一类加密映射,将任意长度的输入压缩成固定长度的输出,而且一般情况输出长度均比输入长度要短。Hash函数的安全性基础在于三点:1)从Hash值很难得到输入值的任何相关信息;2)很难找到两个输入能有相同的Hash值;3)找到一个有特定的Hash值的输入很困难,并且,从一个特定的输入寻找有相似性的输入更加困难[9]。
基于以上理论基础,将Hash函数应用到增量式网络爬虫中,对抓取的网页进行加密生成Hash值,通过对比新旧网页的Hash值来判断网页是否发生变化。Hash 值相同则表示网页没有发生变化,不用进行抓取;Hash值不同则表明网页发生了变化,需要进行增量抓取。
本文的增量抓取过程基于开源网络爬虫Heritrix[10]。Heritrix 是SourceForge 上基于Java 的开源爬虫,采用了模块化的设计,它由核心类和插件模块构成。其系统架构如图1所示。
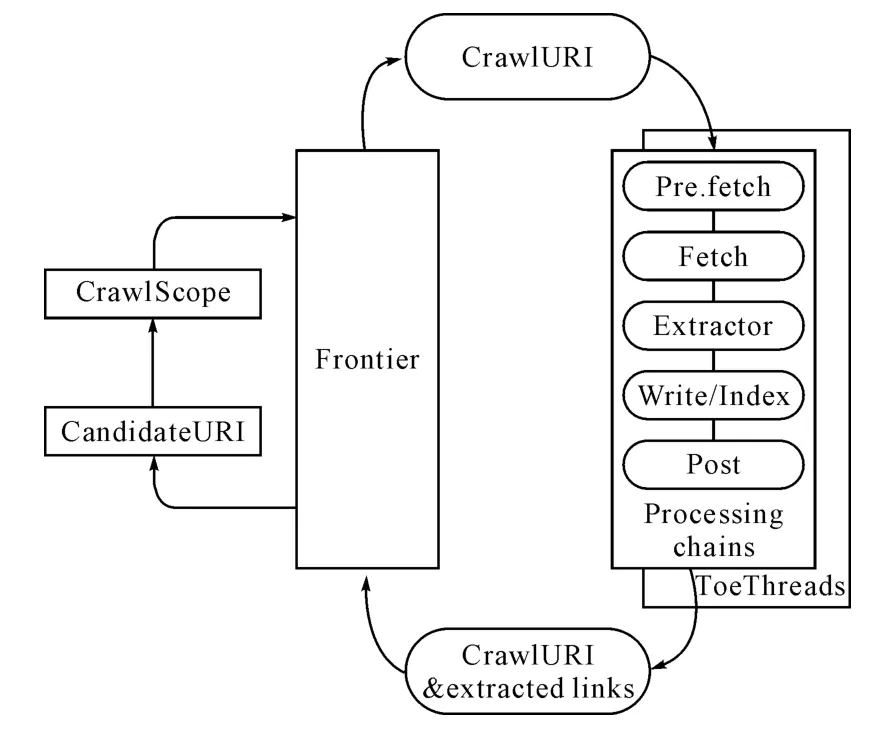
图1 Heritrix系统架构图
Heritrix只能对网页进行一次性抓取,要实现增量抓取必须在Heritrix中添加增量抓取模块,本文在Heritrix的处理链中加入HttpContentDigest和ChangeEvaluator两个模块实现Heritirx增量抓取。
HttpContentDigest:该模块对Fetch Processing Chain抓取下来的网页产生一个Hash 值,该Hash值就是为了判断网页是否发生了变化。接口类java.security.MessageDigest 中的哈希函数SHA-1提供了Hash值产生功能。该模块关键代码如下:

图2 Processing chain
1)创建一个消息摘要值,即Hash值,对文件进行处理;
MessageDigest digest=null;
digest=MessageDigest.getInstance(SHA1);
digest.reset();
2)文件处理;
Matcher m=TextUtils.getMatcher(regexpr,cs);
s=m.replaceAll("");
TextUtils.recycleMatcher(m);
digest.update(s.getBytes());
3)获取新的摘要值;
byte[]newDigestValue=digest.digest();
4)保存新的摘要值;
curi.setContentDigest(SHA1,newDigestValue);
ChangeEvaluator:该模块对爬取网页的当前Hash值与过去的Hash值进行比较,如果相等则处理链的进一步处理跳过,直接进入到提交链模块,并且将爬取的该URI进行标记。该模块关键代码如下:
1)新Hash值与旧Hash值均为空,不做任何处理;
if(currentDigest==null &&oldDigest==null)if(logger.isLoggable(Level.FINER))
logger.finer("On"+curi.toString()+"both digest are null");
return;
2)新旧Hash值均不为空且两者相等;
if(currentDigest!=null &&oldDigest!=null
&&currentDigest.equals(oldDigest))
curi.putInt(A_CONTENT_STATE_KEY,CONTENT_UNCHANGED);
跳过之后处理链的处理阶段:
curi.skipToProcessorChain(getController().get-PostprocessorChain());
重新设定链接:curi.clearOutlinks();
取消日志记录:curi.addAnnotation("unchanged");
设置文件内容为空,不写入磁盘:
curi.setContentSize(0);
3)新旧Hash值不同,判断文件内容改变,则按链接顺序进行抓取,并且更新访问与版本计数器。

3.2 网页去噪模块
基于网页Hash值的唯一性,可以判断网页是否发生变化,但由于网页中噪声的存在,即使网页正文没有发生变化,微小的噪声变化也会导致网页Hash的很大变化,由此判断网页变化是不准确的,必须对网页去噪后仅对正文部分产生Hash值,去噪后的Hash 值能客观地反映网页是否变化。本文采用基于内容分块的网页去噪方法对网页进行噪声去除[11]。
1)噪声内容确定:网页按照布局可划分为不同的区域,如正文、广告、图片、版权信息、分割条、导航链接、搜索服务和版权信息等,将这些不同的区域分为两块,即正文块和噪声块。正文块部分反映HTML页面的正文信息,是需要保留的部分;噪声块部分是需要去除的部分。通过去除噪声块,达到净化网页,提取正文的目的。
2)网页预处理:网页数据大多是使用HTML手工生成的文档,因此时常存在语法错误。首先要对文档进行预处理,去除掉无关的标签,修复语法错误,转换为语法限制性更强、编排良好、具有可扩展性的文档,DOM 树是其中一种形式。对于一个给定的网站,同一类型的网页集合的布局设计基本上是一致的。那么与他们相对应的DOM 树也会有相同或相似的结构。先对其进行分类处理确定属于哪一类型。然后从同一类型的网页集合中选取其对应的DOM 树进行遍历,来寻找其相同的节点,并将相应的信息块提取出来。这些信息块则是我们确定的疑网页噪声内容。
3)噪声去除策略:对于一个给定的网站,同一类型的网页集合的布局设计基本上是一致的,相对应的DOM 树也会有相同或相似的结构。基于此,对这个网页先进行预处理将一些无关标签去掉,将其转换为XML文档。然后将处理好的XML 文档转换为DOM 树,先对其进行分类处理确定属于哪一类型,然后从同一类型的网页集合中选取其对应的DOM 树进行遍历,来寻找其相同的节点,并将相应的信息块提取出来。
4)噪声提取算法:网页噪声块的提取过程就是DOM 树的融合过程,即将同一域名下的所有DOM 树融合,找出DOM 树中的共性部分,提取出噪声块[12]。网页噪声提取算法具体如下:
算法:噪声提取
输入:同一域名下的所有网页的DOM 树
输出:噪声提取模型
(1)从输入集中随机选择两个DOM 树;
(2)令DOM 树的body节点作为初始节点;
(3)若节点都含有子节点,则转到(4),否则转(7);
(4)遍历节点的子节点;
(5)将两个节点的子节点做一一对比,若所有的子节点有相同,则转(3),否则转(6);
(6)回溯到子节点的父节点,并从左到右记录父节点以及父节点的所有兄弟节点;
(7)从左到右记录所有节点;
(8)由所记录的节,奴依次回溯到body节点,形成中间可疑噪声信息块提取模型;
(9)若剩余输入集中的DOM 树大于1,从剩余DOM 树中选取一个DOM 树,转(2),否则,形成的8中形成的可疑噪声信息块提取模型即为结果可疑噪声信息块提取模型;
(10)结束。
网页噪声提取算法实际上是层次遍历DOM树的过程,当给定网站网页集遍历完成后,即可得到网页噪声模型。
5)去噪后基于Hash 的增量抓取模型如图3所示。

图3 去噪后基于Hash的增量抓取模型
4 实验结果与分析
本实验的硬件环境为:CPU:Intel Celeron E3300 双核;主频:2.5GHz/前端总线频率:800MHz;内存:DDR2 3GB 双通道;工作频率:400MHz;硬盘:7200 转。软件配置环境:Eclipse平台。
本实验从2013年7月30日至8月3日,对中安在线(www.anhuinews.com)进行了连续6次抓取实验,设置条件如下:Heritrix版本:1.14.4;最大线程:50;最大深度:3;其它设置:Heritrix1.14.4默认设置。
1)网页去噪前增量抓取实验
在Heritrix处理链中加入增量处理模块:HttpContentDigest和ChangeEvaluator,对中安在线进行第一次普通抓取,间隔1小时后在普通抓取的基础上进行第二次增量抓取,连续六组实验情况如图4所示。

图4 网页去噪前增量抓取实验
可以看出,在加入增量抓取模块后,每组实验中,第二次增量抓取的网页数相对第一次普通抓取网页减少,但第一次抓取的网页大部分还是被抓取下来,只实现了小部分网页的增量抓取。调出Heritrix的Hash值产生的日志文件,对比每次实验中HttpContentDigest模块对第一次普通抓取网页与第二次增量抓取网页产生的Hash值,随机选取其中六个网页,其六组实验的Hash值如表1所示。
同一网页在每组实验中,两次抓取的时间间隔均在1 小时以内,产生的Hash 值确完全不同,这样在网页提取时,对相同的网页又进行了二次抓取。进入网页存储文件mirror,调出两次抓取的网页,对比分析发现,网页仅仅是在访问量与网页时间上有细微的差别,网页正文没有变化,可见网页噪声对基于Hash的增量抓取结果影响很大。
2)网页去噪后增量抓取实验
在Heritrix处理链中加入网页去噪模块与增量抓取模块,以相同的方法对中安在线进行六组普通抓取与增量抓取实验,实验情况如图5所示。

表1 Hash值对比

图5 网页去噪后增量抓取实验
对网页进行去噪处理后,可以发现,Heritrix增量抓取的网页明显减少。进入网页存储文件mirror,调出新抓取的网页,对比分析发现,增量抓取的网页在正文内容上有较大变化,对于相同的网页则没有进行重复抓取,较去噪前Heritrix的增量抓取有较大的改善。
5 结语
目前,针对搜索引擎的增量式爬虫受到越来越多的关注。本文以开源网络爬虫Heritrix为基础,利用其扩展性好的优点,提出基于网页去噪Hash的增量式抓取方法,在利用SHA-1算法对网页产生Hash值前先对网页进行去噪,只对网页正文部分进行Hash计算,有效解决了经典Hash算法过于敏感,对网页变化判断不准确的问题,改善了网站的增量式抓取效率。由于网站结构的复杂性和多变性,不同网站的更新变化频率也不相同,本文只针对单一网站进行了增量抓取实验,根据不同网站的变化频率动态调节抓取时间是下一步需要考虑的问题。
[1]Munish Kumar.A New Approach for Web Page Ranking solution:sNorm(p)Algorithm[J].International Journal of Computer Applications,2010,9(10):20-23.
[2]Dong H,Hussain F K.Focused Crawling for Automatic Service Discovery,Annotation and Classification in Industrial Digital Ecosystems[J].IEEE Trans on Industrial Electronics,2011,58(6):2106-2116.
[3]道格拉斯编.密码学原理与实践[M].第3版.冯国登,译.北京:电子工业出版社,2010:213-219.
[4]杨颂,欧阳柳波.基于Heritrix的面向电子商务网站增量爬虫研究[J].软件导刊,2010,9(7):38-39.
[5]雷凯,王东海.搜索引擎增量式搜集的实现与评测[J].计算机工程,2008,34(13):78-80.
[6]吴丽辉,白硕,张刚.Web信息采集中的哈希函数比较[J].小型微型计算机系统,2006,27(4):673-676.
[7]龚诚.网页增量式采集技术研究[D].哈尔滨:哈尔滨工业大学,2007:35-37.
[8]李莎莎.增量式Web信息采集与信息提取系统的研究与实现[D].武汉:武汉理工大学,2011:22-25.
[9]黄月江,祝世雄.现代密码分析学[M].北京:国防工业出版社,2012:137-139.
[10]Heritrix官网[EB/OL].http://crawler.archive.org.
[11]G.S.Manku,A.Jain,A.D.Sarma.Detecting nearduplicates for web crawling[C]//Proceedings of the 16th International World Wide Web Conference,2007,20(2):43-50.
[12]M.R.Henzinger.Finding near-duplicate web pages:a large-scale evaluation of algorithms[C]//SIGIR,2006,12(3):284-291.
