基于聚类分析的网络论坛社团探测算法*
2014-10-24王长辉
王长辉
(成都纺织高等专科学校)
0 引言
网络论坛(BBS)由于具有及时性、交互性、开放性等特点,因而也是网络舆论产生、形成和发展的主要场所,整个网络论坛的参与者呈现一种特性— —社团结构,即整个网络由若干个社团构成,每个社团内部的节点之间的连接相对紧密,各社团之间的连接相对稀疏.研究网络论坛的社团结构,对了解BBS中网络舆论的传播特点具有现实意义.
网络论坛中成员根据兴趣或背景而形成真实的社会团体,网络中的这些社区有助于更加有效地理解其成员结构和分析网络舆论传播特性.目前对网络社团结构研究主要有两类主要的方法——社会学中的分级聚类和计算机科学中的图形分割方法.分级聚类是探测网络社团的传统方法,基于各个节点间连接的相似性或强度将网络划分成子群,并根据划分时是往网络中添加还是移除边可分为凝聚算法和分裂算法,Girvan和Newman提出基于边介数的分裂算法(简称GN算法);Kemighan-Lin算法和谱平分法则是较为出名的图形分割算法,其中Kernighan-Lin算法根据使社团内部及社团间的边最优化的原则对原始的网络进行分类,谱平分法是根据网络图的Laplace矩阵进行向特征向量空间的谱映射[1,6-8].该文算法是谱平分法的一种改进算法,将模块度函数与聚类分析算法结合进行社团结构探测.
1 算法简介
网络中的社团发现与数据的聚类分析有很多相似之处,聚类分析属于无监督的模式识别,其方法比社团发现更丰富,把聚类分析方法应用到BBS网民关系网络中可发现网民构成的社团结构.应用聚类分析方法来探测网络的社团结构分为两个步骤:第一步是将原问题转化为聚类问题,即要把网络中节点间的联系在特征向量空间中表述出来,谱平分法可实现这一转化;第二步对转化后的数据进行聚类并将聚类结果还原为相应的社团结构,该文在聚类过程中结合网络结构特征,用社团结构的模块度来控制聚类过程,并使用模拟退火算法来进行聚类.
1.1 BBS无向网络的建立
该文对BBS中网民n1和n2间关系给出4种不同的度量方式:
(1)网页同现:记C1(n1,n2)为n1和n2同时出现的网页个数.
(2)同帖同现:记C2(n1,n2)为n1和n2同时出现在一个帖子中的个数.
(3)同句同现:记C3(n1,n2)为n1和n2同时出现在一个句子中,且其间隔的字符数小于一个阈值(该文取20)的语句个数.
(4)连接词同现:定义一组连接词:{和,跟,与,同,and,或者,“顿号”}.记 C4(n1,n2)为 n1和n2由连接词连接的次数.
通过上述4种方法来定义任意两个网民n1和n2间的相关度:
C(n1,n2)=,(其中 pi为权重系数,这里取(p1,p2,p3,p4)=
记Ci(nj)为nj在第i种度量方法中出现的次数定义一个阈值flag(这里取0.05),若:
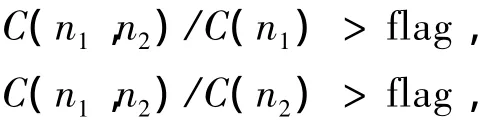
则记n1和n2有关系边,且边的权为相关度C(n1,n2),遍历所有2元人物对,可获得BBS关系网络的连接权矩阵W,从而建立论坛中的无向关系网络,记此关系网络为G(V,E,W).
1.2 模块度函数的应用
Newman等人引进了一个衡量网络划分质量的标准——模块度[9-10].对具有n个节点的无向网络G(V,E,W),其中V为节点集,E为边集,W=(wij)m×n为权矩阵.对此网络得出的某个k社团划分Pk,其对应的模块度定义为

其中,A(Vc,Vc)表示在社团c中所有边的权重和,A(Vc,V)表示所有与社团c中的节点有连线的边的权重和,A(V,V)表示整个网络中边的权重和.基于这样的定义,当网络的k社团结构越明显,则M(Pk)值越大,用M(Pk)作为社团结构有效度度量的标准[10].该文中,模块度是社团结构有效度量,作为优化迭代的一个指标应用到聚类算法中,在搜寻最佳社团数,设定聚类数条件下与目标函数值结合作为迭代的终止条件,在算法中作为适应度函数来控制算法的进化过程.
1.3 模拟退火算法
模拟退火算法模拟熔融状态下物体逐渐冷却最后达到结晶状态的物理过程,通过生成一系列参数向量模拟粒子的热运动,并缓慢地减小模拟温度的控制参数,最终达到系统能量最小值.该算法是局部搜索算法的扩展,算法以一定的概率选择邻域中能量值比较大的状态,理论上是一种全局最优算法.Metropolis等人[2]最早于1953年提出模拟退火算法,1983年 Kirkpat rick等人[3]成功把它应用于组合优化问题,算法模仿退火的物理过程,不依赖初始条件的选择,可寻找全局最小点而不陷入局部极小.
基本的模拟退火算法是:设当前温度为t,当前状态为P,其目标函数值为h(P),在P的邻域N(P)内产生一个新状态P',若h(P')≥h(P),则P=P';否则在[0,1)上产生随机数rand,计算,以概率 prob接受新状态P=P',否则舍去.重复以上过程,直到目标值在当前温度下趋于一个稳定值.
1.4 基于聚类分析的社团探测算法(C-based SA)
对于1.1给出的G(V,E,W),给定社团数目的最大值kmax和最小值kmin,进行以下步骤:
(1)记连接权矩阵W为D=(dij)n×n,其中D为对角矩阵,dii为第i个节点的度,n为节点数.
(2)对满足kmin≤k≤kmax的k,用Capocci方法[14]将寻找k社团问题转化为数据的k聚类问题.实际上是计算N=D-1W的前k-1个非平凡特征向量 e1,e2,…,ek-1(ei∈ Rn,i=1,…,k-1)组成矩阵A.由A的行向量x1,…xn,xi∈Rk)得到n个的数据向量形式的待聚类样本.
(3)用模拟退火算法对上面得到的数据进行k聚类:
这里对n个个体进行二进制编码,根据n的大小确定个体的编码长度len,len=min{i|2i≥n},定义邻域结构:
这里的目标函数选定为模块度函数y=M(Pk)(Pk是对n个个体一个k划分),对相应的模块度函数进行优化迭代,每迭代一次时都需要首先将每个解解码为聚类中心,然后将根据距离聚类中心最近的法则对每个个体进行分类,得出的聚类结果还原为相应的社团结构.
设控制温度参数的衰减系数λ;每一温度下马氏链的长度都取为邻域结构的大小k len.
算法1:(1)随机给定一个初始解x∈S,这里S为可行解集,y=M(Pk);
(2)while(t0<tf)
(2.1)for(i=0;i<;i++)
(2.1.1)t = floor(unifrnd(1,klen -0.0001)),令 x'=x ⊕ It,y'=M(Pk')
(2.1.2)delta(f)=y-y';
(2.1.3)若 delta(f)> =0,则x=x',y=y';
否则,若exp(delta(f)/t0)> random(0,1),则 x=x',y=y';
(2.2)t0=λ·t0;.
(3)输出:SA算法最优解x.
(4)对满足kmin≤ k≤kmax的 k重复(2)、(3),最后比较得到使目标函数最大的k聚类,并根据聚类结果还原为对应的社团结构.
2 试验结果
该文用海峡四川钓友联谊会(http://bbs.chinafishing.com/forum-113-1.html)的实际数据验证1.1和1.4中的算法.海峡四川钓友联谊会是海峡钓鱼网的一个子板块,其中参与者大部分为四川本地钓鱼爱好者,论坛成员具有共同的兴趣爱好.该板块为四川钓鱼爱好者的学习与交流提供了一条新途径.针对相关主题,论坛成员可以提出问题、发表各自的观点和看法,相互交流,相互帮助.
实际数据处理时,根据对已掌握的id对应关系,对部分id进行了特别处理,例如将“清凉油”和“151”这2个id合并处理,将“被草压死的骆驼”与“骆驼”,“黑武器”与“黑版”视为同一个id.
2.1 连接权矩阵的生成
按照1.1的算法,该文从6000余名在该论坛中发言的成员中筛选出满足各种阈值条件的成员1436人,并生成对应的连接权矩阵.
2.2 对比试验
为验证算法的有效性,该文将该论坛数据分别运用 K - Means算法[14]、CNN 算法[15]以及该文的基于模拟退火的社团探测算法.其中,KMeans算法是常见的聚类算法,是基于距离聚类中心最近法则为标准对个体进行分类的;而CNN算法则采用竞争型神经网络模型,进行无监督学习的分类.这里要注意的是,所有数据都经过1.4中第一步和第二步处理后,分别运行相应的算法,这里所有的算法程序都用matlab编写.
表1给出了各算法的试验对比结果.

表1 试验对比结果
这里运行次数为得到最优解的平均运行次数,时间为平均运行时间.
表2给出了应用C-based SA算法模块度在0.36以上的聚类结果,k=3、4、5时模块度较高.

表2 试验结果
图1给出了k=5、λ=0.997时的探测算法的迭代过程,迭代到2300次左右就已经求出了最优解.
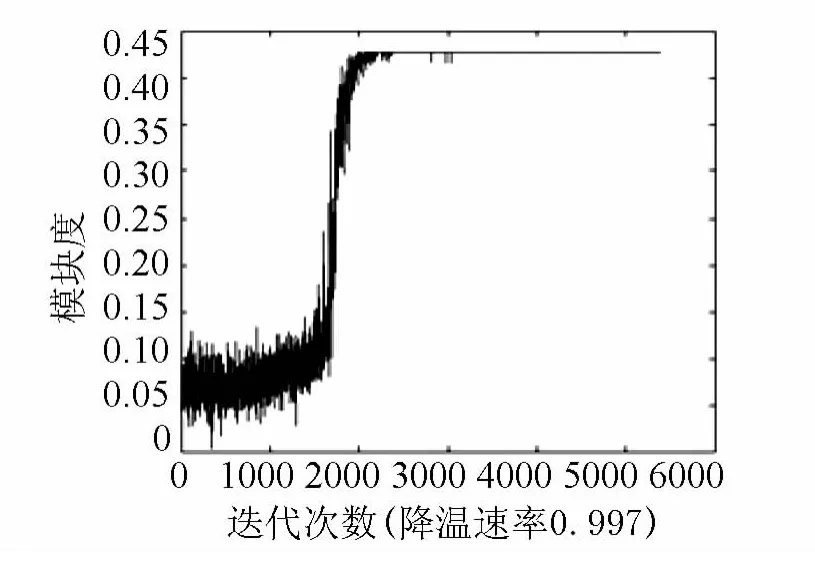
图1 模拟退火社团探测算法迭代过程(k=5,λ =0.997)
2.3 结果分析
通过对实际数据运行3种不同的社团探测算法,结果表明:K-Means算法速度较快,但受初始化条件影响较大,可靠性也比其他两种算法差,网络规模扩大对算法性能影响较大;CNN算法对初始化条件依赖程度较K-Means算法较低,但运算速度较慢,并且对数据预处理需要花较长的时间;三种算法中,C-based SA算法不依赖初始化条件的选取,直接使用模块度函数作为目标函数对网络进行社团探测,能保证达到全局最优解,可靠性较其他两种算法要高,该算法的复杂度依赖于系统降温速率的设置,其缺点是运行时间较长.
3 结束语
提出了针对网络论坛的社交网络的构建方法,将组合优化的方法与聚类分析的思想相互结合并应用到网络论坛社团结构的求取上,并提出了用模拟退火算法来求解,解决了实际工作实践中遇到的问题.试验结果验证了算法的准确性,模拟退火算法与聚类分析的思想能有效的结合起来,对论坛社团结构进行分析有较大的实用价值.
试验结果同时说明,基于兴趣的网络论坛中的社交网络社团结构不太明显,值得注意的是,该文使用的是非重叠性的社团探测算法,考虑到实际网络中,个体往往具有多群体特性,因此,改进社团结构的定义以及在此基础上探索新的社团划分方法是一个值得研究的方向.
[1] Xie Zhou,Wang Xiaofan.An Overview of Algorithms for Ana lyz ing Community Structure in Complex Networks.Complex Systems and Complexity Science,2005(8):46-50.
[2] Metropolis N,Rosenbluth A W.Rosenbluth M N,et al.E-quations of state calculations by fast computing machines.J Chemical Physics,1953(21):1087-1091.
[3] Kirkpatrick S,Gelatt C D,Jr M P.Vecchi Optimization by Simulated Annealing[J].SCIENCE,1983,220(5):4598 -4602.
[4] 邢文训 谢金星.现代优化计算方法[M].北京:清华大学出版社,2003.
[5] 赵天玉.模拟退火算法及其在组合优化中的应用[J].计算机与现代化,1999,61(3).
[6] CapocciA,Servedio V D P,Caldarelli G,et al.Detecting communities in large networks[J].Physica A,2005,352(2-4):669-676.
[7] Clauset A,NewmanM E J,Moore C.Finding community structure in very large networks[J].Phys Rev E,2004,7(6):066111.
[8] Bezdek J C,Boggavarapu S,Hall L O,et al.Genetic algorithm guided clustering[J].FUZZ2IEEE'94,1994(2):34-39.
[9] Newman M E J,Girvan M.Finding and evaluating community structure in networks[J].Phys Rev E,2004,69(2):026113.
[10] White S,Smyth P.A spectral clustering app roach to finding communities in graphs[C].Newport Beach,USA:SIAM International Conference on DataMining,2005.
[11]王陆,马如霞.意见领袖在虚拟学习社区社会网络中的作用[J].电化教育研究,2009,(1):54-58.
[12]叶新东,邱峰,沈敏勇.教育技术博客的社会网络分析[J].现代教育技术,2008(5):36 -41.
[13]胡勇,张翀斌,等.网络舆论形成过程意见领袖形成模型研究.四川大学学报:自然科学版,2008,45(2):347-351.
[14] Capocci A,Munoz M A.Detecting network communities:a new systematic and efficient algotithm [J].Physica A,2005,352(2-4):669-676.
[15] 周开利,康耀红.神经网络模型及其MATLAB仿真程序设计[M].北京,清华大学出版社,2005.111-128.
