车牌字符识别的一种快速算法
2014-10-24贺瑜飞
贺瑜飞
(榆林学院)
0 引言
自动识别系统进行车牌识别,主要由车牌定位、字符分割和字符识别这三部分组成,在字符识别的过程中,由于我国车牌中的信息包含数字、字母和汉字,所以字符识别率是车牌识别的关键部分,传统的方法有贝叶斯统计决策模式识别方法、结构模式识别方法、神经网络方法,还有基于支持向量机的一些识别方法.但是对于一些模糊的车牌,单纯的用一种方法,效果不是很好,该文最后采用了改进的神经网络和模板匹配结合来识别字符,使得车牌的字符识别性能能够得到明显的提高.
1 预处理
1.1 归一化
字符归一化,在某些情况下,可以消除字体大小以及分辨率高低的一些情况对车牌的影响,归一化处理就是消除这些影响,其主要思想是经过对不同尺寸和不同大小的字符化为统一的字符图像.
经过处理后的某像素点(m,n),规定在原图像下的坐标为:

原图大小X×Y,处理后的大小为M ×N,以下的方法是求出像素点位置和他们最近的像素的灰度值,如图1中,假如p像素最相近的四个相邻像素分别是 a、b、c、d,坐标为(x0,y0),(x0+1,y0),(x0,y0+1)以及(x0+1,y0+1),灰度值是g(a),g(b),g(c)和 g(d).

图1 四个相邻的像素图
e的灰度值g(e)和f的灰度值g(f)为(以下上横线为两点间的距离):

那么p点的灰度值g(p):g(p)=ep[g(f)-g(e)]+g(e)
必须保证最后的图像仍是二值图像,需要做阈值处理,如果g(p)≥0.5,则归一化后的图像像素灰度为1相反则为0.最后形成32×32的标准字符,标准化后的图像如图2所示.

图2 标准化后图像
1.2 字符细化
细化主要思想是提取汉字笔划中轴线,得到笔划的类型信息.为了更好提取笔划的信息,还必须要得到汉字均宽,对所确定好的中轴线,把所在线段垂直方向上黑色像素的点数取平均,如果效果不是很好,可以再经过加权,最后用不同的灰度值表示横竖撇捺这四种骨架点.通过这种算法,可以有效抑制笔划交叉处的一些可能存在的变形.
主要步骤:(1)首先必须对图像进行扫描处理,假如果是扫描到的是黑像素点,那么计算出从这一个黑的像素点沿着它的八方向,还有连续笔画边缘点黑像素点的个数,这个就作为当前黑色像素点的八方向长,一次下去,可以得到一个八维的方向向量,按此顺序记为:C(c1,c2,c3,c4,c5,c6,c7,c8),接着将会以 c8为起点,按照逆时的针顺序,必须找到互相相邻的三个方向的长度的最小值,记为 B(b1,b2,b3,b4,b5,b6,b7,b8),定义b1为c1与c2和c8的最小值,b2为c1、c2和c3的最小的值,以此类推,可以找到B向量上其余剩下元素的值.
如果有c1> b3,c1> b7,c5> b3,c5> b7,(c1+c5)>2×(b3+b7)且|b3-b7|≤1,这样黑的像素,最终的结果是可能为横笔划正好的中轴点.所谓的细化,就是为找到中轴线,且是每条笔画的中轴线,先观察p2和p6的值,然后进行判断,是否黑像素点就是横笔画的中心点.结果可能被标记的是k1、k12、k13或者是k14,那么就不能标为横笔画中心点,反之那么标记为k1.
假如 c3> b1,c3> b5,c7> b1,(c3+c7)>2×(b1+b2)而且|b1-b5|≤1,说明这一个黑像素点可能是竖直笔划的中心点.检查是不是已有被标记为 k2、k12、k23、k24中的一个,那么在标记前还需要分别查找p6和p4的值.若被标记,那么这点就是两笔画交叉点,若没有被标记,查找是否已被标为k1、k2以及k4中的一个.撇笔画和捺笔画标记方法与此类似.
细化后的图像,如图3所示.
2 基于改进的模板匹配对英文及数字的识别

图3 细化字符图像
改进模板匹配对英文及数字的识别,其主要思想是基于传统模板,然后增加了用字符特征的描述法和边缘提取,来进行字符识别.中国汽车牌照有自己的特点,既有汉字又有数字和字母,其中有24个英文字母与10个数字,所以根据各种方法的比较,相对比较适合用模板匹配.但是牌照中的一些字符,比如很相似的B,0和D,这样很容易发生错误的判断,再还有一些普遍现象,有些车牌污染严重,所以车牌的字符识别率很低.
2.1 改进的模板匹配算法
模板匹配的基本原理是这样,输入函数f(x,y),在模板匹配中表示输入字符,函数F(x,y)是标准模板,比较后输出的是T(x,y).那么相关器输出是:
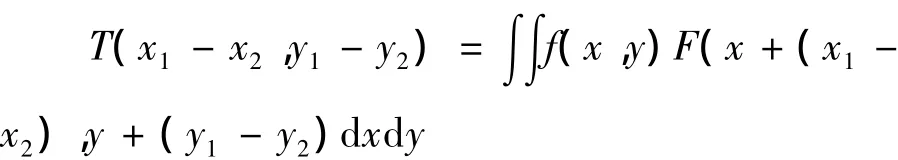
当 x1=x2,y1=y2时

当 f(x,y)=F(x,y)时

有 T(0,0)≥T(x,y),那么T(x,y)在T(0,0)出现主峰,那么副峰就会出现在其他标准字符下,主峰如果能够不等于副峰,就能判断并且能够识别出字符.
模板定义的是一个离散函数Tx,y,假如高斯白噪声会干扰图像Ix,y,把未知标准误差定义为σ,那么相对应的像素相匹配概率为:

即为

最后归结为求小化问题

设标准的模板字符图像是T,待检测字符图像的子图是Fxy(m,n),F(m,n)为待检测图像,这里定义其互相关算子为:

最佳匹配模板就是互相关算子所对应的模板,经过处理后的图形,只存在着灰度值是1或0的像素,最后可以简化为:
根据我们之前的预备知识,首先进行的还是处理,只是图像已经被分割好,仍然是把图像想办法变成统一的大;然后确定匹配的模板库,首先进行阈值的设定,但根据的是已经知道的位置信息;给出的N是阈值数,是指给出的匹配度小于标准模板匹配度,继而把标准化后的字符,和标准模板进行匹配.假若N=1,说明匹配的结果是唯一确定的,输出字符,N >1,说明相类似的字符可能存在于未知的模式中,没办法识别时,我们用特征描述法来进行识别,N=0,匹配的结果可能不理想,因为有磨损或者是噪声存在,接着就会用到边缘模板匹配法来进行匹配.
2.2 特征描述法识别字符
在字符的研究过程中,会发现其中有些数字和字母的结构非常的相似,图片必然会出现笔画粘连、断裂或者是模糊的情况,这时候就要用本文所讲的特征描述法.首先是对字符结构观察,然后进行逼近的一个识别,所以会有识别速度和准 确 率 的 提 高 等 优 点. 比 如: “Z”“2”,“C”“D”“Q”,“B”“8”,“S”“5”这样的字符.这样,就面临着把不容易区分的数字字母做一个区别,接着进行字符构造的分析,把相似的数字和字母归类为一组.分组时先把字符分为无封闭环和有封闭环两种类型,那么“B”是有封闭环的字母,“8”是有封闭环的数字,然后进行一个竖方向的笔画类型划分;一个封闭环字符肯定是“4”,“6”,字母是“A”,接着根据竖笔画来判断,“4”的竖笔画在右边;假如没有输出结果,判断横的笔画,字符“A”就有横笔画,“6”是最后剩下的;数字“7”,“3”,“2”和字母“Z”是没有封闭环的,观察可以发现“Z”是有两条横的笔画,这样就能识别“Z”.剩下的“3”和“7”其横的笔画都是在上方,而“2”的横笔画是在下方,这样比较会比较容易识别出“2”,“7”和“3”所抽取的不是竖笔画,也不是横笔画,而是斜的笔画,有斜的笔画的是“7”,反之则是“3”.数字“0”与字母“O”的区别,这要看其的位置信息,字母“O”出现的位置是第二个字符,这样就能区分数字“0”和字母“O”.
2.3 模板匹配
在匹配的过程中,会发现有些字符没有被识别出来,这就说明没有找到相匹配的模板,,但一个问题是一定的,特有的物理结构是车牌的一个特点,这个特点是字符与车牌的边缘不属于一个平面.该文选用Canny算子进行边缘轮廓的提取,Canny有其自身的优点,可以检出弱边缘的真正存在,而且一个优点是不易受到其他一些因素的干扰.设定两个不同的阈值,分别进行强边缘和弱边缘的检测,弱边缘信息想要包含在输出的图像中,只能检测出的边缘是相连接的.所以,提取车牌边缘信息,主要是用字符的边缘信息来识别.图4是传统模板和边缘模板示意图.

图4
3 神经网络识别中文字符
传统的神经网络算法中,在梯度这方面没有做过多的研究,该文是改进了传统梯度下降的算法,偏导数的幅值不变化,只借用了偏导数符号.权值的变化由偏导数的符号唯一确定,一个更新值来确定大小的变化.在迭代过程中,如果偏导数符号不发生变化,那么就增大更新值,乘以上一个1到2之间的数是新的更新值;相反如果符号发生改变,那么就更新值进行降低,乘以上一个0到1之间的数.迭代过程的公式如下:
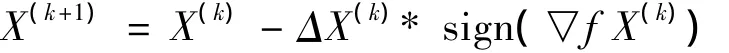
ΔX(k)是前一次的更新值,根据实际情况预先设定初始值ΔX(k).
这里汉字分类器首先要设计神经网络,三层的BP神经网络是我们设计的,输入的节点n由特征向量的提取来进行一个确定.因为汉字选用的是39维向量,那么39维向量是识别系统的输入向量,所以应该取n是39+1作为一个输入神经元的个数.最后需要分类的汉字类别应该与输出神经元的个数m是相同的.经过试验,传统的BP神经网络要经过至少2500次的训练才能收敛,该文的算法只用了1000次就能做到收敛,所以改进后的神经网络比以前的神经网络更优.
4 实验结果分析
实验用相机对汽车进行拍照,然后用该文算法对进行处理,让改进的模板匹配来识别字符.必然会有相似或者是模糊字符发生,按照前面所说,第二次匹配时用字符特征描述法来进行识别,然后第三次匹配用边缘提取.算法是在VC++7.0下来实现,仿真实验结果见表1.识别率明显提高.
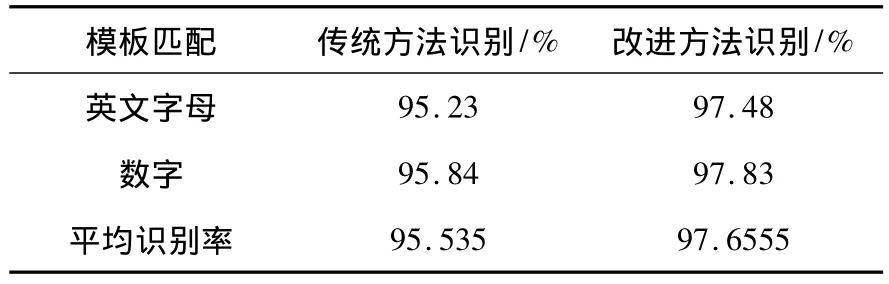
表1 识别结果
[1] 魏武,黄心汉.基于模版匹配和神经网络的车牌字符识别方法[J].模式识别与人工智能,2001,14(1):123 -126.
[2] 虞安军,吴海珍,蒋加伏.改进的遗传算法在车牌自动识别系统中的应用[J].计算机仿真,2006,23(11):224 -227.
[3] 吴红梅,陈继荣,鹿晓亮.一种新的车牌字符分割方法[J].计算机仿真,2007,24(2):252 -255.
[4] 杨晓敏,吴炜,黎涛,等.基于Gabor变换和支持向量机的车牌字符识别算法[J].四川大学学报:工程科学版,2005,37(5):130-138.
[5] 袁志民,潘晓露,等.车牌定位算法的研究[J].昆明理工学报,2001,26(2):56-60.
[6] 崔屹.数字图像处理技术与应用[M].电子工业出版社,1997.
[7] 魏武.智能交通系统关键技术研究图像处理、模式识别与智能控制.武汉:华中科技大学.博士论文,2000.
[8] Sunghoon Kim,Daechul Kim.A robust licenseplate extraction method under complex image conditions[C]//In:The l6th International Conference on Pattern Recognition.Quebec Canada,2002.216 -219.
[9] 大型室内停车场车辆出入计算机自动识别与管理系统[J].哈尔滨师范大学自然科学学报,1995(2).
[10]王鉴,黄山,严国莉,等.车牌字符识别技术[J].中国测试技术,2005(2):45-46.
