基于空间增强和谱减法的语音识别系统
2014-10-11倪曼蒂邹丽萍张楚才
倪曼蒂,李 彪,邹丽萍,张楚才
(1.湖南商务职业技术学院,中国长沙 410205;2.中南大学软件学院,中国长沙 410004;3.湖南师范大学数学与计算机科学学院,中国长沙 410081)
虽然自动语音识别(ASR)系统的研究已投入了大量的人员和资金,但是它还不能够像电话一样,作为日常生活的一部分完整地融入到人们的生活当中.其中一个最主要的问题就是自动语音识别系统在噪声和混响环境下,特别是二者混合环境下的识别性能过于低下[1].在大多数情况下,为获得可接受的识别性能,只能依赖于麦克风阵列的使用,即通过使用大量按照特定位置放置的麦克风来获取语音输入和空间信息.大量的ASR研究,使用麦克风阵列得到方向增益,以改善噪声与混响环境中获取信号的质量;采用模式识别技术中的谱减法来消除噪声和处理语音训练集与测试集不匹配问题[2].
在日常应用中,普通用户既不可能随身携带麦克风阵列也不可能精确地放置它们.目前,日常使用的麦克风是与双通道耳机相对应的,它能得到双通道语音信号,却不能得到复杂的空间信息.如果依然采用传统的信号增强方法(例如广义旁瓣抵消技术)来处理双通道信号,以作为语音识别系统的预处理端,那么噪声的消除反而会带来无法接受的语音失真.
谱减法[3]作为另一种消除噪声的技术,可以不依赖麦克风阵列获取输入信号,但是却存在三大缺点:(1)噪声估计误差过大导致噪声消除时语音失真;(2)增强后的语音中含有明显的“音乐噪声”;(3)混响未被处理.
为解决上述问题,本文基于双声道语音信号简单的空间特性,综合使用改进的广义旁瓣抵消空间增强技术和改进的谱减法技术作为语音识别系统的噪声消除和信号放大的预处理端,并基于HTK开发工具设计一个识别性能优异的语音识别系统.
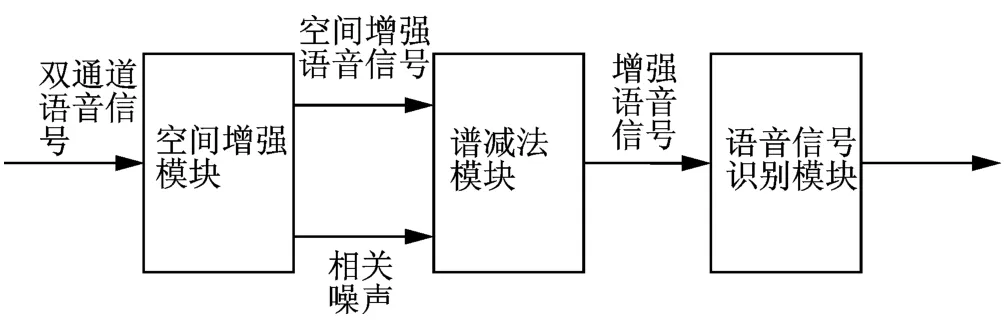
图1 系统结构Fig.1 System structure
1 系统描述
图1为本系统的整体构架.它由空间增强、谱减法模块和自动语音识别模块3个主要部分构成.
1.1 空间增强模块
因为空间线索是语音识别的主要部分和远场麦克风语音识别的组织焦点,在该ASR系统中,采用PASCAL“CHiME”[4]组织提供的双通道含噪语音信号,利用该信号简单的空间特性可以得到表现优异的噪声估计.
有许多经典的使用麦克风阵列的方法来放大目标信号,例如通过延迟求和方式的波束形成,自适应噪声消除(ANC)以及独立成分分析(ICA).它们使用麦克风阵列得到方向增益,以改善在噪声与混响环境中获取信号的质量.
1.2 噪声消除模块
通常的ASR系统在处理含噪信号时性能大幅度下降,因此,噪音消除是该系统中常见且必须的组成部分.当前主流的噪声消除技术可以分为3大部分.(1)使用时域滤波技术,例如维纳滤波和自适应滤波;(2)尝试还原原始语音谱的谱还原技术,例如谱减法[5]和参数减法;(3)为增强语音结构,有许多基于语音模型的噪声消除技术,例如基于谐波模型的噪声消除.然而,使用这些技术来获得噪声衰减和信噪比的改善,往往会造成语音失真.通常,越干净的噪声消除会导致越严重的语音失真,因此,研究设计一个针对复杂声学环境的ASR系统,在语音失真和噪声消除之间寻找一个平衡点,是非常重要的工作.
1.3 识别系统自适应
通过一些经典的空间滤波和噪声消除技术来处理麦克风阵列在真实环境中获取的声音信号,较直接采集含噪声音,具有更好的听感知质量.但是无论系统设计多么完备,获得的加强声音中依然会有噪声残留和语音失真的问题存在,它们能被正常人轻易的接受和识别,但是目前的ASR系统却不具备这样的能力.当前几乎所有的ASR系统都采用模式识别技术,当测试数据集接近训练数据集时,能够得到非常高的识别精确度.但是噪声残留和语音失真会导致测试数据集完全不同于“干净”的训练数据集,训练和测试不匹配的问题会直接导致ASR系统识别率的降低.
为解决这些问题,前人提出许多的方法,例如模型再训练和自适应,特征变换和归一化[6-7],建立环境模型和模型特征一体化技术将之使用在自动语音识别模块上,能起到良好的效果.
综合考虑到对上面所述三部分的分析,所有的模块都应该整合为一体,只有通过良好的语音信号预处理和完善的识别系统自适应,才能构架一个更优异性能的ASR系统.
2 系统设计
本文提出一个简洁而具有高鲁棒性的针对CHiME问题的ASR系统.首先,依据双通道信号的空间信息增强它们,然后采用改进的谱减法获得增强信号,作为ASR系统的输入,最终得到识别结果和关键词准确率.
2.1 改进的空间增强
由于存在混响问题,使用传统方法得到双通道信号的空间信息的有效内容非常困难.另外,如果采用传统的信号增强方法,例如基于广义旁瓣相消(GSC)的波束成型,作为ASR系统的前端,那么噪音消除会带来语音失真[8],会极大地降低ASR系统的识别性能.语音失真是由GSC多路输入抵消器(MC)的窄带自适应滤波器导致的,它既无法良好地消除噪声,同时还消耗昂贵的计算资源.

图2 空间增强Fig.2 Spatial enhancement
本ASR系统的前端,利用双通道语音信号的优势,移除了典型GSC里的MC模型,使得在空间滤波的同时尽量避免语音失真和降低计算负担(图2).该模块的主要任务是提取参考噪声,而不再进行噪声消除.
该模型的输出信号为如下的形式.
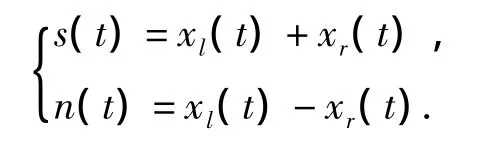
其中,xl(t)和xr(t)定义了双通道信号;s(t)为空间增强信号;n(t)为参考噪声.
2.2 改进的自适应谱减法
谱减法是从噪音环境中还原“干净”语音信号的经典算法.在简单的声学仿真环境中往往能取得较好的性能,但在真实和复杂的环境中却常常失败.主要原因是谱减法的噪声估计方法是猜测语音输入的静音段,即没有目标语音只有噪声的段,通过统计一个时段上的噪声信号,取其均值作为该段上的通用参考噪声估计.
通过该方法来估计噪声信号或者得到其统计特性是一项非常困难的工作,特别是当噪声环境越发接近真实环境时.目标语音很小时,会被误估计为噪声,噪声过大时,会被误认为目标语音.另外的一个问题是混响的作用,它使得双通道信号保留了一定的目标语音.此外,由于采用均值,致使在相位上的噪声消除时,存在过大噪声的语音会存在噪声残留,而存在较少噪声的部分会存在目标语音过度削减[9],且缺乏实时性.
把这些因素加入考虑之中,本系统将噪声估计前置到空间增强模块,开发了一个改进的谱减法的模块,如图3所示.
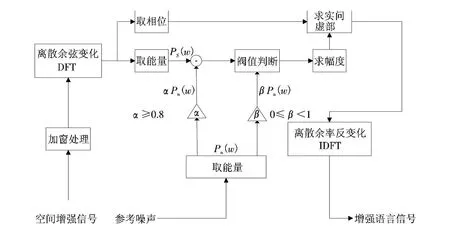
图3 改进的谱减法Fig.3 Improved spectral subtraction
算法流程为:
输入的含噪空间增强语音可以简单表示为:

FFT转换之后,得到式(2).利用最小值跟踪算法对Yk进行估计,得到噪声谱估计Nk.

对式(2)结果的两边取平方,因为s(t)与n(t)独立,式子左右取能量(即振幅)时,得到式(3):

因此干净语音信号的估计值为式(4):

式(4)中的α=1,γ=2就是基本的谱减法,而改进谱减法一般是调整二者的值,本系统不但调整了取值,而且改进了谱减法的构架.为了在谱减法信号中消除噪声而不导致巨大的目标语音失真,本模块主要做了两方面的工作:一是噪声估计被空间增强模块的参考噪音输出取代,二是使用离散余弦变化取代了傅立叶变换,降低了减法因素α的最小值.
本系统的整体算法输出结果如下:
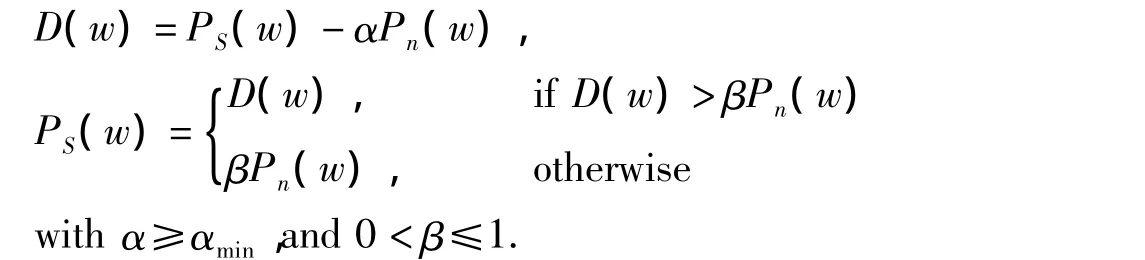
2.3 自动语音识别模块
对文献[10]所介绍的针对CHiME问题的ASR模块做了两个改动,以实现测试与最终数据集的匹配和自适应.本模块基于 HTK package(version 3.4.1).
采用倒谱均值归一化(CMN)实现标准39-梅尔倒频谱系数(MFCC),以单词为建模单元建立从左到右的带自跳转不带状态间跨跳的7高斯混合隐马尔科夫模型(HMMs).通过观察发现,这些静音部分如果不单独建模,那么在训练数据集的脚本和声音信号之间将会产生巨大的不匹配.根据这一结果,对于这些静音,建模非常必要.全盘考虑这一现象,这些静音被单独建模为4状态的隐马尔科夫模型(HMMs).此外,对于识别所采用的语法如下:

训练说话人相关HMM模型,需要面对数据稀疏的问题.首先在开始阶段先训练出说话人无关的HMM模型[11],再使用说话人相关的语料额外执行4次EM训练的迭代.经过这些迭代策略,每个说话人的模型不再近似于说话人无关模型而是各自独立的说话人相关的模型,换言之,在训练模型和识别模型之间存在不匹配.因此,为了尽量克服这样的不匹配,当每个说话人完成独立训练后,使用基于最大后验概率的自适应训练来取代额外的4次EM训练的迭代.
3 实验与结果
用于训练和评估本ASR系统的数据,由CHiME组织提供,在其主页上可以轻松获取.
经过空间增强和自适应谱减法的34个说话人在混响环境中的语句(采样率16 kHz)被用为训练材料.34个说话人的独立含噪语句(采样率16 kHz),经过上述两道工序处理,被送到ASR模块进行识别.
ASR系统的自由参数是减法因素α的最小值.使用开发集的数据进行调节,参数α的最小值设为0.8.
最终测试结果见图4.分别使用开发数据集和测试数据集进行HMM建模后,本系统的关键词准确率见表1和表2.

表1 开发数据集各信噪比情况下关键词识别率实验结果Tab.1 Keywords recognition accuracy of develop data on SNRS from different system structures

表2 最终测试数据集各信噪比情况下关键词识别率实验结果Tab.2 Keywords recognition accuracy of final data on SNRS from different system structures
结果简析:
视图的数据来源于表格.
图5中横轴为不同信噪比的语音信号,纵轴为该语音信号在本系统中所取得的关键词识别率,即正确识别率.
BASELINE为传统语音识别系统(采用基本谱减法和基本空间增强进行语音预处理,使用标准配置进行语音识别)的关键词识别率;
SIL为传统技术的基础上,为空白语音单独建模后的关键词识别率;
SIL+MAP为在SIL基础上,使用了MAP自反馈技术后的关键词识别率;
SIL+MAP+PLUS为在SIL+MAP的基础上,使用改进的空间增强技术后的关键词识别率;
SIL+MAP+PLUS+SUB为本系统完整构架下,即为空白语音单独建模、使用MAP自反馈技术、添加改进的空间增强、添加改进的谱减法后的关键词识别率.
比较结果可以看出,本文对系统的三大改进,都提升了系统在SNR为-6dB到9dB的语言文件关键词识别率.特别是在SNR为-6dB到0dB时,提升非常显著,每个模块或技术加入系统后,对关键词识别率的提升百分比如图5.

图4 各信噪比下不同系统构建关键词识别率Fig.4 Keywords recognition accuracy on SNRs from different system structures

图5 不同信噪比下不同方法对关键词识别率的提升百分比Fig.5 Percentages of keywords recognition accuracy on SNRs improved from different system structures
SIL对静音部分的单独建模,纠正了训练脚本未标记这些部分的错误,改变了信号与训练脚本的不匹配,SIL的加入对性能提升大有帮助.
MAP的加入使得模型在海量数据集的训练下,非常接近于说话人相关模型,因而对关键词识别率的提升显而易见.
PLUS层的作用,单独看来,对系统关键词识别率提升影响很小,因为均衡考虑语音失真和计算复杂度,GSC的多路输入抵消器被移除了,该部分具有去除噪声的功能.但该层是本系统SUB的基础,在低SNR的情况下,参考噪声中完全不存在目标语言,提供了良好的去除噪声的基础.但是在高SNR的情况下,混响的存在会超越背景噪音成为首要问题,它导致从空间增强模块输出的参考噪音依然残留有目标语音,谱减法模块对整个ASR系统会造成伤害.尽管自适应谱减法的最小值阈值被调低,但这依然不是一个解决该问题的最好方法.在图5可以看出,高信噪比情况下,在PLUS的基础上加入SUB层,对关键词识别率的提升非常小,甚至反而降低了关键词识别率.可以预见随着SNR的增加,这个现象会越发明显.
4 结论
本文针对语音识别这一交叉性强的学科,打破传统的语音识别系统局限于利用有限的技术,不断挖掘技术潜力,来达到提高性能的研究模式,提出了一种全新的综合性构架,并取得了实质性的成效;考虑到人类听觉的生理情况,结合空间增强层得出的无目标语言的参考噪声,对谱减法模块做了积极的改变.将去除噪声操作从空间增强层移动到了效率更高的谱减法层,将噪声估计移动到空间增强层,使得整个系统的分工更加明确,以降低耦合,提高鲁棒性;使用了倒谱均值归一化实现标准39维-梅尔倒频谱系数,为语音识别模块加入基于最大后验概率的自适应训练,提高了训练效率和系统整体性能.
[1]宋志章,马 丽,刘省非,等.混合语音识别模型的设计与仿真研究[J].计算机仿真,2012,29(5):152-155.
[2]HIRSCH H G,PEARCE D.The aurora experimental framework for the performance evaluation of speech recognition systems under noisy conditions[C]//ASR2000-Automatic Speech Recognition:Challenges for the new Millenium ISCA Tutorial and Research Workshop(ITRW).Paris,France,2000,9:18-20.
[3]张 满,陶 亮,周 健.基于实值离散Cabor变换的谱减法语音增强[J].计算机工程与应用,2012,48(29):109-113.
[4]BARKER J,VINCENT E,MA N,et al.The PASCAL CHiME speech separation and recognition challenge[J].Computer Speech Language,2013,27(3):621-633.
[5]BOLL S.Suppression of acoustic noise in speech using spectral subtraction[J].Speech and Signal Processing,IEEE Transactions,1979,27(2):113-120.
[6]HERMANSKY H,MORGAN N.RASTA processing of speech[J].Speech and Audio Processing,IEEE Transactions,1994,2(4):578-589.
[7]CHEN C P,BILMES J,ELLIS D P W.Speech feature smoothing for robust ASR[C]//2005 IEEE International Conference on Acoustics,Speech,and Signal Processing:Proceedings:March 18-23,2005.
[8]BRANDSTEIN,MICHAEL,DARREN WARD.Microphone arrays:signal processing techniques and applications[M].New York:Springer,1996:20-75.
[9]KAUPPINEN I,ROTH K.Improved noise reduction in audio signals using spectral resolution enhancement with time-domain signal extrapolation[J].Speech and Audio Processing,IEEE Transactions,2005,13(6):1210-1216.
[10]NAOYA W,NOBORU H,YOSHIKAZU M,et al.A noise robust speech detection system using MFCC analysis[R].电子情报通信学会技术研究报告.ディジタル信号処理,2003,103(146):25-30.
[11]肖 勇,覃爱娜.改进的HMM和小波神经网络的抗噪语音识别[J].计算机工程与应用,2010,46(22):162-166.
