高校网络舆情监控系统的实现*
2014-10-10刘志兵
刘志兵
(长沙大学附属中学,湖南长沙 410022)
高校网络舆情监控系统的实现*
刘志兵
(长沙大学附属中学,湖南长沙 410022)
立足于对高校网络这一校内主要舆论平台的监控的实际需要,结合中文信息处理领域中网络爬虫、网页除噪、特征提取、文本分类等技术,给出了一种高校网络舆情监控系统的实现方案,并通过实验验证了系统的有效性.
网络舆情;数据挖掘;网络爬虫;聚类分析
2014年11月,CNNIC第33次《中国互联网络发展状况统计报告》表明,至2013年12月,我国网民已达到6.18亿.在高校校园,网络已经成为在校大学生获取信息、表达意见、参与社会事务的重要平台,是网络社会的重要力量.在这一虚拟空间里,国内外的一些重大突发事件以及高校内的热点问题都会在很短时间内引发在校学生的关切,当主题逐渐收敛为特定对象,就形成了网络舆情现象.本文将基于网页信息挖掘技术,针对舆情监控系统展开研究.
1 网络舆情研究现状
目前,在国内学术界,针对于“网络舆情”这一概念,还没有形成统一的认识[1].其中“网络舆情是由各种社会群体构成的公众,在一定的社会空间内,对自己关心或与自身利益紧密相关的各种公共事务所持有的多种情绪、态度和意见交错的总和”这一表述较为普便认同.
在国际上,网络舆情的研究方向主要有两个:一是基于自然语言的处理,其关键技术有中英文分词技术和未登录词鉴别.而就热点发现的研究,基于论坛的信息、环境、目标的共享等多种度量指标,则采用多维向量技术来度量话题活性的方法.二是利用数据挖掘技术,研究热点的发现.利用网络的复杂特性对内容进行分聚类.该技术基于网络无尺度网络,即:Scale-Free,此类技术立足于Web特性和数据挖掘.
2 系统功能实现分析
为了测试系统功能的有效性,将本系统部署在湖南省长沙某高校校园网络内,舆情分析监控系统重点关校内某学生论坛的舆情数据.系统开发语言为JAVA;数据库软件为MySQL;开发工具为MyEclipes6;采用为B/S架构,主程序运行在Linux 2.6.32环境中,中间件采用为Tomcat6.0.24,下图1,为网络舆情监控系统的工作流程和主要功能模块.
2.1 信息采集模块
信息采集模块负责本系统的对校园网上各类网站论坛上页面的数据抓取,并为此后进行信息分析提数据来源.在校园网中的各类网站、论坛web页中,蕴涵了非常多的数据信息,且此类页面以半结构化或者是非结构化形式存储数据,并处于时刻更新的状态,所以,系统就必须具备一个信息采集模块,负责对舆情信息进行有效收集,其工作流程如下图2所示.

图1 系统工作流程和主要功能模块
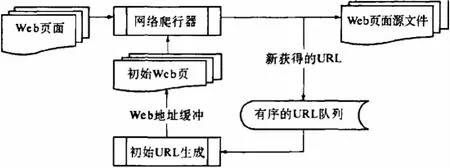
图2 系统采集模块的工作流程
舆情信息采集是指对网页的抓取和相关数据的存储,网页抓取基于网络爬虫技术.第一步,利用页面数据采集器,从初始数据集开始,将此类URL链接信息都存储在一个有序的、等待收集的队列之中;第二步,根据顺序获取URL信息,定向的所指网页,并返回得到页面文件.第三步,通过分析已获取的网页链接信息,生成下一步需要采集的页面的链接信息,并再次将其重新放入待采集的队列中,通过不断重复以上步骤,直到目标网站所有页面或者预设层级页面被全部抓取.为了提高效率,系统设计了几个信息采集器并行采集数据,即多线程地爬行多个网页并存储网页源码.另外,为提高采集页面效率,可使用基于特定主题的定向抓取技术,如:主题网络爬虫.该技术是通过一定的web分析算法,先过滤掉和指定主题无关的URL,再将有用连接信息存入等待抓取的队列之中,依据预设主题,对页面连接与已下载内容进行分析,从而预测出,下步需要进行抓取的连接以及当前web页的主题关联性,确保爬虫对于页面下载的有效性.本系统模块具体要求满足两类操作,一是对普通浏览网页的抓取,二是对用户信息的抓取,采用的技术主要是网络爬虫技术.
(1)对网页的爬取
本文系统利用网络爬虫技术,根据网页或者论坛页面结构进行过滤爬取选定的URL所指页面,分别存放在系统中的:forum、board、rootboard、post文件夹中.并为后续信息理提供基础数据.具体方法如下:
设置爬取深度“1”,对网站或者论坛页面进行爬取.URL过滤规则是依照对其链接进行字符串鉴别.对符合规则的爬取下载页面,按照时间分别存放到系统中相应文件夹中.
(2)用户信息爬取
用户的信息爬取,必须模拟登陆后方能操作,具体分为模拟登陆和爬取信息两个部分.爬取的注册用户信息格式如下形式:

2.2 信息预处理模块
在已抓取的页面之中,除了有用的正文信息外,还存在大量的其他无用信息内容,如:菜单导航、网站版权、友情链接等,不同于结构化数据,web中的数据多为半结构化或者非结构化数据,其形式非常复杂,所以,一般程序就难以对此类原始数据直接进行分析和处理.而系统中的信息预处理模块,其主要负责的工作,就是对网页进行无用信息的清洗除噪,并对内容、特征以及关键词等进行提取工作,下图3所示,即为此模块的工作流程.

图3 系统信息预处理模块流程
(1)页面除噪和内容提取:如前所述,由于web页中含有大量的除正文外的噪声信息,另外,在页面语义内聚性上很难保证,一个网页中,往往有若干个与语义无关内容,因此首先进行页面除噪,将对后续的数据挖掘效果起到非常重要的作用.该项工作的目标是从网页里获得更加精确的数据信息单位,过滤掉如:页面导航、标注、广告等垃圾信息.在完成除噪后,通过内容提取,系统将半结构或者非结构化的数据转变为具有结构化模式的,且可操作的信息.在本网络舆情监控系统里,内容的提取,是依据以下两步完成:第一步,web页逻辑结构的解释;第二步,针对特定元素内容的筛择.
(2)特征和关键词提取:特征提取,就是从文本分词处理后的文档当中,获取有效信息的技术方式.经常使用的是:基于词义、词性特征的提取方法.本系统采用的就是基于词性的特征提取.第一步,获取文本内容里的动词、名词等,并将其定义为该文本1级特征词,再通过计算此级别特征词的文本频数以及文档频数,进而得到其权重值.第二步,依据先前得到的特征词的各权重值,对此类1级特征词实施排序,并预设K,为阈值,然后在此类词中,选出权重值较大的1级特征词,K个,作为核心特征词,进而生成表示该文本的特征向量.
2.3 舆情分析与预警模块
舆情分析是本系统当中最为关键的一个处理模块,该模块基于文本分类和聚类等方法,对先前预处理后的舆情数据进行深入挖掘和分析,并以此提供“话题发现”和“热点跟踪”,下图4,即为舆情分析模块的工作流程.
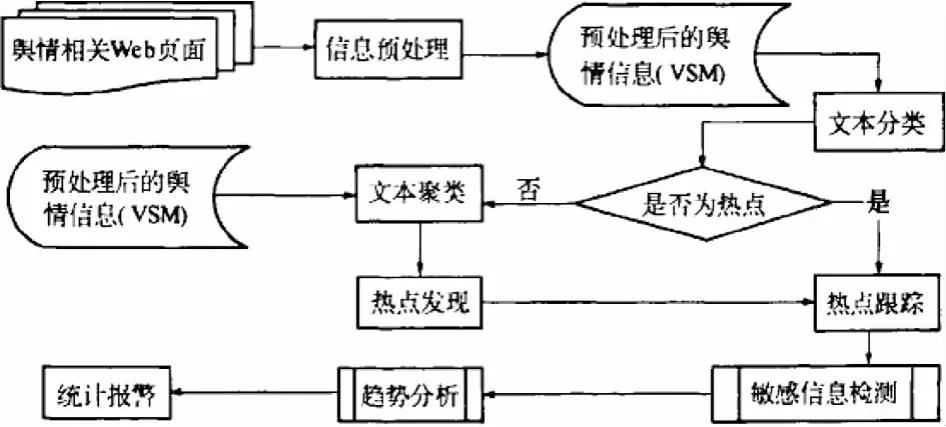
图4 舆情分析功能模块流程
(1)话题发现与跟踪:话题发现功能是将信息内容归入不同的话题,并在需要的时候建立新话题,等同于无指导的聚类;话题追踪负责追踪用户选定兴趣话题的后续发展,判断出与之相关事件[4].此类功能的实现采用的是文本聚类分析技术.聚类分析就参照一定规律要求对事物进行区分的过程,把内容相近的文档进行归纳.聚类分析,其数学描述如下[5]:
针对一个特定的数据样本集合:
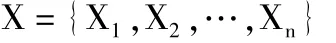
依照集合中数据点的相似程度,将数据的样本集合分成若干个簇
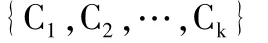
的过程,我们就称其为:聚类的分析.
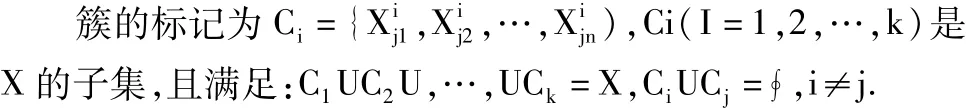
典型应用是作为一个独立的工具透视数据分布.
基本步骤如下:
第一步,指定一个数据集合作为聚类.
第二步,选取文档中的数据特征.
第三步,按照特征,聚合文档到对应类.
第四步,选择关键词,对聚类进行标记.
在实际应用当中,我们最为常见的文本聚类算法有基于网格的方法,还有层次型、分割型等聚类算法.
(2)敏感话题识别:此项功能,是用于分析特定主题在不同时段之中,被浏览者关注的程度.在互联网里,话题往往会根据时间的推移,或者某类事件的发生,出现一定的规律变动.经过研究,可以发现,小规模话题,即使观点对立度在一定时段中变化较快,但因为人们参与话题规模不大,无法代表多数人意见,故,在进行敏感话题识别时,就必须还要结合话题参与规模、网民观注度这些要素,找出舆情在一定时段中的相关网页数量,只有能够都满足参与规模数、观点对立度两个阈值,系统才可以启动预警.
(3)舆情预警:此模块提供舆情监控系统和用户之间的各类交互操作,可以通过报表、图型等方式,将经过系统分析后的结果最终反馈给管理者.其中常见功能如:敏感话题趋势、热点话题排序等,系统通过此类直观交互性展示信息,能使管理者对各类热点敏感信息的进行在线分析,及时把握舆情变化趋势,必要时,系统还能实现预警的自动触发.而预警功能是检验本系统实际应用效果的一个关键指标项,为此本系统针对该模块功能进行了如下评价测试.
①评价标准:舆情预警能对系统分析出的热点词汇、敏感词汇等要素对获取的网页信息进行二次处理,并有效提供管理者查询分析使用.
②实验环境:系统针对特定敏感词“聚会”,对从论坛下载的网页进行筛选,整理出符合条件的网页信息结果.实验的硬件配置为戴尔PowerEdge T110塔式服务器,CPU:Xeon E3-1220,内存:1GB,系统环境:Windows 2003.
③结果分析

图5 舆情预警对敏感词的筛选结果
以上结果可以看出,本系统舆情预警服务能针对热词、敏感词、关键字进行有效筛选,能为管理者及时提供预警信息帮助.
3 结语
加强高校校园网上网站、论坛BBS上的网络舆情信息监控,及时追踪校园网上的舆情变化趋势,对于分析在校大学生的思想行为特点,指导学生身心健康发展,引导校园文化和舆论的正确走向都具有非常重要的积极作用.本文中涉及的舆情系统经过前期的详细论证、认真设计,以及后期的试运行分析,已经表明系统已具备一定的实用功效.但由于时间仓促,在系统的实际应用过程中,我们也发现了一些问题,这也是我认在今后需要进行重点改进的地方:
(1)系统的舆情分析功能有待加强:经过一段时间的运行表明,本系统在一些基本功能方面都已具备,在今后的研究当中,“文本倾向性分析”技术的应用和优化仍然需要重点进行改进的内容.
(2)系统扩展性有待加强:本次工作中所设计实现的网络舆情分析监控系统主要还是针对高校普遍采用的论坛架构体系而言,虽然能通过修改相关XML配置文件和类属性可以实现对不同类型论坛的分析监控,但针对其他如传统网站、应用日志、非HTTP下载应用的信息获取和分析功能还需要进一步完善.
(3)系统部署通用性和兼容性:本系统主要部署在校内服务器上,并基于Linux操作系统和Tomcat中间件发布,目前只应用于校内论坛的舆情信息的监控,如需推广应用,系统就必须综合考虑不同网络环境、系统架构下的兼容性和通用性.
[1]姚占雷,许鑫,赵路平.2005-2009年国内网络舆情文献的计量分析[J].现代情报,2010,(10):174-177.
[2]Franz M,Ward T,McCarley JS,et al.Unsupervised and supervised clustering for topic tracking[A].Proceedingsof the24th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval[C].2001.
[3]Alena N.Sematically distinct verb classes involved in sentiment analysis[A].IADIS International Conference Applied Computing[C].2009.
(作者本人校对)
Realization of the Public Opinion M onitoring System of College Network
LIU Zhibing
(The Middle School Attached to Changsha University,Changsha Hunan 410022,China)
Based on the actualneeds of college campus network,amajormediamonitoring platform,and combined with Chinese information processing fields,such asWeb crawler,web noise removal,feature extraction and text classification techniques,this paper provides an implementation method of university network public opinion monitoring system,and verifies the effectiveness of the system through experiments.
network public opinion;datamining;crawlers;cluster analysis
TP391
A
1008-4681(2014)05-0056-03
2014-07-14
刘志兵(1986-),男,湖南长沙人,长沙大学附属中学网络工程师,硕士.研究方向:网络工程.
