扩展DS证据理论在入侵检测中的应用*-
2014-09-05陈烨,刘渊
陈 烨,刘 渊
(1.江南大学数字媒体学院,江苏 无锡214122;2.江苏省信息融合软件工程技术研发中心,江苏 江阴214405)
1 引言
证据理论也称D-S证据理论,是由Dempster于1967年提出、并由他的学生Shafer进一步发展起来的建立在有限离散领域之上的推理形式。DS证据理论通过定义置信函数,可将不确定性和不知道进行区分,能在先验概率未知的情况下,通过简单的证据合成准则将多个不确定信息进行合成,得出较好的综合结果。D-S证据理论已广泛运用于数据融合的各个领域,如:专家咨询系统、预测、图像处理、人工智能、识别分类等。入侵检测是将网络数据分为正常数据和各类型的攻击数据,本质上是一个多分类问题[1]。然而,单一的检测算法往往存在检测率不高、误报率过高等局限性,所以国内外诸多学者研究将D-S证据理论引入到入侵检测系统中[2]。但是,基于经典D-S证据理论的大部分研究需要假设截获的数据相互独立无冲突,而在真实网络环境中数据不可能无冲突,因此基于经典D-S证据理论的网络数据融合会导致融合结果不合理,影响检测效果。
为了解决经典D-S证据理论在冲突的数据中不能取得合理结果这一问题,本文应用一种基于加权[3]的组合算法,能有效处理高度冲突证据的组合,并融合多个SVM分类器建立异常检测模型。
2 D-S证据理论
2.1 经典的D-S证据理论
D-S证据理论是建立在非空有限域Θ上的理论,Θ称为识别框架(Frame of discernment),表示有限个系统状态{A1,A2,…,An},而系统状态假设Hi是Θ的一个子集,也就是Θ的幂集P(Θ)中的一个元素。D-S证据理论通过对系统状态的一些观察E1,E2,…,Em来推测出当前系统所处的状态。这些观察仅仅是系统状态的不确定性表现,并不能够唯一确定某些系统状态。D-S证据理论中的三个重要函数为:基本的概率分配函数(bpa)或叫做mass函数、信任函数(bel)和似然函数(pl)。
定义1 基本的概率分配函数(bpa):设函数m:2Θ→ [0,1],且满足:
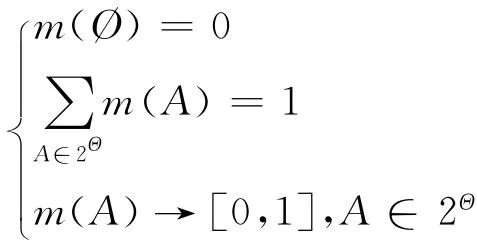
其中,m(A)作为焦元A的基本概率数,表示依据当前的环境对焦元A的信任程度。当A为空集时,m(A)的值为0。
当同一个识别框架Θ有多个数据源时,对于这些数据源根据各自的mass函数提供不同的评测值。合成这些数据源的所有信息的规则称为合成规则。经典的D-S证据理论假设所有的数据源具有相同的可信度。n个证据合成规则如公式(1)所示。
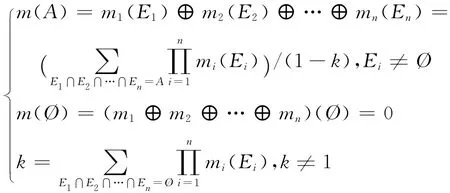
其中,m(A)表示证据A的mass值;k的取值范围为[0,1],称为冲突因子,用来反映融合过程中各证据间的冲突程度,k越接近于1,证据间的冲突越激烈,矛盾也就越明显;而1/(1-k)是修正因子(归一化系数)。为了使识别框架Θ的理论更加完善,避免在进行证据组合时将非零的概率赋给空集,将空集所丢弃的信任分配按比例地补到非空集上,Dempster引入了1/(1-k)。
2.2 经典D-S证据理论的缺陷
尽管单用D-S证据理论通过简单的推理形式能得出较好的融合结果,但在实际运用中,经典DS证据理论存在如下不足:当各证据间的基本概率分配函数存在严重冲突时,融合后得到的结果明显不合理;而且焦元的基本信任分配发生的极其微小变化会带来其组合结果剧烈的变化。这些不足很可能导致判断错误,从而影响入侵检测系统的检测性能[4]。
2.3 组合规则改进
针对各证据间的冲突问题,本文应用一种基于加权的D-S证据合成方法[2]:考虑到各证据之间、焦元之间的相关性,引入平均证据距离,计算各证据的可信度并作为该证据的权值。该方法通过平均证据计算平均证据距离,并得出加权系数从区分各证据在D-S融合中的影响程度,从而解决冲突证据的组合问题。
首先,计算各证据的平均值:
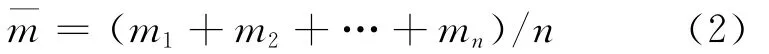
然后,计算各证据到平均证据的距离:
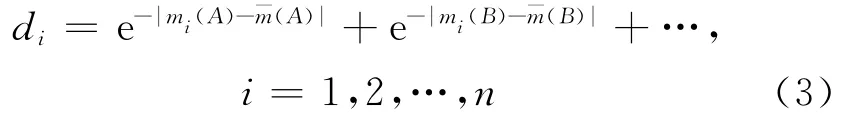
由公式(3)知,两个证据的相似性程度与对应概率的距离成反比,距离小的相似性程度就大,可令该距离为证据的支持度,即s(mi)=di。
最后,计算各证据的可信度:
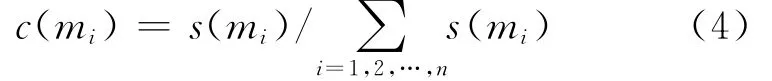
其中,c(mi)作为证据mi的权重,满足1,其他证据体对证据的支持程度表现在该证据的权值上。证据的权值高,则其支持程度高,对组合结果影响大;反之亦然。
那么,可以得出加权D-S证据的合成规则是:
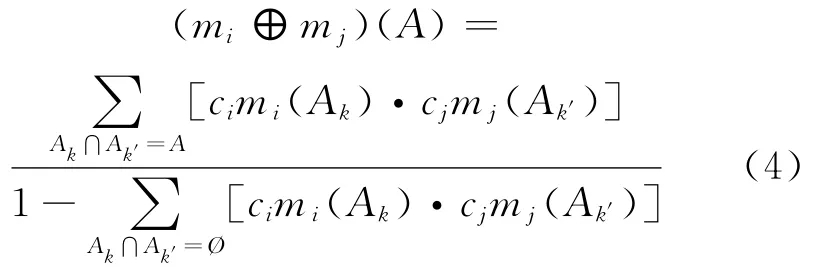
3 基于扩展D-S证据理论的入侵检测模型设计与实现
3.1 入侵检测模型分类模块设计
该模块中使用的数据集是MIT Lincoln实验室提供的 DARPA 数据集 KDD CUP 99[5]。核心分类器是林智仁编写的libsvm 2.8.9版本[6],并在Matlab2009b下完成的。KDD CPU 99数据集共有41维特征,分为:基本特征、流量特征和内容特征[7],如图1所示。
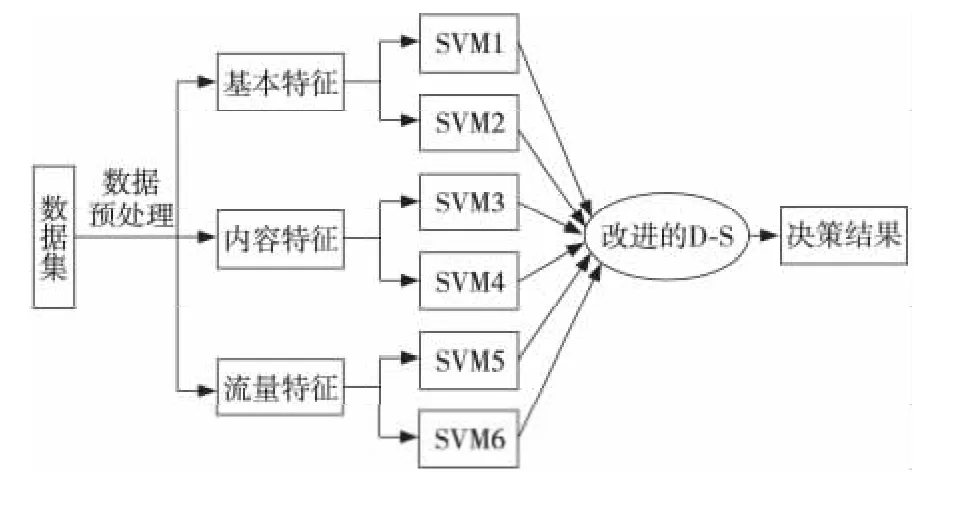
Figure 1 Classifiers based on improved D-S algorithm and SVM图1 基于改进D-S算法和SVM的分类模块
本文提出的检测模型首先在数据集中分别选取一定的数据作为训练数据集和测试数据集,然后对其进行数据预处理。接着,在该检测模型上检测预处理好的训练数据集,得出最终检测结果。
3.2 入侵检测模型实现
步骤1 底层SVM分类器的实现:将训练数据集按特征属性分为三类,分别使用两个SVM分类器进行训练(两个分类器的执行效率较高),得到一个最优分类超平面。再使用测试数据集在各个SVM分类器上测试,将预测的结果保存在S(i)中,其中i=1,2,…,6。
步骤2 模型融合部分的实现:将SVM得出的S(i)作为D-S证据理论的mass函数的参数,再由公式(1)~公式(3)计算出各个证据的权重c(mi),最后利用公式(4)得出最终融合决策。
3.3 SVM中核函数的选择以及参数的寻优
支持向量机中最重要的是核函数的选择。常用的核函数有以下几种[8]:
(1)线性核:K(xi,xj)=(xi·xj+c),c>0。
(2)多项式核:K(xi,xj)= (∂xixj+c)d,∂>0,c>0,d>0。
(3)径 向 基 核 (RBF):K(xi,xj)= exp(-γ‖xi-xj‖2),γ>0。
(4)Sigmoid核:K(xi,xj)=tan(v(xi·xj)+c),v>0,c>0。
通过对上面几种核函数进行比较发现,线性核即使在训练集特别大或属性特别多的情况下也可以快速地训练出结果,计算速度最快,但如果不在近似线性可分的情况下,则很难取得满意的效果;多项式核函数计算虽较快,但其函数值跨度非常大,计算结果可能趋向无穷大或者零,所以导致在有些情况下计算会比较困难;Sigmoid核函数因为不是正定核,相比其他几种核函数,其通用性不够好;RBF核函数具有良好的性能[9],同时参数也较少,在缺乏问题先验知识时其适应性最好,还能够处理非线性的情况,因此本文选择RBF核函数。
确定核函数后还需要确定惩罚参数C以及核参数γ。常用的SVM参数优化算法有网格搜索算法、PSO算法以及遗传算法等,本文使用网格搜索算法寻找一组较好的C和γ。网格搜索法首先需要根据经验制定C和γ的待搜索范围(一般在这个范围之内,C和γ会取得较好的结果),并设置好合适的搜索步长,每个参数在待搜索范围内取一系列待检验的离散值;然后分别取两个参数的所有可能待检验值的组合来训练SVM模型,并对模型的推广能力进行检验;最后选择能训练出推广能力最好的SVM模型的参数作为最优参数。
4 仿真实验
4.1 实验环境
本文实验在Matlab 2009b环境下完成,使用了libsvm工具箱[6]。由于KDD CPU 99原数据集较庞大,完全使用并不现实,因此本文实验仅使用了其中Normal、DOS、Probing和R2L数据各4 000条,U2R数据249条,并将其分为两份,分别作为训练数据集和测试数据集。
4.2 实验流程
(1)数据的预处理。因为 KDD CUP 99数据集中各个数据的特征属性并不统一,其41个特征中既有符号型特征,又有连续型特征,还有离散型特征,所以在实验之前需要对所有的特征属性进行预处理,使它们保持统一。连续型特征采用Rosetta[10]软件中的 Naïve算法进行离散化,而符号型特征则直接通过一般的映射将符号映射到离散型的数值中。最后,使用Matlab自带的映射函数mapminmax将数据集归一化,使所有属性的度量得到统一。
(2)将训练数据集和测试数据集按其特征属性分为基本特征、流量特征和内容特征三类。将分好的训练数据集分别使用两个SVM分类器进行训练。接着,将分好的测试数据集在训练好的SVM分类器上进行测试,并记录结果。
(3)利用加权D-S证据理论的融合规则进行决策融合,最终得出检测结果。
4.3 实验结果及分析
为了评价本文提出的融合模型的检测性能,本文使用以下检测参数:
(1)Precision:指经过检测得出的真正异常的记录数目在总的入侵记录数中所占的比例。
(2)Detection:指总的测试集中被正确分类的数据记录所占的比例。
(3)False Positive:指本来为正常记录、但被错误地检测为入侵记录的数目在总的正常记录中所占的比例。
(4)Recall:指被检测出来的真正的攻击记录在所有攻击记录中所占的比例。
(5)F-Score:用来评估异常检测系统的好坏,是Precision和Recall的调和平均数,F-Score值越大,该异常检测系统越好。F-Score的计算公式为:
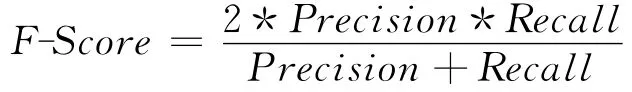
(6)AUC:ROC曲线的横坐标是误报率,纵坐标是检测率,曲线下的面积是AUC值。AUC值越大说明检测系统的性能越好[11]。
本文共做了三组实验。其中,SVM采用网格搜索算法搜索最优参数,根据以往研究经验设置参数的范围(参数C为2-5~25,步长为2;γ为0.1~1,步长为0.1),并采用10折交叉验证方法得出最优参数。
实验数据集中正常数据4 000条,Probing攻击、DOS攻击和R2L攻击数均为1 000条,U2R攻击数为249条,实验结果如表1~表4所示。
从表1和表3可以得出,与单个SVM、经典D-S融合SVM相比,加权D-S融合SVM 的方法几乎在所有的攻击类型的检测率上都有很大的提高,比较均衡,而且在提高检测率的同时又降低了虚警率(综合以上实验可以看出,加权D-S融合SVM算法的虚警率为0.63%,是最低的),即通过加权D-S证据理论融合SVM的方法可以解决单一检测算法在网络异常检测中虚警率高的问题。
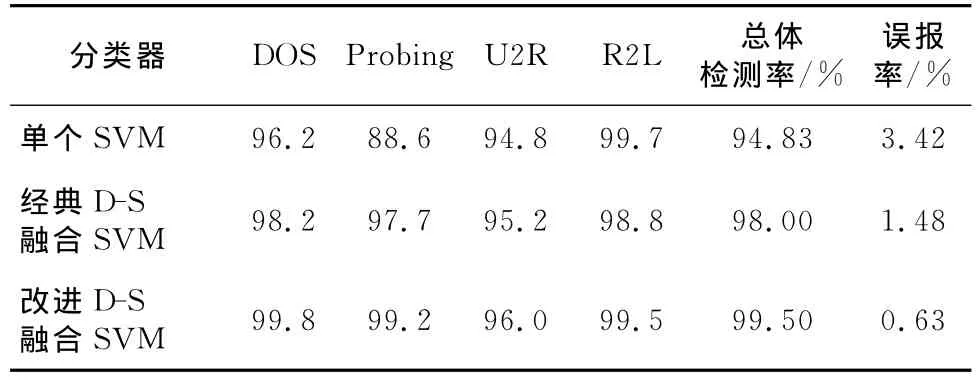
Table 1 Detection rate evaluation of each type of attack on single SVM、classical D-S fuse with SVM and improved D-S fuse with SVM表1 单个SVM、经典D-S融合SVM和改进D-S融合SVM在每种攻击类型上的检测率评测
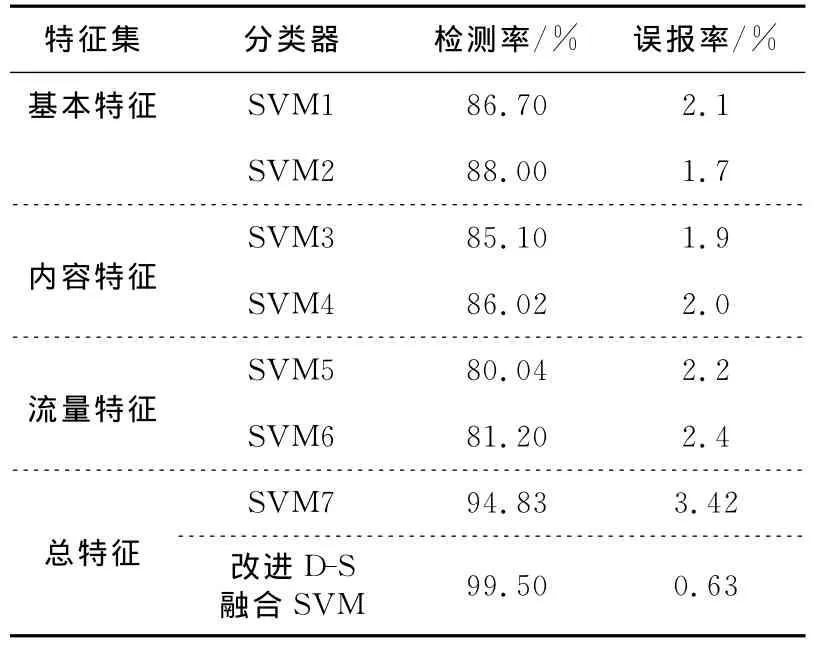
Table 2 Results evaluation of three feature sets表2 分特征集训练结果评测 %
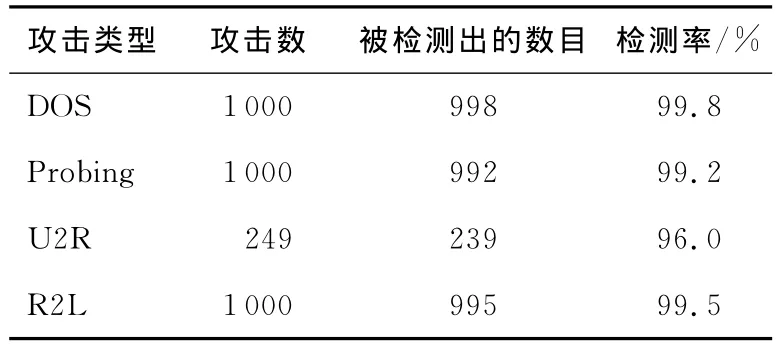
Table 3 Results of the weighted D-S fusion theory fused with SVM表3 加权D-S融合SVM的检测结果
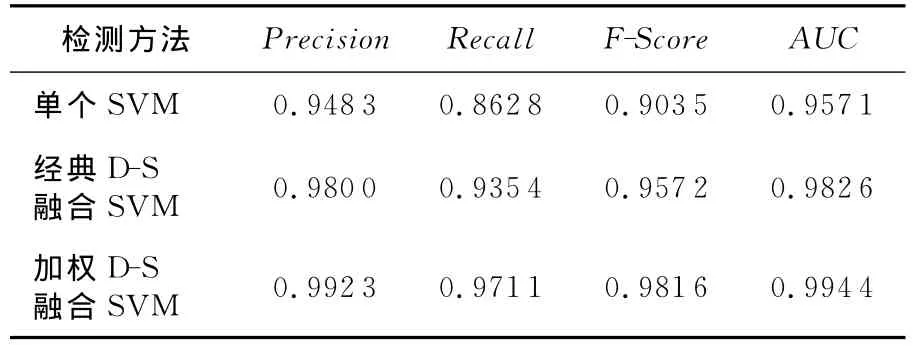
Table 4 Comparison of single SVM,classical D-S fusion SVM and weighted D-S fusion SVM on all the attacks表4 单个SVM、经典D-S融合SVM和加权D-S融合SVM在所有攻击上的整体比较
从表2可以明显看出,以总体特征集训练的SVM比以基本特征集、内容特征集以及流量特征集分别训练的单SVM检测率要高一些,但同时也产生了比较高的误报率。将多个SVM分类器得到的结果经过本文提出的加权D-S融合检测模型,得出的检测率比单个SVM所训练预测的检测率要高一些,同时也降低了检测中的误报率。
表4的数据表明,加权D-S证据理论融合多个SVM的检测率最高,同时,从F-Score上也能看出改进D-S证据理论融合多个SVM的检测模型的性能较好。
使用ROC曲线和AUC值对模型进行性能评价。
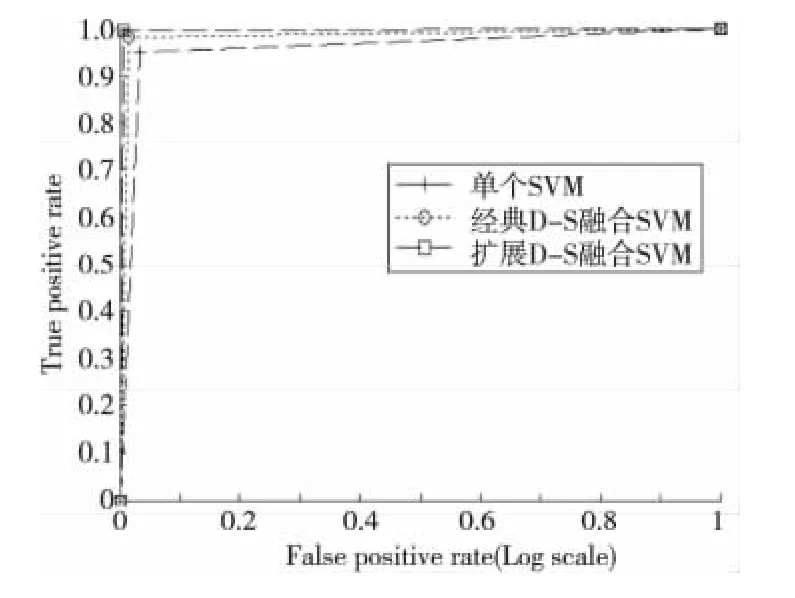
Figure 2 Comparison of ROCcurves图2 ROC曲线比较
图2 中实线下的AUC值为0.957 1,带圈虚线下的AUC值为0.982 6,而带框实线下的AUC值为0.994 4。可以看出,经典D-S融合算法能有效地提高检测系统的检测性能,而本文使用的加权D-S融合SVM检测模型,能够得到比经典D-S融合算法更好的检测性能。
5 结束语
不管是用传统的评价方式还是ROC曲线和AUC值的评价策略,都不难看出,本文提出的改进D-S融合算法在提高检测性能的同时,也能有效地遏制误报率,并且很好地改善了在各类攻击上的检测效果。
[1] Tang Zheng-jun,Li Jian-hua.Intrusion detection[M].Beijing:Tsinghua University Press,2004.(in Chinese)
[2] Zhuge Jian-wei,Wang Da-wei,Chen Yu,et al.A network anomaly detector based on the D-S evidence theory[J].Journal of Software,2006,17(3):463-471.(in Chinese)
[3] Su Lu,Li Quan-long,Xu Xiao-fei,et al.Data fusion algorithm for sensor network based on D-S evidence theory[J].MINI-MICRO SYSTEMS,2006,27(7):1321-1325.(in Chinese)
[4] Yang Jing,Lin Yi,Hong Lu,et al.Improved method to DS evidence theory based on weight and matrix[J].Computer Engineering and Applications,2012,48(20):150-153.(in Chinese)
[5] KDD Cup 1999Data[EB/OL].[2008-01-01].http://www.ics.uci.edu/~kdd/databases/kddcup99/kddcup99.html.
[6] LIBSVM data sets[CP/OL].[2012-07-01].http://www.csie.ntu.edu.tw/~cjlin/libsvm/.(in Chinese)
[7] Chen You,Shen Hua-wei,Li Yang,et al.An efficient feature selection algorithm toward building lightweight intrusion detection system[J].Chinese Journal of Computers,2007,30(8):1398-1408.(in Chinese)
[8] Tian Jun-feng,Zhao Wei-dong,Du Rui-zhong.D-S evidence theory and its data fusion application in intrusion detection[C]∥Proc of CIS’05,2005:244-251.
[9] Halavati R ,Shouraki S B,Zadeh S H.Recognition of human speech phonemes using a novel fuzzy approach[J].Applied Soft Computing Journal,2007,7(3):828-839.
[10] The ROSETTA Homepage[EB/OL].[1998-04-02].http://www.idi.ntnu.no/~aleks/rosetta/.
[11] Yao Yu,Gao Fu-xiang,Yu Ge.IDS evaluation approach based on ROC curves [J].Journal on Communications,2006,26(1A):113-115.(in Chinese)
附中文参考文献:
[1] 唐正军,李建华.入侵检测技术[M].北京:清华大学出版社,2004.
[2] 诸葛建伟,王大为,陈昱,等.基于D-S证据理论的网络异常检测方法[J].软件学报2006,17(3):463-471.
[3] 宿陆,李全龙,徐晓飞,等.基于DS证据理论的传感器网络数据融合算法[J].小型微型计算机系统,2006,27(7):1321-1325.
[4] 杨靖,林益,洪露,等.一种改进的D-S证据理论合成方法[J].计算机工程与应用,2012,48(20):150-153.
[7] 陈友,沈华伟,李洋,等.一种高效的面向轻量级入侵检测系统的特征选择算法[J].计算机学报,2007,30(8):1398-1408.
[6] LIBSVM data sets[CP/OL].[2012-07-01].http://www.csie.ntu.edu.tw/~cjlin/libsvm/.
[11] 姚羽,高福祥,于戈.基于ROC曲线的入侵检测评估方法[J].通信学报,2006,26(1A):113-115.
