普通话智能测试系统的语音识别网络研究
2014-09-04陈彩华
陈彩华
(湖南三一工业职业技术学院,湖南 长沙 410129)
0 引言
计算机辅助普通话水平测试系统自试用以来,已经在全国十多个省市推广。应用该系统不仅减少传统人工现场评分带来的人力、物力、财力成本,而且能较好地解决人工长时间工作所带来的评分波动,实现评分的客观公正。
现行系统属于文本相关的评测,考生按照标准文本发音,计算机根据发音质量反馈出分数。实际推广的普通话水平测试系统采用自动语音识别技术,即采用目前公认的最能反映标准度的基于隐马尔科夫模型(HMM)的对数后概率算法,将考生的语音文本切分到音素,在音素基础上计算出能够反映考生发音标准度、流畅度的评分特征,再给出机器评分结果。HMM是一种基于统计的模型,各音素的发音分布描述只能依据高斯分布,各HMM之间易混淆,从而导致系统无法正确反映音段的发音质量,这将严重影响系统的评分性能,但语音识别中的语言模型能够较好地消除HMM混淆影响;因此,本文借鉴语音识别中的语言模型思想,将普通话发音的语言学知识引入到对数后验算法中,从语言模型的角度来重构对数后验概率算法中的识别网络,消除概率空间中HMM的混淆影响,解决不同音素之间后验概率的不可比性。
如何削弱概率空间对语音测试系统的影响,提高系统的评测性能,学者进行了不懈努力。文献 [1]提出 “根据声韵母时长比例调整后验概率”,根据时长加重声母的权重,改善声韵母间的后验概率不一致问题。文献 [2]提出音素混淆扩展网络的后验概率计算方法。这些方法的思想类似,都通过特定的方法减少概率空间中的音素个数,达到减少概率空间对评测任务影响的目的。
本文从目前已有的普通话水平测试自动评分系统出发,在文献 [3]统计的4大类考生发音错误的基础上,将绝大多数考生的发音错误规律引入到常用的后验概率评价算法中,对算法的概率空间进行优化,并在500份普通话水平现场考试数据集上进行实验。实验结果表明,基于考生发音错误的概率空间能有效降低概率空间带来的混淆。
1 普通话智能测试系统结构
受语音识别技术的限制,现行的普通话水平测试系统只能对考生完全按事先指定的文本朗读的题型进行评测,属于文本相关的语音评测。文本相关的发音质量自动评测系统的流程如图1所示。
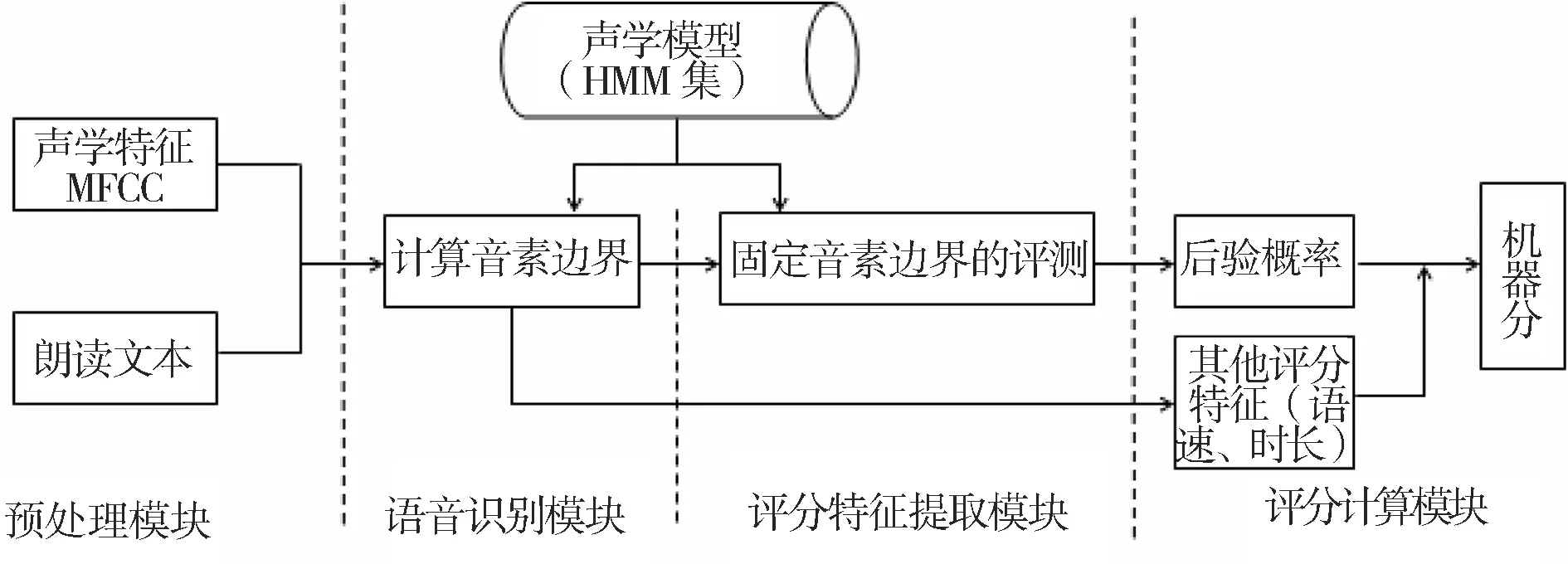
图1 文本相关发音质量自动评测系统流程图
预处理模块接收考生语音和标准文本,得到语音的声学特征和语音识别所需要的信息;语音识别模块根据声学模型进行识别,输出音素及其边界;评分特征提取模块根据识别结果,结合文本和声学模型,提取可量化的描述发音标准度、流畅度、完整度等评分特征;评分计算模块根据评分特征计算并输出考生的机器评分。
2 基于语言学知识的识别网络重构
2.1 普通话评测系统中的识别网络
普通话水平测试系统中的语音评测是基于对数后验概率法的,即先在切分(forced alignment)[3]的音素边界上按式(1)对单个音素进行计算,然后对考生的整个语流按式(2)进行规整,得到考生最终发音质量评分。
(1)
(2)
式中:Oi是根据考生的待测语音所提取的声学特征,即观测数据;di是Oi的时长(帧数);M为后概率空间;P(Oi|qi)是音素qi的似然度;N是考生整个语流中的音素个数。
式(1)中分母的输出反映考生真实发音的音素级识别结果。实际发音评测中,因无法运用语言模型,因此由汉语声韵母构成一个音素循环识别全网络,如表1所示,再在全网络中求各音素的最大似然度。

表1 汉语声韵母列表
2.2 基于语言学知识的识别网络重构
国内参加普通话水平测试的考生大都以汉语为母语,发音质量问题大都是受方言的影响产生的,有很强的规律性。普通话测试专家已经系统总结了带方言口音普通话的各种音段错误和缺陷的基本类型[4]。典型的声母错误包括: 1)将舌尖后音(翘舌音)读作舌尖前音(平舌音);2)将舌尖前音(平舌音)读作舌尖后音(翘舌音);3)将舌尖中鼻音读作舌尖中边音; 4)将舌尖中边音读作舌尖中鼻音。典型的韵母错误包括: 1)将后半高不圆唇元音e读作前中元音,或前半高元音; 2)忽略卷舌韵母er的卷舌; 3)舌尖前元音-i(前)没有保持单元音状态,明显向无元音的舌边滑动; 4)舌尖后元音-i(后)没有保持单元音的状态,明显向无元音的舌边滑动,同时含卷舌成分。
语音识别系统的目标是要将不同人的发音差别尽可能模糊掉,还原发音者想要表达的原文,但是系统受语言模型限制。普通话发音质量评价系统的目标是要对不同考生的发音差别尽可能准确地进行判断,并以此来评判考生发音的标准程度,因此,不能直接使用语音识别中的语言模型;但是系统可以借鉴语音识别中的语言模型思想,利用普通话测试中的语言学知识对算法的识别网络进行精简,即利用上述普通话常见声韵母发音错误情况来限制式(1)中对数分母的最大值计算范围。修改后的计算公式为
(3)
式(3)用音素qj的常见发音错误类型的模型集合Ej代替原来的全体声韵母模型集合M,即用语言学知识[3]指导的精简网络代替原来的全网络。
精简网络[1]是普通话测试专家在常见的语音错误和语音缺陷的基础上,进一步实例化得到。“中国”一词对应的声韵母识别网络如表2所示。

表2 词语“中国”的精简识别网络
3 基于优化概率空间的后验概率计算
普通话水平测试属于文本相关的发音质量评测,与语音识别中基于词图的后验概率有所区别。语音识别部分主要采用基于文本的切分方法,将考生的发音与标准文本强行对齐,得到由切分路径构成的简单识别网络,构成式(1)的分子。式(1)的分母则为由精简网络决定的解码网络。以“中国”为例,对应式(1)中的分子、分母识别网络如图2所示。
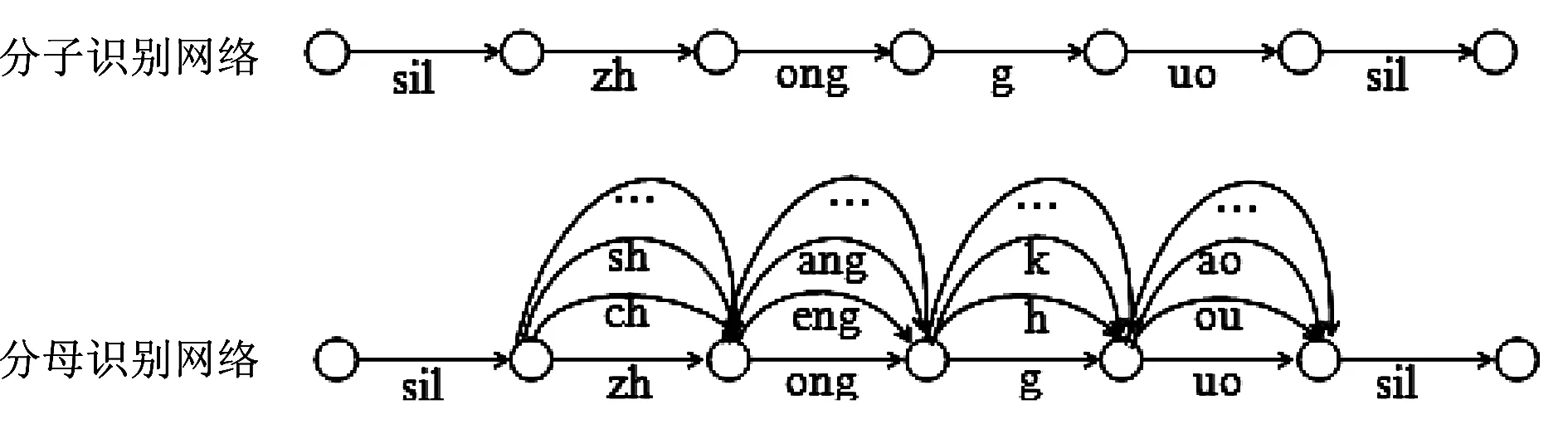
图2 高斯后验概率分子、分母识别网络
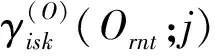
3.1 优化概率空间中弧后验概率计算
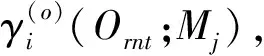
(4)
式(1)中基于分子识别网络的后验概率的计算公式为
(5)
3.2 优化概率空间中状态后验概率计算
在得到弧后验概率的计算结果后,状态后验概率、高斯后验概率的计算基本与语音识别一致。由于在指定弧下,利用Viterbi方法[5-7]得到的状态后验概率仅有0,1这2种值,因此,本文利用Viterbi算法计算状态后验概率。
先将式(1)中分子、分母识别网络中的每条弧切分至状态,再计算每帧的状态后验概率,如图3所示。其中,ong[1]描述发音‘ong’的HMM的第1个有效状态,ong[2]、ong[3]分别为第2、第3有效状态。由Viterbi算法切分的状态结果可知,在t时刻,状态ong[2]的后验概率为1,状态ong[1]、ong[3]的后验概率为0。
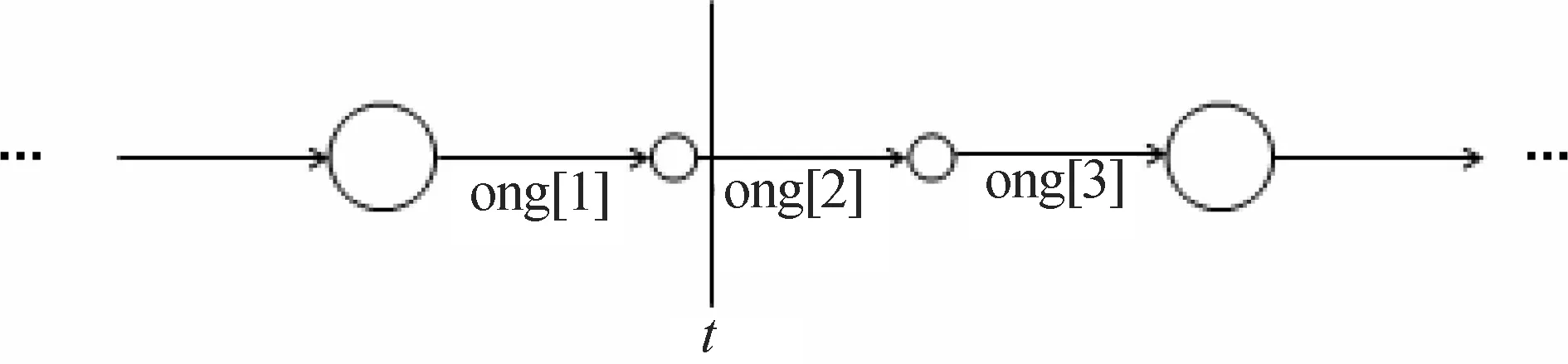
图3 Viterbi算法中的弧状态后验概率示意图
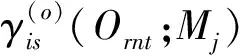
(6)
利用概率空间中各HMM对待测语音的声学特征Or,n进行解码。若弧i的第t帧状态为s,则St(i,s,Or,n)=1,否则St(i,s,Or,n)=0。
3.3 优化概率空间中高斯后验概率计算
在得到状态后验概率的计算结果后,指定状态下的高斯后验概率为当前高斯的加权似然度占所有高斯的加权似然度之和的比例。
分母的高斯后验概率计算公式为
(7)
分子的高斯后验概率计算公式为
(8)
其中

3.4 基于优化识别网络的算法流程
基于优化识别网络的语音评测算法的实现流程如图4所示。
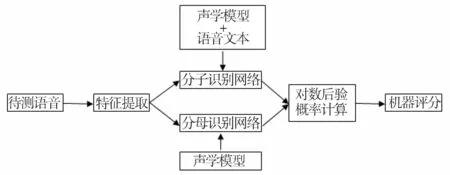
图4 优化识别网络语音评测算法流程
1)根据标准文本对考生语音进行语音识别,得到音素级识别结果。
2)根据考生的朗读文本将音素HMM模型拼接构成强制匹配的分子识别网络,同时生成一个无语法模型限制的音素循环识别网络。
3)按上述后验概率计算公式对音素和整个语流进行归整,得到考生的发音质量评价得分。
4 实验
4.1 实验配置
普通话水平测试系统评测单字朗读、双字词朗读以及篇章朗读3部分。实验主要采用英国剑桥大学的HTK工具包[8]作为研究测试平台,采用39维MFCC_0_D_A_Z声学特征作为训练参数,采用上下文无关的声韵母模型作为声学模型,共计67个HMM,包括声母、韵母、零声母、静音、短时停顿、填充模型,每种模型压缩至平均16高斯。
4.2 实验数据库
随着普通话水平智能测试的推广,全国各地的语音数据在数量上都有了极大的扩充。为保证实验结果的普遍性,从全国各地普通话测试中心选择有代表性的500份语音数据,共计约83 h,涵盖普通话水平测试大纲中的全部字、词、短文,每份数据都有专家的精细评分。
4.3 实验结果
由于机器评分与专家评分间的相关度体现了人机评分的一致程度,因此算法选择人机相关度作为评价系统性能的指标。人机相关度Corr计算公式为
(9)
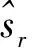
实验采用对比法,在全概率空间、典型错误概率空间分别考察后验概率对评分性能的影响。具体实验结果见表3。
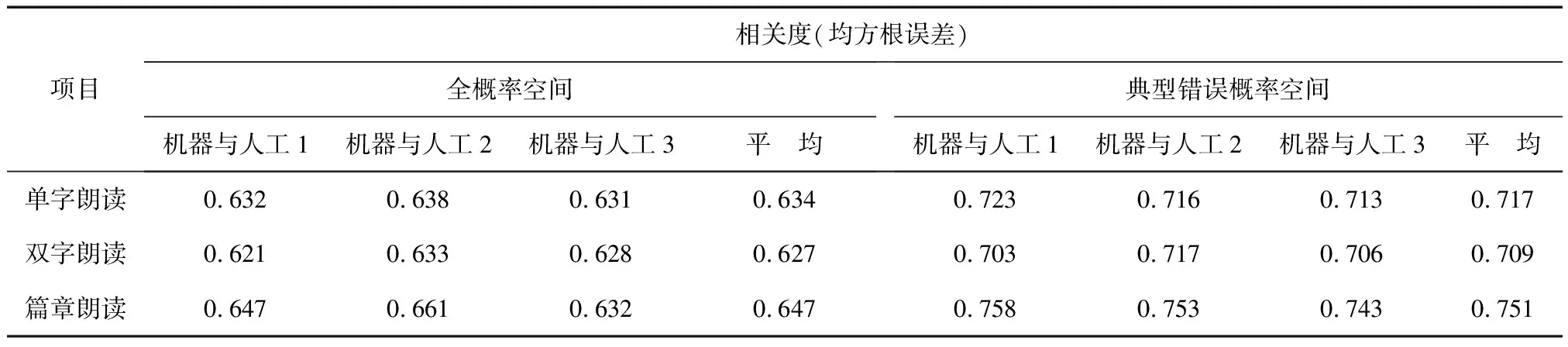
表3 不同概率空间中后验概率算法评分性能
5 实验结论
本文从普通话发音的角度,针对对数后验概率算法中各HMM模型之间混淆率较大的不足,借鉴语音识别中的语言模型思想,从普通话的语言知识出发对算法的识别网络进行简化,进一步优化算法的概率空间,同时结合发音空间对后验概率的计算进行研究。实验表明,概率空间的优化不仅能够提高系统评测模型的性能,同时由于概率空间音素个数远小于全音素概率空间,因此还能显著减少原有算法的运算量。
[1]WEI Si, LIU Qingsheng, HU Yu, et al. Automatic Mandarin Pronunciation Scoring for Native Learners with Dialect Accent [C] // Proceedings of Interspeech 2006. Pittsburgh, Pennsylvania: International Speech Communication Association, 2006: 1383-1386.
[2]Ge F P, Lu L, Yan Y H. Experimental Investigation of Mandarin Pronunciation Duality Assessment System[C] // International Symposium Computer Science and Society (ISCCS).Kota Kinabalu: [s.n.],2011:235-239.
[3]WANG Renhua, LIU Qingfeng, WEI Si. Putonghua Proficiency Test and Evaluation [M].[S.l.]:Advances in Chinese Spoken Language Processing,2006:407-429.
[4]宋欣桥.普通话水平测试员实用手册[M].北京:商务印书馆,2005:139-151.
[5]Liu Qingsheng, Si Wei, Yu Hu,et al. The Application of Phone Weight in Putonghua Pronunciation Quality Assessment [C]// The 5th International Symposium on Chinese Spoken Language Processing. Singapore :[s.n.],2006:603-608.
[6]Young S, Evermann G, Gales M. The Hidden Markov Model Toolkit [EB/OL]. (2005-10-20). http://htk.eng.cam.ac.uk/.
[7]Jang R. Audio Signal Processing and Recognition [EB/OL]. (2009-05-30). http://neural.cs.nthu.edu.tw/jang/books/audiSignalProcessing/.
[8] Young S , Kershaw D, Odell J , et al.The HTK Book :for HTK Version 3.0 [M]. Redmond :Microsoft Corporation, 2000:23-45.
