数据字典驱动的地质数据采集系统设计与开发
2014-08-25徐永龙郭海朋张像源陈文杰李晓亮
徐永龙,李 斌,郭海朋,张像源,陈文杰,李晓亮
(1.长安大学 地质工程与测绘学院,陕西 西安 710054;2.中国地质环境监测院,北京 100081;3.天津市地质调查研究院,天津 300191)
数据字典驱动的地质数据采集系统设计与开发
徐永龙1,李 斌1,郭海朋2,张像源3,陈文杰3,李晓亮1
(1.长安大学 地质工程与测绘学院,陕西 西安 710054;2.中国地质环境监测院,北京 100081;3.天津市地质调查研究院,天津 300191)
地质环境信息化中,地质数据采集入库系统需良好的可扩展性和复用性。设计开发一种由数据字典定制和驱动的地质数据采集系统,采用数据字典序列化与反序列化,解决系统录入界面的自动生成和数据库查询功能的动态实现等关键技术问题,并在汾渭盆地和华北平原等地区的实际应用中得到验证。数据字典驱动的地质数据采集系统开发周期短,易于维护,具有良好的可扩展性和通用性。
数据字典;地质环境信息化;数据采集系统;系统设计与开发
地质数据采集系统是将野外采集的地质环境相关数据进行标准化入库的工具,是侧重于地质专题属性数据录入的一种管理信息系统(MIS系统)。随着我国地质环境信息化工作的不断推进,许多地质环境监测业务部门开始使用数据采集系统,将所获取的地质环境数据采集入库,在提高工作效率的同时提升数据管理水平。但现有的数据采集系统延续了传统MIS系统的构建模式[1],将程序功能、用户界面与数据库表紧密耦合,导致其开发过程繁琐,可扩展性不强。在面对种类繁多、数据量大,且随着数据库表结构不断更新和扩充的地质环境数据时,这种设计模式的缺陷和弊端更为突出,具体表现为:在系统开发过程中,传统的数据采集系统为数据库中的每一张表格设计对应的录入界面,录入界面与特定的表结构、字段一一绑定,并且将所有的查询语句静态地封装在程序中,给开发人员带来大量重复、繁琐的工作,延长软件的开发周期;在系统应用过程中,当用户的数据库表结构发生改变或者需要新增数据表时,由于程序与数据库紧密耦合的构建模式导致系统不具备可扩展性,原有的系统无法复用,必须进行源码级的修改或重写,增加了系统应用和维护的成本。
由此可见,传统的数据采集系统迫切地需要引入新的开发方式,实现系统程序与底层数据的分离,以从根本上解决其扩展性问题,实现地质环境数据采集录入软件的复用。本文针对这一实际问题,在分析现有地质数据采集入库系统的局限与不足的基础上,设计可扩展且可复用的数据字典驱动的地质数据采集系统结构,并对其开发实现的若干关键技术进行探讨。
1 数据字典驱动的地质数据采集系统设计
1.1 系统总体结构
数据字典驱动的地质数据采集系统的总体结构如图1所示,与传统数据采集系统的程序与数据层紧密绑定不同,它将数据字典从数据层抽象出来单独作为一层,位于底层的用户数据库之上,把系统的应用程序和数据库分离开来[2-3]。应用程序中的数据字典驱动模块负责程序与数据字典的通信,向程序提供数据字典中的数据库及表结构等信息,从而实现系统用户界面(录入界面和查询界面)的自动生成及系统功能模块中查询语句(对数据库的增、删、改、查等操作)的动态构建,这就从底层根本性地解决了传统数据采集系统的开发过分依赖数据库表结构的问题。同时,数据字典位于应用程序外部字典库,处于开放的环境中,当用户的数据库表结构发生改变或者需要新增数据表时,可由系统管理人员对数据字典作相应的修改或扩充,应用程序本身则无需变动,由此实现系统的扩展,进而达到系统复用的目的。

图1 数据字典驱动的地质数据采集系统总体结构
1.2 数据字典设计
数据字典是地质数据采集系统的核心,是连接系统应用程序与数据库的纽带。数据字典由多个数据表(字典表)组成,这些表记录了数据库表的全部信息[4-5],包括表、字段及表间约束等信息。字典表以二维表的形式独立存储于系统外部的数据字典库中,其存储结构较为灵活,根据特定的需求而定。数据字典在系统中起到为系统运行提供支撑信息的作用,系统根据数据字典表内容创建数据库表、动态生成录入界面并创建查询语句,这是数据字典设计的要点和依据。为便于更新和维护,本文将满足地质数据采集系统使用的最基本信息汇总在一张字典表中,其表结构如表1所示,该数据字典表结构由22个字段组成,主要反映3方面的内容:①表的基本信息,如表名、表代码、表所属专业类型等;②表的约束信息,如表的主键、外键、父表名称等;③表的字段信息,如字段名称、数据类型、字段长度、重要程度、取值范围等。

表1 地质数据采集系统数据字典表结构设计
需要说明的是,尽管数据字典表的表结构是动态的,可以根据具体情况进行修改,但其具体内容的填写应该遵循地质环境信息化相关标准和规范[6-7],以保证地质环境数据管理的标准化。数据字典表结构建立后,用户只需按照其结构填写要采集录入的数据表的相关信息,即使在使用过程中表结构发生了变化,也只需在数据字典表中作相应的修改即可。
2 系统实现的关键技术
传统数据采集系统界面和功能都与数据表结构静态绑定的实现方式不同,数据字典驱动的数据采集系统的用户界面和程序功能都是根据数据字典动态实现的,以保证数据采集系统的可扩展性和通用性。通过深入研究,本文解决其动态实现过程中的3个关键技术问题。
2.1 数据字典表序列化与反序列化
序列化是将程序中的对象转化为字节序列存储到计算机文件的过程,反序列化是序列化的逆向过程。由于程序在运行过程中需要实时查询数据字典库,获取其中字典表的信息,而这样频繁的实时查询会导致系统效率的降低和性能的下降。出于系统效率和性能考虑,在系统首次运行时,将数据字典表中的数据库表结构信息一次性查询出来,转化为相应的表结构对象,再序列化为用户计算机中的一系列XML文档。每个XML文档分别存储一个数据表的相关信息,包括表名称、代码、主键,以及该表所有字段的信息;系统在随后的运行中,通过反序列化指定的XML文档获取其中的表结构对象,不必再查询数据字典库。实践表明,应用程序反序列化本地XML文档来获取数据表结构对象的效率要优于实时查询数据字典表的效率。
数据字典序列化与反序列化在数据字典驱动模块中实现,其中较为关键的一步是组织好表结构对象的数据结构。合理地组织该数据结构,便于数据库表结构相关信息的提取,从而有利于程序界面和功能的实现。本文给出数据表结构对象(TableInfo)及其中包含的字段信息(FieldInfo)的数据结构,其类图如图2所示。在.NET平台中,将对象序列化为XML文档及其反序列化可利用XmlSerializer类中的相关功能来实现,其他编程平台也提供类似的方法,具体实现细节在此不作详述。
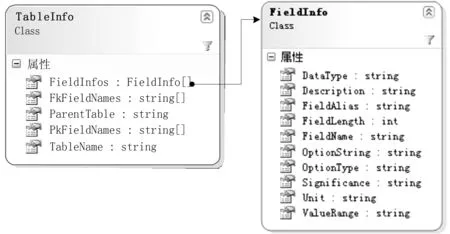
图2 数据表结构TableInfo对象的数据结构
2.2 录入界面的自动生成
录入界面的自动生成是指数据采集系统运行时,根据数据字典驱动模块提供的数据表字段信息,自动调用相应的录入控件来搭建录入表单界面。自动生成录入界面不仅免除了在界面设计阶段为所有数据表逐一设计录入表单界面的大量繁琐工作[8],也使系统具备了可扩展和复用的条件。
自动生成录入界面的技术流程如图3所示。通过反序列化XML文档获取指定数据表的结构信息TableInfo对象(其结构见图2);再遍历TableInfo对象中的包含该表所有字段信息的FieldInfos属性,获取每个字段信息FieldInfo对象的数据类型DataType属性;根据字段的数据类型实例化对应的录入控件(例如,文本型字段使用文本框输入控件,数值型字段使用整数或小数输入控件),并将录入控件加载到录入界面容器中进行显示,直到加载完所有字段对应的录入控件为止。从该实现流程可以看出,录入界面中数据项的顺序和FieldInfos中字段信息FieldInfo对象的顺序是对应的,因此,在系统运行过程中,可以调整FieldInfo的顺序以改变录入界面中数据项的顺序,实现录入界面数据项顺序的定制。

图3 自动生成录入界面的流程
2.3 查询语句的动态创建
数据库系统对数据库的操作,如查询、新增、修改、删除等,都是通过标准的查询语句(即SQL语句)实现。传统的数据采集系统无法扩展的一个重要原因就在于,它的查询语句都是与特定的表结构、字段绑定,静态地写入程序中[9]。动态创建查询语句的基本思路是:在系统运行过程中,根据用户要执行的操作,通过序列化获取操作对象表的字段信息,动态地组合出查询语句并执行该语句的操作[10-13]。在数据采集系统中,最常用操作是在数据库中新增一条数据的INSERT操作。相比删(DELETE)、改(UPDATE)、查(SELECT)等操作语句的构建,INSERT操作语句的动态创建较为复杂。本文以INSERT操作语句的创建过程为例对查询语句的动态创建进行说明。
如式(1)所示,一条标准的INSERT操作的SQL语句由4部分组成,包括INSERT INTO关键字、表名(table_name)、字段名(field1,field2,…)以及与字段名对应的字段值(value1,value2,…)。
INSERT INTO table_name (field1, field2, …) VALUES ( value1, value2, …)
(1)
动态创建查询语句,就是要动态地获取式(1)中各组成部分的实际取值过程,具体步骤如下:
1)根据用户要操作的数据表获取表名,替代式(1)中的table_name;
2)根据表名反序列化相应的数据表结构XML文档,获取表结构对象TableInfo,通过其FieldInfos属性获取该表的所有字段名称,替代式(1)中的field1,field2,…;
3)根据字段名称,获取录入界面中对应的录入控件中的值,赋给式(1)中的value1, value2, …即可。
3 系统实现与应用
数据字典驱动的地质数据采集系统的设计思想及其实现技术已被应用于全国地面沉降数据采集系统的开发。该系统是在.NET平台中采用CJHJ语言开发完成,其界面如图4所示。
系统数据字典涵盖了地面沉降灾害相关的多种专业领域的数据表信息,具有数据录入与修改、查询显示、导入导出、数据库备份与恢复以及用户界面定制等数据采集入库相关的实用功能。经测试和试用表明,数据字典驱动的全国地面沉降数据采集系统具有便于扩展、简洁易用等特点。目前,系统作为地面沉降相关调查与监测数据标准化入库和规范化管理的实用工具,已在我国地面沉降灾害较为严重的汾渭盆地、华北平原等地区的地质环境监测相关业务单位推广使用。

图4 全国地面沉降数据采集系统主界面
4 结束语
数据字典驱动式的设计模式实现了应用程序开发与数据库表结构分离的开发方式,提升软件开发的效率,缩短软件的开发周期,同时实现软件的复用。实际应用表明,较传统数据采集系统而言,数据字典驱动的地质数据采集系统具有以下特点:
1) 以数据字典为核心,系统数据库及数据表由系统根据数据字典自动生成,数据表及表间关系的维护由系统自动完成,无需人为干预;
2) 系统的数据录入界面根据数据字典动态生成,不受数据库表结构变化的限制,并可按照用户使用习惯进行界面定制;
3) 系统具有良好的扩展性和通用性。数据库表结构发生变化时,只需在数据字典中作相应的更新,系统程序无需修改,便于维护和通用。
[1]王德广,张军卒,李文. 基于数据字典的通用查询平台的设计[J]. 科学技术与工程, 2009, 9(19): 5849-5853.
[2]郭胜辉,孙玉芳. 基于数据字典库的信息系统的设计[J]. 计算机学报,2000, 23(4): 414-418.
[3]曾青石,张像源,陈辉. 基于3S技术的地质灾害野外调查数字采集系统的研究[J]. 水文地质工程地质,2008(1): 121-125.
[4]韩志军,汪兴庆,吴冲龙. 野外数据采集系统数据字典的研制[J]. 地球科学—中国地质大学学报,1999, 24(5): 539-541.
[5]D PANTAZIS, B CORNELIS, R BILLEN, et al. Establishment of a geographic data dictionary: a case study of UrbIS 2, the Brussels regional government GIS[J]. Computers, Environment and Urban Systems, 2002, 26(1): 3-17.
[6]中华人民共和国国家质量监督检验检疫局,中国国家标准化管理委员会.GB/T 9649.20-2009 地质矿产术语分类代码表—水文地质学[S].北京:中国标准出版社,2009.
[7]中华人民共和国国家质量监督检验检疫局,中国国家标准化管理委员会.GB/T 9649.21-2009 地质矿产术语分类代码表—工程地质学[S].北京:中国标准出版社,2009.
[8]梁伟晟,李磊. 基于表单的业务系统界面逻辑模型获取的研究[J]. 计算机工程,2007, 33(5): 56-58.
[9]何珍文,吴冲龙,张夏林,等. 数据库应用程序中通用动态查询实现方法研究[J]. 计算机工程,2002, 28(11): 92-94.
[10]张像源,曾青石,陈辉. 地质灾害野外调查数据采集系统数据模型研究[J]. 水文地质工程地质,2007(5): 98-101.
[11]Tr?tteberg H. Model-based user interface design[D]. Trondheim: Norwegian University of Science and Technology, 2002.
[12]郭范春. 基础地理信息数据库管理系统的研建[J]. 测绘工程,2013, 22(3): 80-82.
[13]王明孝,张之孔.基于组合模型的高程拟合方法及精度分析[J].测绘工程,2013,22(2):1-4.
[责任编辑:张德福]
Design and development of data-dictionary-driven geo-environment data acquisition system
XU Yong-long1, LI Bin1, GUO Hai-peng2, ZHANG Xiang-yuan3, CHEN Wen-jie3, LI Xiao-liang1
(1.College of Geological Engineering and Geomatics, Chang’an University, Xian 710054, China; 2.China Institute of Geo-Environment Monitoring, Beijing 100081, China; 3.Tianjin Institute of Geological Survey, Tianjin 300191, China)
Aiming at the extensibility and reuse problems in current geo-environment data acquisition systems, it designs and develops a data dictionary driven geo-environment data acquisition system with the data-dictionary serialization and deserialization used to generate the user interface automatically and implement the function dynamically. The system is verified through its application to Fen-wei Basin and North China Plain areas. The data-dictionary driven geo-environment data acquisition system decreases the development cycle, which is easy to maintain with good extensibility and universality.
data dictionary; geo-environment informatization; data acquisition system; system design and development
2013-11-06
国家自然科学基金重点项目(41130753); 全国地面沉降监测与防治综合研究与信息系统建设工作项目(12120113011700); 中央高校基本科研业务费专项资金资助项目(CHD2011TD019)
徐永龙(1985-),男,博士研究生.
TP311
:A
:1006-7949(2014)10-0041-04
