云存储系统的能耗优化节点管理方法*
2014-08-16林伟伟贺品嘉刘波
林伟伟 贺品嘉 刘波
(1.华南理工大学 计算机科学与工程学院,广东 广州 510006;2.华南师范大学 计算机学院,广东 广州 510631)
数字信息的爆炸性增长催生了海量数据存储的需求,使得存储系统成为以数据为中心的现代计算机系统的最重要组成部分之一.日益增大的数据存储规模与以CPU 为代表的计算部件和以磁盘为代表的外存储部件之间日趋扩大的性能差异,使得存储系统的性能提升和能耗降低成为整个计算机系统性能提升和能耗降低的关键.统计数据显示,对于一个典型的数据中心来说,存储系统的能耗占数据中心总能耗的27%[1],而每年以60%的速度递增的数据存储需求使得存储系统能耗占整个计算机系统能耗的比例在未来数年内持续增加.在当今的信息系统能源消耗中,计算资源消耗与存储资源消耗排在前两位.而由于全球数据量的指数级增长等原因,存储资源消耗很有可能在未来超过计算资源消耗,成为消耗最多的信息系统能源.因此,研究如何节省分布式集群系统中的存储能源消耗乃是重中之重的问题.
在云对外提供的服务中,云存储服务[2-4]正受到越来越多研究人员的关注.绿色计算已成为最受关注的研究热点之一,尤其是随着云计算[5]、物联网和移动互联网的快速发展以及数据中心的大量新建,能耗问题越来越严重.云存储子系统的能耗占据了计算机系统总能耗的较大部分.因此,有效降低云存储系统的能耗是降低云数据中心总成本的主要手段之一.
利用冗余是一种节约能源的方法,如访问转移(DIV)[6]的方法就使用了副本,这种方法提倡把所有数据项的第1 份拷贝存储在一部分磁盘上,以达到节约能源的目的,但这种方法可能会降低系统在全功率模式下的性能.针对大规模闲置磁盘阵列(MAID)系统中的能源节约问题,EERAID[7]、RIMAC[8]和PARAID[9]利用了冗余技术,但其解决方案仅适用于编码有限的磁盘的情况,而不适用于冗余文件广泛分布在系统中的情况.Greenan 等[10]在一些特殊的纠删码类中利用了冗余技术.在低能耗模式中,通常可以关闭部分存储节点.有许多方法可以让磁盘更长时间地处于闲置状态,避免它们停止转动.MAID[11]使用高速缓存磁盘来存储最近被读到的数据.流热点数据集中技术(PDC)[12]把经常被读取的数据集中在一起.Hibernator 能根据数据的活跃程度,把几种速度不同的磁盘与数据不同的集合组合对应起来,以节省能源[1].
能耗已成为当前云计算和云存储研究最关注的问题之一[13].文献[14]对现有云计算中的能耗进行了综合分析和讨论,指出云计算中的数据传输与数据处理、数据存储一样,可能会消耗大量的能源;并指出用户在个人计算机上执行计算可能比在云上执行计算消耗更多的能源.王意洁等[15]通过建立比例模型和两段模型来改进Hadoop 集群的能耗效率.雷成军等[16]提出了集群自主管理的架构,通过传感器将数据整合到计算进程,并通过这些数据对云计算集群的物理现象进行建模,最终在权衡系统性能和工作负载的基础上降低集群的整体能耗.
为减少云存储系统的能耗,文中考虑在云存储系统利用率较低时(例如晚上或周末)关闭部分存储节点.然而,关闭部分节点的前提是保证集群中的所有数据项可用.在云存储系统(如Hadoop 的分布式文件系统HDFS)中,每个数据项均有r 个副本,因此,在云存储系统使用率较低时,可以通过关闭部分存储节点来减少系统能耗,但要求这个关闭节点集合中不能包含某个数据项的所有副本,否则会导致这个数据项失效.为此,针对如何选择云存储系统中可以关闭的节点集合问题,文中设计实现了基于辅助节点的贪心算法,并针对异构云存储系统的能耗优化问题,提出了改进的贪心算法,以降低云存储系统的能耗.
1 云存储系统的能耗优化数据管理问题描述
云存储系统通过分布式存储来实现其可扩展性,通过冗余存储来确保数据的可靠性.为方便描述,设r 为云存储系统的重复因子(即云存储系统中每个数据项冗余存储的份数或副本的个数),M 为云存储系统中的存储节点数,N 为系统中数据项的个数,p 为关闭节点集合中的节点数占总节点数的比例.文中按照使用率高低将云存储系统分为全能耗模式(如白天)和低能耗模式(如夜晚)两种.为节约能源,文中考虑在系统的使用率降低时关闭一部分存储节点.设E 为能源节约率,即低能耗模式下节省的能耗占全能耗模式下能耗的百分比,该值越大表示算法的节能效果越好.
由于通过关闭部分云存储节点实现能耗优化的方法要保证整个系统的可用性(每个文件或数据可访问性),故要保证每个数据项至少有一个副本依然可用,即每个数据项至少有一个副本所在的存储节点未被关闭.一种简单的方法是修改数据分配函数,以达到最佳的节能效果,如把所有数据项的第一个副本存放在选定的存储节点集合中,其余副本随机分配在剩余的节点上;在低能耗模式下,仅开启存有所有数据项第1 个副本的存储节点集合.但系统在全能耗模式下(白天)时,此方法很可能会降低数据的访问性能.因此,在不改动分配函数的前提下,应选出一个关闭节点集合.
在云存储系统中寻找可关闭节点的问题可抽象为一个图的覆盖问题,其评判的标准是剩余的节点要覆盖尽可能多的数据项(至少保存该数据项的一个拷贝).此覆盖问题的输入是一个二部图[17],图中左边有M 个节点(代表系统中的存储节点),右边有N 个节点(代表系统中的数据项),右边的每个数据项(节点)与左边的存储节点有r 条相邻的边(代表该数据项在存储节点上有r 个拷贝).对一个给定的比例p(0 <p <100%),寻找一个节点数为Mp的节点子集,使剩余节点覆盖的数据项数最大化.若一个数据项节点与存储节点有相连边,则称此数据项被覆盖了.文中的优化目标是在给定一个图和最大化关闭存储节点比例p 的情况下,最小化未被覆盖到数据项的节点数.
若一个数据放置方案覆盖了所有的数据项,则称此方案实现了对数据的全覆盖.文中主要讨论寻找图的最佳覆盖(即超图中的点覆盖)问题,这是一个计算复杂而且困难的问题.为此,考虑一个有M顶点(每个顶点代表系统中的一个节点)的超图,共有N 条超边,每条超边连接d 个顶点(超边代表数据项,超边连接着所有存放该数据项的节点).解决此覆盖问题等价于寻找一个节点的子集,使该超图在其子集中节点数尽量小的情况下相连的边尽可能多.当重复度为2 时,此覆盖问题可转化为经典的点覆盖问题(Karp[18]的21 个原始非确定性的多项式问题(NP)之一).因为在分布式存储系统中,数据项经常发生改变,在全能耗模式下使用时,经常有数据项的增加与删除操作,所以针对某个特定数据项集的分布情况求出的最优解,并不会一直适用.而当数据项的分布情况发生改变时,原先的最优解往往也会变成一个较优解,故求最优解没有实际意义.加上求出最优解需要较长的计算时间,较优解足以达到节约能耗的目的,故文中采用启发式算法来寻求一些比较好的覆盖.
2 算法设计
2.1 一般贪心算法
一般贪心算法(算法1)的核心思想是在每次迭代过程中取局部最优解,以使最后结果为全局较优解.能耗优化的目标是使节约的能源最大化,即在低能耗模式下关闭节点的集合达到最大值.在集群数据项总数一定的情况下,关闭节点上的数据项越少,则关闭节点的集合越大.因此,可以先根据节点上的数据项数对节点进行排序(从小到大),再对排好序的vector(节点的抽象数据结构)进行迭代.
一般贪心算法的输入为存储节点集合、数据项节点集合、数据项的重复因子和每个存储节点的能耗,输出为关闭节点集合中的存储节点数与使用该算法所节约的能源量,具体的算法步骤如下:①对两个vector(这两个vector 分别抽象存储节点集合与数据项集合)进行初始化;②将每个数据项随机分配到该整数对应的存储节点上;③调用C ++标准模板库STL 的sort 函数,根据存储节点上的数据项数对存储节点进行排序(从小到大);④从所存放数据项最少的存储节点开始遍历,将节点放入关闭节点集合中,直到有一个数据项没有一个副本存放在未关闭的存储节点上为止;⑤输出关闭节点集合,并据此计算出系统节约的能源量.该算法的伪代码描述如下:

分析最坏情况下贪心算法的复杂度.对有N 个数据项(每个数据项有r 个副本)与M 个存储节点的系统,预先设定关闭节点集的节点数占总节点数的比例为c(以下实验皆同),则算法初始化所有存储节点的时间复杂度为O(M),初始化所有数据项的时间复杂度为O(N),使用随机分配函数对数据项(共有rN 个数据副本)进行分配的时间复杂度为O(rN),根据存储节点上的数据项数对存储节点进行排序的时间复杂度为O(Mlog2M),最坏情况下遍历完所有节点的时间复杂度为O(MN).一般来说M>N,故贪心算法的时间复杂度为O(M + N + M +rN + M + Mlog2M + cMN)≈O(M2).
由此算法可获得可关闭节点的集合,但当数据项不是特别小(如数据项数与节点数的比值为10)时,由此算法求出的可关闭节点集合十分小;当数据项数与节点数的比值较大时,某数据项的所有副本均在被选出的即将关闭的节点集合中.因此,单纯采用贪心算法求出低能耗模式下可关闭节点的集合将十分小.当然这与数据的重复度(即每个数据项的副本数量)有关.为此,文中提出了一种基于辅助节点的贪心算法.
2.2 基于辅助节点的贪心算法
在贪心算法的迭代过程中,若有任一数据项的所有副本存放在所选关闭节点集合中,则停止迭代,这会导致迭代过程较早地停止,因为系统中的数据项一般为(或近似为)随机分配.为此,文中向系统中添加一定的辅助存储节点,即新增专门用来存储在低能耗模式下失效的数据项的节点,以改进算法的节能效果.在物理构造与存储能力上,辅助节点与系统中其他节点一样,区别在于其在整个分布式存储系统中扮演的角色不同.
基于辅助节点的贪心算法(算法2)的输入为存储节点集合、数据项节点集合、数据项的重复因子、预先设定的关闭节点集合中的节点数占总节点数的比例和每个存储节点所消耗的能源,输出为所需要的辅助节点数与使用该算法所节约的能源量.该算法的大部分步骤与2.1 节中的贪心算法类似.在初始化并分配好数据项后,采用与2.1 节相同的方法进行排序;然后,从存储节点vector 中的第一个存储节点开始遍历,将节点归入关闭节点集合中,直到关闭节点集合中的节点数与总节点数的比例与预先设定值p 相等为止;最后,输出关闭节点集合、所需要的辅助节点数与系统所节约的能源量.该算法的伪代码描述如下:
{输入:nodevector,datavector,r,p,energy
输出:Number of auxiliary storage nodes and save_energy

分析最坏情况下基于辅助节点的贪心算法的复杂度.此算法与2.1 中的贪心算法类似.排序后,需要遍历cM 个存储节点上的所有数据项,故时间复杂度为O(cMN).一般来说,M>N,故此算法的时间复杂度为O(n2).
2.3 面向异构系统能耗优化的改进贪心算法
前面提出的贪心算法和基于辅助节点的贪心算法主要适用于同构系统(即由同一种节点构成,其存储容量、计算能力、能耗等均相同).但现实中常有异构的分布式存储系统.为优化异构云存储系统的能耗,文中提出了面向异构云存储系统能耗优化的改进贪心算法(算法3),用于计算关闭节点集合和节省的能耗.为简化问题,文中只讨论各节点能耗不同的情况,即假设集群中的节点有几种不同的能耗.这样,在考虑云存储数据管理的能耗优化问题时,就不能仅仅考虑存储节点上的数据项数,还应考虑该节点的能耗.若只考虑存储节点上的数据项数,则可能出现关闭节点上的数据项数虽少但其耗能是低的情况,从而造成节省的能耗并不高的结果.
在同构系统中,能耗的计算仅需考虑使用贪心算法存储数据项所需要的存储节点数.而在异构系统中,还需要考虑不同存储节点的能耗.为此,文中引入计算能耗因子的函数f(x,y)=ax- by,其中x为节点上的数据项数,y 为节点的能耗(初始化时赋予).通过调整a 和b 值可使系统的能耗趋向最少.通过反复实验最终确定a 和b 的取值分别为1.0 和30.0.
面向异构云存储系统能耗优化的改进贪心算法的输入为存储节点集合、数据项节点集合、数据项的重复因子、预先设定的关闭节点集合中的节点数占总节点数的比例和两个用于计算rank 值的参数,输出为所需要的辅助节点数与使用该算法所节约的能源量.该算法的具体步骤如下:①初始化两个vector(用于抽象存储节点集合与数据项集合);②遍历每个数据项节点,并将该数据项分配到随机的某个存储节点上;③调用C ++标准模板库STL 的sort 函数,根据存储节点的rank 值(由存储节点的能耗与存储节点上的数据项数共同决定)对存储节点进行排序;④从rank 值最小的存储节点开始遍历,将节点归入关闭节点集合中,直至关闭节点集合中的节点数与总节点数的比例与预先设定值相等为止;⑤输出关闭节点集合、所需要的辅助节点数与系统所节约的能源量.算法的伪代码描述如下:

分析最坏情况下算法的复杂度.本算法与基于辅助节点的贪心算法类似,不同之处在于:①要初始化所有存储节点的能耗参数,其时间复杂度为O(M);②数据分配完成后,需要计算出每个节点的评价值,其时间复杂度为O(M).故整个算法的时间复杂度为O(M2).
3 实验结果与分析
为验证文中算法的有效性,在CPU 为3.0 GHz、内存为2 GB、硬盘为120 GB 的个人计算机上进行模拟实验.在Visual Studio 2010 环境下采用C ++开发算法程序,存储节点和数据项分别采用nodeitem类和dataitem 类来模拟,nodeitem 类的数据成员包含一个vector 与几个保存存储节点状态的变量.数据项与存储节点类似,包含一个定长的数组与一些保存数据节点状态的变量,其中定长数组的长度由一个宏变量确定,以方便修改.存储节点集合与数据项集合皆用数组来模拟,实验中可根据需要改变集合的大小,以研究算法在不同数据项数下的能耗优化效果.实验中对每个数据项的每一副本,生成一个一定范围内(由存储节点数确定)的随机数,并根据该随机数来分配数据项的副本,将分配信息同时保存在数据项与存储节点所对应的数据结构中.
由于文中研究的算法是离线的,而且提出的算法主要是计算低能耗(低功率)模式下的关闭节点集合,而低功率模式下系统访问数据比较少,基本上不会影响云存储系统的性能.因此,文中模拟实验主要分析算法对系统能耗的改进.
实验1 采用贪心算法进行实验,存储节点数固定为1000,重复因子r=3,通过改变数据项数来考察数据项数与存储节点数的比值k 对关闭节点集合选取(即关闭节点数C)的影响,取10 次实验结果的平均值作为最终实验结果(以下实验皆同),如图1 所示.
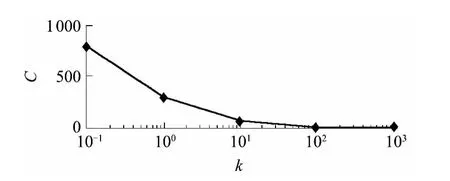
图1 贪心算法的关闭节点数与数据项数的关系Fig.1 Relationship between number of close nodes and data items in the greedy algorithm
由图1 可见:在数据项数比较小时,贪心算法的能耗优化效果较好;随着数据项数的增大,贪心算法的能耗优化效果变得越差;在数据项数与存储节点数的比值较大时,算法求出的可关闭节点集合较小.例如,在数据项数与存储节点数的比值为10 时,所求出的可关闭节点集合中只有70 多个节点,即只能节约7%的能源量.
综合以上讨论知道,在使用随机分配函数或一致性哈希函数的分布式存储系统中,单纯使用贪心算法来求解可关闭的节点集合时,算法的能耗优化效果较差.只有在数据项分布十分稀疏(如数据项数与存储节点数的比值为10-1)时,低能耗模式下节约的能源量才比较可观(为78.17%);若数据项数与存储节点数的比值比较大(如为100),则低能耗模式下节约的能源量可能不及10%.
贪心算法的能耗优化效果较差,其原因在于数据项在存储节点中是近乎于随机分配的,故在选取可关闭节点集合时,很容易把一个数据项的所有副本均包含进去,此时算法会停止迭代,从而导致算法求出的可关闭节点集合很小.
实验2 假设每个辅助节点可存储3 000 个数据项,存储节点数固定为1 000,关闭节点集合中的节点数占总节点数的比例p=60%,重复因子r=3,通过改变数据项数来考察数据项数与存储节点数的比值对能耗优化效果的影响,结果如表1 所示.

表1 两种贪心算法的能耗优化效果对比Table 1 Comparison of energy saving results of two greedy algorithms
从表1 可知,在添加了辅助节点后,系统在低能耗模式下可节约的能源量大大增加.当然,这里尚未考虑添加辅助节点本身所带来的成本.不过从节能的角度考虑,适当增加少量服务器应该是可以接受的,例如辅助节点数为原节点数的10%以下时是可以接受的.在实验中,当重复因子为3、数据项数为106时,仅需要添加69 个辅助节点(6.9%)便可以使系统在低能耗模式下节约近60%的能源量,这个数值是十分可观的.
接着,在存储节点数固定为1 000、重复因子为3、数据项数为106的情况下,通过设定不同的p(分别为20%、40%、60%和80%)来计算使用基于辅助节点的贪心算法所需添加的辅助节点数.实验结果显示:所设定的关闭节点集合越大,所需增加的辅助节点越多;在p 增大到某一值时,增加辅助节点所带来的能耗优化效果大大减少.在p=80%时,估计可节约的能源量为80%,但由于增加的辅助节点较多,故实际节约的能源量仅为68.55%,且系统关闭80%的节点时需要添加16.7%的辅助节点,成本太高.因此,若采取添加辅助节点的方法,则所设定的关闭节点集合的比例不能太大,p=60%时能取得较好的能耗优化效果.
实验3 设置存储节点数为90,数据项数为9 ×104,重复因子为3,将存储节点等分为3 份(其节点集合的能耗参数分别为2、4 和6,辅助节点的能耗参数为4),每份中的30 个节点具有相同的能耗参数,使用随机分配函数把数据分配到90 个节点上,通过设定不同的p(分别为20%、40%、60% 和80%)并采用面向异构系统能耗优化的改进贪心算法和基于辅助节点的贪心算法进行实验,所需能耗和添加的辅助节点数如表2 所示.其中能耗值是低能耗模式下运行节点的能耗加上辅助节点的能耗,该能耗值越小,表明算法的能耗优化效果越好.

表2 两种贪心算法所需能耗和添加的辅助节点数对比Table 2 Comparison of required energy and auxiliary nodes of two greedy algorithms
由表2 可知:与使用基于辅助节点的贪心算法相比,使用面向异构系统能耗优化的改进贪心算法的分布式存储系统在低能耗模式下所需的能源有所降低,能耗减少最多达24.69%;两种算法所需添加的辅助节点数十分接近,这说明使用这两种算法时,为系统添加辅助节点的成本是相同的.综合上述实验结果可知,面向异构系统能耗优化的改进贪心算法的性能优于不考虑异构情况的贪心算法.在管理由异构节点组成的分布式存储系统时,不但要考虑存储在节点上的数据项数,还要考虑节点本身的能耗.若某节点的能耗特别大,则优先考虑关闭该节点.
4 结语
为节省云存储系统的能耗,文中研究了云存储系统的节点管理方法,即考虑在系统的低能耗模式(如夜晚)下关闭部分节点以达到节约能源的目的.但在关闭部分节点时,必须保证所有的数据项依然可用,这就要求从存储节点集合中选出一个关闭节点集合,使某数据项的所有副本尽可能少地出现在该集合中.为此,文中设计了不同的算法并进行实验.结果表明,与基于辅助节点的贪心算法相比,面向异构系统能耗优化的改进贪心算法的能耗优化效果更好,在所需辅助节点数几乎一样的情况下,系统所节约的能源超过10%.
今后将在开源Hadoop 平台上实现文中提出的算法,并在实际应用中验证和改进提出的能耗优化算法.
[1]Zhu Q,Chen Z,Tan L,et al.Hibernator:helping disk arrays sleep through the winter[C]∥Proceedings of the 20th ACM Symposium on Operating Systems Principles.Brighton:ACM,2005:177-190.
[2]Bowers K D,Juels A,Oprea A.HAIL:a high-availability and integrity layer for cloud storage[C]∥Proceedings of the 16th ACM Conference on Computer and Communications Security.New York:ACM,2009:187-198.
[3]林伟伟,刘波.基于动态带宽分配的Hadoop 数据负载均衡方法[J].华南理工大学学报:自然科学版,2012,40(9):42-47.Lin Wei-wei,Liu Bo.Hadoop data load balancing method based on dynamic bandwidth allocation [J].Journal of South China University of Technology:Natural Science Edition,2012,40(9):42-47.
[4]吴吉义,傅建庆,平玲娣,等.一种对等结构的云存储系统研究[J].电子学报,2011,38(5):1100-1107.Wu Ji-yi,Fu Jian-qing,Ping Ling-di,et al.Study on the P2P cloud storage system[J].Acta Electronica Sinica,2011,38(5):1100-1107.
[5]Buyya R,Yeo C S,Venugopal S.Market oriented cloud computing:vision,hype,and reality for delivering IT services as computing utilities[C]∥Proceedings of the 9th IEEE/ACM International Symposium on Cluster Computing and the Grid.Washington D C:IEEE,2008:5-13.
[6]Pinheiro E,Bianchini R,Dubnicki C.Exploiting redundancy to conserve energy in storage systems[C]∥Proceedings of SIGMETRICS'06.New York:ACM,2006:15-26.
[7]Li Dong,Wang Jun.EERAID:energy efficient redundant and inexpensive disk array[C]∥Proceedings of the 11th Workshop on ACM SIGOPS European Workshop.New York:ACM,2004:29/1-6.
[8]Yao X,Wang J.Rimac:a novel redundancy-based hierarchical cache architecture for energy efficient,high performance storage[C]∥Proceedings of EuroSys'06.New York:ACM,2006:249-262.
[9]Weddle C,Oldham M,Qian J,et al.Paraid:a gear-shifting power-aware raid [J].ACM Transactions on Storage,2007,3(3):13/1-33.
[10]Greenan K,Long D,Miller E,et al.A spin-up saved is energy earned:achieving power-efficient,erasure-coded storage[C]∥Proceedings of the Fourth Conference on Hot Topics in System Dependability.Berkeley:USENIX Association,2008:4-9.
[11]Colarelli D,Grunwald D.Massive arrays of idle disks for storage archives [C]∥Proceedings of Supercomputing 2002.Los Alamitos:IEEE,2002:1-11.
[12]Pinheiro E,Bianchini R.Conservation technique for disk array-based servers[C]∥Proceedings of ICS'04.New York:ACM,2004:68-78.
[13]林伟伟,齐德昱.云计算资源调度研究综述[J].计算机科学,2012,39(10):1-6.Lin Wei-wei,Qi De-yu.Survey of resource scheduling in cloud computing[J].Computer Science,2012,39(10):1-6.
[14]Baliga J,Ayre R W A,Hinton K,et al.Green cloud computing:balancing energy in processing,storage,and transport[J].Proceedings of the IEEE,2011,99(1):149-167.
[15]王意洁,孙伟东,周松,等.云计算环境下的分布存储关键技术[J].软件学报,2012,23(4):962-986.Wang Yi-jie,Sun Wei-dong,Zhou Song,et al.Key technologies of distributed storage for cloud computing[J].Journal of Software,2012,23(4):962-986.
[16]雷成军,罗亮,吴文峻.基于云计算的集群能耗监控与节能方法研究[J].计算机应用与软件,2011,28(11):242-244.Lei Cheng-jun,Luo Liang,Wu Wen-jun.Cloud computing based cluster energy monitoring and energy saving method study[J].Computer Applications and Software,2011,28(11):242-244.
[17]Zha H,He X,Ding C,et al.Bipartite graph partitioning and data clustering[C]∥Proceedings of the Tenth International Conference on Information and Knowledge Management.New York:ACM,2001:25-32.
[18]Karp R M.Reducibility among combinatorial problems[C]∥Proceedings of a Symposium on the Complexity of Computer Computations.Yorktown Heights:Plenum Press,1972:85-103.
