基于LDA模型的中文微博热点话题发现
2014-08-11谈成访汪材印张亚康
谈成访 ,汪材印,张亚康
1.宿州学院信息工程学院,安徽宿州,234000;2.宿州学院智能信息处理实验室,安徽宿州,234000
基于LDA模型的中文微博热点话题发现
谈成访1,2,汪材印2,张亚康1
1.宿州学院信息工程学院,安徽宿州,234000;2.宿州学院智能信息处理实验室,安徽宿州,234000
针对微博文本数量增加速度快、信息量繁杂等问题, 将LDA模型应用到热点话题的挖掘中,构建出微博热点话题的识别过程。首先应用LDA模型对微博语料库进行主题建模,采用困惑度方法确定最佳主题个数,通过Gibbs抽样算法实现参数推理,获得语料库的主题-词汇概率分布和文本-主题概率分布,在此基础上计算并识别出微博中的热点话题、热点词汇和热点话题微博。实验结果显示该模型与人工挑选的结果基本一致,表明该模型具有较好的热点识别效果。
LDA;微博;热点话题
随着互联网技术的迅速发展,越来越多的人开始使用微博,微博的便捷性、实时性等特点使其成为人们分享信息、发表观点的重要平台。由于微博文本数量增加速度快、信息量繁杂,使得用户难以对所有的微博信息进行浏览,因此,从海量的微博信息中获取热点话题具有重要的研究意义:一方面有助于用户迅速了解社会各个领域关注的热点,另一方面能为舆情监测领域提供舆论向导。
本文采用一种无监督的机器学习方法——LDA(Latent Dirichlet Allocation)模型对微博语料库进行主题建模[1],进而识别出热点话题、热点词汇以及对应的热点话题微博。
1 LDA模型
LDA模型是Blei等人于2003年提出的一种三层贝叶斯产生式概率模型[2]。该模型认为文档是由若干主题混合而成,每个主题又由一系列的词汇混合而成。模型如图1所示。
在图1中,α和β为LDA模型的Dirichlet先验分布,分别表示整个文档集上文本-主题概率分布和主题-词概率分布,N代表单词数,M代表文档集中文档的总数,T代表主题数。
将微博中的一条消息作为一篇文档,微博语料库即为文档集D,假设文档集D是M个文档的集合,表示为D={d1,d2,…,dm},其中任意一个文档d包含N个单词,表示为d={w1,w2,…,wn},由此,一条微博文本中每个单词的概率分布计算公式如下:

(1)
其中,z1是潜在变量,表示单词wi取自该主题,p(wi|zi=j)表示词汇w属于第j个主题的概率,p(zi=j)表示文档d中属于第j个主题的概率。

图1 LDA模型
2 基于LDA模型的微博热点话题识别
本文将LDA主题建模的方法引入到微博热点话题的挖掘中,模型参数估计利用Gibbs抽样算法,间接计算得出微博文本内容和主题之间以及主题和词汇的概率分布关系,在此基础上计算并发现海量微博中的热点话题。具体识别过程如图2所示。
2.1 文本预处理
首先将网页爬虫爬取的微博语料进行HTML解析,再使用中国科学院计算机研究所的“汉语词法分析系统ICTCLAS”进行中文分词和词性标注,然后在已有停用词表的基础上,加入英文字符、数字、数字字符、标点符号,同时统计微博中频繁出现的无意义的词语和符号,如“@”、“转发”等,构建出适用于中文微博文本的停用词表,并对中文分词后的词语进行停用词过滤。

图2 基于LDA模型的微博热点话题识别过程
2.2 LDA主题建模
由于主题个数影响LDA模型对文档集的拟合性能,因此需要确定主题个数的最佳值。本文采用目前常用的评价标准困惑度(perplexity)来确定最佳主题个数的值,困惑度是从模型泛化能力衡量LDA模型对于文本的预测能力,通常情况下,困惑度越小,说明模型的泛化能力越强,模型的推广型也就越好[3]。计算公式如下:
(2)
其中,M为文档个数,Ni表示第i个文档d1的长度,P(di)表示LDA主题模型产生文档di的概率。
LDA模型的参数求解方法有很多种,本文利用MCMC中的Gibbs抽样算法进行推理,通过对变量进行Gibbs抽样间接计算出文本-主题概率分布和主题-词概率分布,即θ和φ[4],计算公式如下:

(3)

(4)

2.3 热点话题发现
2.3.1 热点话题计算
利用LDA模型对微博语料库进行主题建模,可以获得每条微博在这些潜在主题上的概率分布情况以及每个单词在各个潜在主题上的概率分布情况。设在微博文本集合D={d1,d2,…,dm}中,一条微博的影响力表示为fdj:
fdj=Nu
(5)
其中,Nu为该微博用户的当前关注人数。
将每条微博中概率值由高到低排在前N位的潜在主题看作是该条微博的话题,每个话题Ti的影响力计算方法如下:
(6)
其中,m是微博数,P(Ti)为话题Ti在各个微博中的出现概率值。
通过对各个话题计算影响力,即可发现当前微博中的热点话题。
2.3.2 热点词汇识别
假设微博热点话题集合由K个话题构成,即MT={T1,T2,…,Tk},将每个话题Ti产生的所有文档,按照概率值由高到低排序,取前N个文档并将这些文档看成是话题类别Ti,采用中文分类中效果较好的MI(Mutual Information)方法,计算文档中单词w相对于话题类别Ti的互信息[5],其计算公式如下:
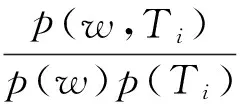
(7)
其中,p(w Ti)表示w和Ti同时出现的概率,p(w)表示w出现的概率,p(Ti)表示Ti出现的概率。
最后根据公式(7)计算出每个单词在其话题类别Ti中的互信息值,并对互信息值取执行降序排列,从中取前N个单词作为该话题的热点词汇。
2.3.3 热点话题微博推荐
假设微博中的热点话题T包含n个热点词汇,记为WT={w1,w2,…,wn},C(vi,T)表示微博M中单词vi和热点话题T的关联度,C(vi,T)的计算方法如下:
(8)
其中,Nd表示热点话题T所在的话题类别文档个数,Ed表示该话题类别中出现单词vi的文档数。
微博M和热点话题T的相关度表示为R(M,T)的计算方法如下[6]:
(9)
其中,TF(vi)是微博M中单词vi的TFIDF权重,s为微博中的单词数。
根据公式(9)计算出微博和热点话题之间的相关度,并按照计算结果降序排列再推荐给微博用户。
3 实验与分析
3.1 实验数据
本文实验数据是利用网页爬虫从新浪微博进行抓取,通过新浪提供的API抓取了新浪微博平台上2014年1月10日到2014年2月25日的微博共98 894条。经过分词、去掉停用词等预处理后,从中选取微博文本长度超过40个字符的10 267条作为微博实验语料库。
3.2 实验结果分析
首先使用前面介绍的最佳主题个数确定方法,根据α=50/T,β=0.01[7](此为经验值,这种取值在本实验语料库上有较好的效果),令T分别取值10、20、30、40、50、60、70、80、90、100,在各种不同的取值下分别运行Gibbs抽样算法,分析困惑度的变化。实验结果如图3所示。
由图3可以看出,当T=50时,LDA模型困惑度最小,此时模型的性能最佳。因此,在实验中所采用的主题个数T均为50。
下一步利用LDA模型对预处理后的微博语料库进行主题建模,分别得到单词在50个潜在主题上的概率分布以及潜在主题在每篇微博中的概率分布,再根据前面介绍的计算方法挖掘出热点话题、热点词汇和热点话题微博。

图3 困惑度和主题数T的关系
为了方便进行实验对比,本文采用人工方式从预处理后的微博语料库中挑选5个热点话题,并且用“人工标注+词频统计”的方法,挑选出每个话题对应的排在前5位的热点词汇;同时,通过LDA主题建模识别微博语料库的热点话题,并且选取排列在前的5个话题作为热点问题,然后对每个热点话题,利用互信息法抽取出值最高的5个单词作为热点词汇。使用人工方式挑选的热点词汇和基于LDA模型方法自动抽取出的热点词汇比较结果如表1所示。
从表1中可以看出,本文使用的基于LDA模型的方法所识别的热点话题与人工方式选取结果相一致,自动抽取的热点词汇与人工选取的当前时间段的社会热点基本相符合,并且所抽取出的热点词汇能准确地描述对应的话题。

表1 两种不同方式下选取的热点词汇比较
4 结束语
本文对如何从海量微博文本中自动识别出热点话题、热点词汇和热点话题微博进行了研究,通过对微博语料库进行预处理,构建LDA主题模型,将Gibbs抽样算法引入模型参数推理中,根据参数估计得到微博语料库的主题-词汇概率分布和文本-主题概率分布,同时结合微博的影响力,计算并发现热点话题,最后利用互信息识别与热点话题相关的热点词汇,实验结果表明本文提出的方法具有较好的识别效果。此外,由于微博中网络用语的随意性、口语化等特点,使得少数分词不够准确,对主题分析产生了一些不同程度的影响,在今后的研究中需要进一步改进。
[1]余传明,张小青,陈雷.基于LDA模型的评论热点挖掘:原理与实现[J]. 信息系统,2010,33(5):103-106
[2]Blei D M, Lafferty J D. A correlated topic model of science[J].Annals of Applied Statistics, 2007(1):17-35
[3]CAO Juan, XIA Tian,et al.A density-based method for adaptive LDA model selection[J]. Neuro computing, 2009,72:1775-1781
[4]QUAN X J, LIU G, et al.Short text similarity based on probabilistic topics[J].Knowledge Information System,2010,25(3):473-491[5]李劲,张华.基于特定领域的中文微博热点话题挖掘系统BTopicMiner[J].计算机应用,2012,32(6):2346-2349
[6]Lv Nan,Luo Junyong,Liu Yao,et al.Topic three layer model based topic evolution analysis algorithm[J].Computer Engineering,2009,35(23):71-75
[7]Blei D M, NG A Y, Jordan M I.Latent Dirichlet allocation[J].Journal of Machine Learning Research,2003,3(3):993-1022
(责任编辑:汪材印)
A Hot Topic Identification based on LDA for Chinese Microblog
TAN Cheng-fang1,2, WANG Cai-yin2,ZHANG Yakang1
1.School of Information Engineering, Suzhou Anhui,234000;2.Intelligent Information Processing Lab, Suzhou Anhui,234000,China
In order to solve the problem that the number of microblog text is increasing quickly and the amount of microblog information is very complicated, LDA model is applied to mine the hot topic, and the identification process of microblog hot topic is constructed. Firstly, we use LDA to model microblog corpus, determine the best number of topics by the perplexity, and achieve parameters estimation with Gibbs sampling algorithm, then we obtain the probability distribution of the topic and the word and the probability distribution of the text and the topic, on the basis of this, we calculate and identify hot topics, hot words and hot topics microblog. Experimental results show that this model is consistent with the results of artificial selection, indicating that the model has better recognition performance on hotspots.
latent dirichlet allocation;microblog;hot Topic
2014-03-01
宿州学院校级科研平台开放课题项目“问答社区中基于LDA的问题推荐机制研究”(2013YKF14);安徽省大学生创新创业训练计划项目“基于微博的网络舆情挖掘研究”(AH201310379082);安徽省大学生创新创业训练计划项目“改进的BP神经网络在ERP实施风险评价中的应用”(AH201310379078);安徽省高校省级自然科学研究项目“基于本体的直搜索研究及应用”(KJ2012Z395)。
谈成访(1981-),女,安徽舒城人,硕士,讲师,主要研究方向:web数据挖掘。
10.3969/j.issn.1673-2006.2014.04.021
TP391
A
1673-2006(2014)04-0071-04
