种植业区域分工的原因、效率与证据研究
——以云南省种植业为例
2014-08-01孙鹤,高亮
孙 鹤,高 亮
(云南农业大学 经济管理学院,云南 昆明 650201)
种植业分工可以提高经济效率是比较优势理论最早的成功注释之一。在发达市场经济国家,种植业区域分工发展得十分成熟,出现了大片专业种植带,如在美国的中西部的几个州就以种植玉米和大豆为主。改革开放以来特别是随着社会主义市场体制的逐步建立,我国种植业区域分工也开始演进发展。20世纪90年代学者们开始讨论我国种植业区域分工现象。大多数讨论以应用比较优势理论提倡种植业区域分工为主[1]。也有一些研究运用区域产业集中度指标刻画种植业区域分工的地区分布特征及其程度和演进的趋势,或者分析我国种植业分工发生的原因[2-3],不过这种原因分析往往停留在一般国际贸易理论中的比较优势论、要素禀赋论或者规模经济论,而对种植业区域分工在市场经济条件下的特点剖析不够。同时,研究我国种植业区域分工经济效率的文献比较鲜见。有学者使用时间序列数据发现了种植业区域分工的发展与种植业产值有着高的正相关性[4],不过,时间序列的简单相关性证据还很难说明种植业区域分工产生了经济效率,因为种植业经济效率的提升可能只不过是要素投入的增加或者其它技术进步的结果*技术进步是一个综合性很强的概念,种植业区域间结构调整也可以视为种植业技术进步的一个部分。,而可能与种植业区域分工无关。
本文考虑到种植业经济效率随着时间的提升应该是多种因素共同作用的结果,除了种植业区域分工可能发生了作用,应该还有人们公认的投入要素的增加和技术进步的原因。本文在计算产业区位熵的基础上,构造了区域分工指数,使用面板数据多元回归,分析了云南省各个州市种植业,发现在提取投入要素增加和技术进步对种植业产值的作用的同时,区域分工仍然对种植业产值产生了显著的影响。该结果有力支持我国的种植业区域分工产生了显著的经济效率。
一、 云南省种植业区域分布特征及原因
考虑到云南省大宗特色的六类农作物,即粮食、蔬菜、薯类、花卉、烤烟和甘蔗,首先使用区位熵方法计量了各个品种在16个州市的集中程度。区位熵是用来衡量一个产业在一个地区专业化发展程度的一种常用方法,其优点是能够直接表现区域产业专门化程度。在此使用的数据是全省及各个州、市1993—2009年的各类农作物播种面积及主要农作物播种面积*计算使用数据来源于云南省各个年份的《云南省统计年鉴》。。t时刻地区i的一类农作物种植业区位熵为:
其中,Mit为地区i在t时刻的该类农作物播种面积;Nit为地区i在t时刻的主要农作物播种面积;Mt和Nt分别为t时刻全省的该类农作物播种面积和主要农作物播种面积。由定义可知,该类农作物种植业区位熵的本质是各个州、市该类农作物播种面积占全省该类农作物播种面积的份额与各州、市主要农作物播种面积占全省主要农作物播种面积的份额之比。一般而言,这一指标的数值越大,表明该类农作物种植业在该地区的专业化程度越高,大于1则显示了该地区该类农作物有比较优势。
区位熵分析表明:随着时间的推移,云南省各个州市种植业专门化程度不断提高,对于一个地区来说,一些农作物区位熵越来越大,另一些则越来越小。比如说,花卉生产主要集中在昆明地区,区位熵高达53;蔬菜生产主要集中在玉溪地区,区位熵高达1.98;薯类主要集中在滇东地区,曲靖市达2.06,甘蔗主要集中于滇西南各个州市,最高的德宏州达4.6;烤烟主要集中在滇中地区,其中的玉溪市区位熵达到了2.97;等等。而粮食生产的集中度一般不高,主要用于本地区使用,区位熵最高的也只是1多一点,主要表现在交通不便的边远州市,外地粮食运入成本过大,也可能是“米袋子”首长负责制的结果,如滇西北地区,怒江州的区位熵是1.17。表1给出2009年各类农作物区位熵处于第一位和最末位的州市。
造成云南省种植业区域分工的直接因素主要是:距离市场的远近和交通的便利,气候地理条件、劳动力多寡等要素禀赋特征。而在一般区域分工中起重要作用的资本的余缺或者技术含量的高低,由于资本在一国内流动迅速,各类种植业之间生产技术含量差别不大,它们并没有显著作用。对于一般区域分工起重要作用的外部规模经济,由于云南山区面积占94%,耕地分布支离破碎,除了中心城市昆明区域,其他州市的农用生产资料供给能力、生产服务能力、科技服务能力、农产品加工开发能力、商贸发展能力等差别不大,外部规模经济没有显著作用。在市场经济条件下,生产者追求的不是产量,而是产值及利润。各个区域的农业生产者比较他们自己面临的市场价值、生产成本和运输成本作出了种植决策,其中运输成本的大小起了很大的作用。花卉和蔬菜直接供城市消费,远距离公路运输损耗太大,它们的种植需要投入较多的劳动力,故它们的种植主要分布在交通便捷、空运枢纽、劳动力比较丰富的区域中心城市昆明的郊区和玉溪。甘蔗种植要求气候比较热,就地加工方便,花费劳动力少、土地较为丰裕,它的种植主要分布于较边远的滇西南地区。薯类比较适于旱地种植,运输比较方便,因此它的种植主要分布于缺水的曲靖和昭通。烤烟需求量大,它的种植要求湿润温暖,需较多人力,故广泛分布于滇中各个州市。云南省各个州市的种植业区域分工体现了屠能的农业区位圈理论:云南省农业的分工围绕着昆明这个交通枢纽和中心城市需求来展开。第一圈是花卉,分布在昆明郊区;第二圈是蔬菜,主要分布在玉溪市;接下来是薯类和烤烟的种植;最后是甘蔗和粮食。云南省的粮食自给率已经逐步从改革开放之初的基本自给演变成仅自给八成多一点,这其中还含有主要作为饲料和蔬菜的玉米、作为副食的薯类、豆类和小杂粮,它们的比例越来越大,稻麦的比例逐渐变小。

表1 云南州市种植业专业化分布
二、 云南省种植业区域分工效率之证据
云南省种植业区域分工微观上是生产者自主选择的结果,在宏观层面也应该表现出经济效率。下面是一个云南省种植业区域分工经济效率的计量分析。首先构造了一个衡量各个州市种植业分工程度的指标,种植业区域专业化指数。然后把它与化肥、技术进步一起作为解释变量,被解释变量取各个地区的种植业产值,作面板数据回归,由此来检验提取化肥和技术进步的作用的同时种植业分工的发展是否促进了种植业产值的增加。
(一) 数据、变量与模型设定
本文选用了云南省16个州、市1993—2009共17年的横截面数据*数据来源于云南省各个年份的《云南省统计年鉴》。。种植业亩均产值作为因变量,各个州、市1993年至2009年的农用化肥施用量和关于五类种植业的区域专业化指数作为自变量,对它们进行实证分析(1998年及之前东川地区的相关数据已被加到同年昆明地区中,在本文中被视为同一地区)。云南省各个州、市历年的种植业亩均产值可表示为:
其中,Vit表示云南省各个州、市历年的种植业总产值(以1993年的可比价格计算);Sit表示云南省各个州、市历年的农作物总播种面积;i表示第i个地区;t表示各个年份。
各个州、市关于五类种植业历年的区域专业化指数可表示为(由于最小区位熵可能为零,故本文采用作差的方法计算此专业化指数,而不用商的方法):
ZYHit=max(Rj)it-min(Rj)it
其中,max(Rj)it表示云南省各个州、市历年的五类种植业区位熵中最大者;min(Rj)it表示云南省各个州、市历年的五类种植业区位熵中最小者;Rj表示第j种农作物的区位熵;i表示第i个地区;t表示第t个年份(由于蔬菜种植业在1993年的数据缺失,故本文在计算专业化指数时对1993年各个地区蔬菜种植业区位熵不做考虑)。
根据以上对数据的处理方法,得到了用于描述云南省各个州、市相关情况的16张数据表。其中,每张表格对应一个州市,包含因变量ncz,表示云南省该州、市历年的种植业亩均产值,单位:元;自变量hf和zyh,分别表示云南省该州市历年的农用化肥施用量(千t)和关于5类种植业的区域专业化指数。技术进步在宏观层面随着时间推移在提升,人们经常使用时间T来表征,这里也如此处理。
用时间序列数据建立模型经常会遇到样本量太小及解释变量出现多重共线性等问题,用截面数据建立模型则可能遇到如价格等一些经济变量缺乏足够大的变异及无法参考动态行为特征等问题。此时,如果能够把时间序列数据域截面数据结合在一起建立模型,就有可能在一定程度上解决上述问题,从而得出更为可靠的模型估计结果。概括地说,将时间序列数据和截面数据合并成面板数据进行处理具有以下优势:(1)可以增加样本容量;(2)可以提高数据的信息含量;(3)可以分析不同研究对象之间的差异;(4)可以分析经济对象的动态变化。因此,设定模型如下:
NCZit=c+α×HFit+β×ZYHit+γ×t
(二) 计量分析
在计量分析中,使用Eview软件,综合考察经济意义、统计检验和计量经济学检验结果,比较了简单混合数据、固定效应和随机效应与横截面、时间交叉产生的6种基本模型下的各种估计方法的结果,选用了表现比较好的简单混合数据模型的横截面表面似不相关估计(Pooled EGLS-Cross-section SUR)结果[5,6]。这也说明由于各个种植区域在相同的时期内受到同一个国家、同一个省份的相同的经济政策和宏观环境的影响,使得模型的随机干扰项uit对于固定的时间t不同的地区i和j之间有较强的正相关,而该方法利用了这种随机干扰之间的相关性信息,较大的改善了估计结果。结果见表1。
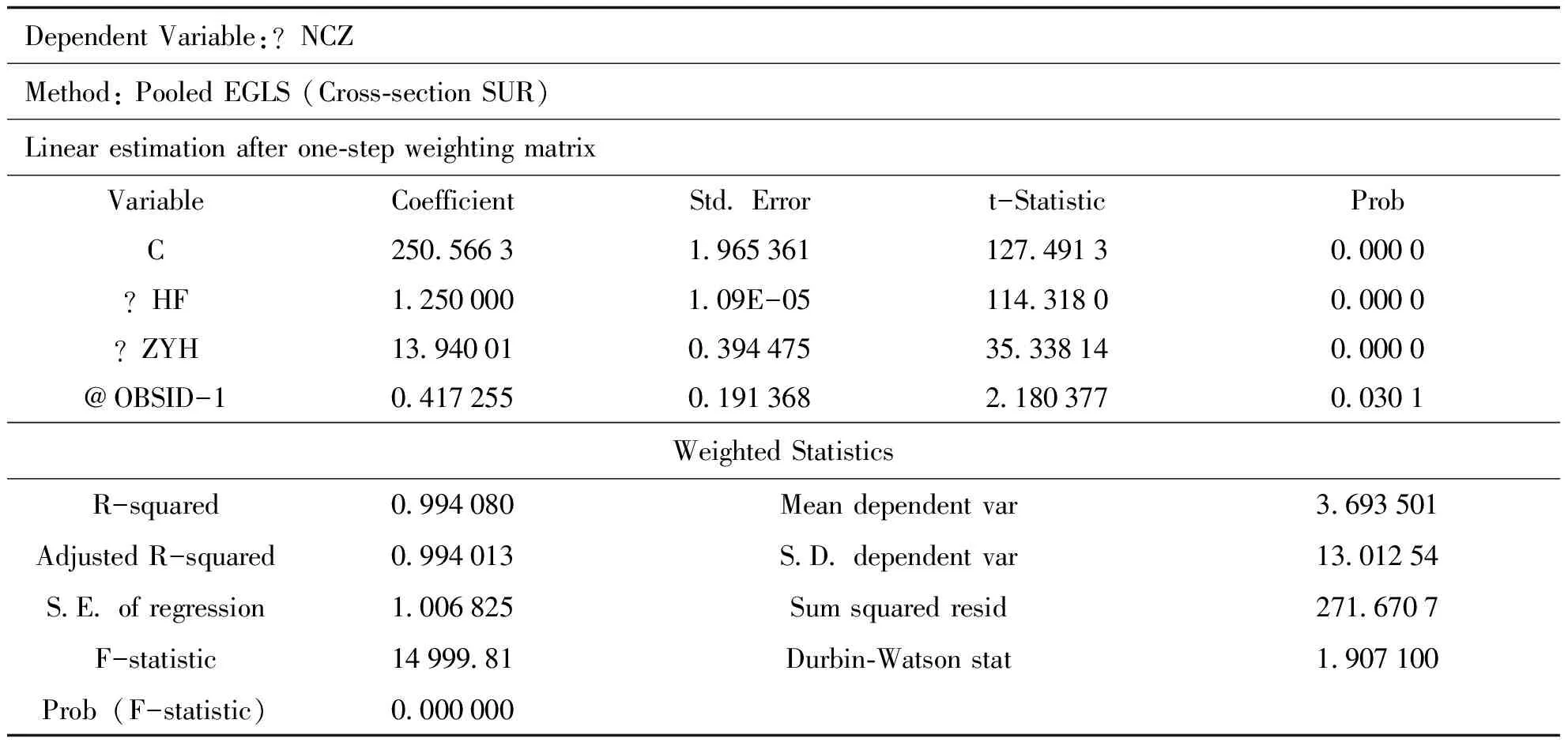
表2 种植业专业化影响计量分析结果
计量方程:
NCZit=250.57+1.25HFit+13.94ZYHit+0.42t
(三) 计量结果解释
根据处理结果,时间序列的样本范围的跨度包含17年,横截面数据包含16个州市,因此共产生混合观察272个。结果显示,HF的系数α为1.25,表示云南省一个州市一年农用化肥施用量每增加1千吨,种植业亩均产值平均增加1.25元;ZYH的系数β为13.94,表示种植业区域专业化指数每增加1个单位,平均来说,云南省1个州市1年的种植业平均产值增加209元/hm2。同时,两个自变量的系数的P值都是 0.000 0,表示对两个自变量系数的检验都非常显著;技术进步的作用表明每年产值平均增加6.3元/hm2,显著程度也达到了0.03。R-squared达到了0.994,F检验的显著度很高,D-W检验统计值达到1.91,与2非常接近,这些数值都表明了模型的估计是比较成功的。
计量结果表明:即使提取了要素投入(以化肥为代表)和技术进步对产值的作用,仍然可以检验到区域分工专业化对种植业产生的显著作用。有充分的理由支持种植业区域分工产生了显著的经济效率的结论。
三、 结论和建议
造成种植业分工的原因主要是交通运输成本、自然禀赋或者生产条件方面的差异。而资本余缺、外部规模经济等的作用不明显。
本文计量分析考虑了种植业经济效率的多因素性质、使用面板数据多元回归方法,有力证实了种植业区域分工的经济效率。长期来说,无论是生产者个人,还是一个区域或者整个省种植业区域分工都获得了更高的经济利益,这是一个双赢、或者多赢的结果。
应该从完备信息、加强服务、发展农业产业化、发挥龙头企业的引导作用、发展农业保险、发展订单农业、发展农业期货市场和电子商务等方面完善农产品市场。应该继续改善交通条件、完善仓储设施,进一步发挥各地区种植业比较优势。
[参考文献]
[1]李建强,祖立义,钟秀玲.种植业比较优势分析——以四川省为例[J].农村经济,2005(9):47-49.
[2]苗齐.中国种植业区域分工研究[D].南京:南京农业大学,2003:121.
[3]王宇露.主产区粮食种植业区域分工现状及其引导机制[J].农村经济,2006(9):39-42.
[4]张哲,张蕾.种植业区域分工的经济增长效应分析——以陕西省,甘肃省为例[J].西北农林科技大学学报:社会科学版,2003,3(3):24-27.
[5]张晓峒.Eviews 使用指南与案例[M].北京:机械工业出版社,2007.
[6]HSIAO C.面板数据分析[M].第二版,影印本.北京:北京大学出版社,2005.
