基于Hadoop的自动售票日志分析系统设计
2014-08-01蒋秋华
王 斌,李 超,蒋秋华
(1.中国铁道科学研究院 研究生部,北京 100081;2.中国铁道科学研究院 电子计算技术研究所,北京 100081)
基于Hadoop的自动售票日志分析系统设计
王 斌1,李 超2,蒋秋华2
(1.中国铁道科学研究院 研究生部,北京 100081;2.中国铁道科学研究院 电子计算技术研究所,北京 100081)
通过对自动售票系统日志数据分析,不仅能了解系统的运行状况,还能在日常维护中更容易地发现问题,降低维护成本,提高维护的效率。针对这一目的,本文基于Hadoop框架设计一个自动售票系统的日志分析系统,搭建Hadoop集群环境,并对处于不同自动售票应用服务器上的日志进行收集,针对自动售票系统日志的特点,编写Map/Reduce算法,对收集到的日志进行分析处理,使其结果满足需求,同时,验证基于Hadoop的自动售票日志分析系统的有效性及可行性。
Hadoop;自动售票机;分布计算;日志分析
近年来,随着铁路信息化的发展,自动售票系统在国内的高速铁路已普遍使用。目前,全路自动售票机(TVM,Ticket Vending Machine)装机量达3 000台以上,日均售票量占总售票量的10%左右,在部分车站甚至高达40%。自动售票机的大量应用,取得了很好的效果,不仅方便了旅客,而且很大程度上缓解了车站售票的压力。然而,与此同时,就会产生相当大规模的日志数据。目前,在日常维护中都是通过人工查看这些日志文件来发现问题,这样不仅对维护人员要求较高,而且效率低下,因此,如何存储并高效处理这些日志数据就变得尤为重要。
Hadoop[1~2]是一个流行的大规模数据处理框架,它能够运行于多种平台上,并且具有良好的健壮性和可扩展性,在大规模数据处理方面具有一定的优势,成为进行日志分析的有效解决方案。
1 Hadoop简介
Hadoop 的核心由HDFS(Hadoop Distributed File System)和MapReduce体现。HDFS提供了一个稳定的文件系统,而Map /Reduce提供一种分布式编程模型。一个HDFS 集群由一个称为名称节点(NameNode)和数个数据节点(Datanode)这两类节点构成,这两类节点以管理者—工作者模式运行。名称节点负责维护整个文件系统。数据节点是文件系统中实际的工作者,它们提供存储、定位块的服务,并定时向名称节点汇报存储块的信息。Map /Reduce 可以使得程序分布到集群上并发执行。Map /Reduce 将整个工作过程分为Map 阶段和Reduce 阶段。每个阶段都以键/值对作为输入、输出。Map 将用户的输入数据以键/值对形式通过用户自定义的映射过程转变为一组中间键/值对的集合。而Reduce 过程则会对中间生成的临时中间键/值对作为输入进行处理,并输出最终结果。目前,Hadoop被广泛应用于海量数据的处理。
2 自动售票日志分析系统的设计
2.1 日志分析系统整体架构
日志分析系统的总体架构如图1所示。
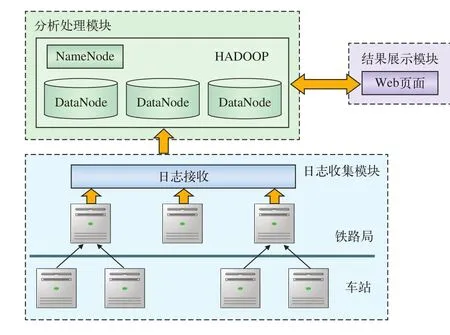
图1 日志分析系统架构图
2.1.1 日志收集模块
对大规模日志数据进行处理,要把分散在前端目标主机上的日志文件进行收集[3]:
(1)在前端目标主机,对原有系统的日志进行收集并保存;
(2)将前端目标主机上保存的日志文件传输到 Hadoop 集群中;
(3)将处于Hadoop集群中的日志文件导入到HDFS,利用HDFS的存储原理和备份机制,在各个节点间建立数据通信方式,配置相应的数据节点、数据备份的数目及对应的名称节点信息。
日志传输的方式有很多种,既可以通过脚本实现,也可以通过现有的传输工具实现,本系统采用Flume系统进行日志采集。Flume是一个分布式、可靠和高可用的海量日志聚合的系统,支持在系统中定制各类数据发送方,用于收集数据。同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力,其数据源支持console(控制台)、RPC(Thrift-RPC)、text(文件)、tail(UNIX tail)、syslog(日志系统,支持TCP和UDP等2种模式),exec(命令执行)等。其逻辑架构如图2所示。Agent代表一个需要进行日志收集的节点,其中Source表示数据来源,Sink表示数据去向[4]。

图2 Flume逻辑架构图
由于现有的自动售票系统存在两种模式:(1)车站自主管理模式,即各站自主管理,每个车站均配有自动售票服务器及附属设备;(2)铁路局集中模式,即在各个铁路局设置自动售票应用服务器集群,所有车站的终端设备都直接连接到铁路局,将所有下辖车站的应用处理服务全部集中管控,采用负载均衡器实现业务均衡处理,保证系统的高可靠性和高安全性[5]。因此,要想使用Flume进行日志收集,需要在所有部署自动售票系统的应用服务器节点上部署一个Agent,并在f l umeconf.properties文件中配置相应的Source和Sink:
agent.sources=spooldirSource
agent.channels=memoryChannel
agent.sinks=hdfsSink
配置完成后,启动每一个Agent节点。这样,Flume系统就会自动将各节点上产生的日志文件收集到Hadoop集群中,以供分析。其日志收集流程如图3所示。
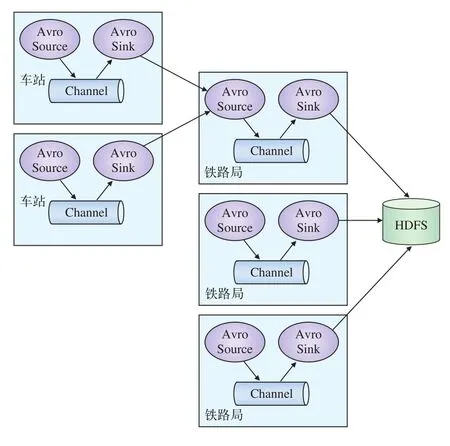
图3 日志收集流程图
2.1.2 日志分析处理模块
日志分析处理模块是进行大规模日志分析的核心,主要负责将收集到的日志进行分析处理,得到想要的结果。在系统中,其目标是处理所有自动售票应用服务器上产生的日志文件,由于这些日志文件记录了全国各个车站TVM终端发送的请求以及服务器的响应信息,因此其数据规模相当大。提高系统日志分析处理效率以及降低系统成本是设计系统时必须要考虑的一个方面。
系统采用Hadoop开源框架实现日志分析处理模块。Hadoop对大规模数据的处理通过Map/ Reduce算法实现[6]。(1)JobTracker创建并初始化一个作业对象,根据已划分的输入数据创建Map任务,并根据一定的属性创建Reduce任务。(2)初始化完成后,JobTracker通过一定的调度算法为每个TaskTracker分配Map或者Reduce任务。(3)由TaskTracker执行相应处理。
2.1.3 结果展示模块
通过Hadoop对日志进行分析处理,其处理结果有多种展现形式。可以通过某些静态网页的形式产生,可以直接输出到文档中保存,也可以输出到关系型数据库中保存。由于设计日志分析系统的目的是要通过Web页面进行交互,用户只需提交自己想要的查询,系统进行处理后会在页面展现最终的结果,使用户可以更直观地了解到系统的运行状态,发现系统存在的问题并及时处理,因此,本系统的结果将通过Web页面的形式展现。例如,在实验中,通过分析处理,在页面上展现一段时间内,自动售票终端发送各个请求的成功次数、失败次数、成功响应平均时间和超时次数等。
2.2 通过Hadoop进行日志分析
2.2.1 实验环境的搭建
(1)硬件环境
本系统的实验在由4台普通笔记本组成的集群上完成,其中一台作为Master主机,主要负责NameNode以及JobTracker的工作,NameNode是Hadoop分布式文件系统的管理者和调度者,JobTracker的主要职责是启动、跟踪和调度各个Slave节点的任务执行。其余3台作为Slave,负责DataNode以及TaskTracker的工作,DataNode 用来储存系统中的数据信息及其备份,TaskTracker执行Map任务以及Reduce 任务,进行实际的数据处理。
(2)软件环境
操作系统采用SUSE10版本,Hadoop采用Hadoop1.1.1版本。
2.2.2 Hadoop日志分析主要算法
本文的日志数据来源于自动售票应用服务器的日志文件,记录了TVM终端用户的请求行为和服务器响应的结果,主要内容如表1所示。

表1 自动售票系统日志内容
实验通过对该日志文件分析,计算出不同请求的成功响应与失败响应的次数以及相应的平均时间,其分析算法主要过程如图4所示,其中none、fail、suc分别代表未匹配到、匹配失败、匹配成功的状态标签。

图4 程序流程图
(1)导入HDFS中的日志文件分成M块Split,将所有的Splits均衡地存储在各个Slave节点。
(2)通过Hadoop的Map/Reduce算法对输入分片Splits进行处理。Map阶段,对输入文件进行解析,通过终端ID以及终端身份信息进行请求与相应的匹配,将终端身份信息与终端ID拼接为key,如果请求与响应匹配成功,则将“suc”与响应时间拼接为value,如果匹配失败,则value值为“fail:1”,如果未获得响应信息,则value值为“none:1”, 将
(3)根据需求,输出Reduce的结果。
3 结束语
本文设计了Hadoop分布式环境下自动售票日志数据分析系统。在实验室集群环境中,对10 G的日志文件进行了分析,总约有1 000万条记录,仅用时430 s分析完成。
从实验结果中可以看到:使用Hadoop建立的分布式日志分析系统,在大规模日志数据处理方面具有明显的优势,很大程度上节约了分析成本,提高了分析效率,因此具有很好的应用价值和研究空间。本文只是初步实现了对自动售票系统日志简单的处理,今后完全可以根据需求实现更加复杂的业务,比如,对各个铁路局的服务器运行状况进行监控,统计售票、取票情况,甚至能够分析用户的购票行为与使用习惯,这样不仅能够提高维护效率,降低维护成本,而且还能为决策者提供一种决策支持。
[1] Apache. Hadoop 1.1.1 Documentation[EB/OL]. http://hadoop. apache.org/docs/r1.1.1/.
[2] Tom White. Hadoop权威指南[M]. 曾大聃,周傲英,译.北京:清华大学出版社,2010.
[3] 张兴旺,李晨晖,秦晓珠. 云计算环境下大规模数据处理的研究与初步实现[J]. 现代图书情报技术,2011(4):17-23.
[4] Apache. Flume 1.4.0 User Guide[EB/OL]. http://f l ume.apache. org/FlumeUserGuide.html.
[5] 李士达,蒋秋华,康 勇,韩新建. 铁路旅客自动售票系统设计与实现[J]. 铁路技术创新,2012(4):42-44.
[6] Shim, Kyuseok. MapReduce algorithms for big data analysis[J]. Lecture Notes in Computer Science, 2013(7813): 44-48.
责任编辑 杨利明
TVM Log Analysis System based on Hadoop
WANG Bin1, LI Chao2, JIANG Qiuhua2
( 1. Postgraduate Department, China Academy of Railway Sciences, Beijing 100081, China; 2. Institute of Computing Science, China Academy of Railway Sciences, Beijing 100081, China )
TVMs could produce a large number of log data which included much valuable information. From these information, we could know the status of our system and maintain the system more eff i ciently. In all ways of data processing, Hadoop was an open source framework which was used widely in large data sets processing. For this purpose, this paper designed a log analysis system of automatic ticketing system based on Hadoop, in this way, we could collect and analyze the log data of TVM and make the result meet our demand by Map/Reduce Algorithm. Meanwhile it was verif i ed that the System was effective and feasible.
Hadoop; Ticket Vending Machine(TVM); distributed computing; log analysis
U293.22∶TP39
A
1005-8451(2014)07-0020-04
2014-01-06
王 斌,在读硕士研究生;李 超,助理研究员。
