基于相似领域共享特征的分类学习模型
2014-07-08徐俊芬叶俊杰刘业政
徐俊芬,叶俊杰,刘业政
1.合肥工业大学管理学院,合肥 230009
2.过程优化与智能决策教育部重点实验室,合肥 230009
基于相似领域共享特征的分类学习模型
徐俊芬,叶俊杰,刘业政
1.合肥工业大学管理学院,合肥 230009
2.过程优化与智能决策教育部重点实验室,合肥 230009
传统上下文在分类研究中通常存在失真和有效性等问题。引入研究对象领域的相似领域作为上下文,借助迁移学习理论,使用结构化相似性学习方法构建研究对象领域和其相似领域间的低维共享特征,提出一种基于相似领域共享特征的分类学习模型。实验以QQ空间的个性化设置数据作为上下文,对用户电子商务网站页面的风格偏好进行分类,验证了所提模型的可行性和有效性。
分类;相似领域;上下文;共享特征;特征迁移学习
1 引言
分类算法是机器学习、模式识别和数据挖掘等领域中被广泛研究和应用的一个重要课题。分类学习模型的有效构建很大程度依赖于充足的样本和有效的特征信息,然而在现实中数据不完备现象广泛存在,从而导致分类准确率不高。为此,许多研究者提出了基于上下文的分类学习模型[1-2]。这类模型一般引入用户描述文件(User Profile)[3]、在线社会关系网络(OSN)[4]、位置[5]等各种各样的情境上下文,以此作为目标分类的特征信息或作为辅助信息来提高分类模型的有效性。这类模型表现出了较好的分类性能,但有时这些特征信息的准确性并不能保证,且该类传统上下文对某些特定研究领域并不存在有效影响,这使得许多模型的推广应用受到限制。例如,在拍拍网上需要判别用户偏好于何种风格的Web页面时,用户的位置、教育程度等上下文的利用并不能有效地提高分类效率,而性别、年龄等虽然对部分风格选项有效却可能由于信息失真而使模型失去效果。
上例中,由于拍拍网用户大部分拥有开放的QQ空间并对其空间风格和页面进行了个性化配置,由此可以通过一定的技术手段有效获取这些信息,而这些信息与商品展示页面风格偏好同属对Web页面风格的偏好,属于相似领域,其中必然蕴含着用户对页面风格的偏好信息。若将这些信息作为上下文来构建相关的分类模型,其分类效果应该会更好。为此,本文提出一种基于相似领域共享特征的分类学习模型,即CM-CFBSD(Classification model based on the Common Features Between Sim ilar Domains)。本文尝试借助迁移学习理论[6-8],利用特征迁移学习技术中的结构化相似性学习方法(Structural Correspondence Learning,SCL)[9]获取上下文和研究对象之间的共享特征,并将此作为上下文集成利用的有效桥梁从而构建CM-CFBSD模型。该模型提出引入相似领域特征信息作为新的上下文建模数据源,有效地解决了上下文失真以及某些特定领域分类中缺乏有效上下文的问题,具有一定的应用价值。
2 相关研究
特征迁移学习技术是迁移学习中一种主流的技术方法,该方法旨在不同但相似的领域之间通过挖掘领域间的共享特征来实现知识的有效迁移,其学习过程就是发现这部分共享特征的过程。由此共享特征的获取问题受到了广泛的关注,不少学者对此展开深入研究。例如,Blitzer等[9]提出了SCL方法,利用领域未标记数据提取一些降低领域间差异的相似性特征来解决NLP问题;Bonilla[10]等人将模型建立在高斯过程的基础之上,由此诱导得出共享特征;Dai等[11]同时对两领域数据进行自学习聚类多次迭代来寻求一个共同的特征表示。这些方法从不同角度解决了特征学习技术中获取共享特征的问题。其中,SCL方法在域自适应问题上表现出了良好的性能,且能精炼地提取出领域间的一致性特征和依赖关系。
K-Means聚类算法则是一种基于领域内样本间相似性度量的间接聚类算法,由M acQueen于1967年首次提出。该算法处理流程清晰易懂,操作简便,并因其高效性、可扩展性,许多聚类问题都选择该经典算法。同时,K-Means聚类算法可有效地发现数据分布和其中的隐含模式。
3 CM-CFBSD模型
CM-CFBSD模型主要包括三个部分:(1)应用SCL方法构建相似领域A、B之间的低维共享特征集;(2)将学习得到的低维共享特征集附加到领域A和领域B的原特征集上,生成相应的拓展特征集并据此进行聚类;(3)按照最近原则[12]将两领域的聚类类别一一映射,获取两领域间的类别映射关系,以此结合领域A的特征实现领域B的分类。
3.1 相关符号定义
定义1领域A、B的样本集分别记为{Ai}和{Bi},i= 1,2,…,n,其中n为两领域的样本数,且两领域的样本是一一对应关系。
定义2样本Ai的特征表示为F={f1,f2,…,fk},其中k为特征集F的特征数。相应地,Bi特征表示为G= {g1,g2,…,gl},其中l为特征集G的特征数。现将领域A、B的样本相融合构造一个新的样本集:X={Xi},i=1,2,…,2n,其中2n为样本集X的样本数,其特征表示为F∪G,共k+l个特征。记Xij为样本i的第j个特征值,当1≤i≤n,1≤j≤k时,Xij=Aij;当1≤i≤n,k+1≤j≤k+l或n+1≤i≤2n,1≤j≤k时,Xij=NULL;当n+1≤i≤2n,k+1≤j≤k+l时,Xij=Bi-n,j-k。
3.2 基于相似领域上下文的低维共享特征学习
为了将相似领域A的信息应用于领域B中,有效集成该上下文,首先需提取出相似领域之间的桥梁信息,记为枢纽特征集P={p1,p2,…,pm},其中m表示枢纽特征集P的特征个数。本文相应地构建m个二值分类器,将pj(j=1,2,…,m)表示为“该样本中是否具有枢纽特征j,若有,则pj=1,反之pj=-1”。最后,将分类问题转换成m个线性预测问题:
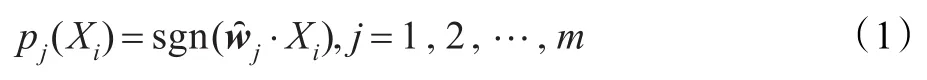
其中,wj为X的特征集F∪G的权重分配向量,是一个含有k+l个值的实值列向量,表示用于枢纽特征预测的k+l个特征的权重。wj的求解问题可转换为求解如下形式的二次无约束规划问题:
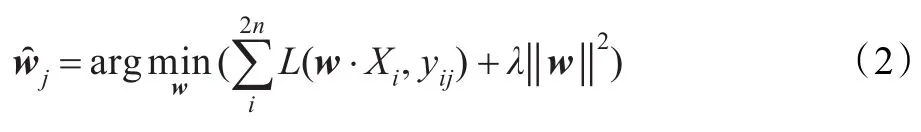
其中,yij是样本i对枢纽特征j的标注值;‖w‖2是权重分配向量w的内积;λ是调整训练数据错误率和权重分配向量w内积的一个平衡因子;这里L(w·xj,yij)是一个实值损失函数,本文采用hinge损失函数,定义为:

算出权重分配矩阵W={w1,w2,…,wm}以后,本文按照文献[9]对W作奇异值分解,由此得出低维映射θ,其中θ选取奇异分解所得矩阵U的转置矩阵的前q行,依此得到联系最紧密的q个共享特征,记为S={s1,s2,…,sq}。θXi是样本Xi的共享特征S的实例化表示,记为Si,即Si=θXi。该共享特征集充分地挖掘出领域A、B之间的一致性信息,有效实现跨领域上下文的集成。

3.3 基于拓展特征的领域聚类
将应用SCL方法从相似领域A、B学习得到的低维共享特征集S分别附加到原特征集F和G上,生成拓展特征集F∪S和G∪S,并在此基础上利用K-Means算法分别对领域A样本集{Ai∪Si}和领域B样本集{Bi∪Si}进行聚类,最后得到聚类结果、,i,j= 1,2,…,h。具体过程如下(以领域A聚类为例,领域B聚类同理):
输入:领域A样本集{Ai∪Si},简记为{Zi},i=1,2,…,n。
步骤1指定聚类数目h。
步骤3计算每个样本到h个类中心点的距离,将所有样本分派到最近的类中。
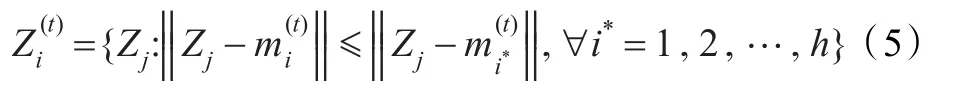
步骤4重新确定h个类中心。

步骤5判断是否满足终止条件,若没有,返回步骤3,不断反复上述过程,直到满足终止条件。
3.4 基于相似领域上下文的分类
为了便于分析,本文用每个类别的中心点表示相应的类别,即:↔,↔,i,j=1,2,…,h。在上一步得到的聚类结果的基础上,将领域A和领域B的每类中心点中的原特征集通过共享特征的线性映射矩阵θ将其线性表示成包含q个元素的特征向量。再加之每类中心点中原有的q维共享特征向量,由此将领域A和领域B的h个中心点映射到Rh×2q空间中,即两个领域的中心点都转换成了相同维度的向量,2q维的行向量,因而具有可比性。其次,计算经线性转换后的和的欧式距离,并为寻找一个最近的,此中心点所对应领域A的类别即是所对应领域B类别的映射类。该映射过程可表示为:
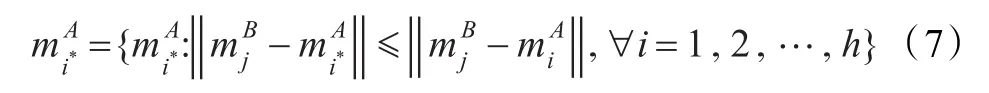
经上述处理后,领域A和领域B的类别处于一一映射的关系,由此确定领域间的类别映射关系。因此,模型借助领域A、B间的共享特征,有效集成相似领域A该上下文,并在此基础上根据类别映射关系实现领域B类别的预测。
3.5 算法步骤
输入:相似领域A、B的样本集{Ai}、{Bi},总样本集X={Xi},以及待分类样本
(1)选择m个枢纽特征,构建m个二值分类问题。
(2)For j=1 to m
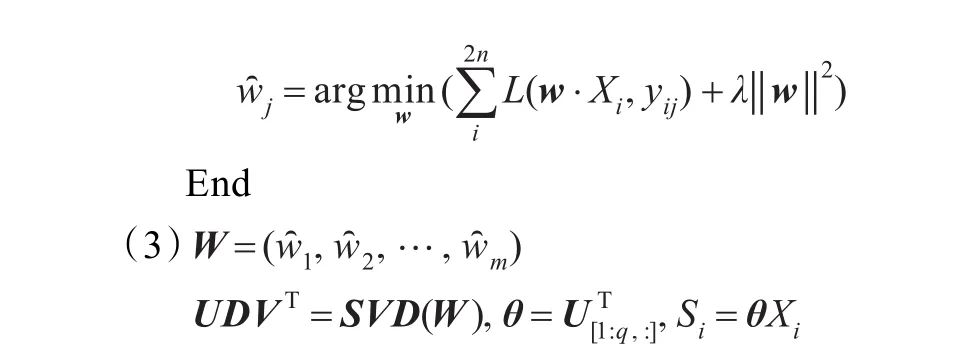
(4)应用K-Means算法分别对样本集{Ai∪Si}和{Bi∪Si}聚类,并返回聚类结果KA、KB。
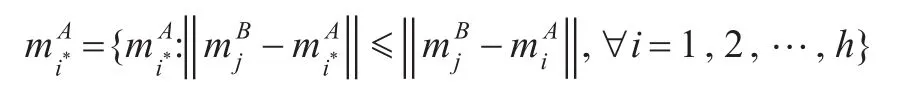
4 应用实例
4.1 应用背景和实验设计
在用户电子商务网站web页面风格偏好分类中,像用户的性别、年龄、位置等传统上下文对偏好分类不能起有效作用,而用户的QQ空间页面个性化设置却蕴含有用户页面偏好信息。针对这个问题,可用本文所提模型加以解决。因此,本文选取用户对电子商务网站w eb页面的风格偏好作为研究对象,而将QQ空间页面个性化设置作为上下文,以期利用上述模型实现网购用户页面偏好分类。
具有相同认知特征的用户对页面的展示形式有相同认知偏好。因此,该实验将用户的页面认知特征作为以上两个领域的枢纽特征,分别为p1、p2、p3,即对表象信息的偏好[13]、对页面复杂性的偏好[14]和对页面交互性的偏好。模型中权重分配向量的训练是一个二次无约束规划问题的求解过程,本实验将平衡因子λ设为0.000 01,并采用中规模的拟牛顿搜索算法。在寻找两领域的低维共享特征表示时,本实验选取3个最密集的共享特征(q=3)。在K-Means聚类学习过程中,距离测量采用欧氏距离,迭代停止条件是各样本所属类别不再发生变化。
4.2 数据采集
鉴于本文所提方法的应用背景为两个相似领域(两个存在着广泛显性共享特征的领域),且要求领域间的数据是一一对应关系,同属于一个用户,而目前该类研究中普遍采用的“Text,E-mail,W iFi,Sen”[6]这四个标准数据集属于不同领域不同用户的数据,不存在一一对应关系,因而对本文方法适用性较差。因此,本文通过实验方式获取用户QQ空间页面个性化设置和用户电子商务网站web页面的偏好信息这两大数据集作为领域A和领域B。其中,领域A数据集通过人工上网抓取获得,共有400个样本,每个样本由14个特征组成;领域B数据集通过问卷调查获取,问卷以图1(a)~(d)中的4种风格页面为考察对象据此收集数据,该数据集共有400个样本,每个样本由12个特征组成。以上样本集合的特征信息及经预处理后的特征值等相关信息如表1所示。此次实验在400个样本中随机抽取80%(300个)作为训练集,剩余的20%(100个)作为测试集对模型分类性能进行验证。

图1 4种不同风格的商品展示页面
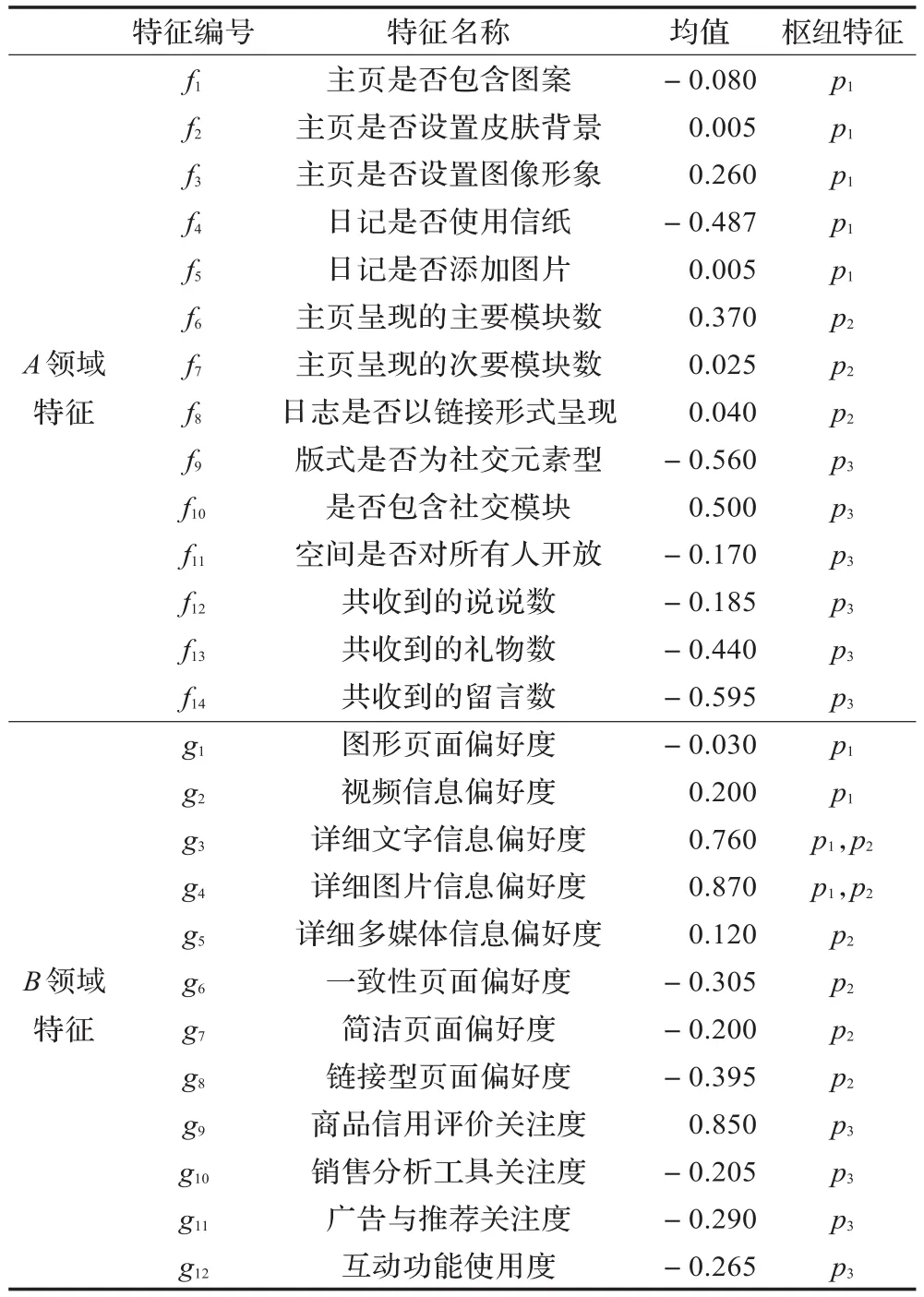
表1 经处理后的样本数据集合特征信息
4.3 实验结果
采用EXCEL2007对所收集的数据进行规范化处理,再使用MATLAB2008计算获取A、B领域间的低维共享特征,然后使用Clementine的K-Means算法分别对A领域和B领域的训练集进行聚类,并根据聚类结果确定其类别映射关系,如图2所示。图中箭头表示两个领域类别之间的映射关系,例如,领域B的类对应于领域A的类;而类标后括号中的数字指代该类所包含的样本数。
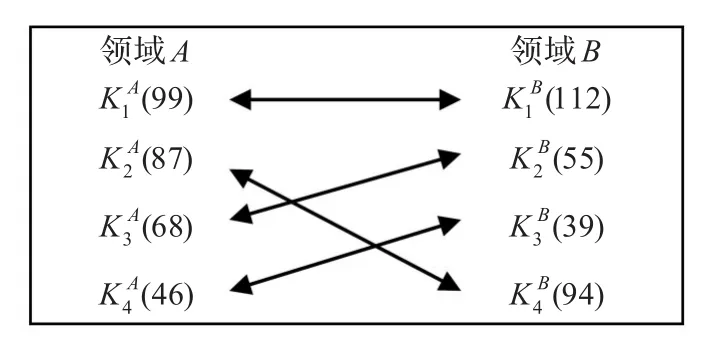
图2 领域A和领域B的类映射关系
4.4 模型验证
为了验证所提模型的有效性,本文还用主观判定法和基于相似领域原特征的分类模型(CM-SD)对测试集进行分类。主观判定法是指依据人们现有的知识经验主观地为待分类样本的各个特征分配权重,通过加权学习得以实现分类,在本实验中就是根据对用户页面风格偏好的影响因素的认识和4.2节中表1的特征归类,平均分配领域A和领域B各枢纽特征下的原特征的权重并加权求和确定3个枢纽特征的取值,最后依据枢纽特征的取值实现样本类别预测。CM-SD法与本文的CM-CFBSD法相似,区别在于CM-SD法在领域聚类时没有集成利用获取得到的共享特征,直接对原特征表示的领域样本聚类(聚类方法仍是K-Means算法),据此获取类别映射关系以实现分类。以上三种方法的实验结果如表2所示。
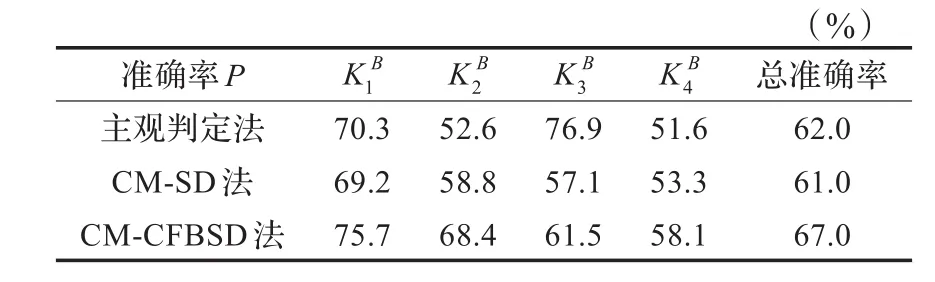
表2 三种方法在测试集上的分类准确率对比
表2数据显示,从总准确率上来看,本文提出的CM-CFBSD法显著优于主观判定法、CM-SD法,具有良好的综合分类效果。从各类准确率来看,CM-CFBSD法对每类样本的分类准确率皆优于CM-SD法,这表明共享特征S对样本的特性表征起关键作用,能有效消除噪音数据,保证重点知识的集成利用。相比于主观判定法,CM-CFBSD法在第1、2、4这三类分类效果更好,第3类则略差。观其各类样本特征发现,主观判别法在特征显著易察明的类别具有一定的优势,但对特征显著性较差的类别进行分类则比较困难。CM-CFBSD法则不论样本特征取值是否存在显著差异,都能良好的对样本加以分类,能有效地弥补主观判定法的不足,适应性更强。这主要是因为该方法不仅通过低维共享特征有效集成相似领域上下文,此外还在分类时使用了更为客观的K-Means聚类算法,从而可根据样本数据分布有效挖掘其中的隐含模式。
实验结果表明了通过共享特征来集成利用相似领域上下文进行分类学习的高效性。该实验基于QQ空间领域和电子商务网站领域的低维共享特征来实现用户电子商务web页面的风格偏好分类,该共享特征精确地提炼出两个领域之间的关系,并有效识别QQ空间领域这一相似领域上下文信息中对电子商务领域用户页面偏好分类产生重要影响的关键因素,减弱上下文中噪音产生的干扰,使得上下文的利用更合理、更有效,分类准确率更高。该评价结果很好地验证了本文所提模型的有效性和可行性。
5 结论
在分类研究中,分类学习的上下文信息利用的有效性问题是一个极具挑战性和研究意义的热点问题。针对传统上下文的准确性不能保证且对某些特定研究领域并不存在有效影响的问题,本文创新性地提出了跨领域上下文信息在分类学习模型中的应用,在该问题上借助迁移学习理论,构建一个基于相似领域共享特征的分类学习模型。实验表明,该模型通过获取相似领域间的共享特征从而充分利用上下文信息,可有效实现研究领域的准确分类。相较于实验中其他两种方法该模型的分类准确性具有明显优势,但从总体来说其分类准确率仍不是很高,存在提升的空间。今后将进一步改进模型与此同时使用网络用户的真实数据进行模型测试。
[1]王立才,孟祥武,张玉洁.上下文感知推荐系统研究[J].软件学报,2011,23(1):1-20.
[2]Chen M M,Sun J T,Ni X C,et al.Improving context-aware query classification via adaptive self-training[C]// Proceedings of the 20th ACM International Conference on Information and Know ledge Management,New York,2011:115-124.
[3]Vieira V,Tedesco P,Salgado A C.Designing context-sensitive systems:an integrated approach[J].Expert Systems with Applications,2011,38(2):1119-1138.
[4]W hite R W,Bailey P,Chen L W.Predicting user interests from contextual information[C]//Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval,New York,2009:363-370.
[5]Chon Y,Cha H.Lifemap:a smartphone-based context provider for location-based services[J].Pervasive Computing,2011,10(2):58-67.
[6]Pan S J,Yang Q.A survey on transfer learning[J].IEEE TKDE,2010,22(10):1345-1359.
[7]Chen D,Xiong Y,Yan J,et al.Know ledge transfer for cross domain learning to rank[J].Information Retrieval,2010,13:236-253.
[8]Raina R,Battle A,Lee H,et al.Self-taught learning:transfer learning from unlabeled data[C]//Proceedings of 25th International Conference on Machine Learning,New York,2007:759-766.
[9]Blitzer J,M cdonald R,Pereira F.Domain adaptation with structural correspondence learning[C]//Proceedings of the 2006 Conference on Empirical Methods in Natural Language Processing,Sydney,2006:120-128.
[10]Bonilla E,Chai K M,W illiams C.Multi-task Gaussian process prediction[C]//Proceedings of the 20th Annual Conference on Neural Information Processing Systems,Vancouver,2008:153-160.
[11]Dai W Y,Yang Q,Xue G R,et al.Self-taught clustering[C]// Proceedings of the 25th International Conference on Machine Learning,New York,2008:200-207.
[12]袁玉波,杨传胜.数据挖掘与最优化技术及其应用[M].北京:科学出版社,2007:102-103.
[13]叶俊杰,刘业政,蒋玮.Web环境下认知风格对商品信息关注度的影响研究[J].图书情报工作,2012,56(6):95-101.
[14]蒋玮,叶俊杰,刘业政.消费者认知风格对Web页面复杂度偏好影响的实证研究[J].情报杂志,2011,30(7):178-184.
XU Junfen,YE Junjie,LIU Yezheng
1.School of Management, Hefei University of Technology, Hefei 230009, China
2.Key Laboratory of Process Optimization and Intelligent Decision-making, Ministry of Education, Hefei 230009, China
Distortion and low efficiency are two constant problems when employing traditional context in classification problems. Inspired by the transfer learning theory, the paper regards the similar domain of the target domain as context,and constructs the low-dimensional common features between the target domain and its similar domain by structural correspondence learning method. Based on the common features between similar domains, the paper puts forward a new classification model. The experiment employs users’personalized options of QQ-zone as context to classify users’preferences of e-commerce web pages, the results verify the feasibility and availability of the proposed model.
classification;similar domain;context;common feature;feature-based transfer learning
XU Junfen, YE Junjie, LIU Yezheng. Classification model based on common features between similar domains. Computer Engineering and Applications, 2014, 50(17):137-141.
A
TP181
10.3778/j.issn.1002-8331.1210-0141
国家自然科学基金(No.71071047);高等学校博士学科点专项科研基金(No.20090111110016)。
徐俊芬(1988—),女,硕士研究生,研究领域为电子商务、数据挖掘;叶俊杰(1977—),男,博士研究生,讲师,主要研究领域为网络营销、数据挖掘;刘业政(1965—),男,博士,教授,主要研究领域为电子商务。E-mail:xujunfen88@163.com
2012-10-15
2013-01-08
1002-8331(2014)17-0137-05
CNKI网络优先出版:2013-01-18,http://www.cnki.net/kcms/detail/11.2127.TP.20130118.1024.004.htm l
