A Corpus-based Study on Collocation and Colligation of "Soil" in Agricultural English
2014-07-02HuJiayingandSunYuanyuan
Hu Jia-ying, and Sun Yuan-yuan
College of Humanities and Law, Northeast Agricultural University, Harbin 150030, China
Introduction
Collocation is one of the most significant fields in the research of corpus linguistics, it has been the central focus in researchers. A corpus-based study on collocation has gradually increased in recent years.However, researches on the collocation in ESP (English for Specific Purposes)are not too many. The British linguist Firth (1957)first defined "collocation" as"You shall know a word by the company it keeps".Generally, collocation can be broadly defined and narrowly defined. In broad definition, words can be called "collocation" when the co-occurrence of them can reach a statistically significant level.Syntax and semantics are not within consideration.In narrow def i nition, collocation is strictly inf l uenced by grammar and grammatical structures. The latter has been accepted by most researchers, which gives consideration to lexical factors and grammatical factors, thus it has both qualitative standard and quantitative standard. It is suitable for the practical study based on small-scale corpus (Yang, 2002).Colligation is the collocation relationship in the level of grammar, it is the co-occurrence of word class and grammar class (Wei, 2002). Halliday and Sinclair had put forward a set of concept and collocation method such as node, span and collocates. This set of method brought about significant change in collocation research. This paper was accomplished under this research method and took the definition of collocation by Wei (2002)A collocation is a conventional syntagmatic association of a string of lexical items which co-occur in a grammatical construct with mutual expectancy greater than chance as realization of meaning in texts. The collocation standard in this paper was that collocates first should reach a statistically signif i cant level and then their syntax and grammar restrictions should be considered.
ESP had become one of the most important fi elds in English language. Agricultural English is a signif i cant branch in EST (English for Science and Technology).Teachers and students are often facing with some difficulties in collocation in their teaching practice and English learning and writing process, especially in the group of postgraduates and doctors who need to publish English academic papers in SCI or other international academic journals to get their degrees.However, there is no specialized corpus on agricultural science and technology English at present for students to use.The greatst signif i cance of the study lied in the real-using language data, and all the articles in this paper were selected from the international journal European Journal of Soil Biology which covers all aspects of soil biology with the impact factor of 2.146 in 2013. The strong corpus evidence and effective means of research methods presented the typical context and form. According to the real collocation examples, researchers could analyze and summarize the typical meaning of the words. Therefore, using this method to research agricultural science and technology English had a more objective, concrete and typical significance. This study was based on the idea of building an agricultural science and technology English corpus, and trying to provide a research method for building the corpus. The purpose of the study was to fi nd out the typical collocation of the key word "soil" in agricultural English, and also the verb collocates in front of "soil" and the preposition collocates after "soil", so as to reveal the general collocation regulations between keywords and the high frequency words. The results could help English learners to get the common-used collocation in academic papers and then they could use them in their own academic writing and translation practice.
Collocation Study in China and Abroad
The British linguist Palmer (1933)undertook corpusbased research on recurrent combitions of English words, which resulted in a description of over 6 000 such collocations. This research led Palmer to conclude that collocations exceed by far the popular estimate of the number of simple words contained in our everyday vocabulary, thus calling for a reconsideration of the nature of vocabulary (Kennedy, 2000).
Since the 1990s, corpus linguistics study in China had developed rapidly. In corpus linguistics, the study on collocation had not only started, but also in its central place (Yang, 2002). In early June of 2013, the author took "corpus" and "collocation" as keywords and retrieve in CNKI academic pool, which got a result of 4 604 articles. Thus, we could see that in recent years many researches were focusing on a corpusbased study on collocation and the achievements were productive. Among these articles, the trend showed that researches had been gradually into the various branches of English language, including EST, legal English, engineering and construction English. The research achievements on collocation in EST mainly included Zhang (2012, 2008), Song (2012), Qin (2011),He and Zhang (2011), Wei (2009), Yu (2008), Ruan(2006)and so on.
Research Design
Data collection
Because of the situation that nowadays there is no specif i c corpus on agricultural science and technology English, the writer built a small-sized corpus as the research object when writing this paper. The data was collected from the European Journal of Soil Biology published in 2012. From Volume 56, the writer chose 30 articles with the keyword "soil" in the title and kept the abstract and body parts (not including the graphic,charts, reference and acknowledgements).
Research method
According to Wei (2002), there are three methods to study collocations by using corpus linguistics:(1)data-based approach, based on corpus evidence,refer to colligation, check and summarize the collocation behavior of words. This method is artificially observation and description without using statistical measurement; (2)data-driven study, extract the node word and all collocates from the corpus, use statistical measurement to calculate the collocates and the co-occurrence degree of the words, then fi nd out the typical collocation; (3)extract clusters from the corpus. This paper combined the data-driven method and data-based approach together. Firstly, the writer used the data-driven method to fi nd out all the collocates of the node word "soil", and then referred to the colligation to describe the concrete collocation behaviors based on the high-frequency collocates.
Collocates
Collocation is the study of the typical co-occurrence of words. Fundamentally typicality is the matter of probability. The main measurements for calculating the collocates are as followings, MI (Mutual information)value, MI3 value, Z-score, T-score, Log-log score, Loglikehood ratio, Dice coeff i cient and so on. When calculating the collocational strength in this paper, the writer took MI value, MI3 value, T-score and Z-score of the collocates of "soil" to observe (Tables 1 and 2).The results showed that MI value and MI3 value tended to treat the low-frequency words (such as "status",which appeared twice and "aggregator", which appeared once)as the strong collocates of "soil". This kind of word did not coincide with the principle of "cooccur frequently in corpus" and could not reflect the typicality of collocation, therefore, it could not be called "collocation". Z-score had the similar problem.While MI3 value laid particular stress on high-frequency words, such as the functional words "the","and"and "in". This paper aimed at analyzing the practical application of the collocates of "soil" in agricultural English, mostly the content words. In this way, T-score was the chosen measurement because collocates with high T-score were mostly content words. From the statistics of T-score, words such as"fauna", "CO2", "moisture", "temperature”, "fluxes",on the one hand, their own frequency was high; on the other hand, their co-occurrence with the node word"soil" was also high. Therefore, taking these words as the strong collocates of "soil" was more suitable to the practical language application than other measurements.
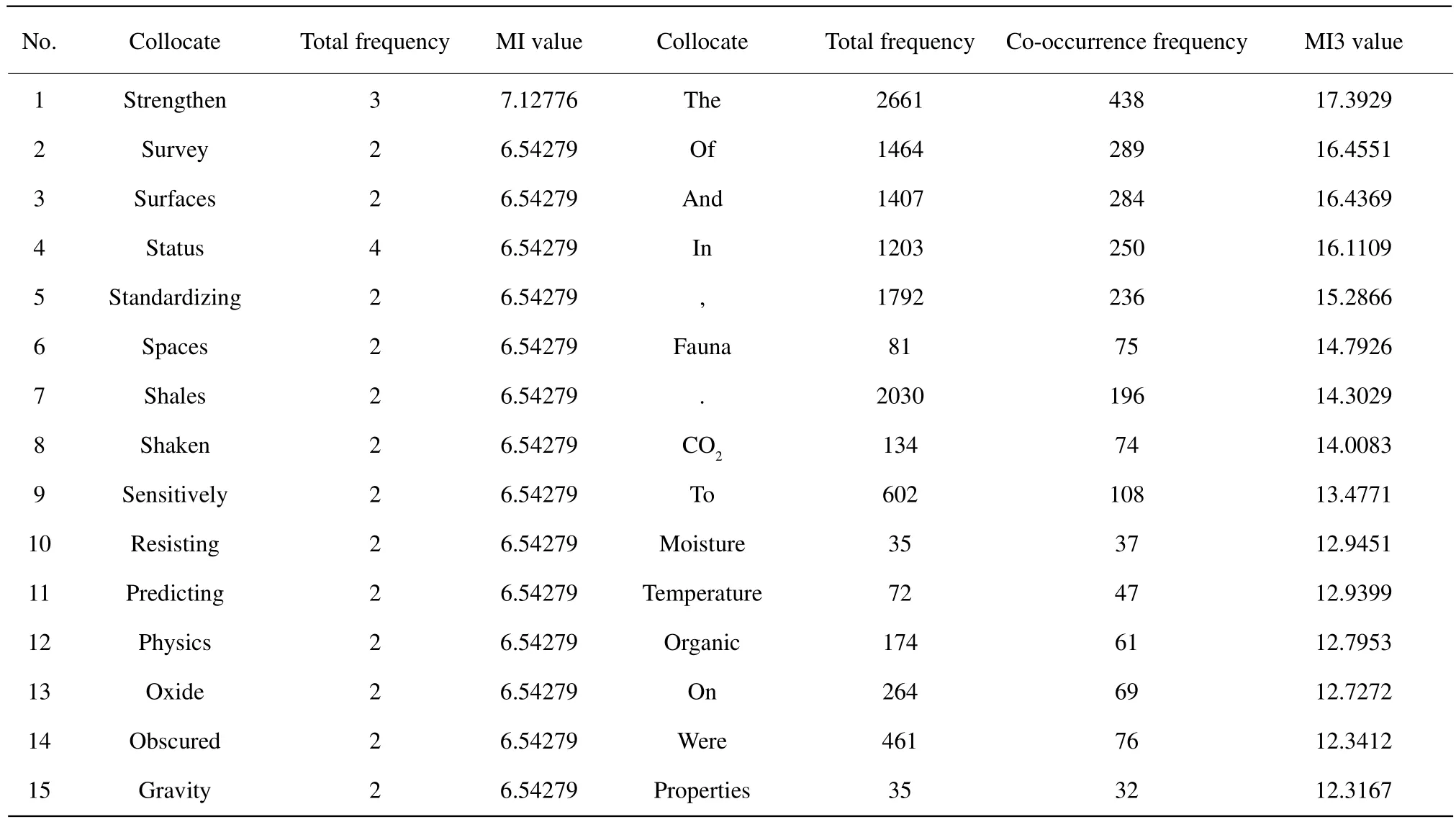
Table 1 Collocates of "soil" arranged by MI value and MI3 value
Results and Discussion
In this research, "soil" was chosen to be the node word, the span was 5. The observed frequency of"soil" in this corpus was 797. All the words within the span were called collocates. In this corpus, according to T-score, the front 100 collocates included 57 nouns,17 adjectives, 14 verbs and 12 functional words.The data showed that language communication was mainly lexical-driven and the nominalization was very common in EST texts. The fi xed noun collocation was also very common in ESP texts. In this section, the writer would extract different categories of collocates to describe, analyze and summarize.
Table 2 clearly showed that among all the collocates of "soil", the word "fauna" enjoyed the highest value.The total frequency of "fauna" was 81, while the cooccurrence frequency with "soil" was 75. From all the hits, we could see that mostly "fauna" appeared after the node word "soil", so the typical collocation was"soil fauna".
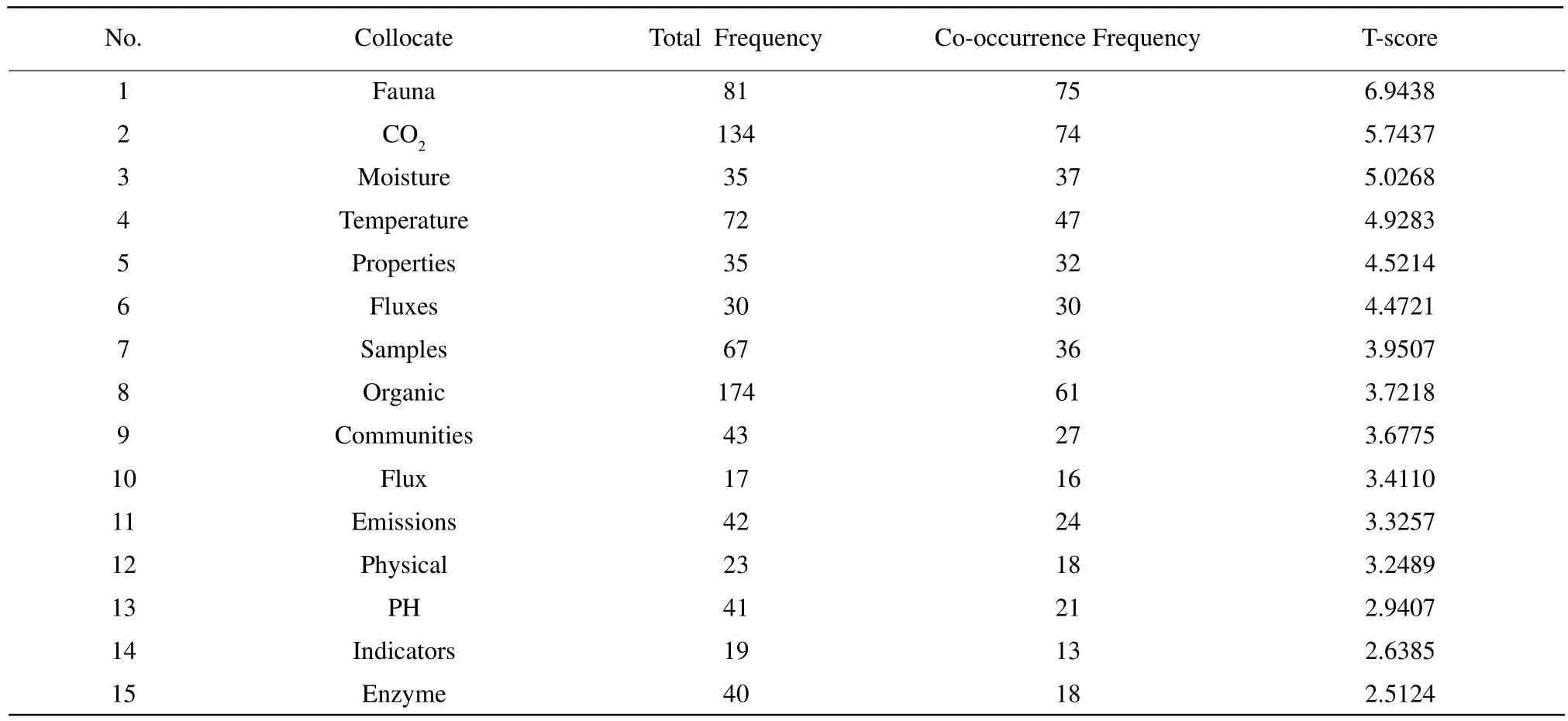
Table 2 Collocates of "soil" arranged by T-score
The collocation emphasizes the "company" of words;another concept related to collocation is colligation. Colligation also focuses on the relationship of "company", not the company of words, but the company of word class and even the grammatical level. For example, adjectives and nouns often constitute a kind of colligation (Liang, 2010). In this corpus, just as the hits of "soil" and "fauna", the collocate "fauna" on the right of "soil" was a noun, so we could call it the colligation of "N+N". What's more,the colligation not only exists in the fi eld of words, but also in phrases or grammatical categories. Colligation could be seen as the higher level of collocation, which had a close relationship with language syntax. From the 75 hits, we could count that on the left of "soil", the functional word "of (the)" had the most high frequency of 42, thus, we could see that "n(pl)+ of (the)+soil +N" was one of the colligations of "soil". Examples are as the followings:
(1)Of richness and diversity of soil fauna, and abundances were
(2)Of each taxonomic group of soil fauna varied with litter species
(3)Higher species richness of the soil fauna than components monoculture litter
(4)Support more species richness of soil fauna than the components of
(5)Abundances of 12 groups of soil fauna comprising more than 95%
(6)To examine the influence of soil fauna on the remaining litter
(7)Richness and abundance of the soil fauna between litter treatments.
(8)Showed the highest richness of soil fauna, while P.
(9)Indicating that most groups of soil fauna were detected during the
(10)Many components of the soil fauna were most abundance in
(11)And predicted values of the soil fauna community compositions in the
(12)And fauna, degradation of soil labile organic carbon in lab
(13)Llitter mixing effects on the soil fauna communities.
(14)Of litter mixing on the soil fauna assemblages.
(15)The responses of soil fauna to the litter mixtures
(16)Restricted the activities of the soil fauna in the litterbags.
According to this research method, we could also study on other collocates of "soil", such as CO2,moisture, temperature, properties, fluxes, samples,communities and so on. We could get some fixed phrase collocations such as soil CO2flux(es), soil CO2emissions, soil moisture and temperature, soil(physical/chemical)properties, soil samples, soil enzyme activities, soil bulk density, paddy soil, and soil crusts, these phrase collocations were mostly professional terms. This phenomenon also showed the character of specialty in agricultural science and technology English vocabulary. In agricultural science and technology English, some common words also have their own characteristics in collocation.For example, the analysis of word "impact" is as the followings: the total frequency of "impact" in the corpus was 17, its co-occurrence frequency with "soil"was nine. The followings are the retrieve lines of the co-occurrence of "impact" and "soil":
(1)Remarkable positive impact on the soil development.
(2)Magnitude of the impact of soil mendments on CO2emissions from
(3)Interaction of plant-released allelochemicals with soil microorganisms largely determines the impact
(4)Extent of the impact of soil fauna on litter decomposition differs
(5)Magnitude of the impact of soil amendments on soil CO2emissions
(6)Impact of soil amendments on soil CO2emissions depends primarily on
(7)Combined impact of climatic and soil factors on seasonal variation of
(8)Impact of soil amendments on soil CO2emissions primarily depends on
(9)Magnitude of the impact of soil amendments on soil CO2emissions
In Oxford Advanced Learner's Dictionary (OALD),the word "impact" has two lexical categories: as a noun, it means "the powerful effect that sth has on sb/sth", the application is "impact (of sth)(on sb./sth)"; as a verb, it means "to have an effect on sth", the application is "impact (on/upon)sth". By observing the retrieve lines, all the "impact" co-occurred with"soil" were served as "nouns". The total frequency of "impact" in this corpus was 17, the frequency of being a noun was 14, which was also a proof that nominalization was a common phenomenon in EST texts, this kind of word also included "influence","bulk" and so on.
According the above retrieve lines, the collocation of "soil" and "impact" could be summarized as follows:
(1)The impact of + "soil phrase"+ on+ N, means""soil phrase" has an effect on sth."
(2)Impact +on + "soil phrase", means "sth has an effect on 'soil phrase'"
In the following section, some other verbs will be extracted randomly. Took "measured" as an example,the total frequency of "measured" in the corpus was 21, and its co-occurrence frequency with "soil" was 10. The retrieve lines are as the followings:
(1)Soil physical parameters were measured following
(2)The bulk density of the soil samples was measured with stainless
(3)Of seven most widely measured soil enzyme activities , and found
(4)Room temperature. Major soil characteristics were measured using the
(5)Content was extracted from in soil slurry and then measured as (previously described)
(6)where F is the soil CO2flux measured in the(f i eld)
(7)and T is the soil temperature measured in the fi eld
(8)Using an elemental analyzer. Soil bulk density was measured using
(9)To temperature and moisture. Soil CO2fl ux was measured using
(10)C · g-1and 31 mg TN · g-1. Soil CO2flux was measured using
The use of "measured" could be summed up as the following four aspects:
(1)N phrase+were/was measured+with/following/using, this type appeared for seven times, which was the most frequent one. Its corresponding colligation was "N+be (were/was)+measured+adverbial modifi er".
(2)"Measured" served as the postpositive attributive, which appeared for two times. The example was"T was the soil temperature measured in the field".In this sentence, the part before "measured" was the noun or phrase that "measured" modified, and was followed by the adverbial modif i er. Its corresponding colligation was "be+ (the)N+measured+adverbial modif i er".
(3)"Measured" served as the pre-modifier, which appeared only once in the retrieve lines. The example is:
of seven most widely measured soil enzyme activities
According to the analysis above, the collocation of"measured" and "soil" was relatively objective. This research method was also applied to other verbs like"correlated", "improve", "extracted" and "affect". By analyzing the above verbs, we could also get their typical collocation and colligation, the result we had got could be directly applied in practice.
Conclusions
Using the corpus-based research method to analyze the word "soil", the writer objectively described and analyzed the collocation and colligation of "soil" in the academic papers. The study enriched the academic position of Firth school, that is, collocation is the cooccurrence of words and the statistical measurement is the important method. In this research, the signif i cant point was to summarize the collocation and colligation of node word according to the corpus evidence, instead of imposing the grammar system upon the corpus evidence or one-sided emphasizing the syntactic restrictions on word behavior. Words and grammar could influence each other just as the relationship of collocation and colligation. The ideal collocation study is to integrate collocation and colligation together: any descriptions of collocation behavior should refer to the colligation of the node word; any descriptions of colligation should be based on the real behavior of the collocates.
In terms of academic paper writing and translation,the corpus linguistics method will help English learners and teachers to fi nd the common collocation in academic papers so as to write or translate academic papers and improve their own English. We believe that the significance of this method, that is, using corpus research to help English learners with their academic writing and translation is higher than the research itself. Both teachers and students should make full use of the corpus and realize its great importance in teaching and learning. Due to the limitations of the self-built corpus, this corpus had its restrictions. In this research, all the collocates chosen to be analyzed had strong collocation relationship with the node word "soil", and all the examples were chosen from the retrieve lines of the collocation of"soil". If we consider the collocation of the analyzed word in the whole corpus, the result will be totally different, which is the limitation of this research. In this research, the writer chose "soil" as the node word,and some of its collocates in agricultural science and technology English to analyze, the results showed that this research method was available in building a corpus on agricultural science and technology English in the future.
Biber D, Conrad S, Reppen R. 2000. Corpus linguistics. Foreign Language Teaching and Research Press, Beijing. pp. 265-269.
He Y, Zhang J D. 2011. A corpus-based study of model verbs in EST texts. Journal of Donghua University (Social Science), 3(11): 73-77.
Firth J R. 1957. Papers in linguistics 1934-1951. Oxford University Press, London. pp. 11.
Kennedy G. 2000. An introduction to corpus linguistics. Foreign Language Teaching and Research Press, Beijing. pp. 244-246.
Liang M C, Li W Z, Xu J J. 2010. Using corpora: a practical coursebook. Foreign Language Teaching and Research Press, Beijing. pp.12-13, 203-211.
Qin S J. 2011. Study on collocation in gene related news based on corpus linguistics. Yanshan University, Yanshan.
Ruan Y. 2006. A corpus-based analysis of nominalization structures and its ideational functions in EST. Huazhong University of Science and Technology, Wuhan.
Sinclair J. 1991. Corpus, concordance, collocation. Shanghai Foreign Language Education Press, Shanghai. pp. 109-121.
Song Y. 2012. A corpus-based study on nominalization of verbs and adjectives in legal English. Henan Normal University, Henan.
Thomas J, Short M. 2001. Using corpora for language research.Foreign Language Teaching and Research Press, Beijing. pp. 162-175.
Wei J J. 2009. A corpus-based study on collocation in English for science and technology. Donghua University, Shanghai.
Wei N X. 2002. A corpus-based and corpus-driven study on collocation.Contemporary Linguistics, 4(2): 101-104.
Yu Y. 2008. An experimental study on teaching and learning EST sub-technical terms by collocation. Shanghai International Studies University, Shanghai.
Yang H Z. 2002. An introduction to corpus. Shanghai Foreign Language Education Press, Shanghai. pp. 7-8.
Zhang J D, Liu P. 2008. Collocation study on EST texts based on word form. Foreign Languages Research, 6(112): 28-35.
Zhang J D. 2012. A corpus-based study of lexis heterogeneity in EST texts. Shanghai International Studies University, Shanghai.
杂志排行

Journal of Northeast Agricultural University(English Edition)的其它文章
- Recent Progress of Commercially Available Biosensors in China and Their Applications in Fermentation Processes
- Wheat Generation Adding in Xundian County of Yunnan Province in Summer
- Screening of Optimal Differentiation Medium to Lonicera edulis
- High-solid Anaerobic Co-digestion of Food Waste and Rice Straw for Biogas Production
- Microsatellite Analysis of Genetic Diversity Between Loach with Different Levels of Ploidy
- Rapid Non-destructive Detection for Molds Colony of Paddy Rice Based on Near Infrared Spectroscopy