基于改进型DTW算法和MFCC的语音识别
2014-07-02陈孟元
陈孟元
(安徽工程大学 安徽省电气传动与控制重点实验室,安徽 芜湖 241000)
语音识别是通过机器识别将语音信号转变为相应的文本或命令的技术,属于多维模式识别和智能接口的范畴[1-2].近年来,语音识别研究取得了广泛关注和显著进步,其中小码本的孤立词语音识别系统识别率高,在工业命令控制、个人信息确认及个人移动通信呼叫等应用场合具有广阔前景[3-5].孤立词语音识别系统的识别单元是孤立发音的单词,在训练阶段熟悉和记忆说话人的语音特征,建立参考模板库,在识别阶段通过比对测试将具有最大声学相似性的模板作为输出结果[6].为了提高系统的识别率和识别速度,并使系统对语音的地域差别具有较强的适应性,在特征参数提取和模板匹配过程中,对DTW(动态时间归整[7],Dynamic Time Warping)算法和 MFCC(梅尔频率倒谱系数[8],Mel Frequency Cepstrum Coefficient)进行改进,基于MATLAB环境下的实验表明,该系统对于来自不同地域的语音具有较高识别水平.
1 系统工作原理
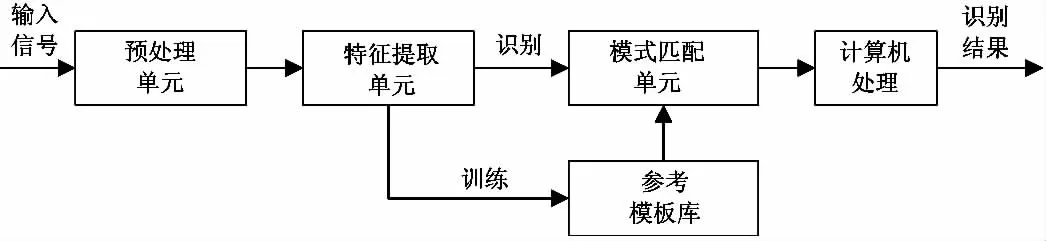
图1 语音识别系统的结构框图
语音识别系统的结构框图如图1所示[9-10].由图1可知,语音输入信号首先进入预处理单元,去除冗余信息,得到平稳的语音信号.语音信号包含发音人的语音特征,语音识别通过提取语音特征参数使机器具有一定记忆功能,这个过程称为训练阶段.在训练阶段,系统建立参考模板库,保存语音特征参数.参考模板库建立后输入测试语音,进行语音识别.在识别阶段,采用模式匹配的技术,通过匹配函数计算输入模板和参考模板间的声学误差,系统将误差最小的参考模板作为识别结果输出.
2 语音识别处理
2.1 预处理单元
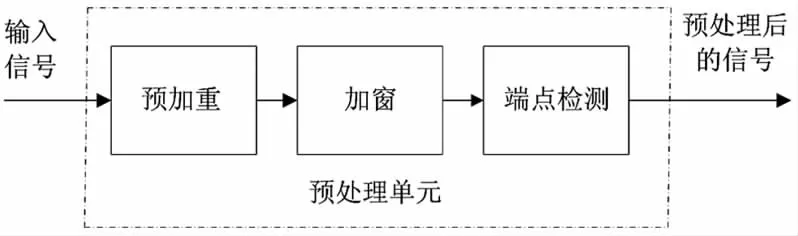
图2 语音信号的预处理过程
语音信号的预处理过程包括预加重、加窗和端点检测,如图2所示.
数字语音“0”的端点检测仿真图如图3所示.由3个子图组成,最上面的子图是语音信号波形图,横坐标为时间;中间的子图是短时能量检测图,横坐标为帧数;最下面的子图是过零率检测图,横坐标为帧数;图3中两竖线间的区域是端点检测出的语音段.数字语音“0”大致在115~185帧之间,帧移为80 检测的语音范围为第9 200~14 800采样点.
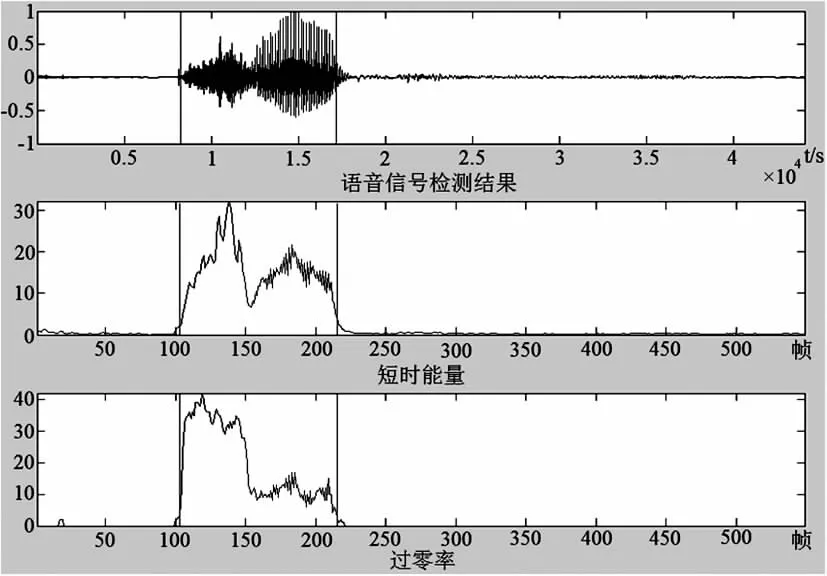
图3 数字语音“0”的端点检测仿真图
2.2 特征提取单元
特征参数提取的优劣对系统识别的精度有很大影响,在含一定噪声的语音识别系统中,采用MFCC作为语音的特征参数可使系统具有一定的稳健性.传统的MFCC只反映语音的静态特征,为了获得语音的动态特征,在提取MFCC基础上,整合差分倒谱参数作为语音的特征参数,提取过程如下:
预处理后语音时域信号y(n)通过补0构成长度为N的时间序列,N=512.时间序列经过FFT得到线性频谱Y(k).Y(k)通过Mel滤波器组得到Mel频谱,对数能量处理后得到对数频谱S(m).其中,Mel滤波器组由M个带通滤波器组成,总传递函数可表示为:
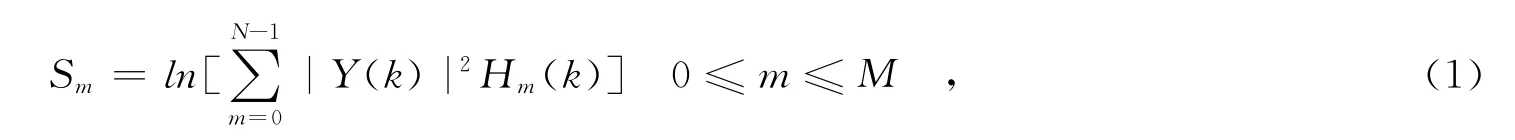
式中:Hm(k)为带通滤波器的传递函数.
将对数频谱S(m)通过DCT(离散余弦变换,Discrete Cosine Transform)变换到倒谱域,得到标准的MFCC,MFCC表示为C(n),

求出前3阶的MFCC,将各阶参数值乘以权重系数ε进行加权处理得到C*(n),

式中:k为待求MFCC的阶数.求取MFCC差分倒谱参数,将各阶MFCC差分倒谱参数和MFCC参数矢量合成,作为一帧语音信号的特征参数.MFCC差分倒谱参数的求取可表示为d(n):
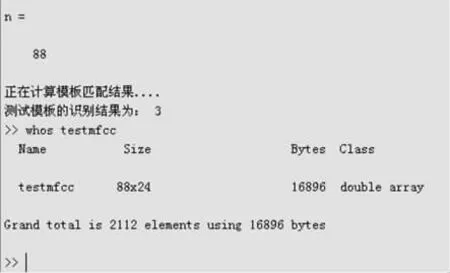
图4 数字语音“3”的MFCC数据结构图

在MATLAB环境下提取各语音信号的MFCC,数字语音“3”的MFCC参数数据结构图如图4所示.由图4可知,数据结构为88×24的二维矩阵,88为帧数,24为参数阶数.
2.3 模板匹配单元
模板匹配的过程中,为了规整参考模板和测试模板的时间对应关系,常采用DTW算法,可以求解出衡量模板间似然度的测度函数,保证最大的声学相似性[10].DTW算法通过计算参考模板和测试模板中各个对应帧之间的失真距离,得出帧匹配距离矩阵,绘制DTW网格.网格中的格点是对应帧的交汇点,按照距离最短原则搜索前续格点,反复递推得到一条最优路径,实现累积失真量最小.DTW算法在路径搜索的过程中,由于路径约束条件的存在,部分格点计算存在冗余,并且每列格点的匹配计算只与前列的两个网格相关,不用保存所有的累积距离矩阵和帧匹配矩阵.因此对DTW算法做出改进,有助于减小存储量,提高识别率和识别速度.改进型DTW算法流程图如图5所示,M为参考模板的语音帧总数,N为训练模板的语音帧总数,α为累积距离矩阵,β为帧匹配距离矩阵,m为参考模板语音帧的时序标号,n为测试模板语音帧的时序标号,int[]为取整函数.
3 实验结果与分析
为体现系统对语言地域差别的适应性,建立湖北、闽南和安徽3个地域的语音数据库,并与普通话语音作比对实验.选取的语音地域性显著,具有一定的代表性.

图5 改进型DTW算法流程图
3.1 地域语音识别的MATLAB实现
建立3处地域的方言和普通话语音组成的语音数据库,数据库包括0~9共10个语音样本元素,每位发言人将每个元素发音6遍,共240个发音.分别录制1个参考模板组和5个测试模板组,每个模板组包括0~9共10个汉语数字语音,参考模板组共包括来自语音数据库的40个发音,测试模板组共包括另外的200个发音.
在MATLAB环境下,提取语音的累积误差距离矩阵,湖北口音测试模板组1和组2的累积误差距离矩阵如图6所示,行对应测试模板中的语言,列对应参考模板组的语音1-10,矩阵中的数值为对应测试组之间的误差距离,dist为累计误差距离,椭圆圈出的数字为一行中最小的数.测试人从数字“0”开始朗读,一直朗读到数字“9”,按照改进DTW算法累积误差距离最短的原则,语音被完全识别的条件下,椭圆全部位于主对角线,连成直线,如果识别出现错误,会产生折线.累积误差距离矩阵表明,模板组1的测试语音均与参考模板中对应的正确语音匹配距离最小,模板组2第9行的测试发音“9”与第6列参考模板中数字发音“6”匹配距离最小.湖北口音测试模板组1和组2的识别结果如图7所示.进行比较分析可知,系统正确识别了模板组1的10个数字语音,将模板组2中的语音“9”识别为“6”,出现一处识别错误,DTW算法的计算结果与实验结果一致.

图6 湖北口音测试模板组1和组2的累积误差距离矩阵
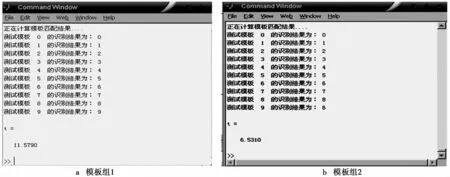
图7 湖北口音测试模板组1和组2的识别结果
3.2 改进型DTW算法和MFCC对系统性能的影响
系统采用不同特征参数和匹配算法的性能指标如表1所示,模板匹配时间是20个测试组的平均匹配时间,模板识别率是20个测试组的平均识别率,在4种组合方式下统计比对.
组合1和组合2均采用传统的DTW算法,MFCC提取方式不同.实验结果表明,组合2的模板匹配时间比组合1低6.73%,模板识别率比组合2高3.28%;组合2和组合4均采用改进型MFCC,DTW算法不同.实验结果表明,组合4的模板匹配速度比组合2高29.42%,模板识别率比组合2高3.17%.
通过其余组合两两比对表明,改进型MFCC虽然增加了系统运行时间,但提高了系统的识别率.改进型DTW算法提高了系统识别率,并且对提升系统运行速度作用显著.采用改进型DTW算法和改进型MFCC的组合4与采用传统DTW算法和MFCC的组合1相比,模板匹配速度提升了24.32%,系统识别率提升了6.56%.

表1 系统采用不同特征参数和匹配算法的性能指标
3.3 地域语音和普通话的识别结果
通过分别测试和整理,语音识别系统各测试模板的识别结果如表2所示.分别对普通话语音、湖北语音、安徽语音和闽南语音进行测试,每种语音有5个测试模板组,每个模板组将0~9这10个数字语音重复10遍,包括100个测试语音.普通话语音测试组正确识别率最高,平均识别率为98.6%,闽南语音测试组正确识别率最低,平均识别率为90.2%,湖北和安徽测试组的平均识别率分别为94.0%和95.4%.系统对所有测试模板组的平均识别率为94.55%.
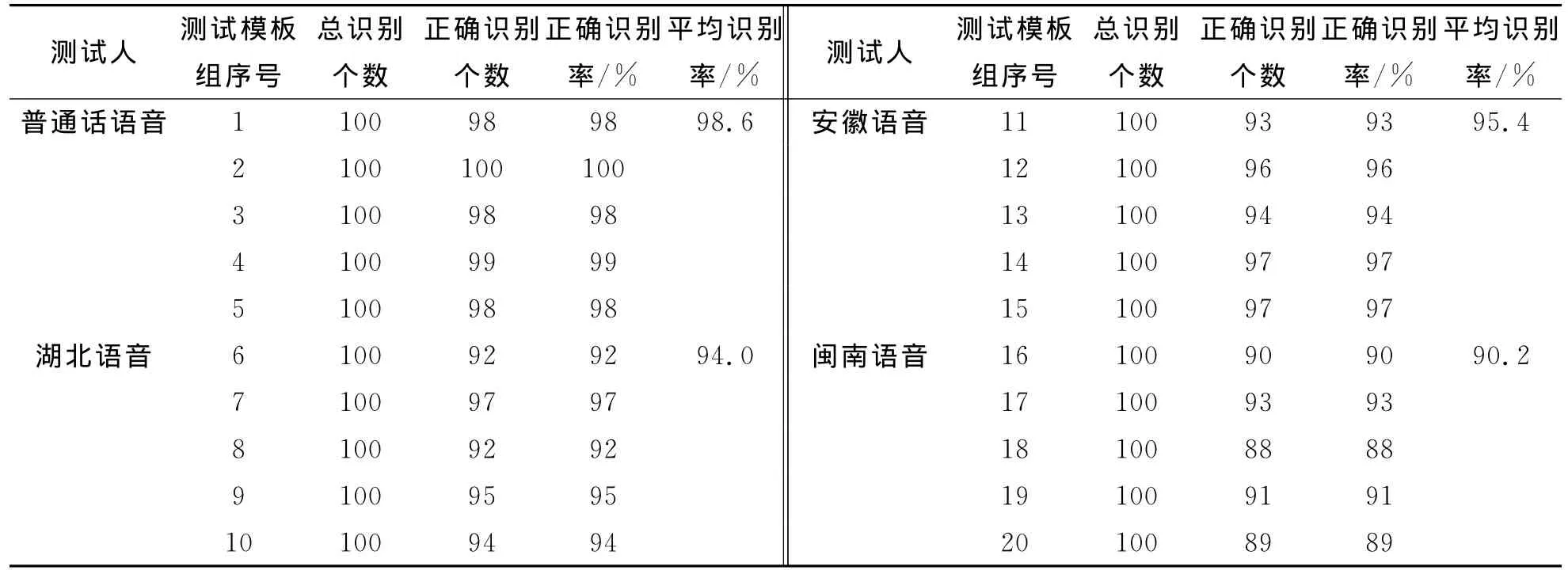
表2 语音识别系统各测试模板的识别结果
4 结论
为了提高语音识别系统的识别速度和正确率,并对不同地域的语音具有较好的适应性.在特征参数提取的过程中,将MFCC和差分倒谱参数结合为一帧的特征参数,并对传统的DTW算法做出改进,减小模板匹配的时间和计算量.采集了具有地域代表性的3省方言和普通话语音,在MATLAB环境下进行仿真实验.实验结果表明,改进型DTW算法提高了系统识别率,提升了系统运行速度;改进后的MFCC一定程度上增加了系统运行时间,但提高了系统识别率;基于改进型DTW和MFCC的语音识别系统比传统的系统识别速度高24.32%,识别率高6.56%;改进后的系统对普通话语音的识别率最高,对地域特征明显的语音识别率有所降低,所有测试模板的平均识别率为94.55%.
[1] 袁正午,肖旺辉.改进的混合 MFCC语音识别算法研究[J].计算机工程与应用,2009,45(33):108-110.
[2] 荣薇,陶智,顾济华,等.基于改进LPCC和 MFCC的汉语耳语音识别[J].计算机工程与应用,2007,43(30):213-216.
[3] 汲清波,卢侃,李康.在孤立词语音识别系统中动态时间规整的改进算法[J].计算机工程与应用,2010,46(25):118-120.
[4] 张震,王化清.语音信号提取中 Mel倒谱系 MFCC的改进算法[J].计算机工程与应用,2008,44(22):54-55,58.
[5] 安镇宙,杨鉴,王红,等.一种新的基于并行分段剪裁的 DTW 算法[J].计算机工程与应用,2007,43(15):35-36,89.
[6] 杨大利,徐明星,吴文虎.语音识别特征参数选择方法研究[J].计算机研究与发展,2003,40(7):963-969.
[7] 郭继云,王守觉,苑海涛.一种基于频能比的端点检测算法[J].计算机工程与应用,2009,31:49-51.
[8] 相征,尹成俊.基于基音频能值和梅尔参数的语音识别设计与实现[J].计算机系统应用,2008,9:86-89.
[9] 黄文龙.语音识别关键技术研究及系统实现[D].重庆:重庆大学,2010.
[10]舒琦.小词汇量的孤立词语音识别方法研究[D].武汉:武汉理工大学,2012.
