一种基于改进KNN的哈萨克语文本分类
2014-06-27古丽娜孜孙铁利胡西旦伊力亚尔库瓦特拜克
古丽娜孜,孙铁利,胡西旦,伊力亚尔,库瓦特拜克
(1.伊犁师范学院电子与信息工程学院,新疆伊宁835000;2.东北师范大学计算机与信息科学学院,吉林长春130117)
一种基于改进KNN的哈萨克语文本分类
古丽娜孜1,2,孙铁利2,胡西旦1,伊力亚尔1,库瓦特拜克1
(1.伊犁师范学院电子与信息工程学院,新疆伊宁835000;2.东北师范大学计算机与信息科学学院,吉林长春130117)
将文本分类理论应用于哈萨克语中,给出了哈萨克语文本预处理过程.介绍一种改进的KNN算法,并结合自己构建的哈萨克语料集实现基于改进KNN算法的哈萨克语的文本分类.仿真实验数据表明,该方法在哈萨克语的文本分类上获得了较好的效果.
哈萨克语本分类;词干提取;向量空间模型;相似度;KNN
0 引言
文本分类(Text Categorization)是一项基本的数据挖掘技术,是依照实现定义好的特定类别,为语料集中的每篇文档确定一个所属类.在文档的组织和管理、搜索引擎对网页的排序、数字图书馆、邮件的过滤、文本过滤、信息安全保密、自动文摘、分类新闻组等领域里文本分类发挥着重要的作用.
在文本自动分类技术方面,不同文种存在许多共性,但由于各语言语法结构之间的差异,使得基于其他语言文本分类的研究成果,不能简单地用于哈萨克文文本的分类问题上,绝大部分技术的工作原理只能作为参考,因此需要研究出适用于哈萨克语自己的文本分类理论体系.针对哈萨克语语法体系及其文本信息的独有特性需要研究出适合哈萨克语文本的分类模型和方法,实现哈萨克语信息的智能挖掘.该研究对促进地区哈萨克族的科研、文化教育、宣传出版等工作具有重要的意义和实际应用价值.将文本分类理论运用到哈萨克语文本分类工作是我们开创性的特色研究.
目前文本分类算法主要有支持向量机(SVM)、尽近邻算法(KNN)、Naive Bayes算法等.在文本表示方法中向量空间模型(VSM)的文本表示格式较直观,所以大部分包括以上几类文本分类方法一般都利用VSM来表示文本.当直接应用这些传统分类方法来解决问题时一般都会存在缺点,因此大多数领域一般采取改进方法或者混合方法来达到最终目标.比如,KNN方法就是一种无参、简单、稳定性较高的方法.但是,KNN算法设计原理本身就简单,在具体应用时往往露出其懒性缺点.为了提高KNN方法效率,王煜、李杨、李荣陆等人对KNN方法进行更深入地研究,并提出快速KNN算法、索引表快速方法和基于密度的修剪方法等一系列的改进方法,并取得了较好的分类效果.本文提出通过减少样本间相似度的计算量来解决KNN分类方法的巨大搜索空间困难的一种改进KNN方法.[1-11]
1 文本预处理
文本分类工作当中首先对文本进行预处理,也就是让计算机来表示出文本,之后才能对其进行特征抽取.
文本预处理主要是从文本中提取关键词来表示文本的处理过程.在预处理过程中,首先要将连续的语句分隔为分散的有独立意义的词集,然后去除集合中的停用词,获得文本的关键词集合.
当然,在书写语法格式不同的语言文本中提取独立意义的关键词时,很显然要采取不同的切分、组合的提取技术.例如,英文文本需要提取词干、中文文本需要切分词等.鉴于哈萨克文文本信息的特性,即哈萨克文文本中词与词之间已经是以空格分开的,所以我们不需要对其进行切分词,但需对其进行提取词干.
首先解决以下几个重要问题:(1)由于各种语言语法体系结构的不同,就不能简单地套用以其他语言为背景建立的(如,英文,维文,蒙文等)文本词干提取算法.我们必先研究实现适合哈萨克文语法体系的词干提取算法.(2)为实现文本分类任务还需要一定规模的语料库,但在哈萨克语言中到目前为止还没有一个公认的哈文语料库,必需先建设构建一定量的语料集,为分类算法提供数据平台.
文本预处理是影响文本分类准确度的关键因素之一,只有解决了上述2个问题,才能标注样本,之后选择最合适的文本分类算法实现分类任务.由于篇幅问题下面对这两环节只进行简要介绍.
1.1 哈文预处理
哈萨克语的单词都是通过单词原形的后面或前面加附加成分构成的,这就说明哈萨克语是一种典型的黏着语.因为这个特点,可以让一个哈萨克语单词对应多个字符串形式.例如,哈萨克语中词根(月亮),在其后加等各种附加成分后,可以演变出等多词.但是,任何一种词典规模都是有限的,不可能收录所有的语法演变形式.所以,在哈萨克语预处理工作时,要找出单词原形即词干与相应的多个字符串之间的连接对应关系,也就是要找出文本中词的原形.这就是哈萨克语词的词干提取过程.
哈萨克语分词中,有些构形附加成分单独还可以表示一定的意义,所以除了词干提取以外有时对构形附加成分还要进行细切分,否则不能准确领会整个单词的含义,例如,词“”中的“”就是一种附加成分,其含义是“山”的意思,而整词“”是“火山”的意思;词“”中的“”就是一种附加成分,其含义是“马”的意思,而整词“”是“平安”的意思.因此,对于哈萨克语词干提取方法的研究应和其构形语素的分析同时进行.与此同时还需考虑原词干连接处的边界字母有时会发生一些变化的情形,即根据哈萨克语语法规则,在有些词干后面连接需要的附加成分时,原词干的连接处边界字母会发生一些变化,如,;;;等,因而,在词干表中找不到完全匹配的这些词干,根据语法规则像这样典型的情况还得加以分析并解决.在附加成分的切分和词干提取过程中,出现歧义词切分情况又是必然现象,所以本文算法同样考虑到可能出现的几种歧义词现象并给出针对处理方法.
哈萨克语中除了少数从外来语引进的词前缀以外,绝大部分单词都是通过在原词干的后面按一定规律连接各种词缀构成的.哈萨克语中的构形附加成分之间也有严格的连接规则,这有助于对词附加成分进行正确切分.名词、动词、形容词、数词、代词和副词中,名词和动词是哈萨克语中数量最多的词类,由此,可以引用有限状态转录机(Finite State Machine,FSM)来较方便地为哈萨克语单词建立词干模型.
本文在词性有限状态自动机的基础上利用双向全切分和词法分析相结合的改进方法来实现了哈萨克语的词干提取和构形附加成分的细切分.通过采用改进逐字母二分词典查询方法来搜索词干表,提高词干提取效率.在上述研究工作的基础上,实现哈萨克语单词的词干提取,解决了哈萨克语文本的读取预处理问题.程序运行结果如图1所示,图1中很容易看到原词及其切分后的词干.
本文研究对词干切分所做实验的评测标准主要以附加成分切分的正确率(Precision1)和歧义词切分排除率(Precision2)两方面来进行定性评价的.这2种评估指标分别为:

图1 哈文词干切分结果示例
词干提取正确率
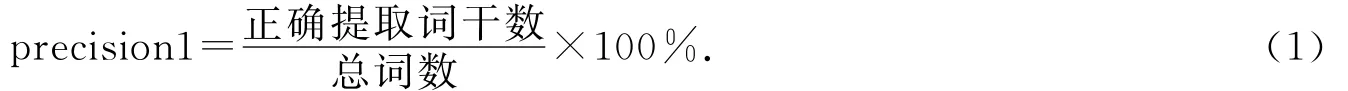
歧义词切分正确率

表1为本文词干提取所做实验结果数据综合分析表.

表1 词干提取实验结果综合分析
根据表1中的实验结果,我们可以得知本文提出的算法和处理方法具有较好的结果,达到了预期的研究目标.
当然,这一算法依赖于原始词典(词库),词典的内容直接影响切分正确率.比如,由于有些新词汇(流行词)还未录入到词典里,词典词汇较旧,就会直接影响切分效果.因此,词典的建立与维护非常重要.因模型参数的训练不足,歧义词切分概率尚不理想,在今后的研究工作中,有待提高模型参数的可信度.
为了达到如图1所示的实验目标结果,我们还做出了以下2项主要的基础性准备工作.
(1)以哈萨克语文本分类为主题.沿着实现哈萨克语词干提取任务要求先筹备了对应词干表和附加成分表,而这表里已收录了由新疆人民出版社出版的《哈萨克语详解词典》中的6万多个哈萨克语词干和438个哈萨克语附加成分.附加成分的详细分类在附加成分切分阶段进行词法分析时非常有用.哈萨克语语法体系规定将附加成分分为构形附加成分和构词附加成分两大类.其构词附加成分分为动词、形容词、数词和副词附加成分等4种,而构形附加成分分为谓语性人称、格附加成分、领属性人称附加成分、复数附加成分等4种.
(2)关键环节是哈萨克语料库的建设.实现任何分类任务首先应具备一定规模的语料库,考虑到目前还没有一个公认的哈萨克语料库,为此本人通过翻译中文公认语料库里的部分文章内容来构建由交通、体育、农业、艺术、政治等5类共200篇文本组成的本文研究的语料集.这一些列研究不论从理论角度还是从应用角度都是非常重要的,在实际应用中具有重要意义.
1.2 文本模型
为了让计算机能够直接处理文本,首先要将文本由大量字符构成的字符串形式表示出来.向量空间模型是将文本由特征项和特征项权重组成的向量(W1,W2,…,Wm)形式表示出来的最经典的文本形式化表示方法,其中Wi为第i个特征项的权重.一般运用以下TF-IDF公式[1]来计算特征权重.
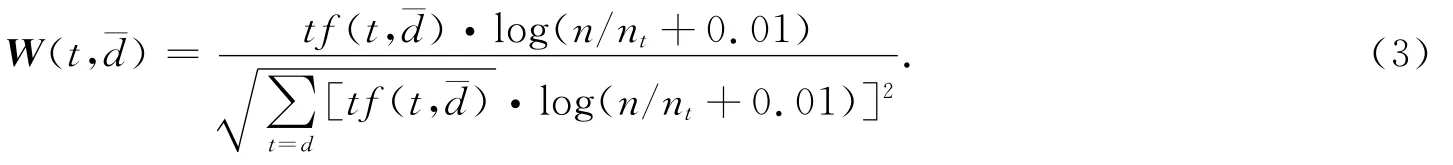
其中:W(t,d¯)为词t在文本d¯中的权重;tf(t,d¯)为词t在文本d¯中的词频;ni为训练文本集中出现t的文本数;n为训练文本总数.
通过以上处理和计算,文档集可由m行n列的词-文档矩阵(Term-Document Matrix)表示出来:

式中:m为文档集中所有不同词的个数;aij为第i个词在第j个文档中出现的权重.不同的词对应矩阵A的不同的一行,每个文档则对应矩阵A的一列.
2 基于改进的KNN分类算法
2.1 KNN算法
KNN算法是一种简单、有效、无参数的监督分类算法.KNN算法不需要特殊的数据来描述规则,其规则本身就是数据样本.算法原理就是根据待分类样本的k个最近邻样本来预测未知样本的类别.所以要使用KNN算法,必须明确最近邻样本的数目k和测量相似性的距离函数这2个基本因素.常用的有曼哈顿距离、欧氏距离等.关于计算文本相似度,一般都采用余弦公式,公式为:

其中Sim(di,dj)是文本di与dj之间的相似度,而wi,k是文本di中第k个特征的权重.
在具体分类时,先将待分类文本转换成与训练样本一致的向量空间模型;然后由公式(5)计算该文本与每个样本之间的相似度;再取相似度最大的k个样本,根据k个样本由公式(6)来计算属于每个类别的权重;最后将该文本归属到权重最大的那个类别中.

其中Sim(di,d)表示文本d与其k个最近文本di之间的相似度.

由以上公式可知,KNN算法先计算待测试文本与训练文本之间在该坐标系中的Cosine距离,然后才依据测试文档与训练文档距离的远近来确定类别,这就说明KNN算法的实质就是以特征属性权值作为特征空间的坐标系测度,由此不难给出分类问题的数学模型.
KNN分类过程的数学描述:
定义判别函数为
分类的决策规则:
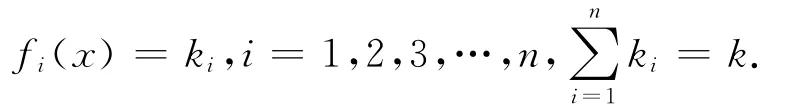
如果

则决策x∈Ci.其中:x为得分类文档;n为总的类别数目;k为训练集中与x距离最近的文档数(k≥1);
Ci为训练集中类别;ki为属于Ci类的文档数.
2.2 改进的KNN算法
传统的KNN分类算法要求计算要测试的样本与其他所有训练样本之间的相似度,因此,要处理大规模数据,算法时效受影响[9-10].本文提出了一种改进的KNN分类算法.该算法主要思想:最快速度找到n0个候选类别,然后将KNN算法应用到这个由n0个候选类别为中心的新的数据区域里,这样KNN算法的分类花的时间将会大大缩短.算法具体内容可以下三大阶段来描述.
初始化:总的类别数目n;n0=0.
第一阶段 基础工作——计算算法指标
step1:将每个类别的训练文本都表示成向量空间模型(即都以向量形式表示出来),分别求出各类别的均值向量,当做各个类别各自的中心向量Ci;
step2:求出训练文本与该类中心向量Ci的最小相似度Minsim,定为一个未知样本是否属于该类的阈值;
step3:求出该类训练文本与该类中心向量Ci的平均相似度Avesim,当做KNN分类选取代表样本的参考依据.
第二阶段 划出中心数据区域——快速得到文本x的n0个候选类别,其余的类别将不再考虑.
step4:取一个测试样本x,计算该测试样本与每个类别中心向量Ci之间的相似度Sim(x,Ci);
step5:若Sim(x,Ci)≥Minsim,则认为Ci对应的类可当做候选类别,否则放弃该类并不再对该类进行处理;回到step4一直扫完所有测试样本为止.
第三阶段 KNN分类——完成n0个类别中的最后文本所属类别.
改进算法优点:经过第二阶段的处理,将会排除n-n0个类别,这样测试样本x就只能属于n0个(n0≤n)个候选类别中一种,其目的就是快速排出明显不是x所属类别的那些训练样本,减轻KNN的负担.
3 实验结果及分析
文本分类工作中训练文本的质量直接影响分类器性能,因此选择训练文本是关键.KNN训练文本过程见图1.训练文本集合大多都是公认的、经人工分类的标准语料库.但是,对于哈萨克语文本来说,到目前为止还没有一个标准的语料库,因此为了实现文本分类任务,首先要做好哈萨克语语料的建设工作.考虑到语料集的鲁棒性,通过人工翻译公认中文语料库里部分文章来收集了本研究的语料集.所构建的语料集由交通、体育、农业、艺术、政治等5个类别的共200篇文本构成,其中给每个类分别准备了40篇文本.任意选取的120篇文本作为训练集,剩下80篇文本作为测试集.
对文本分类效果进行评估,其标准有查准率、查全率:

图2 KNN训练文本过程示例
这2个指标能够反映分类质量的2个不同的方面,因此通过综合考察这2项指标可得一个新的评估指标F1测试值,实验结果如表2所示.


表2 综合考察查准率与查全率的实验结果
实验的总体效果比起性能较好的分类软件来说有一定的差距.但本文研究以此效果来说明哈萨克文文本分类问题的可行性比成熟的其他文本分类技术和所达到的精度而言,还需迎接一系列挑战.改进算法在时效上也不是很理想,算法似乎以前期准备阶段所耗的时间代价来换来了较短的KNN分类时间,因而整体算法运转时间还是较长.除此之外影响算法精度的还有以下几方面的问题:(1)对哈语单词的切分处理,提取词干的准确度同样直接影响分类效果.由于被提出的哈萨克语词干提取规则还不够细致,文本内容的表示受到影响,从而导致特征选择的误差.(2)由于自制语料的质量和数量都不如已公认的标准语料集,会直接影响文本的最终分类.后续工作中有待增加文本数量,提高类别代表性.(3)所提出算法在划出中心文本区域时,避免不了类别边界处样本的误分、漏分或具有潜在特征样本的误分现象,而影响算法整体效率.
4 结论
本文介绍了一种基于改进KNN的哈萨克文文本分类的总体过程.在通过人工翻译收集的哈萨克文语料集的基础上编写程序实现了哈萨克文词干解析提取,解决了哈萨克文文章的读取预处理.用向量空间模型VSM来表示文本,基于改进KNN算法的基础上最终实现了哈萨克文文本分类任务,但仍有一些地方需要完善,无论是哈萨克文词干提取、语料集质量,还是算法本身从性能、执行效果上都有待于提高,在未来还需要进一步研究.
[1] 冷明伟,陈晓云,谭国律.基于小样本集弱学习规则的KNN分类算法[J].计算机应用研究,2011,28(3):915-917.
[2] GUO G,WANG H,BELL D.KNN model based approach in classification[C].Berlin:Springer Verlag,2003:986-996.
[3] GUO GONGDE,HUANG JIE,CHEN LIFEI.KNN model based incremental learning algorithim[J].Pattern Recognition Artificial Intelligence,2010,23(5):70l-707.
[4] 王煜,白石,王正欧.用于Web文本分类的快速KNN算法[J].情报学报,2007,26(1):60-64.
[5] 李扬,曾海泉,刘庆华,等.基于KNN的快速Web文档分类[J].小型微型计算机系统,2004,25(4):725-729.
[6] 李荣陆,胡运发.基于密度的KNN文本分类器训练样本裁剪方法[J].计算机研究与发展,2004,41(4):539-544.
[7] ZHANG BIN,SRIHARI S N.Fast k-nearest neighbor classification using cluster-based trees[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2004,26(4):525-528.
[8] GHOSH A K,CHAUDHURI P,MURTHY C A.Multiscale classification using nearest neighbor density estimates[J].IEEE Transactions on Systems,2006,36(5):1139-1148.
[9] 宋玲,马军,连莉,等.文档相似度综合计算研究[J].计算机工程与应用,2006,42(30):160-163.
[10] 周靖,刘晋胜.基于分类贡献有效值的增量删N模型修剪研究[J].计算机工程与应用,2012,48(3):185-189.
[11] 黄杰,郭躬得,陈黎飞.增量KNN模型的修剪策略研究[J].小型微型计算机系统,2011,5(5):845-849.
Textcategorization of Kazakh text based on improved KNN
Gulnaz1,2,SUN Tie-li2,Hurxida1,Yiliyar1,Kuwatbek1
(1.School of Electronics and Information Engineering,Yili Normal College,Yining 835000,China;2.School of Computer and Information Science,Northeast Normal University,Changchun 1300117,China)
Appling the theory of text categorization to the study of kazakh text,given the kazakh text pre-processing,introduce a improved KNN algorithm,implemented the Kazakh text preprocessing that based on the improved KNN method on the their own built kazakh data sets.The experimental results show that can obtain better classification performance in the kazakh text classification.
Kazakh text categorization;stemming;vector space model;similarity;KNN
TP 391.1 [学科代码] 520·30
A
(责任编辑:石绍庆)
1000-1832(2014)02-0063-06
10.11672/dbsdzk2014-02-013
2013-09-01
国家自然科学基金资助项目(61363066);教育部博士点基金资助项目(20110043110011);吉林省科技发展计划项目(20120302);伊犁师范学院资助项目(2012YB017).
古丽娜孜(1972—),女,讲师,博士研究生,主要从事文本分类、模式识别、智能控制研究.
