基于改进粒子群优化的文本聚类算法研究
2014-06-07王永贵刘宪国
王永贵,林 琳,刘宪国
(辽宁工程技术大学软件学院,辽宁葫芦岛125105)
基于改进粒子群优化的文本聚类算法研究
王永贵,林 琳,刘宪国
(辽宁工程技术大学软件学院,辽宁葫芦岛125105)
针对k-means算法的聚类结果高度依赖初始聚类中心选取的问题,提出一种基于改进粒子群优化的文本聚类算法。分析粒子群算法和k-means算法的特点,针对粒子群算法搜索精度不高、易陷入局部最优且早熟收敛的缺点,设计自调节惯性权重机制及云变异算子以改进粒子群算法。自调节惯性权重机制根据种群进化程度,动态地调节惯性权重,云变异算子基于云模型的随机性和稳定性,采用全局最优值实现粒子的变异。该算法结合了粒子群算法较强的全局搜索能力与k-means算法较强的局部搜索能力。每个粒子是一组聚类中心,类内离散度之和的倒数是适应度函数。实验结果表明,该算法是一种精确而又稳定的文本聚类算法。
粒子群优化;自调节惯性权重机制;进化程度;云变异算子;k-means算法;文本聚类
1 概述
文本信息量随着互联网不断的发展日益膨胀,人们亟需对这些庞大而又复杂的文本信息进行高效的组织和整理,以便能有效地定位满足用户需求的信息,文本挖掘是解决这类问题的主要技术。聚类是数据挖掘、模式识别研究的重要内容之一[1]。文本聚类的目标是将文本划分成若干个簇,使相同簇之间的内容相似度尽可能大,而不同簇之间的内容相似度尽可能小。
文本聚类的方法多种多样,其中,k-means算法简单、高效,是一种重要的文本聚类算法。但其对初始聚类中心选择敏感,许多学者对k-means算法进行改进。文献[2]通过对数据集进行多次采样和kmeans预聚类以产生多组不同的聚类结果,利用不同聚类结果的子簇之间存在的交集构造出关于子簇的加权连通图,并根据连通性合并子簇,提高聚类结果的质量。文献[3]利用混合Hausdorff距离作为相似测度实现数据聚类。文献[4]运用谱方法估计特征中心来初始化聚类中心。
粒子群优化 (Particle Swarm Optimization, PSO)[5]是一种源于对鸟类捕食行为模拟的重要群体智能算法。PSO初始化一群随机粒子,即随机解,然后通过迭代找到最优解。在每一次迭代中,粒子通过跟踪个体极值和全局极值来更新自己的速度与位置。该算法具有较强的全局搜索能力且概念简单,易于实现,作为一种有效的优化工具己被成功地应用到诸多工程领城[6]。但它自身也存在缺陷,在遇到局部极值时,粒子的速度迅速降低直到停滞,且很难跳出局部极值点,出现早熟现象,而惯性权重是粒子群算法一个重要参数,用以调节粒子群的搜索能力。
通过对k-means算法和粒子群优化的分析,本文提出一种基于改进粒子群优化的文本聚类算法。改进粒子群优化算法,增强其全局搜索能力、避免早熟收敛,并将改进后的粒子群算法与局部搜索能力较强的k-means算法相结合,以解决k-means算法对初始聚类中心选择过分依赖的问题。
2 文本表示
在聚类之前通常将文本转化成易被计算机识别的形式,然后计算文本间的相似性,根据相似性将文本划分成各个簇。
文本聚类问题中常采用向量空间模型(Vector Space Model,VSM)[7]进行文本表示。该模型将每个文本表示成空间向量,特征词作为文本的表示单位,向量的每一维是对应特征词在该文本中的权值。即把文本集x表示成(x1,x2,…,xn),xi的向量空间表示为(ω1(xi),ω2(xi),…,ωm(xi))。其中,m表示特征项的数目;ωj(xi)表示第j个特征项在文本xi中的权值。计算特征项权值的方法有很多,一般选用TF*IDF算法[8]。
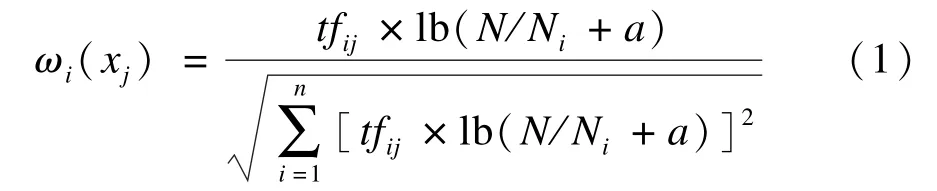
其中,tfij表示第 i个文本特征在文本 xj出现的次数;N为文档总数;Ni为文本集合中出现第i个特征词的文本数;分母为归一化因子。文本相似度是衡量文本间相似程度大小的一个统计量,是文本聚类的一个主要依据,计算方法有余弦法、内积法、距离函数法等。本文选用距离函数法中的欧氏距离法:
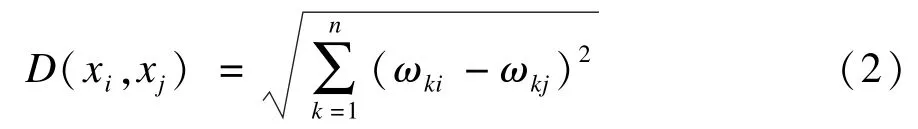
其中,ωki与ωkj分别为第k个文本特征在文本xi与xj的特征权值。
3 云理论
设U是一个用精确数值表示的论域,A为U上对应着的定性概念,对于U中的任意一个元素x,都存在一个有稳定倾向的随机数μA(x),记做y,y∈[0,1],y就叫作x对概念A的确定度,x在U上的分布称为云,记为 A(x,μ)。每一个 x称为一个云滴[9]。
云的数字特征——期望Ex,熵En和超熵He,用于反映云要表达的定性概念A的整体特性。其中,期望Ex表示论域空间U中最能够代表定性概念A的点,即这个概念量化的最典型样本点;熵En表示熵是定性概念随机性的度量,既反映了代表定性概念A的云滴出现的随机程度,又反映了在论域空间U中可以被语言值A接受的云滴值范围。超熵He表示超熵是熵的不确定性的度量,即熵的熵[10]。
生成云滴的算法或硬件称为云发生器[11]。下面对本文用到的基本云发生器的算法[12]进行介绍。
基本云发生器算法的具体步骤:
Step 1 生成期望为En,标准差为He的正态随机数En′。
Step 2 生成期望为Ex,标准差为En′的正态随机数x。x为论域空间中的一个云滴。
Step 4 重复Step1~Step3,产生n个云滴。
4 粒子群算法与k-means算法
PSO算法最初是受到鸟类捕食行为的启发,进而利用群体智能建立的一个简化模型。该算法将每个个体抽象成解空间中的点,具有位置和速度属性。所有的粒子都有一个适应度值,该值由目标函数决定,以评价粒子位置的优劣性。粒子通过跟踪个体极值和全局极值来更新自己的速度和位置,其更新公式如式(3)和式(4)所示。
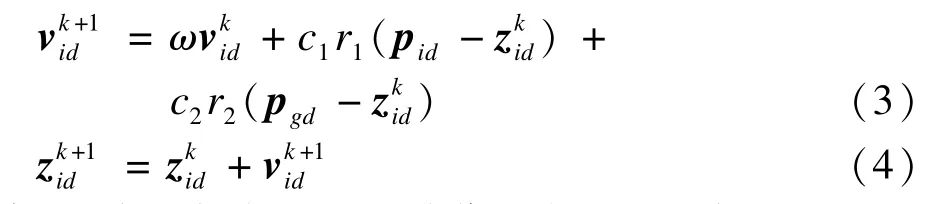
其中,zid为i个粒子的d维位置矢量;vid为粒子的飞行速度;pid为粒子迄今为止搜索的最优位置;pgd为整个粒子群迄今为止搜索的最优位置;ω为惯性权重,表示先前粒子的速度对当前速度的影响程度;r1和r2为[0,1]之间的随机数;c1和c2为学习因子,也称加速因子。粒子群算法具有较强的全局搜索能力,但它在优化过程初期收敛速度较快,易陷入局部极值,过早收敛。
k-means算法是一种典型的聚类算法,具有较强的局部搜索能力。假设将文本集合X中的n个文本分为m类。计算步骤为:选取m个文本作为初始聚类中心,计算每个文本到聚类中心的距离,将其划分到离其最近的类中,计算每个类中文本的均值作为新的聚类中心,重复该过程直到聚类中心不发生变化。从上述步骤可以看出聚类中心的选取对结果有很大的影响。因此,合理选择初始聚类中心是 kmeans算法的关键步骤。
5 改进的文本聚类算法设计
5.1 改进的粒子群算法
粒子群算法虽然简单、易于实现,但它自身也存在缺陷,其局部搜索能力较差,搜索精度不高,后期容易陷入局部最优,失去粒子的多样性,从而难以保证搜索到全局最优解。为优化粒子群算法,设计了自调节惯性权重机制和云变异算子,提高了算法的精度和收敛速度,保证能够有效地搜索到全局最优值。
5.1.1 自调节惯性权重机制
惯性权重ω是粒子群算法中一个重要的参数。从粒子速度更新公式中可以看出,当ω较小时,vid接近全局极值与局部极值的可能性较大,有利于全局极值的收敛。这在后期是非常有利的,能够加快算法的收敛性,快速向全局极值靠拢。但是在初期却不然,因为初期应大力探索新的解空间,寻找更好的全局极值。ω较大时情况与之相反。因此,较大的ω值有利于全局搜索,较小的ω值有利于局部搜索。现在最常用的方法是线性递减ω值,即先设置较大的ω值,增强粒子的全局搜索能力,随着迭代次数的增加ω值线性递减,最后局部搜索,得到精确极值。这样做从一定程度上可以改善粒子的搜索能力,但还存在一定的缺陷:首先,ω减小的速度较快,可能极值点所在的解空间还没搜索,就进行局部搜索了。其次,寻优初期可能找到极值点了,由于ω较大而跳过极值点。因此对ω值的调节不仅要依赖于迭代次数,还应依据整个群体的进化程度。为此,本文提出一种自调节惯性权重机制。


5.1.2 云变异算子
随着迭代次数的增加,种群多样性会逐渐减小,有可能发生早熟现象。因此,当种群进化到一定程度时对种群进行变异操作以提高种群多样性,从而避免陷入局部最优。基于云的模糊性和随机性,利用云的3个数字特征,即期望Ex,熵En,超熵He实现变异过程。
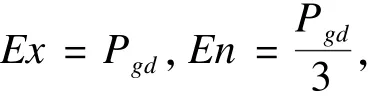
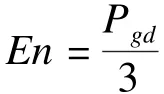
5.1.3 改进的粒子群算法描述
下面给出改进的粒子群算法的基本步骤。
Step 1 初始化种群。粒子的速度、位置、个体极值、全局极值等。
Step 2 计算粒子适应度值,比较各粒子适应度值,更新个体极值与全局极值。
Step 3 判断全局极值是否在规定代数内没有发生变化或达到变异阈值。如果是,则产生云变异算子,利用基本云发生器完成对所有粒子的云变异操作。否则,跳转到Step4。
Step 4 采用自调节惯性权重机制,即按式(5)计算惯性权重ω。
Step 5 按式(3)、式(4)更新粒子的速度和位置。
Step 6 若达到最大进化代数,输出全局最优值,算法结束。否则,跳转到Step2。
5.2 改进的文本聚类算法原理
5.2.1 粒子编码
现在大多数的粒子群聚类算法都采用实数或者浮点数的编码方式,即维数为d的若干个文本组成的文本集合聚成k个类,每个粒子的位置是k×d维的向量,速度跟位置具有同样的数据结构,所以粒子的速度也是k×d维的向量。其编码方式如图1所示。这种编码方式相对复杂,个体结构较长,必然会增加算法搜索的时间。
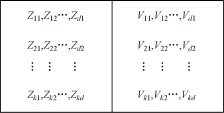
图1 多数粒子群聚类算法的个体编码结构
本文提出了一种新的个体编码方式,将文本集中N个文本编号,即1~N,用K个聚类中心在文本集中的编号代替聚类中心,其编码结构如图2所示。其中,Zi(i=1,2,…,K)是第i个聚类中心在文本集中对应的编号;Vi(i=1,2,…,K)是粒子的飞行速度。这种编码方式不仅使粒子长度大大减小,还能保证聚类中心的搜索空间不会随着粒子迭代次数的增加而增大,提高了算法的效率,是一种简单、有效且易于理解的编码方式。

图2 本文算法的编码结构
5.2.2 适应值函数
文本聚类的目标是使各类内文本距离之和的总值最小,本文使用欧氏距离进行文本间相似性度量,将适应度函数定义如下:
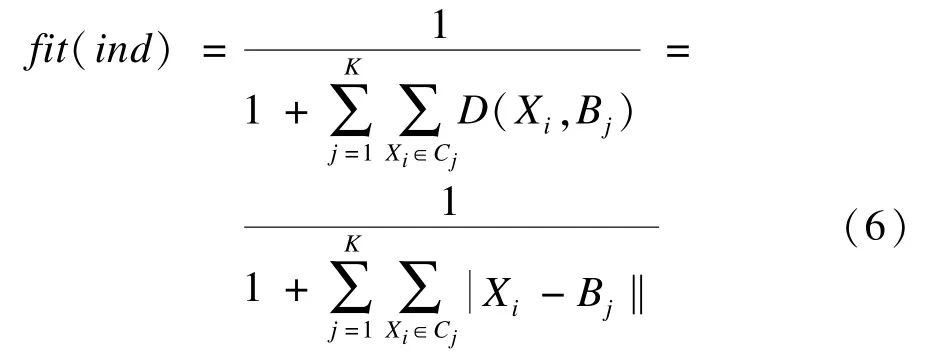
其中,K为聚类数目;Xi为类Cj中的文本;Bj为聚类中心,其实际意义是各类文本到其聚类中心距离的总和(即离散度之和)加1后求倒数,即为粒子的适应度值。这样,粒子的适应度与离散度之和成负相关,离散度之和越小,粒子的适应度值越大。
5.2.3 算法描述
基于改进粒子群算法的文本聚类算法可以描述为:
Step 1 种群初始化。将文本集合中N个文本编码为1~N,随机选择K个文本作为初始聚类中心,用文本编号作为粒子的位置编码,并初始化粒子的速度。重复M次,生成种群数量为M的粒子群。
Step 2M个粒子采用 k-means算法分别对N个文本进行聚类划分,并按式(6)计算粒子的适应度值。更新个体极值、全局极值。
Step 3 观察全局极值是否在规定代数内没有发生变化,如果是,则生成云变异算子,对所有粒子进行变异操作。否则,跳转到Step4。
Step 4 按式(5)更新惯性权重。按式(3)、式(4)更新粒子的速度和位置。
Step 5 判断算法是否达到停止标准,如果是,则跳转到Step6,否则跳转到Step2。
Step 6 输出适应度最大的粒子作为初始聚类中心,其对应的k-means聚类结果为最终聚类结果。
该算法的基本原理是:将文本聚类中心按文本编号编码成粒子个体,利用改进的粒子群算法产生新的粒子,即新的聚类中心,再用k-means算法进行优化,如果种群陷入停滞状态,则生成云变异算子对种群进行变异,重复此过程,直至结束,最终得到的最优个体所对应的k-means聚类结果为最终结果。该算法将改进的粒子群算法的全局优化能力与kmeans算法的高效性与局部搜索能力充分结合,从而快速准确地找到初始聚类中心。
6 仿真实验与结果分析
6.1 实验参数设置
在自调节惯性权重机制中,k=0.3,控制参数i= 1。文献[13]发现当ωmax=0.95,ωmin=0.4时,算法的性能会显著提高,因此,取ωmax=0.95,ωmin=0.4。c1=c2=2.0。改进的粒子群算法对比实验中,算法的终止条件是进化代数达到50次。聚类实验中,算法的终止条件是整个种群平均适应度值连续多代无明显变化。
6.2 改进的粒子群算法对比实验
本次实验采用以下3个经典函数优化问题(求解最小值)来测试算法性能。其中,Sphere函数是一个简单的单峰函数,用以测试函数的精度;Griewank函数与Schaffer函数的全局极值点周围包围着很多局部极值点,容易陷入局部最优,是难度较大的复杂优化问题。
(1)Sphere函数:

对于上述测试函数分别采用标准的粒子群算法(PSO)、混沌惯性权值调整策略的粒子群优化算法(CIWPSO)[14]及本文改进的粒子群算法进行求解,种群规模为50。其中,PSO算法与本文改进的粒子群算法参数按6.1节设置,CIWPSO采用文献[14]的设置,c1=c2=1.5。实验结果如表1所示。
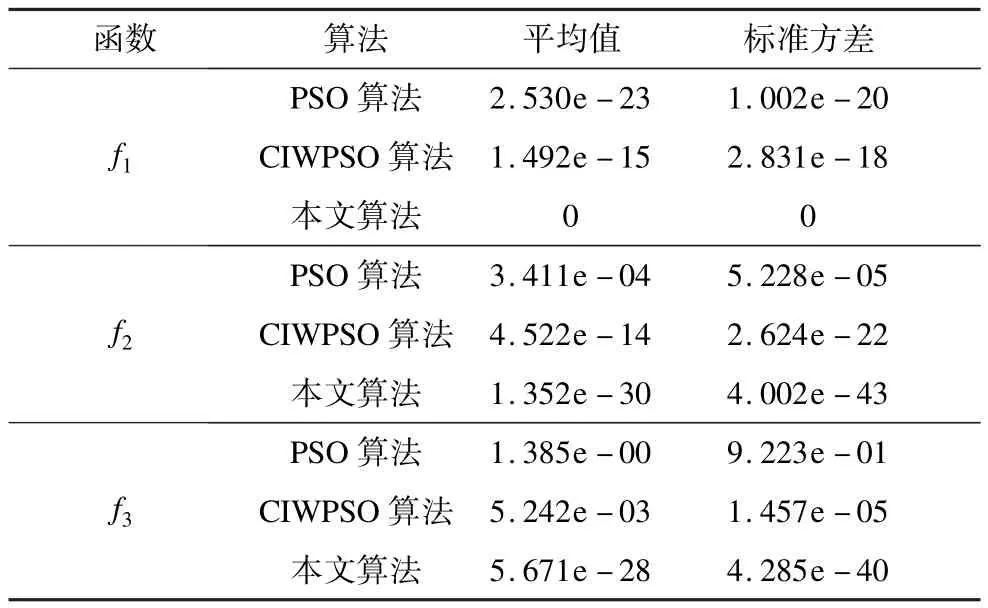
表1 3种算法的实验结果对比
从表1可以看出,对于所有测试函数,改进的粒子群算法均表现出良好的性能。在Sphere函数上,本文改进的粒子群算法的平均值为0,即为精确的最优解,且方差也为0,表示本文改进的粒子群算法每次都能搜索到精确最优解。而在Griewank函数与Schaffer函数上,本文改进的粒子群算法则表现出更高的精确性和稳定性。以上数据表明,该算法具有良好的精确性和鲁棒性。
6.3 实验与分析
实验1 算法稳定性测试
在本次实验中,分别采用k-means算法、基本的PSO聚类算法、优化的 PSO聚类算法、PSO+K-means算法与本文算法对源自腾讯网的150篇文档(共5类,每类30篇)进行聚类测试,每种运行50次。测试结果如表2所示。
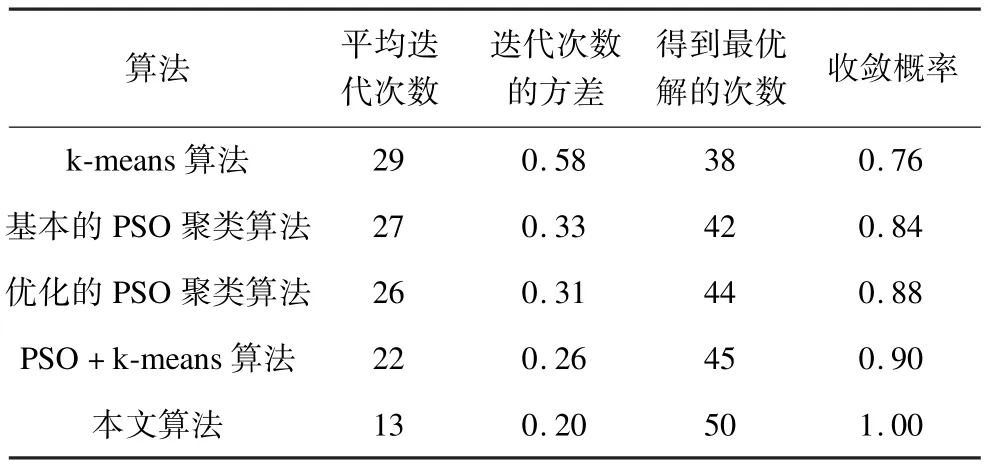
表2 算法稳定性测试结果
从上述实验结果可以看出,k-means算法的稳定性较差,原因在于其对初始聚类中心的依赖性较强。基本的PSO聚类算法和优化的PSO聚类算法在稳定性上有较大的提高且平均迭代次数也相对减小。PSO+k-means算法将两者结合,虽然在稳定性和迭代次数上有较大的提高,但因其只是单纯地将两者结合,而没有优化,其性能仍不如本文算法。本文将全局搜索能力较强的粒子群算法进行优化,防止其早熟收敛,再与局部搜索能力较强的k-means算法结合,无论是在迭代次数还是稳定性上都有着显著的提高。在收敛概率上,本文算法达到了100%,即50次实验中,每次都能得到最优解。
实验2 算法精确度测试
本实验的数据集都来自于腾讯网,每组数据集分别是关于娱乐、体育、时尚、新闻方面,其具体情况如表3所示。

表3 测试数据集
目前大多数聚类结果评价通常用F-measure来衡量,它是信息搜索领域中测试系统性能的常用指标,综合了2个重要的概念——查准率(precision)与查全率(recall),分别考察的是精确性与完备性。对于一个聚类i和主题类别j:

其中,N1为在聚类i中但属于主题类别j的文本数量;N2为聚类i中的文本数量;N3为主题类别j中的文本数量。主题类别j的F-measure定义为:

对于聚类结果来说,总的F-measure则由主题类别j的F-measure加权平均值得到:
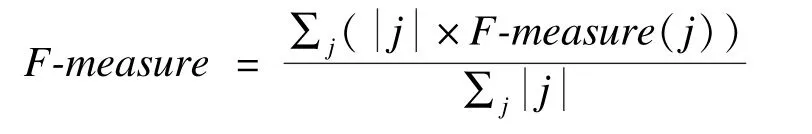
其中,表示主题类j中所有文本的数量。
基于实验1的实验结果,本次实验选择各性能仅次于本文算法的PSO+k-means算法作比较。通过对数据集测试10次的总F-measure值的平均值评价聚类效果,实验结果如图3所示。
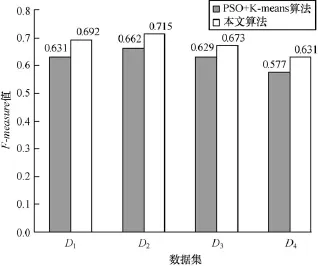
图3 2种算法的F-measure值
观察图3,纵向来看,对于各数据集,本文算法的F-measure值都要高于PSO+k-means算法,约高出5个百分点 ~6个百分点。例如对数据集D4,用PSO+k-means算法聚类的F-measure值是0.577,但采用本文算法聚类后,F-measure值提高到了0.631。横向来看,除了数据集D4,本文算法在其他3个数据集上的F-measure值都超过了0.67,而PSO+k-means算法在数据集D2上的F-measure值最高,为0.662。对于在数据集D4上F-measure值较低可能是因为数据集的选取引起的。整体来看,本文算法在聚类效果上有着显著的优势。
7 结束语
本文改进了粒子群优化算法,并将改进后的粒子群算法与k-means算法结合,充分发挥粒子群算法的全局优化能力与k-means算法的高效性和局部寻优能力,提出了基于改进粒子群算法的文本聚类算法。实验结果证明,该算法具有较强的稳定性和较高的准确性,能够产生较好的聚类效果。在改进的粒子群算法中,i的选取能有效地控制惯性权重ω的增加或减小的速度,合理的i值既能加快收敛速度,又能防止算法早熟。在基于改进粒子群算法的文本聚类算法中聚类算法是在聚类数确定的前提下执行的,而实际聚类问题中,聚类数是未知的。因此,对于控制参数i的选取以及如何优化聚类数目是下一步研究的重点。
[1] 孙吉贵,刘 杰,赵连宁.聚类算法研究[J].软件学报,2008,19(1):48-61.
[2] 雷小锋,谢昆青,林 帆,等.一种基于K-means局部最优性的高效聚类算法[J].软件学报,2008,19(7): 1683-1692.
[3] 谢红薇,李晓亮.基于多示例的k-means聚类学习算法[J].计算机工程,2010,36(17):179-181.
[4] 钱 线,黄萱菁,吴立德.初始化K-means的谱方法[J].自动化学报,2007,33(4):342-346.
[5] Kennedy J,Eberhart R.Particle Swarm Optimization[C]//Proceedings of IEEE International Conference on Neural Networks.Piscataway,USA:IEEE Press,1995: 1942-1948.
[6] 倪庆剑,长志政,王蓁蓁.一种基于可变多簇结构的动态概率粒子群优化算法[J].软件学报,2009,20(2): 339-349.
[7] Salton G,Wong A,Yang C S.A Vector Space Model for Automatic Indexing[J].Communications of the ACM, 1975,18(11):613-620.
[8] Salton G,Buckley B.Term-weighting Approaches in Automatic Text Retrieval[J].Information Processing and Management,1988,24(5):513-523.
[9] 王守信,张 莉,李鹤松.一种基于云模型的主观信任评价方法[J].软件学报,2010,21(6):1343-1344.
[10] 李海林,郭崇慧,邱望仁.正态云模型相似度计算方法[J].电子学报,2011,39(11):2561-2567.
[11] Hu Changhua,SiXiaosheng,Yang Jianbo.System Reliability Prediction Model Based on Evidential Reasoning Algorithm with Nonlinear Optimization[J].Expert Systems with Applications,2010,37(3):2550-2562.
[12] 戴朝华,朱云芳,陈维荣.云遗传算法及其应用[J].电子学报,2007,35(7):1419-1424.
[13] Shi Y,Eberhart R C.Empirical Study of Particle Swarm Optimization [C]//Proceedings of Congress on Computational Intelligence.Washington D.C.,USA:[s.n.],1999:1945-1950.
[14] 吴秋波,王允诚,赵秋亮,等.混沌惯性权值调整策略的粒子群优化算法[J].计算机工程与应用,2009, 45(7):49-51.
编辑 顾逸斐
Research on Text Clustering Algorithm Based on Improved Particle Swarm Optimization
WANG Yonggui,LIN Lin,LIU Xianguo
(College of Software,Liaoning Technical University,Huludao 125105,China)
Clustering result of k-means clustering algorithm is highly dependent on the choice of the initial cluster center.With regards to this,a text clustering algorithm based on improved Particle Swarm Optimization(PSO)is presented.Features of particle swarm algorithm and k-means algorithm are analysed.Considering the disadvantages of PSO including low solving precisions,high possibilities of being trapped in local optimization and premature convergence,self-regulating mechanism of inertia weight and cloud mutation operator are designed to improve PSO.Selfregulating mechanism of inertia weight adjusts the inertia weight dynamically according to the degree of the population evolution.Cloud mutation operator is based on stable tendency and randomness property of cloud model.The global best individual is used to complete mutation on particles.Those two algorithms are combined by taking advantages of power global search ability of PSO and strong capacity of local search of k-means.A particle is a group of clustering centers,and a sum of scatter within class is fitness function.Experimental results show that this algorithm is an accurate,efficient and stable text clustering algorithm.
Particle Swarm Optimization(PSO);self-regulating mechanism of inertia weight;degree of evolution; cloud mutation operator;k-means algorithm;text clustering
1000-3428(2014)11-0172-06
A
TP301.6
10.3969/j.issn.1000-3428.2014.11.034
国家自然科学基金资助项目(60903082);辽宁省教育厅基金资助项目(L2012113)。
王永贵(1967-),男,教授,主研方向:智能计算,云计算,数据挖掘;林 琳,硕士;刘宪国,讲师。
2013-10-29
2013-12-19E-mail:lidypli@126.com
中文引用格式:王永贵,林 琳,刘宪国.基于改进粒子群优化的文本聚类算法研究[J].计算机工程,2014,40(11):172-177.
英文引用格式:Wang Yonggui,Lin Lin,Liu Xianguo.Research on Text Clustering Algorithm Based on Improved Particle Swarm Optimization[J].Computer Engineering,2014,40(11):172-177.
