面向目标检测的多尺度运动注意力融合算法研究
2014-05-30宋琦军
刘 龙 孙 强 宋琦军
面向目标检测的多尺度运动注意力融合算法研究
刘 龙*①孙 强①宋琦军②
①(西安理工大学自动化学院 西安 710048)②(北京邮电大学信息与通信工程学院 北京 100876)
运动目标检测是视频分析领域的关键技术之一,针对目前全局运动场景下目标检测算法的局限性,该文提出一种多尺度运动注意力融合的目标检测算法,为目标检测问题提供了新思路。该算法通过时-空滤波去除运动矢量场噪声,根据运动注意力形成机理定义运动注意力模型;为提高注意力计算的准确性,定义了目标像素块的测度公式,采用D-S证据理论对多尺度空间运动注意力进行决策融合,最终获取运动目标区域位置。多个不同高清视频序列的测试结果表明,该文算法在全局运动场景中能准确对目标进行检测定位,从而有效克服了现有算法的局限性。
目标检测;运动注意力;融合;全局运动场景
1 引言
运动目标检测非常具有实用价值,它是视觉目标识别、目标行为理解、视频内容分析等技术的必要环节,同时在社会和军事领域有着广泛的应用,因此成为视频处理领域研究的热点问题之一。
运动目标检测按照镜头静止和运动两种情况可分为局部运动场景检测和全局运动场景检测。局部运动场景的运动目标检测方法有背景差分法和帧间差分法[1]等。对于全局运动场景,采用的主要方法是全局运动补偿策略[2,3],全局运动估计的准确性要受目标大小和运动强度的影响,当目标所占图像面积较大或运动较强烈时,场景内运动信息受目标影响较大,使全局运动估算的准确性下降,大大限制了全局运动估计补偿策略的目标检测适用范围。
2002年,文献[4]提出了注意力区域的概念,并建立了视觉注意力模型,之后衍生出各种视觉注意力计算方法及应用。文献[5]提出了一个新的视觉计算模型,该模型为了检测场景中的人造目标将自上而下和自下而上的机制结合起来,可以在自然场景中确定显著对象的位置。文献[6]提出的一个基于粒子滤波器的新颖的视觉注意力模型,具有独立高级过程的精简模型,是一个使自上而下的注意机制和自下而上的过程自然结合的单一模型。
目前,有少量研究涉及了采用运动注意力模型应用于视频检索、目标检测等问题。文献[7]根据从MPEG码流中解压所得到的运动矢量场的运动矢量能量、空间相关性和时间相关性综合定义了运动注意力模型,通过该模型可以得到运动显著性区域,应用于视频检索。文献[8]将注意力分为静态注意力和动态注意力两种,静态注意力主要由图像的亮度、颜色等信息引起,动态注意力是在全局运动补偿的基础上计算区域的变化像素的比例进行定义的,注意力模型最终由静态注意力和动态注意力融合得到主要应用于运动目标检测。
上述有关运动注意力的研究工作还存在以下问题:(1)由于光流估算本身缺陷以及噪声影响,运动估计不够准确,造成注意力计算不准确;(2)在文献[7]中,运动注意力模型构建采用了熵的概念,从统计特性上反映运动反差,但未考虑到运动矢量局部时-空分布的反差,与注意力形成机理不符;(3)文献[8]中的方法依然需要全局运动补偿作为目标检测的基础,受到全局运动补偿缺陷的限制。
基于上述考虑,本文提出一种基于多尺度运动注意力融合算法,该方法避免了全局运动估计,克服了当前运动注意力计算方法的不足,为全局运动场景下的目标检测问题提供了新思路。
2 运动注意力模型
在视频场景中,根据运动反差构建合理的运动注意力模型,从而有利于目标检测。
2.1 运动矢量场的时-空滤波
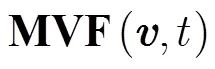
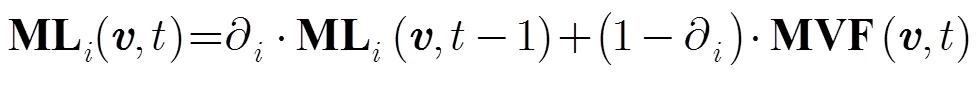


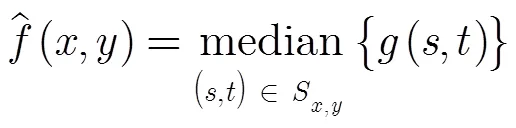
2.2 运动注意力模型
在时间维度上,邻域内定义运动矢量差值描述时间注意力因子,定义的时间注意力因子为
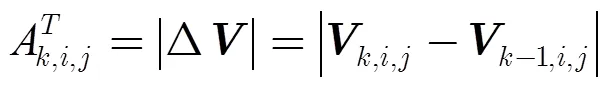

运动注意力由时间注意力与空间注意力两方面的融合构成,定义运动注意力模型为时间和空间注意力因子的线性融合模型,其公式为
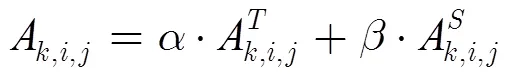
如式(6)所示,线性运算具备了简洁和高效的模型构成,但从时间和空间对注意力影响的角度看,其不足以合理反映出时间与空间注意力的影响对比的变化,时间和空间注意力在不同时刻对注意力的影响偏重是不同的,这取决于这两方面运动反差大小的变化,因此在运动注意力模型中,应加入对注意力的影响力变化的部分,这样才能真正有效反映客观变化,借鉴文献[8]中的对静态和动态注意力融合的模型定义时-空运动注意力融合,其公式为

3 多尺度运动注意力融合
鉴于视觉观测对空间尺度的依赖性,本节讨论在上述运动注意力计算的基础上,通过D-S (Dempster-Shafer)证据理论对多个尺度空间的运动注意力进行融合,以此提高注意力计算的准确性,并最终获取目标区域的方法。
3.1 运动矢量估算的信任度
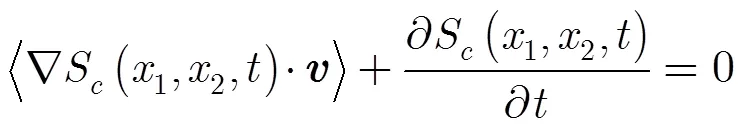
根据上述分析,在图像某个方向上的方向导数越接近于梯度值,则其估计结果越真实可靠,可信度越高,因此可采用方向导数衡量光流估算得到的运动矢量可信度。设图像亮度分布的方向导数(directional derivative)为

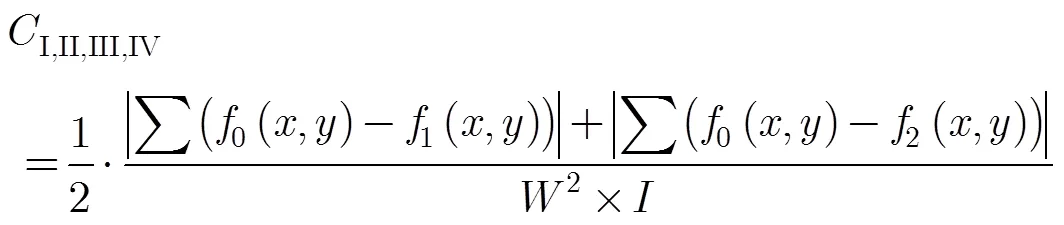
3.2 多尺度空间运动注意力决策融合
由于视觉对观测尺度具有依赖性,对多个尺度空间的运动注意力进行融合使注意力显著图逼近真实,突出镜头与目标之间形成的运动反差,为获取目标区域创造条件。
3.2.1定义置信函数 采用D-S证据理论的辨识框架,将目标像素块的测度值作为证据体,采用双向指数函数来构造概率信任函数(Bel)。
定义目标像素块的测度函数为
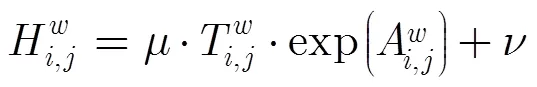
目标像素块的Bel函数需要服从的原则为:

图1 运动矢量的信任度计算
根据上述原则,本文采用双向指数函数来构造目标像素块的基本置信函数,具体定义如下:
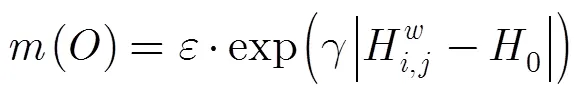

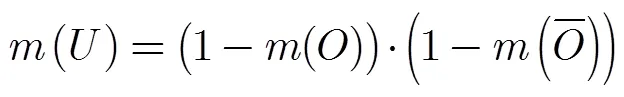
对上述的Bel函数进行归一化处理,以满足对mass函数的定义。
3.2.2决策融合 在空间维度上采用Haar小波基来构造滤波器进行多分辨率分解,并在不同尺度低频空间中进行运动估计,得到不同尺度下的运动矢量场,根据式(12)、式(13)和式(14)计算每个尺度的置信函数值。


4 实验分析


表1 GMC-VA方法的参数配置

表2 MSMAF方法的参数配置

图2空间多尺度运动注意力融合
从图3所显示的测试结果显示GMC算法、GMC-VA算法在全局运动场景对运动目标的检测结果都不如MSMAF算法效果好,MA算法对运动注意力的计算结果不能准确反映场景中的真实运动显著性特征。在全局运动强烈,或背景复杂时,GMC算法很难有效保留目标剔除背景,但在镜头运动缓慢,目标剧烈运动时,GMC算法通过设定阈值可以取得一定的目标检测效果;在同等条件下,GMA-VA算法融合了全局运动补偿和静态注意力,相对GMC算法有更好的效果,但是对于运动目标的检测在有些情况下效果较差,不能准确定位目标区域;MA算法不能正确计算全局运动场景的运动显著性,显然不适于检测运动目标。上述算法主要受到以下两方面因素的影响:(1)全局运动估计不准确导致目标检测效果不理想;(2)噪声干扰和光流估算的导致错误的运动注意力计算不准确。实验结果显示,本文提出的MSMAF算法通过对运动注意力模型的合理定义以及空间多尺度的融合,能够较准确地获取全局运动场景中的运动目标区域,具有更好测试效果。另外,从表3中看出,在算法的运行效率方面,MSMAF算法具有比同类算法较少的时间损耗。

图3实验结果
表3计算时间对比(s/次)
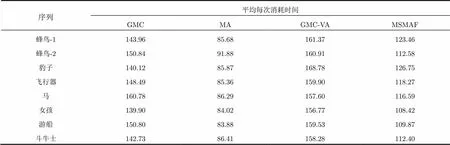
序列平均每次消耗时间 GMCMAGMC-VAMSMAF 蜂鸟-1143.9685.68161.37123.46 蜂鸟-2150.8491.88160.91112.58 豹子140.1285.87168.78126.75 飞行器148.4985.36159.90118.27 马160.7886.29157.60116.59 女孩139.9084.02156.77108.42 游船150.8083.88159.53109.87 斗牛士142.7386.41158.28112.40
5 结论
本文针对目前全局运动场景下目标检测算法的局限性,提出一种多尺度运动注意力融合的目标检测算法,为目标检测问题提供了有价值的新思路。本文算法根据运动注意力形成机理定义了运动注意力模型,并通过D-S证据理论融合多尺度空间运动注意力,最终获取目标区域。本文算法不仅突破了传统算法的局限,而且实验结果显示其在全局运动场景下对运动目标的检测具有鲁棒性高、适用范围广等优势。
[1] Stauffer C and Grimson W E L. Adaptive background mixture models for real-time tracking[C]. Proceedings IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Fort Collins , America 1999, 2: 246-252.
[2] Qi Bin, Ghazal Mohammed, and Amer Aishy. Robust global motion estimation oriented to video object segmentation[J]., 2008, 17(6): 958-967.
[3] Chen Yue-meng. A joint approach to global motion estimation and motion segmentation from a coarsely sampled motion vector field[J]., 2011, 21(9): 1316-1328.
[4] Itti L and Koch C. Computational modeling of visual attention[J]., 2001, 2(3): 193-203.
[5] Fang Yu-ming, Lin Wei-si, Lau Chiew Tong,.. A visual attention model combining top-down and bottom-up mechanisms for salient object detection[C]. Proceedings IEEE International Conference on Acoustics, Speech and Signal Processing, Prague, Czech Republic, 2011: 1293-1296.
[6] Ozkei Motoyuki, Kashiwagi Yasuhiro, Inoue Mariko,.. Top-down visual attention control based on a particle filter for human-interactive robots[C]. Proceedings International Conference on Human System Interactions, Yokohama, Japan, 2011: 188-194.
[7] Ma Yu-Fei, Hua Xian-Sheng, and Lu Lie. A generic framework of user attention model and its application in video summarization[J]., 2005, 7(5): 907-919.
[8] Han Jun-wei. Object segmentation from consumer video: a unified framework based on visual attention[J]., 2009, 55(3): 1597-1605.
[9] Verri A and Pggio T. Motion field and optical flow: qualitative Properties[J]., 1989, 11(5): 490-498.
刘 龙: 男,1976年生,博士,副教授,研究方向为智能信息技术与嵌入式系统.
孙 强: 男,1979年生,博士,副教授,研究方向为图像处理.
宋琦军: 男,1978年生,博士,教授,研究方向为通信信号处理.
Research on Multi-scale Motion Attention Fusion Algorithm for Video Target Detection
Liu Long①Sun Qiang①Song Qi-jun②
①(,’,’710048,)②(,,100876,)
The detection to target in motion is a key technology in video analysis. This paper proposes a target detection algorithm based on a multi-scale motion attention analysis, which provides a new method for motion target detection under a global motion scene. Firstly, the noise of motion vector field is removed by filter, and according to the mechanism of visual attention, spatial-temporal motion attention model is built; then the trust degree of motion vector is suggested on the basis of validity analysis of motion vector, and decision fusion of multi-scale motion attention is accomplished by D-S theory for detecting the region of motion target. The test results of different videos show that the algorithm is able to detect precisely targets under a global motion scene, thus effectively overcoming the limitations of the traditional algorithms.
Target detection; Motion attention; Fusion; Global motion scene
TP391
A
1009-5896(2014)05-1133-06
10.3724/SP.J.1146.2013.00477
刘龙 Liulong@xaut.edu.cn
2013-04-11收到,2014-01-10改回
国家自然科学基金(61001140),陕西省教育厅产业化培育项目(2012JC19)和西安市技术转移促进工程重大项目(CX12166)资助课题
