非英语专业大学生英语词汇磨蚀实证研究
2014-04-16蒋拓新JIANGTuoxin李丽生LILisheng
蒋拓新 JIANG Tuo-xin;李丽生 LI Li-sheng
(①昆明理工大学外国语言文化学院,昆明 650500;②云南师范大学外国语学院,昆明 650500)
(①Faulty of Foreign Languages and Cultures,Kunming University of Science and Technology,Kunming 650500,China;②School of Foreign Languages&Literature,Yunnan Normal University,Kunming 650500,China)
0 引言
语言磨蚀,意指双语或多语使用者由于某种语言或语言某一方面使用的减少或停止,其运用该语言的能力随着时间的推移而逐渐减退。1980年“语言技能磨蚀会议”在美国宾夕法尼亚大学召开。这次会议之后,语言磨蚀被正式确立为语言研究的一个新窗口。本研究所讨论的语言磨蚀指的是外语学习者在接受语言教学后经过一段时间不使用或使用减少而产生的外语知识,技能丧失或退化的现象。
语言磨蚀和语言习得是语言研究的两个面,二者密切相关,忽视任何一面都不可能了解语言学习的全过程。语言磨蚀的研究为语言习得的研究提供了全新的视角。语言磨蚀研究在国外已有近三十年的历史,然而与国外如火如荼的实证研究相比,我国在这一领域直到近几年才开始有学者研究,最初只有介绍性质的文章,未能系统地展现语蚀研究全貌。在缺乏相应外语输入的汉语语言环境下,如何有效地避免和克服语言磨蚀显得极为重要。
词汇是语言学习的基础,词汇习得是语言习得的一个重要环节,以往对词汇的研究大都关注的是词汇习得的研究,对词汇磨蚀的研究较少。因此,本文通过对中国四年制大学本科学生在完成两年英语学习的一年后及两年后的词汇能力的磨蚀研究,探讨大学三四年级学生的词汇磨蚀程度及哪些词汇更容易发生磨蚀,并讨论相关因素对词汇磨蚀的影响。期望研究结果能帮助了解汉语背景下中国大学生的英语词汇磨蚀状况,进而指导英语的教与学。
本研究采取定量研究的方法,从昆明理工大学电力学院电气自动化专业抽取三个年级(每个年级50名学生)150名学生作为受试对象,即三组受试对象。定量研究的材料来自于对研究对象的词汇测试。采集数据使用MATLAB统计工具箱进行分析。
1 研究方法
1.1 研究对象 为了更好的控制英语学习背景,确保磨蚀程度的可观察性,体现研究对象的典型性,本文从昆明理工大学电力学院电气自动化专业抽取三个年级(每个年级50名学生)150名学生作为受试对象,即三组受试对象。研究对象来自同一个专业,使用相同的英语教材,接受相同的英语教学模式。第一组受试对象为大学二年级学生,刚刚结束两年的大学英语学习;第二组受试对象为大三学习刚刚结束的学生,第三组受试对象为大四即将毕业的学生。
1.2 词汇测试和问卷调查的设计 本文以常用的考察学生能否记住词汇意义作为词汇测试的主要手段。词汇测试由50个词汇选择题构成,要求学生在不借助任何工具书和课本的前提下独立完成词汇意思的选择。每题2分共计100分,选错或漏选均不得分。《大学英语课程教学要求》中的参考词汇表共收录单词7676个,对三个不同教学要求所规定的词汇量的具体分配见表1。本研究中的词汇测试所选50个单词即根据以上三个不同教学要求词汇量在总收录单词中所占比例计算,结合受试对象所使用的英语教材随机挑选而成,见表2。
1.3 测试和调查方法 在一学年结束时,即6月底,由不同老师负责将同一份词汇测试分别发给三组受试对象,要求三组受试对象在课堂上独立完成,老师负责发放测试题并监督学生认真完成,学生完成后老师收回待批阅。
1.4 数据分析方法 词汇测试结果数据使用MATLAB统计工具箱通过计算机进行分析。统计分析分为以下几个步骤:①描述统计;②假设检验,采用Jarque-Bera检验和Lilliefors检验;③双样本T测试,检验不同受试群体的测试成绩与假设经验值之间是否存在显著差异,从而说明不同受试群体词汇磨蚀程度是否存在显著差异。

表1 不同教学要求所规定的词汇量的具体分配表
2 结果
2.1 描述统计数据 描述统计是对变量进行描述性统计分析、计算,列出一整套必要的统计指标数据。此部分数据分析选择描述统计中的以下几个指标:Max(最大值),Min(最小值),Mean(均数),Median(中数),Mode(众数),Range(全距)和Standard Deviation(标准差)。
该测试共有三组受试群体,第一组受试对象为大学二年级学生,刚刚结束两年的大学英语学习;第二组受试对象为大三学习刚刚结束的学生,第三组受试对象为大四即将毕业的学生。词汇测试由50道词意选择题构成,每题两分,共100分。

表3 三个组词汇测试成绩统计数据表
从表3可以看出,第一组受试群体的均数,中数和众数分别是90.48,90和94;第二组受试群体的均数,中数和众数分别是78.24,78和74;第三组受试群体的均数,中数和众数分别是81.76,82和86。每组的这三个值都非常接近,这说明,三个组的词汇测试成绩没有偏值,异常值或极值。如果单看均值的话,第一组90.48最高,说明第一组受试对象的整体词汇水平最高,第二组和第三组分别是78.24和81.76,说明第三组受试对象词汇水平高于第二组,第二组的词汇知识整体水平最低。
三个组的全距值分别是20,26和36。也就是说第三组的最大值和最小值之间的差异是最大的,这可能表明,第三组受试对象中存在一些学生的词汇水平急剧下降的情况。三个组的标准差分别为5.3385,7.1673和7.6946。该数值从组1到组3逐渐增大。由此可以看出第三组受试对象个体间的词汇知识水平差异最大,第一组个体间表现出最小的词汇知识水平差异。
2.2 成绩分布的正态性检验 在对词汇测试数据进行分析之前,有必要对数据的正态分布进行检验。生成正态概率图并进行假设检验,以检查观测值是否服从正态分布。假设检验方法有很多中,本文采取的是Jarque-Bera检验和Lilliefors检验。如果这两个测试拒绝零假设,其返回逻辑值h=1,反之h=0。

表4 三个组词汇测试成绩数据正态分布检验表(alpha=0.02)
p值是拒绝原假设的最小显著水平,换句话说,就是当原假设为真时所得到的样本观察结果或更极端结果出现的概率。用p值与设定的显著水平相比可以得出是否接受原假设的结论。如果α>p值,则在显著性水平α下拒绝原假设。如果α≤p值,则在显著性水平α下接受原假设。在该测试中显著水平α取0.02。从表中可以看出,p值都大于0.02,说明接受原假设。
stat,指测试统计量;critval指测试的临界值。当stat>critval时,表明在显著性水平α下拒绝零假设。
从表4可以看出测试所有返回逻辑值h=0,进一步说明三组样本数据在显著水平α取0.02的情况下呈正态分布。
2.3 不同受试群体词汇测试成绩之间的差异分析 为了分析不同受试群体词汇测试数据之间是否存在显著差异,使用假设检验和双样本T测试。双样本T测试用于分析两个样本的均值是否存在统计上的差异,它是基于假设检验原理而进行的一种检验。首先要确定零假设为三个样本群体的词汇测试数据的均值相等。测试结果返回逻辑值h=1表明在显著水平α取0.02时拒绝零假设,若h=0表明在显著水平α取0.02时接受零假设。鉴于有三个样本群体,那么将分析每两个样本群体之间的均值是否存在统计上的差异,如表5所示。
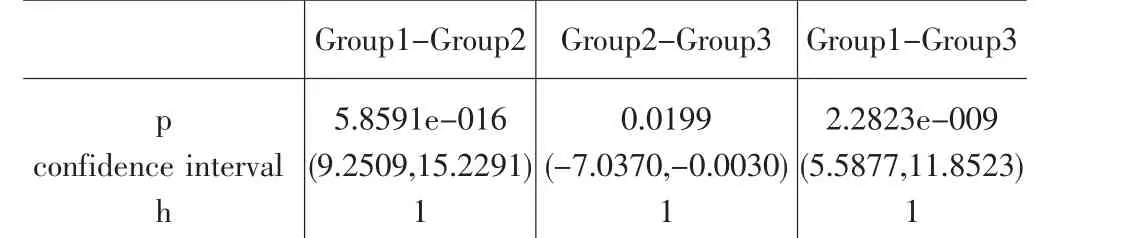
表5 两个组间词汇测试双样本T测试数据表
从表5可以看出,测试返回的h值均为1,说明样本的均值存在差异。置信区间(confidence interval)是指由样本统计量所构造的总体参数的估计区间。表5中的置信区间均不包含零点,即0不属于置信区间,这表明样本均值之间的差异显著。
此外,p值(p value)是当原假设为真时所得到的样本观察结果或更极端结果出现的概率。p值越小,拒绝原假设的理由越充分,表明结果越显著。根据表5中所显示的p值,我们发现一组和二组的均值差异最不显著,其次是一组和三组的均值差异,二组和三组之间的均值差异最大。
从以上分析可以看出,三个样本群体的词汇磨蚀程度存在显著差异。结合表1的分析,第一组受试对象的整体词汇水平最高,第三组受试对象词汇水平高于第二组,第二组的词汇知识整体水平最低。我们可以认为第二组受试群体的词汇磨蚀程度比第三组受试群体的词汇磨蚀程度高。
2.4 不同受试群体不同要求层次词汇磨蚀分析 为了探明《大学英语课程教学要求》中参考词汇表里不同要求词汇的磨蚀程度,首先需要分析不同要求词汇测试成绩数据以及成绩之间的差异。本次测试的50个单词中有31个一般要求的词汇,11个较高要求的词汇,8个更高要求的词汇。不同要求的词汇测试成绩数据先进行标准化,转换成百分制,再进行数据分析。
表6表7和表8显示了各受试群体三个不同层次要求的词汇测试成绩的描述统计数据。

表6 一般要求词汇测试成绩统计数据表

表7 较高要求词汇测试成绩统计数据表

表8 更高要求词汇测试成绩统计数据表
从表6、表7和表8看出三个组一般要求词汇测试成绩的均值分别是94.7097,90.3226,90.9677,较高要求词汇测试成绩的均值是87.0909,69.2727,73.8182,更高要求词汇测试成绩的均值是78.75,43.75,57。由此可以看出受试群体一般要求词汇测试成绩最高,其次是较高要求词汇测试成绩,更高要求词汇测试成绩最低。也就是说,更高要求的词汇最易发生磨蚀,其次是较高要求的词汇,一般要求的词汇在受试对象的词汇体系中相对稳定。
3 讨论
学习一个单词涉及到掌握其方方面面的特点,如单词的拼写,词意的把握,词的搭配使用等,因此,遗忘单词同样涉及临时或永久丧失该词某一方面或多方面的知识。本研究只关注词意的掌握这一方面。
从以上分析可以看出,大三学生和大四学生都经历了词汇磨蚀,并且大三学生的词汇磨蚀程度比大四学生的词汇磨蚀程度更高。参考词汇表里的更高要求的词汇最易发生磨蚀,其次是较高要求的词汇,一般要求的词汇在受试对象的词汇体系中相对稳定。
这些发现表明,词汇知识的保持需要学习者自身以及学校和教师的共同努力。作为学习者,他们应该花更多的时间进行语言学习,从而更好的掌握词汇知识。另一方面,绝大多数遗忘的词汇实际上一直存在于学习者的大脑里,重要的是如何刺激大脑再次获取这部分词汇。因此,学校要适时调整教学大纲,优化课程设置,提供更多与英语相关的选修课程。从教师的角度来看,创新教学模式尤为重要。这其中,两个问题值得思考,首先什么样的输入才能使学习者的外语能力得到最佳的保持,其次当学习者的语言知识面临磨蚀的威胁时,采取什么手段帮助学习者找回并巩固语言知识?第二语言习得的过程包括输入和输出两大重要部分,强调输入的同时,还不能忽视输出这个环节。因此,学习者还必须加强语言的运用,通过语境掌握语言知识。
纵观大量的磨蚀文献,磨蚀领域的研究需要对变量进行一定程度的控制,或是采用历时研究,对研究对象进行长期跟踪,从而获取数据展开真正的实验设计。本研究的三组受试对象来自同一学校同一个专业,使用相同的英语教材,接受几乎相同的英语教学模式,这从整体上控制了研究对象的学习背景的相似性,一定程度上体现了研究对象的典型性,但对个体学生的语言学习变量难以控制。因为某些个体还会因为准备英语竞赛,复习考研,出国申请等因素而加强了英语的学习。其次,受时间的限制及考虑到跟踪毕业生的难度,本研究仅探讨了在校大学生结束正式课堂英语学习后的一年及两年的词汇磨蚀状况。
4 结论
基于本文提供的结果和综合以往文献的讨论,我们可以得出如下的基本结论:①第二组和第三组受试对象(大三学生和大四学生)在结束两年大学英语学习后都经历了词汇磨蚀,并且大三学生的词汇磨蚀程度比大四学生的词汇磨蚀程度更高;②《大学英语课程教学要求》中的参考词汇表里的更高要求的词汇最易发生磨蚀,其次是较高要求的词汇,一般要求的词汇在受试对象的词汇体系中相对稳定。
以上研究成果对大学英语词汇的教与学有着现实意义。首先教师应从诸多词汇教学方式中挑选出实时教学和抗磨蚀远期效果均好的方式用于教学。其次,外语学习者应有个体的外语学习规划,通过不同的途径增加外语接触机会来防止词汇磨蚀。
[1]Cohen,A.Forgetting a second language [J].Language Learning,1975(25):127-138.
[2]Hansen,L.Learning and forgetting a second language∶The acquistion,loss and reacquisition of Hindi-Urdu negative structures by English -speaking children [J]. Dissertation Abstracts International,1980,43:193A.
[3]Lambert,R.D.,&Freed,B.(Eds.).The loss of language skills[M].Rowley,MA∶Newbury House Publishers.1982.
[4]Weltens,B.,de Bot,K.,&Van Els,T.Language attrition in progress.Dordrecht∶Foris,1986.
[5]教育部高等教育司.大学英语课程教学要求[Z].外语教学与研究出版社,2007:1-7.
[6]钟书能.语言流损研究对我国外语教学与研究的启示[J].外语教学,2003,24(1):66-70.
[7]蔡寒松,周榕.语言耗损研究述评[J].心理科学,2004(4)∶924-926.
[8]倪传斌,刘治.基于外语“磨蚀”的教育学反思[J].外语与外语教学,2008(3)∶38-40.
