多语种网络文本快速新词抽取
2014-04-14刘冰洋刘欣然程学旗
刘冰洋,刘 倩,张 瑾,刘欣然,程学旗
(1.中国科学院计算技术研究所网络数据科学与工程研究中心,北京100190;2.中国科学院大学,北京100190;3.国家计算机网络应急技术处理协调中心,北京100029)
1 引言
网络文本的重要特点之一是不断的涌现新词。2011到2012年出现的网络新词有,“hold住”、“给力”、“穿越”、“小清新”、“12306”、“甄嬛体”等等。语言带有强烈的时代烙印,这些新词基本上都是以前未出现的,包括了命名实体,词组和短语以及约定俗成的固定用语。新词最能敏锐反映时代和社会心理的变迁,它与新的社会现象密不可分,从一个特定的角度表达着人们的价值观和文化心态。所以,挖掘网络新词对于跟踪社会发展,发现社会、网络舆情,预测发展趋势具有重要意义。
互联网是一个开放的信息平台,存在多领域多语言的文字。截止到2011年12月30日,互联网的网页内容中,英语占56.6%,接下来依次为德语、俄语、日语、西班牙语、中文、法语、意大利语,其中中文的内容量为4.5%[1]。值得一提的是,使用中文的网民量占全球的25%。同时,由于中国的多民族环境,少数民族语言的互联网内容也在日渐增多。因此,适用于网络文本多语言的通用的新词识别方法被迫切需求。
统计方法在自然语言处理中,尤其是在面向网络文本的浅层自然语言处理中已经逐渐占据主流地位。规则方法很难适用于多语言的处理。而从通用有效的统计特征出发,可以有效的识别语言要素和语用环境,提取出重点字串,包括但不限于:新词、关键词、固定搭配、命名实体。本文主要面向的是新词抽取方法。
2 相关工作
使用统计方法进行新词抽取的时候,通常第一步是从文本中抽出频率大于一定阈值的重复串作为候选串集合,然后再通过其它统计量筛选、过滤或合并候选串集合中的字符串。
抽取重复串有分词后统计和非分词两种方案:分词后统计以词语作为构成字符串的基本单位,非分词方案以字为基本单位。文献[1]、[2]采用了最大匹配分词;文献[3]使用ICTCLAS进行分词和词性标注;文献[4]使用非分词方案,采用了n元递增分步算法,并借鉴了Apriori算法的思想,从1字子串生成2字子串最后到n字子串,从而得到所有可能的重复串。
分词方案的优点是可以减少计算量,缺点是词语切分的错误会向后传递,导致一些可能是新词的重复串无法被发现。非分词方案的优点在于枚举到了所有的可能子串,缺点是计算量大,且会出现大量垃圾串,需要有效的垃圾串过滤方法。文献[5]使用后缀树来处理中文文本,但是并没有解决后缀树应用于中文时的效率问题。
本文使用了非分词方案,并通过多语言统一编码和对后缀树的改进,克服了通常认为的使用后缀树处理中文时字符集过大的缺点,可以快速提取所有满足频率阈值的重复串。
判断候选串集中的字符串是否成词,可以同时借助字符串的上下文环境信息和内部信息,通常在中文分词领域被应用。文献[6]提出邻接类别(Accessor Variety)的概念来描述字符串的使用灵活性;文献[4]使用互信息来计算字符串内部信息和相邻字符串,判断是否成词;文献[1]结合使用了邻接类别、邻接熵以及双字耦合度的方法;文献[7]提出统计学习的框架,使用CRF和最大熵模型,利用前、后缀,左、右熵以及串长、串频等多个特征对候选串进行是否为新词的标注,取得了较好效果,但由于模型的训练需要基于已标注的训练数据,无法应对多领域和多语言的需要;文献[8]使用了邻接类别、互信息、是否为锚文本这三个统计量来提升中文分词的效果,本质上也是计算成词可能性。
本文以邻接类别为基础,结合字符串频率提出了字符串整体度来判定成词和过滤垃圾串,可以仅使用简单的阈值过滤和权重计算,得到最终的新词结果,并使其可以应用到多语言环境。
3 基于双后缀树的动态规划新词提取算法
处理多语言文本需要面对不同的语言形态和特征,因此需要先统一多种语言的形态,再计算与语言无关的统计量来达到新词抽取的目的。
本文采用如下流程抽取多语言文本中的新词,如图1所示。首先对文本进行统一编码,然后在双后缀树上统计重复频率与邻接类别并计算字符串整体度,最后对候选结果集进行编码还原、筛选和排序得到最终的新词结果集。通过重复频率来描述字符串的应用频繁程度,通过邻接类别来描述字符串的应用场景,并在非分词场景下提出了字符串整体度来描述字符串的成词概率。

图1 多语言文本新词抽取流程
3.1 多语言统一编码
语言的基本意义单元是词语,但不同语言对应的文字中词语的表示形式不同。以中英文为例,中文的词语之间没有空白符,英文的词语之间有空白符作为自然间隔。本文把中文视为连续字节流,并通过动态词典的方案把英文转化为字节流,提出如下的多语言统一编码方案以统一处理中英文。该方案也可适用于其他语言文字。
由于中文的字符集较大,常用字符约为4 000个,|∑|≈4 000,log|∑|≈12,且汉字在GBK编码下需要两字节来表示,使得建立后缀树时的指针开销很大,不利于发挥后缀树数据结构的时间优势,所以在以往的大数据量中文文本处理中较少使用后缀树。
本文提出了一种方案:把中文文本转换为Unicode-16编码后,以4-bit为单位作为字符划分。此方案把字符集大小固定为16,缩小了指针的开销。如图2所示,“是”的Unicode编码为0x662F,拆分为4个4bit字符,分别是(小端字节序)。

图2 中文编码方案
本文采用的后缀树[9]算法最多使用2N个节点来建树,其中N为原字符串的单位长度。设每个后缀树节点有C字节的固定空间开销,每个指针的空间开销为P字节,字符串长度为Z字节。以x-bit为单位时,总空间开销为SP(x)如式(1)所示。
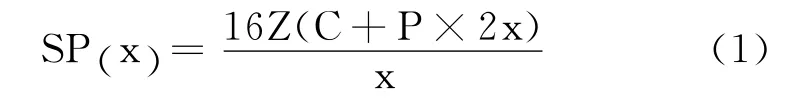
在32位计算机上P取4,在本文的后缀树实现中,C约为64字节。4-bit的方案最为节省空间。
对于英文以及其他不需要分词的语种,本文采用动态词典的方式,将单词映射为序号。以英文为例,现代英文中约有10万在用单词,在局部文本中使用双字节就可以存储编号值,然后同样采用4-bit为单位划分,如图3所示。

图3 英文编码方案
中英文的最大区别在于英文不需要分词,如果直接对英文字符串建树,会造成存储空间的浪费;另一方面,英文中单词具有不同的时态、数、性,需要对它们进行词根还原(Stemming)。本文的实现中使用了Porter Stemming的规则方法。
3.2 重复字串统计
重复字串发现的基本流程为以标点符号为自然分隔,统计一段文本中所有子串的出现次数,例如,“发现新闻、新词”的子串集合及其频率为:{发(1),现(1),新(2),闻(1),词(1),发现(1),现新(1),新闻(1),新词(1),发现新(1),现新闻(1),发现新闻(1)}。下文中把字符串S的频率记为Freq(S)。
汉语特点是其字符表很大,结合这个特点,目前可应用于和已应用于中文文本的重复串查找算法有后缀树算法和n元递增分步算法[4]等。
传统的后缀树算法建树的复杂度依赖于词汇量(对于以字符为单位的后缀树而言,则是字符表的大小),其时间复杂度为O(N*min{log|Σ|,logN}),空间复杂度为,其中N为串的长度,为字符集大小,而遍历后缀树查找重复串的时间复杂度均为O (N)。特点是空间复杂度较高,而时间复杂度较低,只适用于小规模语料处理时快速发现重复串。
n元递增分步算法虽然时间复杂度比较高,但是空间复杂度O(N)较低(N是语料规模)。其主要思想先统计所有两字串的频次,然后再逐步统计三字串,四字串,五字串……记录每一次扩展的字串以及对应频次,到达句末或者是字串长度达到阈值时停止扩展。
本文对传统后缀树建树算法进行了改进。汉字的常用字符表大小约为4 000,本文中把字节流以4bit为单位划分,使得字符表大小变为16,减少了指针开销。建树的时间复杂度为O (N *4),空间复杂度为O (N *4),均为线性复杂度。以4bit为单位划分字节流的额外好处是不需要考虑被处理的字符串的编码类型、编码空间,且易于扩展到其它语言。
3.3 上下文邻接统计
通常来说,一个词语的内部结合度比较高,如词语“禽流感”中的三个字总是一起出现。而它与外部上下文的关系比较松散,上下文环境灵活多变。对比“禽流”一词,它的下文在语料中只有“感”字,所以“禽流”一词的上下文环境不够多变,不足以形成独立的词。本文在文献[1,6]的基础上重新给出邻接类别适用于不对中文进行分词时的定义。
定义3.1(n-左邻接集合):指在真实文本中,与字符串左边相邻的n字节字符串的集合,记为n-AVL。同理得n-右邻接集合n-AVR。
定义3.2(n-邻接类别):min{|n-AVL|,|n-AVR|},记为n-AV。它反映了串S上文和下文中邻接类别的最小值。
本文取n为2,即只统计串S上文两个字节和下文两个字节中出现的邻接集合。“微博”一词在2010年成为网络热词,下面是真实网页中的例句:
浙江组织部门开官方微博听取民意
新浪微博是全中国最主流最具人气当前最火爆的微博产品
网易微博秉承让每个人都成为中心做中国脉搏的思想让个人的力量不再微薄
微博又叫微博客(micro blog)是微型博客的简称NBA官方微博落户腾讯联手打造第一球迷社区
2-AVL(微博)={方,浪,的,易,BOS,叫},2-AVR(微博)={听,是,产,秉,又,客,落},|2-AVL(微博)|=6,|2-AVR(微博)|=7,2-AV(微博)=min{6,7}=6.下文中字符串S的2-AVL、2-AVR、2-AV分别简记为AvL(S)、AvR(S)和Av(S)。
3.4 字符串整体度
由于本文对中文处理时不进行分词,所以候选的字符串可能高频但并不成词,即为垃圾串。字符串整体度可以用来描述一个字符串的成词概率,过滤垃圾串。
定义3.3(字符串整体度):在给定语料C中,字符串S的整体度(String Integrity Measure,SIM)记为It(S,C),如式(2)所示。

由于Av(S)≤Freq(S)且Av(S)≥1,可知It(S,C)≥0。
3.5 算法描述
在已经建好的后缀树上统计候选字符串时,本文使用了自底向上的动态规划方法,仅遍历各节点一次,在线性时间内统计出所有节点所代表的字符串的重复频率与Av值,同时借助简单有效的剪枝方法来减少计算量,加快计算速度。
为了便于描述算法,给出以下简记定义:
1)字符串S的倒序记为rev(S);
2)取后缀树T的任意节点X,它记录了从根节点到X所表示的字符串,记为S(T,X);
3)后缀树T的根节点记为root(T),以后缀树T的任意节点X为根节点,得到的子树记为sub(T,X),可知T=sub(T,ro ot (T));
4)后缀树T的任意节点X,sub(T,X)的叶节点个数记为leaf(T,X);
5)后缀树T的任意节点X,X的深度记为H(T,X);
6)后缀树T的任意节点X,删除所有深度大于H (T ,X)+m的节点后,sub(T,X)的叶节点个数记为leafm(T,X),并定义leaf0(T,X)=1,leaf∞(T,X)=leaf(T,X)。
使用后缀树T存储字符串S,后缀树Tr存储字符串rev(S),有如下性质:
1)Freq (S (T,X))=leaf(T,X);
2)AvR (S (T,X))=leaf4(T,X);
3)同2),在后缀树Tr上可以取得AvR(rev(S (T,X)))的值,即为AvL(S (T,X))。
4)后缀树T的节点集合与字符串S的子串集合一一对应,每一个节点的统计量都代表了其对应子串的统计量。
根据以上性质,自底向上的动态规划算法递推式如下:
设后缀树T上节点X的所有子节点集合为c(X),
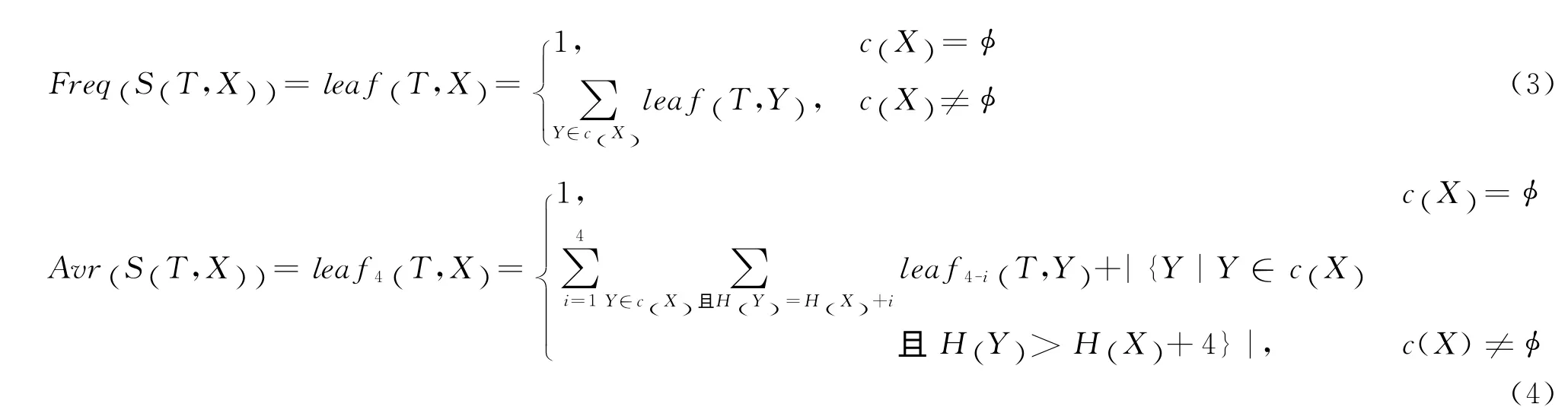
图4中实线边表示实际存在的边,虚线边表示省略了部分节点,实心节点表示叶节点。图中所示的后缀树中,leaf (T,X)=9,leaf4(T,X)=6。
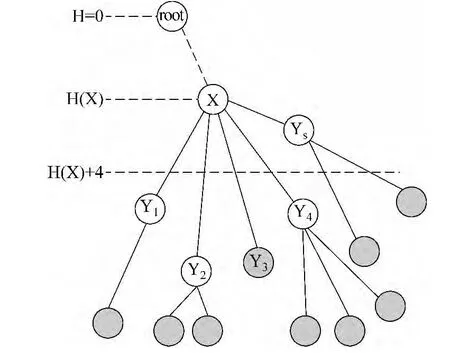
图4 基于动态规划的后缀树算法
从后缀树提取候选字符串时采用了如下的剪枝规则:
i.规定候选字符串的最大、最小长度,由此规定了遍历的最小最大深度;
ii.规定候选字符串的最小频率和最小n-AV值;
iii.由频率和n-AV的统计方法可以得知,当遍历到树的某一节点已经不满足规则ii、iii时,它的子节点也不会满足,可以直接返回。
应用以上的剪枝规则后,后缀树有效节点数缩小为原来的10%以内,见本文第4部分。
3.6 基本排序
对结果字符串进行基本排序的目的是选出最有可能成为候选新词的字符串并给出它们的排序。基本排序时使用的权值计算公式如式(5)所示。


上述计算公式中,W1(S)是Freq(S)与Av(S)的调合平均数。α通常取值范围为[0.5,1.2],当α>1时,Freq(S)所占权重更高,当α<1时,Av(S)所占权重更高;W2(S)是字符串整体度描述;W3(S)是字符串的长度在词典中的先验概率,也可以根据经验来决定。不同的经验值配置会在结果中反映为对不同长度词语的重视程度。
在最后的排序结果中,存在部分词语是其他词语的子串,通过以下的筛选方法去除。
设Weight(A)>Weight(B):
如果B为A的子串,删除B;
4 实验分析
本文的中文新词抽取实验采用网络语料,共计200篇新闻与博客,涵盖财经、体育、娱乐、社会领域,采用人工标注的方法评价语料中提取出的词语是否为新词。但由于每篇文本中的新词数有限,因此仅评价在背景词典过滤之前所提取出的所有词语是否成词。
大部分网页文本正文长度为2.5KB至12KB。由于每篇文本长度不同,返回的结果数也不同,如图5所示。为了方便对比所有文本的结果集,本文提出了P@Percentage的评价方法。
定义3.4(P@Percentage):设返回的字符串集合元素个数为N。把返回的字符串集合按规则R排列,记字符串S在R下的排列序号为rank(R,S):

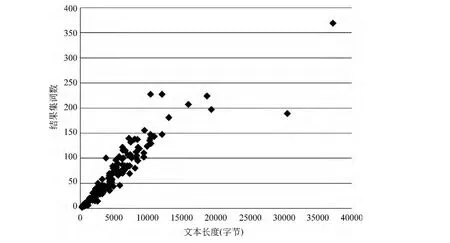
图5 结果集词数与文本长度关系分布图
本文对结果集采用人工评估,把结果集中的字符串分为三类:正确词语、组合词语和错误词语。其中组合词语定义为该字符串由几个完整词语拼合而成,例如,“金融体制”,是由“金融”和“体制”两个词组合而成。评价结果中正确词语的比例记为P1@Percentage,正确词语与组合词语所占的比例之和记为P2@Percentage。
表1、2分别给出了在整体度排序和总权值排序下的结果。可见排名靠后的字符串是组合词语的可能性更大。字符串整体度和以此为基础给出的总权值均可有效度量字符串是否成词。使用总权值排序可取得比字符串整体度略好的效果。
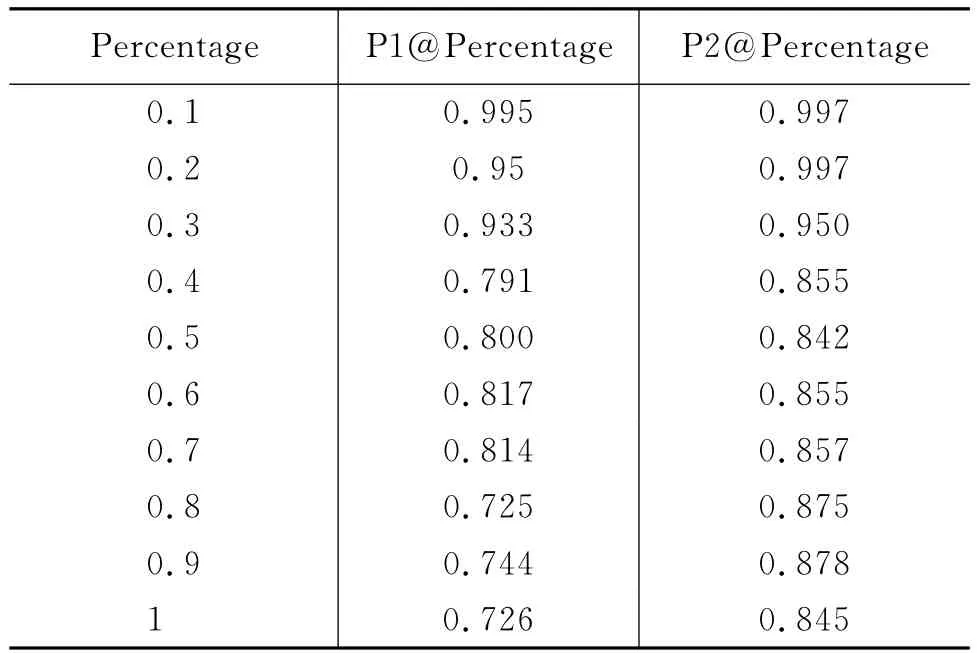
表1 P@Percentage由整体度排序
本文的方法无法发现和抽取Av≤1的词语,召回率在不同文本集上评测的结果差距较大,对于词语的召回率低于0.15,对于新词的召回率平均值为0.634。由于出现新词的文本中往往对新词有较多的集中应用和解释,所以本文的方法可以较好的召回新词。

表2 P@Percentage由总权重排序
本文在统计上下文邻接类别时,使用了按2字节统计的方式。与传统的按词语统计方式比较,在上下文邻接类别较小时,两种方法的结果基本相同。随着词语上下文应用环境变复杂,2字节为单位统计的值与按词语统计的值逐渐产生差距(图6)。由于结果集中往往是AV值较低的字符串影响准确度,所以采用2字节为单位的统计方法对结果的筛选基本没有影响,可以在减少计算量的同时保证计算效果。
本文使用的剪枝方法可以有效的减少计算量。使用最小AV值和最大字符串长度作为剪枝标准,结果见表3。在本文所测试的语料上,当最小AV值为2,最大字符串长度为20字节(10个汉字)时,经过剪枝后的节点数量减少至原来的10.397%。当最小AV值限定为4时,节点数减少至1.069%。在实际使用中,为增加召回率,通常采用第一行的剪枝标准。

图6 以2字节为单位统计AV值

表3 剪枝效果分析
本文的方法在多语言语料上同样适用。简单的为每种语言配置几个过滤字词之后即可达到与中文接近的效果。以英文为例,由于英文词语之间有空格分隔,不需要考虑成词概率,所以在式(5)上去掉了W2。评价结果集内大于等于两词的短语是否为实体名或固定语言搭配。测试语料为100篇来自FIFA的新闻语料。结果集使用简单规则过滤掉以of,the,for,a开头和结尾的词组之后,P@Percentage(1.0)为0.674,新词和短语的总召回率为52.5%。
5 总结
本文在前人研究工作的基础上,总结了新词发现的常用方法,改进了后缀树模型的计算量:修改了传统后缀树以字节为单位的基本结构,提出并实现了以4bit为单位的通用字符串后缀树方法,统一了中、英文处理的核心部分;不需要对中文文本分词,利用双后缀树以线性时间统计重复串与上下文邻接量,并以此为基础提出了字符串整体度用以过滤候选字符串。下一步工作是通过计算各语言中高频搭配的背景数据,自动化的过滤结果集中高频但无意义的搭配,例如,中文的“的一”,英文中的“of a”,等等。
[1] 贺敏.面向互联网的中文有意义串挖掘[D].中国科学院研究生院:计算技术研究所,2007.
[2] 黄玉兰.有意义串挖掘及其应用[D].中国科学院研究生院:计算技术研究所硕士学位论文,2009.
[3] 邹纲,刘洋,刘群,等.面向Internet的中文新词语检测[J].中文信息学报,2004,18(6):1-9.
[4] Zhang Y,Liu C.An improved fast algorithm of frequent string extracting with no thesaurus[C]//Proceedings of the artificial intelligence 6th Mexican international conference on Advances in artificial intelligence.Berlin,Heidelberg:Springer-Verlag,2007.894-903.
[5] Zeng D,Wei D,Chau M,et al.Domain-specific Chinese word segmentation using suffix tree and mutual information[J].Information Systems Frontiers,2011,13(1):115-125.
[6] Feng H,Chen K.,Deng X,et al.Accessor Variety Criteria for Chinese Word Extraction[J].Computational Linguistics,2004,30(1):75-93.
[7] 张海军,栾静,李勇,等.基于统计学习框架的中文新词检测方法[J].计算机科学,2012,39(2):232-235.
[8] Sun W,Xu J.Enhancing Chinese word segmentation using unlabeled data[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing.Renals S.Stroudsburg,PA,USA:Association for Computational Linguistics,2007.970-979.
[9] Ukkonen E.On-line construction of suffix trees[J].Algorithmica,1995,14(3):249-260.
