一种基于作者建模的微博检索模型
2014-04-14王斌
李 锐,王斌
(1.中国科学院计算技术研究所,北京100190;2.中国科学院大学,北京100190)
1 引言
微博客(microblogging或microblog,也称微型博客,简称微博)是一种允许用户及时更新简短文本(通常少于140字)并可以公开发布的微型博客形式。它允许任何人阅读,也可以由发布者指定阅读权限阅读[1]。近期微博网站的发展如火如荼,不仅国外的微博网站Twitter、Facebook吸引了广泛使用和关注,国内的各大IT门户网站也纷纷推出各自的微博来抢占市场份额,比较著名的如新浪微博、腾讯微博等。据新浪和腾讯发布的最新统计,两者的用户数都已经超过2亿而逼近3亿,新浪微博用户平均每天发布的微博内容已达7 500万条。为了区分微博站点和用户具体发布的每条微博消息,在本文中前者称为微博站点,后者称为微博记录。
微博的发展,给互联网行业带来了新的机遇和新的挑战。它本身的信息更新快,文本较短且内容丰富。微博爆炸式的传播速度,给网民带来便利的同时,也推给读者很多不相关的信息。因此,微博用户往往有从大量微博记录中获得相关信息的需求。由于微博中主要包括两类对象:用户和微博记录,因此用户检索的对象也包括这两类。本文主要关注对微博记录的检索,即从大量微博记录中找出感兴趣的记录,如有关“威廉王子大婚”、“美国大选”等主题的记录。从这个意义上说,微博检索和传统检索非常类似。
微博检索与传统的检索有很大不同,微博站点的特点为微博搜索带来了新的挑战:
(1)文本短,微博记录平均长度只有十几个词[2],一个很偶尔在微博记录里出现的词将被认为有很大的概率。这给微博记录的模型估计带来很大的问题,且微博中很多的简称缩写、表情、错字和不正规的符号也给词的匹配带来困难;
(2)每个微博记录都是有作者(发布者)的,作者都有或多或少个人信息,而如何将作者的信息合理融入检索模型也是一个值得研究的问题;
(3)用户之间有关联(关注、互粉、回复、转发等),并形成巨大的关系网络;
(4)微博记录里包含很多转发,回复,Hashtag话题(用#括起来的部分,如#物价上涨#,#回家过年#)和网页链接URL,甚至图片与视频[3-4]。
传统的web检索模型并未考虑这些问题,未对这些文本和非文本内容建模;本文只关注前两点对检索带来的影响,主要思想是针对上述提到的微博较短的问题,使用作者模型对微博记录进行了扩充;又从语义层面,使用作者的话题模型来对微博检索模型做了平滑。
本文后续内容组织如下:第2节对相关工作进行简单的介绍;第3节提出了一个作者模型,将微博中的作者信息应用到微博检索中;第4节讨论了如何利用这些作者信息来估计作者的模型,并将其用于排序函数中;第5节对我们的实验平台、步骤以及结果做了阐述和讨论。最后对本文的工作做了总结,并说明了下一步工作的方向。
2 相关工作
微博检索涉及到传统检索以及微博特定的技术,所以本节从两个方面来介绍相关工作。首先,我们先简单介绍传统的检索方法并对其在微博检索上应用情况进行分析;其次,我们介绍微博检索相关的一些研究工作。检索中要使用到自然语言处理的一些预处理工作,其中中文要有切词,英文要有词根还原等问题。因此本文遵从文献[5]中的说法,用词项(处理后的词)来代表查询和文档的基本单位。
2.1 传统的方法
传统的检索方法主要有两大方法:基于相似度的向量空间模型的方法和基于概率模型的方法。但近年来提出的语言模型,带来了新颖的表达和建模方式,还具有灵活且易于扩展的特点,也引起了广泛的关注和使用[6]。
2.1.1 向量空间模型与概率模型
向量空间模型是信息检索中最基本的表达模型之一,认为每个词项对应向量空间的每一维,从而将查询和文档都表示成向量空间中的一点。在向量空间模型的基础上,大量工作使用查询和文档在空间中的相似度作为打分函数(或称为排序函数),得到查询和每个文档的分数后,根据这个分数从高到低将文档作为检索结果返回[5-6]。
另一个比较重要的模型是概率模型,主要思想是计算p(R=1|d,q),也就是计算给定查询和文档的情况下,它们相关的概率,然后再依据概率排序原理来得到最后的排序结果,详见文献[5-6];概率模型认为影响查询结果的因素主要有:词在文档中和查询中的频率,词的文档集频率,文档长度。
2.1.2 语言模型
1)查询似然模型
语言模型最早由Ponte和Croft提出[7],最基本的语言模型是查询似然模型,主要思路是认为每个文档是一个语言模型,而查询则是文档模型的一个抽样。计算在每个文档模型Md下,抽样(生成,产生)出查询q的概率。而最终就是基于这个概率p(q|Md)来对文档进行排序,最后得到检索结果。基本公式如式(1)所示。

其中w代表词项,q代表查询,d代表文档,c(w,q)代表该词在查询中出现的次数。p(w|d)是文档产生词项的概率,最基本的方法采用式(2)来估计:
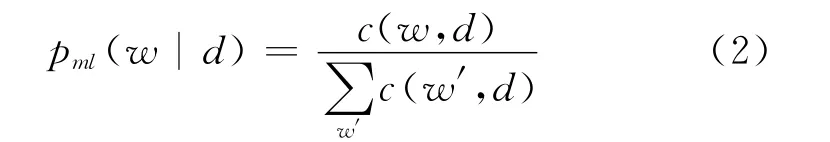
其中c(w,d)代表词w在文档d中的出现次数。
2)平滑方法
上述的估计文档产生词项概率p(w|d)的方法,文档中每个词项权重相等,未考虑噪音,而且对于文档中未出现的词会得到零概率,影响打分函数的计算。因此语言模型的工作大都采用文档集频率p(w|C)做了平滑,主要的平滑方法有Jelinek-Mercer(JM)平滑和Dirichlet Prior(DIR)平滑。其中JM平滑在最大似然估计的基础上,做了一个线性插值,具体公式如式(3)。

其中λ是JM平滑的平滑参数,C代表文档集。而DIR平滑中的平滑参数是与文档长度相关的,具体公式如式(4)。

其中μ是平滑参数,|d|代表文档长度,文档长度越大,前式越大后式越小。也就是说,DIR平滑与JM平滑相比,平滑参数与文档长度有关,对短文本做了更大的平滑[6]。
2.2 相关工作
近年来对微博的研究较多,除了传统的微博分类聚类摘要等[2-3,8],微博检索也是一个热门的研究方法[4,9-12]。其中Rinkesh Nagmoti等人[4]采用了一些启发式的方法,简单考虑了作者入度出度,是否URL等信息,并未对作者发布的所有微博记录建模;Kamran Massoudi[9],Miles Efron[10]对微博检索中的查询的扩展做了一些研究,分别考虑了微博中的时间和Hashtag因素;Wouter Weerkamp提出了几种生成式模型[11],根据查询来挑选外部资源,来对查询进行扩展;Yajuan Duan在文献[12]中使用了learning to rank的方法来对微博进行检索。而从微博记录扩充的角度来改进微博检索模型的工作还比较少。
除了使用文档频率(df)和文档集频率(cf)的平滑方法外,对稀疏性的解决最重要的方法之一就是丰富和扩展稀疏的数据。传统检索中专门用于文档扩充的方法并不多见,大多都是在语言模型基础之上提出来的,这是因为语言模型中有单独的文档模型,可以较为方便的融入各种信息。目前可以看作是对文档内容扩充的方法主要有基于聚类的方法[13-14],基于话题模型的方法[8],基于上下文的方法[15-16]和使用翻译模型[17]。其中前三种方法都是在数据集本身的数据上,最后一种方法可以使用已有的或离线训练好的翻译词典,因此可以利用外部信息。
使用聚类来对文档内容做扩充[13]的方法,其主要思想是首先将文档聚类,得出每个类别Ci在词上的分布p(w|Ci),然后,将类别的分布作为p(w|d)的插值平滑。但在微博检索场景下,有一定的问题:首先聚类的结果不容易评价好坏,再者聚类在文档很短的情况下本身也不能达到很好的效果。基于话题模型[14]的方法思想与基于聚类的方法类似,也存在着话题在文档很短的情况下不能很好的训练的问题。基于上下文的方法主要思想是将微博中对同一条微博记录的回复,转发等记录重新组合成一条新的文档,相当于对微博记录做了丰富和扩充。但该工作未将其用于检索模型中,也没有考虑同作者的微博记录。
信息检索中的翻译模型是一种生成模型,认为从文档生成查询词的过程分为两个步骤:首先文档产生出文档本身的词,然后这个词经过一次“翻译”,翻译到查询词。该方法可以较为灵活的融入各种信息,重点在于翻译概率的学习上。本文提出的使用作者信息扩展微博的方法重点关注于对作者信息的利用,亦可以与上述各种方法结合使用。
3 作者模型
传统的方法,建立在这样一个假设上:给定的文档足够长,平滑模型适合,可以很好的估计出文档模型。概率模型认为文档中每个词项出现的频率(tf)以及词项的文档频率(df)可以代表该词项的权重。但对于微博检索来说,微博记录很短,一个很偶尔出现的词项会占有较大的概率,而真正核心的词项也可能只出现一次。也就是说,在这种极短的情况下,没有足够的信息来估计文档的模型。在语言模型中,p(w|d)代表了一个文档在每个词项上的分布,而基本的估计方法也是通过极大似然来估计,最终也转到词频统计上来。虽然采用了文档集的频率作为平滑方法,但文档集里所有文档采用的是同一平滑,最终得到的效果也类似于df。因此,在文本极短的情况下,使用查询似然模型和基于文档集的平滑方法估计p(w|d)的时候也存在严重的稀疏性问题。
本文实验中发现,除去非英文、非文本信息、回复转发符号(@)、URL,Hashtag(#)以及表情等,微博记录的平均长度只有9.75。如上节所说,极偶尔出现的一个词将会有很大的产生概率,如直接对文档建模存在着很大的稀疏性问题。
3.1 模型与检索
本节在语言模型框架下提出一个根据作者信息来丰富微博记录模型。作者信息在文本方面,最重要的就是作者发布的微博记录。在语言模型的框架下,每个文档都可以估计出一个语言模型,因而对于作者来说,也一样可以估其所对应的语言模型。语言模型认为一篇文档在观测到的词项(文档里出现的词项)上有分布,在未观测到的词项上也有分布。使用文档集的平滑方法基于的思想是:未观测的词项出现的概率p(wunseen|d)等于该词项在文档集上的频率p(w|C)乘以某个权重。而微博记录则因为长度的限制,会尽量的简练它的语句,需要更细致的平滑方法。本文提出作者模型的意义在于,可以对未观测的词项做更加细致的估计,在微博记录未观测到的词项中:①文档集出现过的词项具有一定概率;②作者发表过的词项也会有一定的概率,且与整个文档集中出现过的词项不同。本节的思想可以从两种角度来描述,一是从平滑的角度来看,使用作者的语言模型作为背景平滑模型,若使用JM平滑,更新公式如示(5)所示:

其中α和β是JM平滑方式下的平滑参数,p(w|A)是词项在某作者所发表所有文档里出现的频率,它代表了词项w由文档d的作者写出的可能性。若使用DIR平滑,则更新公式如式(6)所示:

其中μ1和μ2是DIR平滑方式下的平滑参数,μ1可以反映p(w|A)所占的权重,μ2可以反映p(w|C)所占权重。最后将上述两种p(w|d)分别代入式(1)中即可。
二是对排序函数的改进,直接计算出微博作者在查询q上的分数,然后与已有分数做一个插值,也就是直接更新式(1)为新的排序函数,如式(7)和式(8)所示。

其中Sa-JM为使用JM平滑的作者模型得到的排序分数,Sa-DIR(q,d)为使用DIR平滑的作者模型得到的排序分数。这两种公式(式(5)对应式(7),式(6)对应式(8))分别是等效的,推导也较为简单。为方便起见,本文后续的公式将按照第二种公式继续给出。
3.2 作者模型描述
本文使用的作者模型是利用作者的信息来丰富文档的信息,从而估计出更加准确的文档模型,那么如何计算作者模型S(A,q)呢?根据上文我们知道,每个微博记录都有发布者(作者)。作者信息包含三个部分:作者的个人信息,作者发布的微博记录,作者的关系网络。而作者发布的所有微博记录又可以使用话题建模。因此本文提出作者模型可以分为几部分估计,如式(9)所示。

其中A代表作者,Stweet代表使用作者发布的所有微博记录得到的分数,Stopic代表作者所有微博记录的话题模型得到的分数,Sprofile代表作者个人信息,如个人标签、工作等信息的模型,Snet代表作者的关系网络在查询上得到的分数,一可以使用作者的“粉丝”信息,二可以使用作者在微博中的静态rank来估计。其中因为数据集的关系,Sprofile和Snet在本文实验中并无使用。
4 作者模型估计
本节的实现中作者模型S(A,q)的意义是,将查询视为从文章里抽出的关键词,给出一个查询,估计出该查询是由某作者的文章里抽出来的可能性。认为这个可能性越大,该作者与该查询的相关度也越高。
4.1 作者模型
基于上述思想,我们的作者模型分为两部分,第一部分是作者发布的所有文章估计作者的模型:Stweet(A,q)。它的计算与之前的查询似然模型的计算类似,但要将同作者发布的所有微博记录全部收集起来。具体计算方法如式(10)所示。
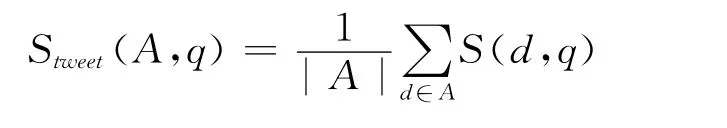

其中|A|代表作者发布的微博记录的个数。
4.2 作者话题模型
第二部分是作者的话题模型,使用作者发布的微博记录估计的作者模型,只有对作者发布过的词项会估计其概率,而不能调整语义相关的其他词,例如:一个作者发布了很多关于“World Cup 2022”、“FIFA”的微博,那么“soccer”、“football”等词项是很相关的,也应具有一定的出现概率。尤其当一个作者发布的微博较少的情况下,估计出语义相关的词出现的概率更显重要。本节提出的话题模型正是为了一定程度上解决该问题。
那为什么不直接对微博记录本身使用话题模型呢?话题模型(topic model)从问世以来就一直备受青睐[18-20],主要思想是对每个文档的隐语义空间建模,也就是认为每个文档在话题上有一个分布,而话题本身又是在词汇表上所有词的分布。每个话题是潜在语义空间里的一维,将同一语义以话题的形式组织起来。但在话题模型中训练出话题分布时,使用了词和词的共现关系。这些共现指的是每篇文档内的共现,对文档长度有很大依赖性。因此微博场景下,微博记录很短,会造成词的共现矩阵稀疏度很高。那么直接使用PLSA或LDA训练出的话题将不会有很好的效果[21]。
基于上面两个原因,本文并不基于每条微博记录来训练话题模型,而将同一作者发布的所有微博记录视作一个文档,然后对新文档集来训练话题模型,将其用于文档内容的扩展中。融合使用作者的话题模型之后,一个微博记录在未观测到词项的分布将包含以下三种:①文档集出现过的词项;②作者发表过的词项;③作者感兴趣的话题所包含的词项。
这种方法还使得每个“文档”的长度变长,丰富了词的共现矩阵,降低了该矩阵的稀疏度。可以很大程度上改善微博记录很短导致的话题难以训练的问题。在训练出作者的话题模型之后,基于该模型的相似度计算如式(11)所示。
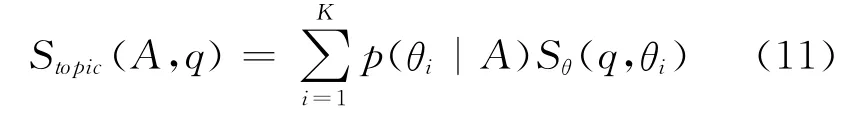
其中K代表总话题个数,θi代表每个话题,而Sθ(q,θi)又由式(12)得到。
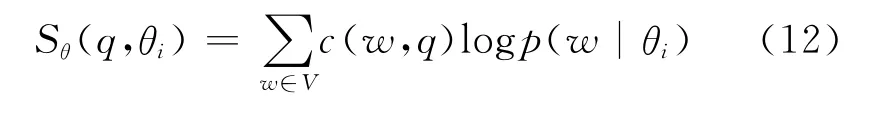
4.3 噪声去除
由于上文中的作者模型,使用的是作者发布的所有文档来估计的。而作者在同一时间段内可能会发布一些各不相关的微博,因此上述模型也会引进大量的噪音。所以本文在此引入一个阈值Td,当前文档与作者发布的某微博记录相似度大于Td时,才用该微博记录来对当前文档扩展,进而估计文档模型。Td意在剪除同作者发布的完全不相关的文档,对某条微博记录扩展造成的影响。对文档d′进行扩展时,计算相似度的公式如式(13)所示。
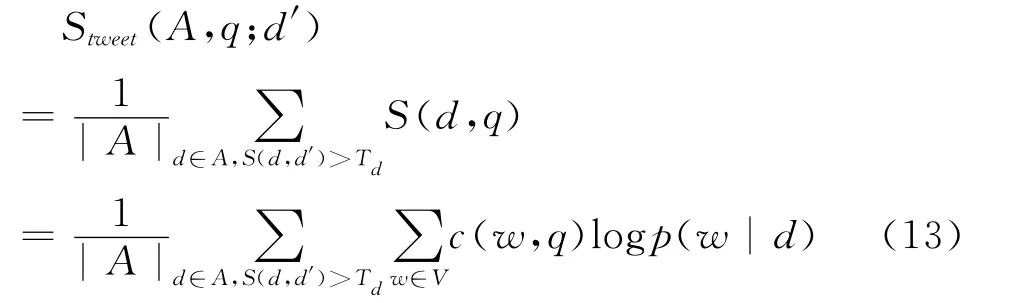
同样,作者话题模型训练出作者在每个话题上都有一定概率,因此在作者的话题模型上,我们也引入一个阈值Tt,当作者在话题上的分布大于Tt时,才认为该话题是作者感兴趣的话题。Tt意在剪除作者话题中的噪音,留下作者最可能关心的一些话题。剪除之后重新归一化,新公式如式(14)所示。
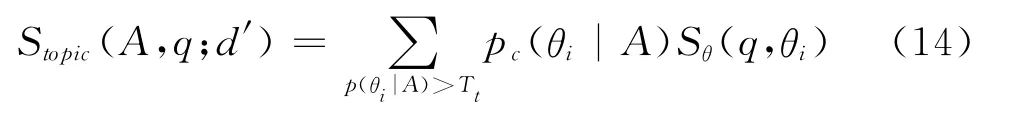
5 实验与分析
本文实验的数据集采用TREC 2011中的微博检索子任务提供的数据集。这也是目前研究界公开的支持微博检索的数据集。微博是动态性的,存在用户更名或者微博记录被删掉的情况。因此,除去少许网络问题和已不存在的微博记录,再去除一个无任何相关文档的查询(不影响评价结果),我们的数据集共包含49个有效查询和14 889 941条微博记录。其中包含URL的约占18.2%,包含回复(@)的约占42.4%,包含Hashtag(#)的约占13.3%。
评价方法包含TREC 2011官方指定评价方法P@N(前N个结果的正确率)和MAP(宏平均正确率)。实验取前15个查询作为测试集,后34个查询作为训练集。实验结果如表1所示,其中“QLM”表示查询似然模型,“AM”表示用作者发布的所有微博记录估计出来的作者模型(即式(9)仅使用Stweet),“ATM”表示作者模型与作者的话题模型(式(9)里使用Stweet和Stopic(A,q)),“JM”表示JM平滑,“DIR”表示Dirichlet平滑。
5.1 作者模型
作者模型的对比实验中,我们首先收集同一作者发布的所有微博记录作为一个新文档,这样共收集到5 075 108个作者,经过porter切词和过滤掉非英文等信息后,剩余3 673 968个有效作者,采用Indri对其建立索引,每个作者的平均文档长度达到了32.97。然后根据这个新文档集来训练话题模型,初始参数α=1,topic个数N=2 000。从表1和表2中可以看到,作者模型的效果较好。效果的提升可能由于两个原因:1)作者模型丰富了微博记录的模型,一定程度上缓解了极短文本带来的问题;2)根据训练好的话题模型,可以从隐含的语义层面匹配作者与查询词。但微博记录较短,直接使用话题模型训练的效果很差。本文提出的作者的话题模型则含有较长的文本,可以有效降低词共现矩阵的稀疏度:平均长度为9.75的文档,其中词的共现信息约为45个(以33计算),而文档长度扩展为32.97时,词的共现信息约为528个(以33计算),提高了约11.7倍。另外实验结果中还可以看出,P@10和P@20都有较大的提升。搜索引擎中也越来越重视前N条结果的正确率,因为可以极大地提高用户体验度,很大一部分的检索过程中用户都只看前两页结果。还有值得注意的是,在宏平均正确率MAP提高的基础上,P@30与未使用作者模型相比有稍许降低,这也一定程度上说明我们的模型可能也引入了部分噪音,但与提升效果相比还是可以接受的。
其中本次实验得出的参数如下:查询似然模型JM平滑的参数λ=0.8,DIR平滑参数μ=4 000;作者模型中作者的JM平滑参数β=0.02,文档集JM平滑参数也为0.8。作者模型中作者的DIR平滑参数μ1=1,μ2=4 000;作者话题模型中,话题的JM平滑参数0.02,话题的DIR平滑参数为1(反映了式(9)中λ2的大小)。也就是说在JM方式平滑下,在估计p(w|d)时,作者发表过的词项,约以十分之一的概率扩展给微博记录较好,而采用DIR方式平滑时,需要的则更小。因此实验结论是,不论是作者模型还是作者的话题模型,采用两种平滑方法都在取较小的平滑参数时达到较好的效果。
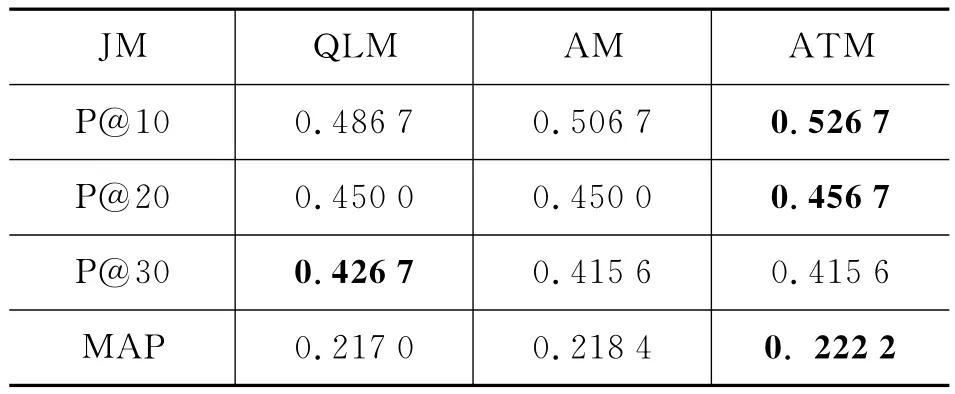
表1 JM平滑下查询似然,作者模型与作者话题模型的实验结果
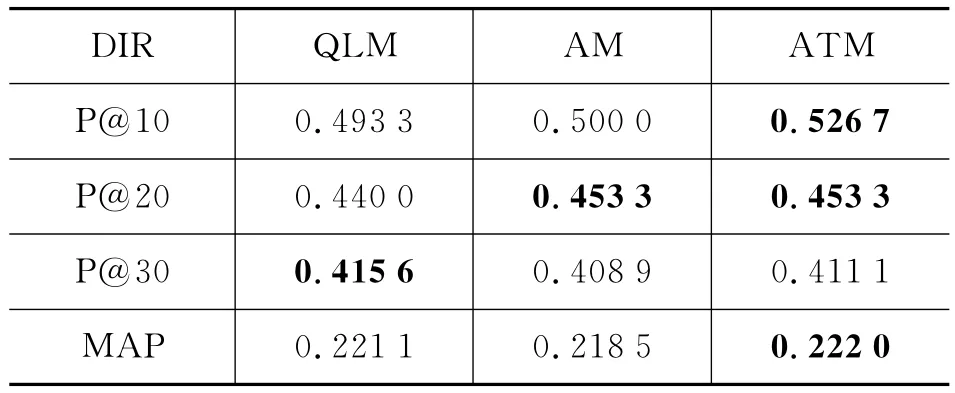
表2 DIR平滑下查询似然,作者模型与作者话题模型的实验结果
5.2 参数敏感性
在作者模型中,与平滑参数不同的是我们引入了新的参数:阈值Td实验中阈值取了训练集上的平均最好值。阈值Td与检索结果的关系见图1,从图中可以看到,当阈值变化的时候,四个指标的变化(尤其是P@30与MAP)都很平缓。也就是说我们提出的作者模型对Td这个参数并不敏感。

图1 JM平滑下的阈值Td(左),DIR平滑下的阈值Td(右)
在作者的话题模型做平滑的实验中,我们引入的新参数是Tt,同样的阈值也选取的是训练集上训练得出的平均最好值。阈值Tt与检索结果的关系见图2,在JM平滑下,作者的话题模型表现出对阈值Tt更加不敏感,稳定性稍好。

图2 JM平滑下的阈值Tt(左),DIR平滑下的阈值Tt(右)
6 总结与下一步工作
本文根据微博检索的特点,提出了使用作者模型来对微博记录进行扩充。具体实现方式是首先在语言模型的基础上用作者模型作为背景模型,对微博记录的语言模型做了平滑;然后采用了作者训练话题模型,改善了微博记录较短的问题。最后将作者模型和作者话题模型用于微博检索实验,再对其中的阈值进行了分析与敏感性实验。实验证明本文提出的方法可以有效地提高微博检索效果,具有良好的稳定性。
有以下几点可以作为与本文相关的下一步工作方向:
(1)物以类聚,作者关系网络比较重要,但由于实验数据集没有作者的个人信息和作者关系网络,因此第3节中的作者模型并没有使用这些信息。下一步工作我们将采用更多的微博数据集,并对作者的“粉丝”以及作者的静态重要度(类似于page rank的作者rank)做相应的研究;
(2)本文使用的方法主要是对微博记录进行扩展,而影响查询效果的另一个重要方面是查询扩展。因此下一步工作将深入分析微博查询,分析较短的反馈文档对查询扩展的影响,并将作者网络等因素引入查询的重构当中;
(3)本文的实验过程中发现,作者发布的微博记录数目差别很大,存在发布微博记录特别少的用户。在这种情况下,本文提出的作者模型尚有很多值得研究和改进的地方。
[1] 维基百科[OL]http://zh.wikipedia.org/wiki/%E5% BE%AE%E5%8D%9A.
[2] Sharifi B P.Automatic Microblog Classification and Summarization[D].2010.
[3] Sriram B,Fuhry D,Demir E,et al.Short Text Classification in Twitter to Improve Information Filtering[C]//Proceeding of the 33rd international ACM SIGIR conference on research and development in information retrieval,2010.
[4] Nagmoti R,Teredesai A,Martine De Cock.Ranking Approaches for Microblog Search[C]//2010IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology,2010,(1):153-157.
[5] Christopher D M,Raghavan P,Hinrich Schutze,王斌(译).信息检索导论[M].北京:人民邮电出版社,2010.
[6] Cheng X Z.Statistical Language Models for Information Retrieval[M].Foundations and Trends in Information Retrieval,2008.
[7] Jay M P,Croft W B.A language modeling approach to information retrieval[C]//Proceedings of the 21st annual international ACM SIGIR conference on research and development in information retrieval,New York,USA.1998.
[8] Ramage D,Dumais S,Liebling D.Characterizing microblogs with topic models[C]//ICWSM,2010.
[9] Massoudi K,Tsagkias M,Rijke M D,et al.Incorporating Query Expansion and Quality Indicators in Searching Microblog Posts[C]//ECIR,2011,4:19-21.
[10] Efron M.Hashtag Retrieval in a Microblogging En-vironment[C]//Proceeding of the 33rd international ACM SIGIR conference on researchand development in information retrieval,2010.
[11] Weerkamp W,Balog K,and Maarten de Rijke.A Generative Blog Post Retrieval Model that Uses Query Expansion based on External Collections[C]//Proceedings of the Joint Conference of the 47thAnnual Meeting of the ACL and the 4th International Joint Conference on Natural Language,2009.
[12] Duan Y J,Jiang L,Qin T,et al.An Empirical Study on Learning to Rank of Tweets[C]//Proceedings of the 23rd International Conference on Computational Linguistics,2010.
[13] Liu X,Croft W B.Cluster-based retrieval using language models[C]//Proceedings of the 27th international ACM SIGIR conference on research and development in information retrieval,2004:186-193.
[14] Wei X,Croft W B.Lda-based document models for ad-hoc retrieval[C]//Proceedings of the 29th international ACM SIGIR conference on research and development in information retrieval,2006:178-185.
[15] Pochampally R,Varma V.User context as a source of topicretrieval in twitter[C]//Proceedings of the 34rd international ACM SIGIR conference on research and development in information retrieval,2011.
[16] Karmarkar A,Peters R,Context-enriched Microblog Posting.U.S.Patent No.US20100211868A1,2010.
[17] Karimzadehgan M,Cheng X Z.Estimation of statistical translation models based on mutual information for ad hoc information retrieval[C]//Proceedings of the 33rd international ACM SIGIR conference on research and development in information retrieval,2010.
[18] Blei D M,Ng A Y,Jordan M I.Latent dirichletallocation[J].The Journal of Machine Learning Research,2003,3:993-1022.
[19] Hofmann T.Probabilistic latent semantic indexing[C]//Proceedings of the 22nd annual international ACM SIGIR conference on research and development in information retrieval,1999:50-57.
[20] Rosen-Zvi M,Griffiths T,Steyvers M,et al.The author-topic model for authors and documents[C]//Proceedings of the 20th conference on uncertainty in artificial intelligence,2004.
[21] Ramage D,Dumais S,Liebling D.Characterizing Microblogs with Topic Models[C]//Proceedings of the ICWSM 2010:130-137.
