基于词典和统计相结合的维吾尔语拼写检查方法
2014-04-14麦合甫热提艾山吾买尔麦热哈巴艾力吐尔根伊布拉音
麦合甫热提,艾山·吾买尔,麦热哈巴·艾力,吐尔根·伊布拉音,张 健
(1.新疆大学教务处,新疆乌鲁木齐830046;2.新疆大学信息科学与工程学院,新疆乌鲁木齐830046;3.新疆虹联软件责任公司,新疆乌鲁木齐830002)
1 引言
人工进行拼写检查是一项时间耗费量巨大而繁杂的任务。因此计算机自动校对系统的研究与开发是自然语言处理的主要应用领域之一,可应用于报刊及出版社、打字、文字识别等需要进行文本校对的行业。
在中国,中文(汉文)校对方面的研究已有了一定的深度,有很多研究成果现已商品化,如黑马校对系统、金山校对系统、工智校对通等。维吾尔语校对方面也有了一些商品化的软件。如,Yulghun维吾尔语正字法校对系统,维软公司维吾尔文正字法校对系统等。但这类软件是基于词汇库的,由于软件的准确率取决于词汇库的容量,因此对词汇库的要求很高。为了弥补基于词典的查错方法具有鲁棒性不高,对词干提取无法检查连接的词缀是否有效等不足,结合维吾尔语的特点,我们提出了词典与统计相结合的方法。
2 维吾尔语拼写检查
维吾尔语属于黏着语言[1],因此在拼写过程中难免会出现拼写错误,而且拼写错误率较高。在实际使用过程中,有些单词的拼写检查根本不会影响读者对内容的正确理解。但是,拼写错误不仅对出版行业重要,对语言自身的健康发展也很重要。
拼写错误一般指的是键入的文本,即人们键入文本时,无意识或不知正确拼写的情况下,根据发音拼写单词而产生的错误。拼写错误一般情况下可以归于两类:非词错误和真词错误[2]。本文对非词错误的差错进行研究。例如,(作者们)这个单词如果在文章中错误地写为:那么拼写检查的任务就是及时发现错误,并用正确的拼写替换错误的拼写。
3 词典与统计相结合的拼写检查方法
3.1 基于词典和词干提取的拼写检查方法
维吾尔语属于高度或强黏着语言,在实际的文本中多数单词为表达语法功能,在单词词尾附加词缀。维吾尔语中所有词类的构形词缀大约有210个,这些词缀不仅可以单独出现,也可以相互连接。因此,一般情况下很难把每一个单词的所有形态变化或词形收录于词汇库。表1所示单词“书”(kitab)的部分词形。

表1 名词“书”的各种形态变化
为了提高查错能力,减少正确单词因形态而被判断为拼写有误的单词,本文中采用了先从常见正确词库匹配词汇,然后对未被匹配的单词进行词干提取,并对词干进行词干库匹配的策略。
正确词汇库是从生语料库收集所遇的词汇,并对其进行频率统计,然后根据单词频率进行人工校对而建设。目前,词汇库包括的单词有30万词汇,词干库有11万多词干。为了不断地扩充词汇库,使词干提取后被判断为正确的单词增加到正确词词汇库,提出基于词汇库和词干提取的拼写检查算法如下:
S1:读入词汇Wi;
S2:从词汇库检索Wi,若存在转S6,否则转S3;
S3:对Wi进行词干提取,若词干Si与Wi相同,则转S7,否则转S4;
S4:从词干库检索词干Si和词缀组合,若存在转S5,否则转S7;
S5:把Wi加入词汇库;
S6:返回正确;
S7:返回错误;
例如,“kitab”的变形为正确拼写词汇库,对单词“kitabtek”(像书那么…)进行拼写检查时,因词汇库不包含该词汇,系统对其进行词干提取,因词干“kitab”和词缀“tek”存在于词干库,系统判断该单词拼写无误,并把“kitabtek”加入词汇库。通过这种方法可以不断地扩充词典,减少词干提取,系统速度会得到较高的提高。
3.2 基于统计的词干和词缀连接有效性判断模
基于词典的查错方法具有判断结果可靠,速度快等特点,但是也有鲁棒性不高、对词干提取无法检查连接的词缀是否有效等不足。维吾尔语词法语音和谐规则中指定,单词元音或最后音节的元音是前元音,则只能附加包含前元音的词缀,若单词的最后音节的元音是后元音,则词缀只能附加包含后元音的词缀。例如,词干“kitab”可以附加词缀“ta”而不能附加“te”。因为“kitab”最后音节“tab”所包含的是后元音“a”,因此,只能连接包含后元音的“ta”,而不能连接包含前元音的“te”。虽然,词干和词缀的连接具有元音和谐的规则,但是还有很多情况,并不能根据元音的前后特性来予以判断。例如,词干可以附加但不能连接词缀这个两个词汇完全符合元音和谐规则;词干(巴扎尔)可以连接词缀而不能连接词干尾处附加构形词缀,不仅符合元音的和谐规则,还要看语义上是否合适。
根据研究,目前还没有比较可靠的规则可用。为了检查词缀连接的有效性以及提高系统对未登录词的检查能力,本文中使用N语言语法建立维吾尔语词干词缀有效性判断模型和词干提取匹配失败的单词拼写检查模型。
N-gram是最为常用的统计语言模型,其中尤以二元文法(Bigram)和三元文法(Trigram)模型应用最为广泛。n-gram以马尔可夫模型为理论基础,对一字符串L=l1l2l3,...,li,可以认为字母li(1≤i≤n)的出现与上文的前n个字母相关,则字符串L出现的概率可通过如下的方法得出:
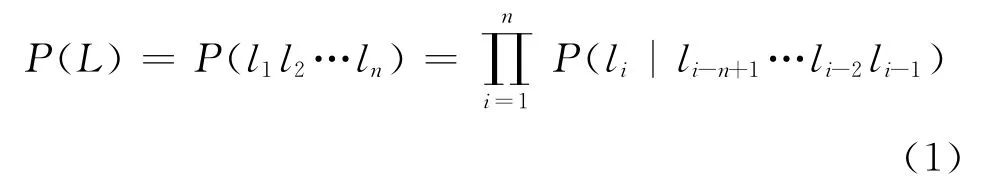
一般来说,n取2或3。该模型在维吾尔语可以建立为字母序列概率模型、音节序列概率计算模型,不仅仅可以为拼写检查提供服务、还可以为OCR、语音识别等提供语言模型服务。比如,可以计算出单词基于二元、三元或音节的困惑度如式(2)所示。
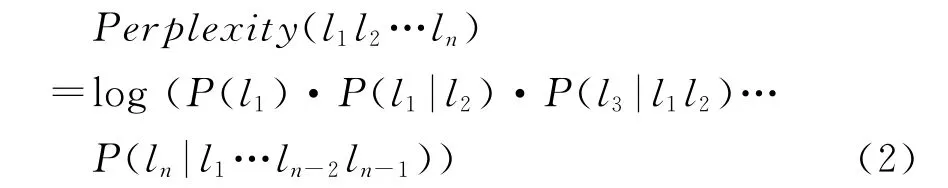
困惑度越高表示该序列的自然率就越高,困惑度越低表示该序列越接近于自然情况。根据困惑度所表示的信息,可以得出拼写有误单词的困惑度大于拼写正确的单词困惑度。另外,为了建立该模型,还可以计算某些序列后出现某一个字符或字符串或音节等的概率P(s|context);为了确定适合于维吾尔语单词拼写判断,利用30万词的词汇库构建了基于二元、三元、四元以及五元的模型训练,并进行了测试。表2所示的是对词干各类形态的实例进行计算的结果。
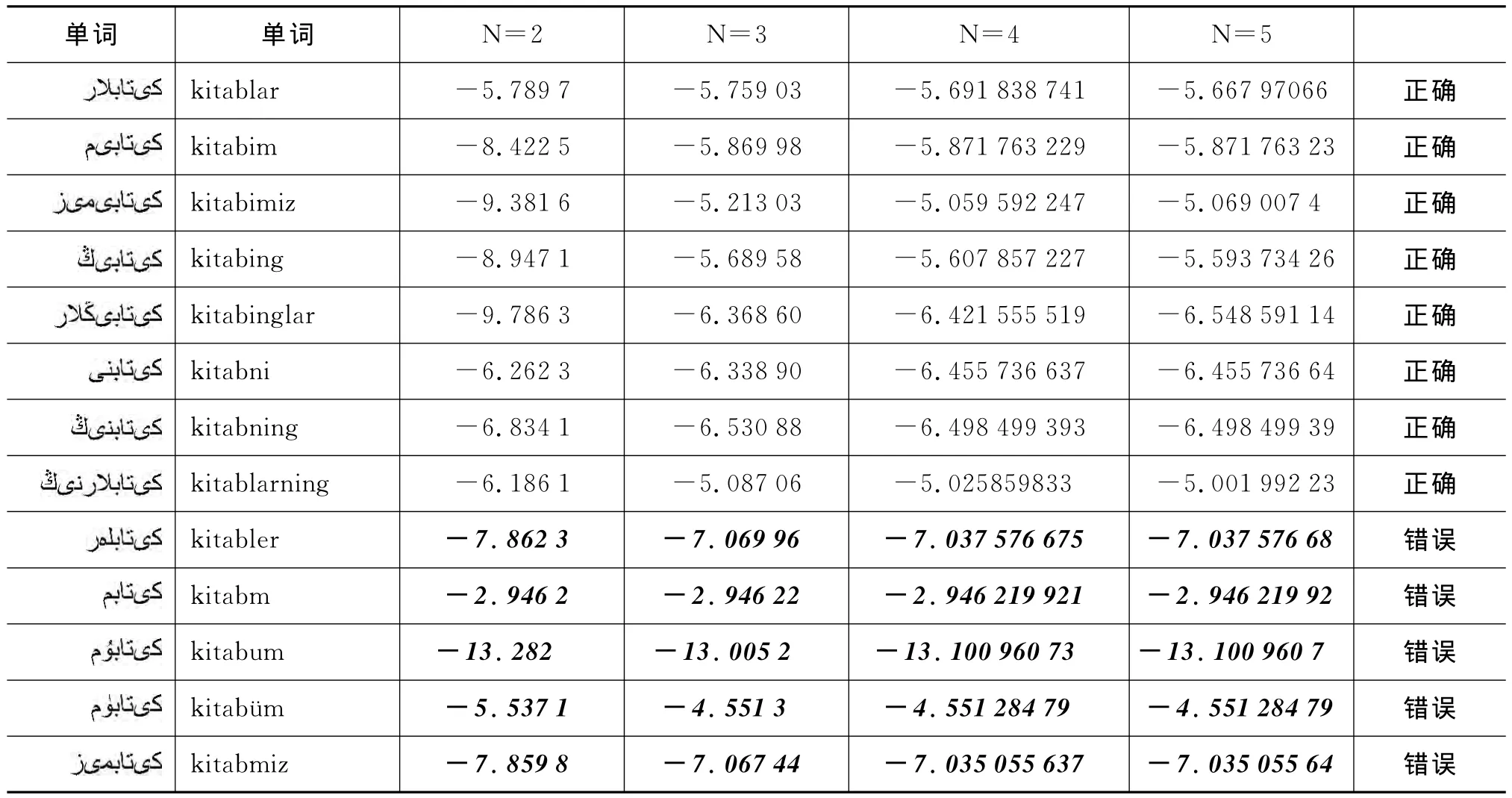
表2 词汇困惑度计算实例

续表
由表2可知,正确单词的困惑度取值范围比较稳定,而大部分错误单词的困惑度随着N的变化而发生较大的变化,根据实验发现N越大的时候,正确和错误单词困惑度的差距越大。因为维吾尔语字母互相搭配频率较高,且比较灵活,二元、三元等较短的N元组合无法充分体现同现规律,而四元、五元等因较长,所以能代表一定的局部,具有较强的约束能力,计算出的困惑度也具有较高的可靠性和代表性。另外,不同正确单词的困惑度的变化也较大,难以使用统一的阈值来判断单词是否正确。例如,虽然错误单词等的困惑度比正确单词较大,而的困惑度比正确单词较少。根据实验结果,本文中提出阶梯层判别模式,分三层计算单词三元至五元的困惑度,根据语料库中建设的词干平均困惑度来判断词缀连接的有效性。
具体过程如下:
利用正确词汇训练三元、四元、五元模型;
对词汇库进行词干提取,把所有的单词根据词干进行分类;
把同一个词干的词汇根据连接的词缀数进行分类;
通过以上过程构建的词干和词缀概率库文件结构如表3所示。

表3 根据词干和词缀分类实例
从表3中的数据产生词干的困惑度词典,词典中保存词干附加一个词缀的困惑度范围和词干附加两个或三个词缀的困惑度范围。词典结构如表4所示。
对词干在词干库中存在的单词进行判断时,先计算该单词的困惑度,然后根据该单词连接的词缀个数与困惑度范围词典进行比较。若在范围之内,判断为正确,否则判断为错误。例如,表2中的单词的词干为词缀为()“m”,该单词三元、四元、五元的困惑度分别为-2.946 22、-2.946 219 921、-2.946 219 92,该单词的困惑度不在困惑度范围词典中的取值范围之内,因此判断为错误词缀连接。

表4 词干形态困惑度范围词典
3.3 基于词典和统计相结合拼写检查方法
基于词典的方法具有可靠、速度快等特点,但鲁棒性较低,对未登录词没有任何处理能力;而基于统计的方法对未登录词有一定的处理能力,但存在判断结果不完全可靠的不足之处。为了弥补各种方法的缺点,有效利用资源和经验值,最大程度上减少未登录词的人工处理,本文中把基于词典、词干提取和基于统计的词干和词缀连接有效性判断模型相结合,提出了统计与词典结合的维吾尔语查错方法。
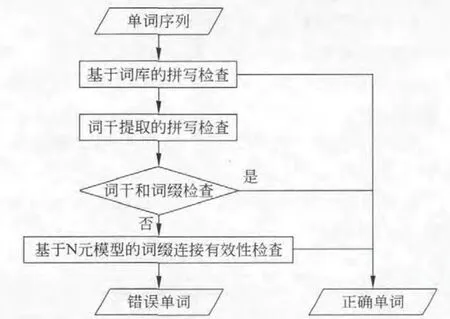
图1 基于混合策略的维吾尔语拼写检查方法
4 实验与分析
本节中的实验使用新疆多语种重点实验室自然语言处理组研制的维吾尔语语料库,其中正确单词规模为30万词、拼写错误与正确写法对照单词1.4万词,词干库11万词干。
4.1 基于词典的拼写检查
为了观察拼写检查词汇库的覆盖面,我们从新疆维吾尔自治区人民政府新闻网站(http://uygur.xinjiang.gov.cn/index.htm)下载100篇文章进行拼写检查,其中最长的文章有567个单词、最少的有150多个单词。经过测试,最高匹配率为99.12%,最低匹配率84.24%,不匹配的单词主要集中在术语、词缀层叠较高的词汇、外国人名、企业名称以及一些新产品名称等。
4.2 基于词干提取的拼写检查测试
对4.1中没有识别的单词进行基于词干提取的拼写检查后,最高匹配比例没有变化仍然是99.12%,但是最低匹配率提高到92.37%,主要对术语、词缀层叠较高的词汇的检查起到了一定的作用。基于词干提取后,未能匹配的单词主要是词缀弱化的外国人名、企业名称以及一些新产品名称等。
4.3 基于统计的词干和词缀连接有效性判断模型实验
在基于统计的词缀连接检查模型使用随机选出的25万词进行模型训练,其余的5万词和拼写错误的1.4万词作为测试数据使用。经过训练得到了7 308个三元、24 882个四元和36 974个五元。
为了更客观的评价模型的性能,我们采用准确率(Precision)、召回率(Recall)、F1值(F1-Measure)等性能指标进行评价。计算公式如下:

实验结果如下,召回率为87.52%、准确率为86.67%,F值为87.09%。经过错误分析发现,词缀正确附加词干错误判断的情况占95%,而词缀错误附加词干判断为正确的情况占5%。
第一种错误的原因是在词典中按照附加的词缀数量进行范围匹配,实际上同一个单词的不同词缀具有不同的长度,尤其是单词本身长度也不长,单词词缀的字符数比较多的情况一词中 是词干,长度为等为词缀)。因此,计算困惑度时较长词缀的困惑度值会超出范围。

表5 单词“beyjing”(北京)连接一个不同的词缀的困惑度
表5中可以看出,单词“Beyjing+lar”被模型判断为正确的词干和词缀连接,实际上是错误的连接,即错误的单词。经过对类似的错判的单词进行统计分析发现,这些单词和词缀的连接符合维吾尔文的词法的元音和谐规则,所以在训练库中大量的出现过一样的三元、四元、五元参数,这些参数值影响模型的判断结果。
第二种错误是外来的词单词结构与维吾尔文单词具有较大的差距,而大部分统计值来自于维吾尔语单词,所以对外来词的误判较多。
5 结术语
本文提出了由多种策略组成的拼写查错方法,并实现了实用的维吾尔文文字校对软件。在查错方法中为了弥补基于词典的方法的不足,提出了利用形态分析方法检查的方法。为了提高该方法的可靠性,又使用N元语法模型检查了词干和词缀连接的有效性。
在国内属于同类语系的有哈萨克语、柯尔克孜语,在国外有土耳其语、乌兹别克语、土库曼语等。维吾尔语在这方面的研究,将对这些国内外语言的研究具有很大的促进作用。
[1] Kukich K.Techniques for automatically correcting words in text[C].Proceedings of the ACM Computing Surveys,1992,24(2),377-439
[2] Boswell D.Language Models for Spelling Correction[C].Proceedings of the CSE 256,2004.
[3] Rickard J C.Domeij Viggo Kann Ola Knutsson.A Swedish Grammar Checker[R].Association for Computational Linguistics,2000.
[4] Dhanabalan T,Parthasarathi R,Geetha T V.Tamil Spell Checker[C].Proceedings of the Sixth Tamil Internet 2003Conference,Chennai,Tamilnadu,India,2003:22-24.
[5] Hamrouni B M.Logic compression of dictionaries for multilingual spelling checkers[C]//Proceedings of the 15th Conference on Computational Linguistics,Kyoto,Japan,1994:5-9.
[6] Menno van Zaanen,Gerhard van Huyssteen.Improving a Spelling Checker for Afrikaans[C]//Proceedings of the Language and Computers,Publisher Rodopi,ISSN 0921-5034,2003,47(1):143-156.
[7] Arif Billah Al-Mahmud Abdullah,Rahman A.A Generic Spell Checker Engine for South Asian Languages[J].IASTED 2003,2003:3-5.
[8] Dembitz S,Knezevic P,Sokele M.Developing a Spell Checker as an Expert System[J].Journal of Computing and Information Technology-CIT 11,2004:285-291.
[9] 施得胜,等.基于统计的中文错字侦测法[J].电脑与通讯.1992,8:19.
[10] 张仰森,丁冰青.基于二元接续关系检查的字词级自动查错方法[J].中文信息学报,2001,15(3):36-43.
[11] 阿里甫·库尔班,吐尔根·依布拉音,阿布力米提.维吾尔文单词拼写检查器的研究与实现[A].中国科学技术协会.
[12] 玛依热·依布拉音,米吉提·阿不里米提,艾斯卡尔·艾木都拉.基于最小编辑距离的维语词语检错与纠错研究[J].中文信息学报,2008,22(3):110-114.
[13] 海米体·铁木尔.现代维吾尔语语法(词汇学)[M].北京:民族出版社.1987.
[14] 古丽拉·阿东别克,米吉提·阿布力米提.维吾尔语词切分方法初探[J].中文信息学报,2004,18(6):61-65.
[15] 米热古丽·艾力,米吉提·阿不力米提,艾斯卡尔·艾木都拉.基于词法分析的维吾尔语元音弱化算法研究.中文信息学报[J],2008,22(4):43-48.
[16] 梁奇,郑方,徐明星,吴文虎.基于tri-gram语体特征分类的语言模型自适应方法.中文信息学报[J],2006,20(4).
[17] 麦合甫热提.维吾尔语文本词语拼写检错和纠错算法研究和实现[D].新疆大学硕士学位论文.2010.
