高光谱图像半监督局部稀疏嵌入降维算法
2014-03-25赵春晖崔晓辰
赵春晖,崔晓辰,齐 滨
(哈尔滨工程大学 信息与通信工程学院,黑龙江 哈尔滨 150001)
高光谱技术是遥感领域近年来兴起的新技术,在诸多领域获得了广泛应用.高光谱图像的光谱波段数多达几百个,在对高光谱数据分类时,常常会引起Hughes现象,特征提取是消除Hughes现象的重要手段之一.用于高光谱图像特征提取的传统算法包括无监督学习:主成分分析(principle component analysis,PCA)和利用图来逼近数据间局部流形的降维算法,如近邻保持嵌入(neighborhood preserving embedding,NPE)[1]、邻域保持投影(locality preserving projection,LPP)[2]、线性局部切空间排列(linear local tangent space alignment,LLTSA)[3]等算法;有监督学习有线性鉴别分析(linear discriminant analysis,LDA)算法.然而在实际应用中,只有少量的数据有标签信息,而获取有用的监督信息需要大量的人力和时间.因此,人们提出了能够同时运用无标签数据和有标签数据的半监督学习,能够得到相对较好的学习精度.半监督鉴别分析(semisupervised discriminant analysis,SDA)[4]算法是在LDA[5]目标函数中加入一个正则项,从而保持数据的内在关系.半监督局部费希尔鉴别分析(semisupervised local fisher discriminant analysis,SELF)[6]利用一个权衡参数将无监督学习和有监督学习结合起来,然而还没有标准来确定权衡参数的最优值.为了解决传统算法寻找最优参数的问题,最近,Liao等人提出一种无需调整参数的半监督局部鉴别分析(semisupervised local discriminant analysis,SELD)[7]算法,目标是寻找一种能够保持数据局部信息和最大化类间鉴别信息的投影方向.然而,流形学习算法在构造近邻图时,不可避免的要考虑参数的设置.其次LDA作为一种全局特征提取算法,无法获取数据的局部鉴别信息.本文提出一种半监督局部稀疏嵌入算法(semisupervised local sparse embedding,SELSE).利用稀疏表示系数[8]作为样本间相似度构建稀疏图,保持无标签数据在高维和低维空间的稀疏重构关系,最后通过求解广义特征值问题得到最佳投影,有效地实现了高光谱图像的特征提取.
1 半监督局部稀疏嵌入降维算法
1.1 问题描述
令X={x1,x2,…,xN}∈RD表示一个高维高光谱数据样本集,Z={z1,z2,…,zN}∈Rd是其低维子集,其中d≤D,D是高光谱数据的波段数,d是低维子空间的维数.目标是寻找一种映射,可以尽可能保持原始数据的信息,即
zi=f(xi)=WTxi.
(1)
其中投影矩阵W=[w1,w2,…,wd]∈RD×d.在特征提取算法中,投影矩阵W可以通过求解下式的最优问题获得,即
(2)

为了解决高光谱数据的半监督降维问题,本文算法需要利用基于稀疏表示系数构造图的无监督算法处理高光谱数据集中大量的无标签数据,同时利用基于局部几何关系的有监督降维算法处理高光谱数据集中少量的有标签数据,最后通过线性方法将两部分数据组合起来,确定投影矩阵,最终实现降维处理.
1.2 基于稀疏图的无监督算法
在基于流形学习的降维算法[9]中,图构造[10]一般采用K近邻算法[11].图中每个顶点只与自己在某种距离(如欧几里得距离)测度下的k个近邻相连接.这样得到的图是有向图,而很多基于图的半监督学习算法所用的是无向图,这样必须对图的边缘进行处理,需要引入近邻参数和热核参数.通常特征提取算法自动选择最优参数是十分困难的,而且没有唯一的标准.为了解决上述问题,采用基于稀疏表示的图构造策略,将高维数据集看作一个字典,求得每一个样本点在该数据集的稀疏表示向量,将得到的稀疏系数作为图连接结构.求解式(3)L0范数优化问题
min‖hi‖0,
s.t.xi=Xhi.
(3)
式中,‖·‖0为L0范数算子,hi是关于样本xi的稀疏重构系数向量.然而式(3)是一个NP-hard的非凸组合优化问题.在解足够稀疏的情况下,可以采用求解L1范数代替求解L0范数问题.
min‖hi‖1,
s.t.xi=Xhi;1=1Thi.
(4)
式中,‖·‖1为L1范数算子.问题的目标函数定义为
s.t.WTXXTW=I.
(5)
构建稀疏表示模型后,需要构建训练字典以及通过稀疏重构优化算法得到稀疏表示系数.可以通过贪婪寻踪算法得到近似结果,通过OMP(正交匹配追踪)和SP(子空间追踪)算法进行稀疏重构,得到稀疏系数.上述问题等价于求解最优化问题
wsparse=argmaxtr(WTXSsXTW),
s.t.WTXXTW=I.
(6)
1.3 基于局部几何关系的有监督算法
传统的LDA算法是全局算法,基于全局二阶统计量的,要求样本为高斯分布,以类中心来表示该类样本.因此算法容易被原始空间中本来就相距较远的样本主导,并且没有考虑到局部的数据分布.通过邻域内构造吸引图表达,拉近同类数据点,即
argmaxtr(WTX(DI-RI)XTW),
(7)

argmaxtr(WTX(DP-RP)XTW)
(8)
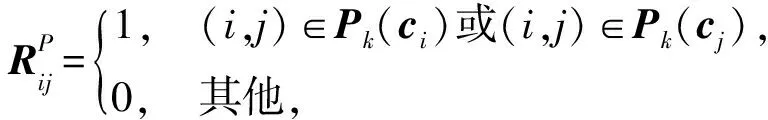
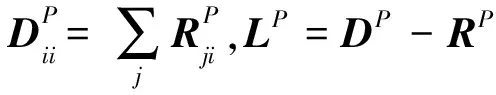
(9)
在LDA算法中如果在同类数据中存在少数相距较远的样本时,会造成鉴别准则因类内散布矩阵奇异而无法求解,使得算法性能下降.本节算法在一定程度上克服了LDA无法解决的样本多模分布问题,并且获得的投影向量比LDA多,且对数据的分布不作预先的假设,类间间隔能够更好地用于分类,缺点是需要调整的参数较多.
1.4 算法描述
同样地,利用稀疏表示构造图对大量无标签数据进行降维
(11)
对两类数据分别降维后,需要将结果整合得到,
问题等价于求解
S1W=λS2W
(13)
最大的d个特征值对应的特征向量.
2 算法步骤及流程图
2.1 算法步骤描述
输入 高光谱数据样本集X={x1,x2,…,xN}∈RD;
步骤1 将原始数据集分为两部分,Xlabel,Xunlabel,X={Xlabel,Xunlabel}={x1,x2,…,xN};
步骤2 根据式(6)得到无标签数据的稀疏重构权重矩阵;
步骤3 根据式(9)得到有标签数据的权值矩阵;
步骤5 求得高维数据的低维嵌入坐标,Z=
WTX;输出:降维后高光谱数据Z={z1,z2,…,zN}∈Rd.
2.2 算法流程图
图1是求解稀疏表示系数的算法流程图.
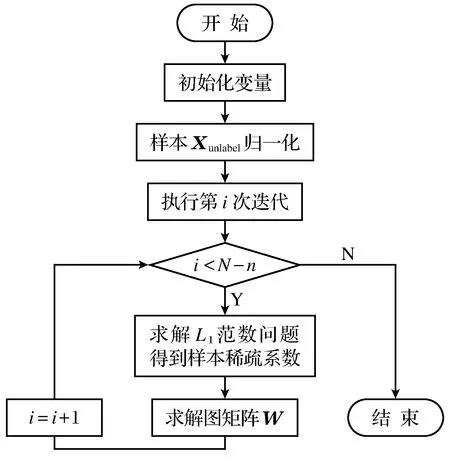
图1 求解稀疏表示系数算法流程图Fig.1 Solving sparse representation coefficients algorithm flowchart
3 实验结果与分析
3.1 实验平台和高光谱图像数据
实验所用计算机为64-bits,主频3.5 GHz Intel i7 4770K CPU,内存16 G,三级缓存8 MB.本文实验采用的AVIRIS高光谱遥感图像,Indian Pine数据集取自1992年6月拍摄的美国印第安纳州西北部印第安遥感试验区的一部分,图像大小为145×145像素,共包含220个波段,像素深度16 bits,波长范围从400到2 500 nm,包含16类确定类别的地物.本文实验从中选取类间相关度较小的8类地物,真实的地物分类图和每一类的样本个数如图2和表1所示.实验数据样本X包括有标签样本Xlabel和无标签样本Xunlabel.从标签样本中随机选出7%作为有标签样本,剩下的93%作为无标签样本.再从有标签样本中随机选出80%用来训练SVM分类器.图2为高光谱数据的灰度图及类别标记图,表1为所选数据类别.

图2 高光谱数据的灰度图及类别标记图Fig.2 Grayscale map and labeled graph of hyperspectral data(a)—高光谱数据的灰度图;(b)—类别标记图.

表1 所选数据类别Table 1 The selected data categories
3.2 降维与分类结果分析
本实验SVM分类器使用RBF kernels(径向基核函数).每个实验做10次,取平均值.随机从各类地物样本中选择20%作为训练样本.利用(overall classification accuracy,OCA)总体分类精度和KAPPA系数来评估特征提取的结果.将本文提出的算法和已有的算法进行比较.图3给出了高光谱数据的总体分类精度与低维嵌入空间的维数之间的关系.
由图3中可以看出:
随着低维嵌入空间维数的增加,各算法的总体分类精度增加并逐渐收敛.
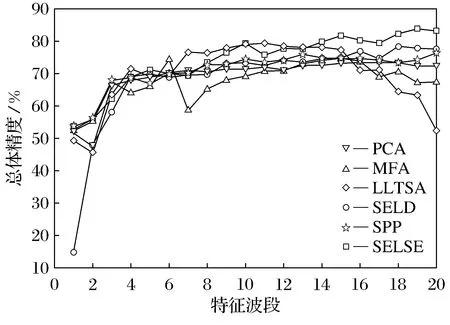
图3 不同特征提取算法对应的分类总体精度Fig.3 The overall classification accuracy of different feature extraction algorithms
与无监督算法SPP比较,充分利用了高光谱数据少量先验类别信息的SELD算法,获得了更高的总体分类精度.相比其他基于流形学习的降维算法,由于不用考虑参数的影响,曲线平滑上升.而对参数敏感的流形算法在一些特定的维数总体分类精度会不稳定.
本文提出的算法并不是在所有波段都表现良好,例如在维数7到11维,总体分类精度小于LLTSA算法.在维数大于14时,总体分类精度是所有算法中最高的,原因是考虑到数据集局部的几何关系,效果好于全局算法.
表2给出了最高总体分类精度对应的各类别分类精度,图4给出了不同特征提取算法对应的最高总体分类精度的分类图.由表2和图4可以看出,各算法对干草和小麦的分类精度明显优于其他类别;本文提出的算法在3个类别的分类精度达到较好效果.
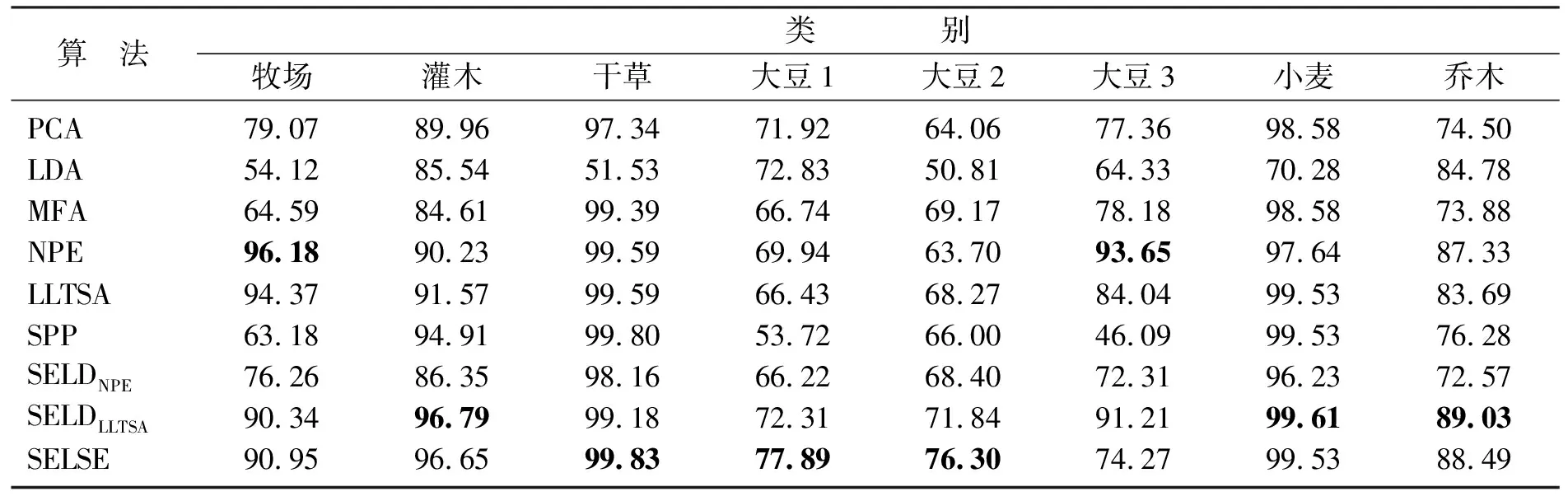
表2 最高总体分类精度对应的各类别分类精度(每类别最高用黑体表示)Table 2 Highest overall classification accuracy of classification accuracy corresponding to each category (the highest of each category represented in bold)
3.3 计算复杂度分析
本文算法的计算复杂度主要包括稀疏系数求解和广义特征值求解[12],与样本个数N和维数D有关,计算复杂度为4D2/3+DN+o(N)+o(D3),而SELD算法的计算复杂度主要包括寻找近邻图,计算复杂度为o(DN2),当N≫D时,本文算法可以较节省时间.表3给出了不同特征提取算法降维和分类的平均运算时间.
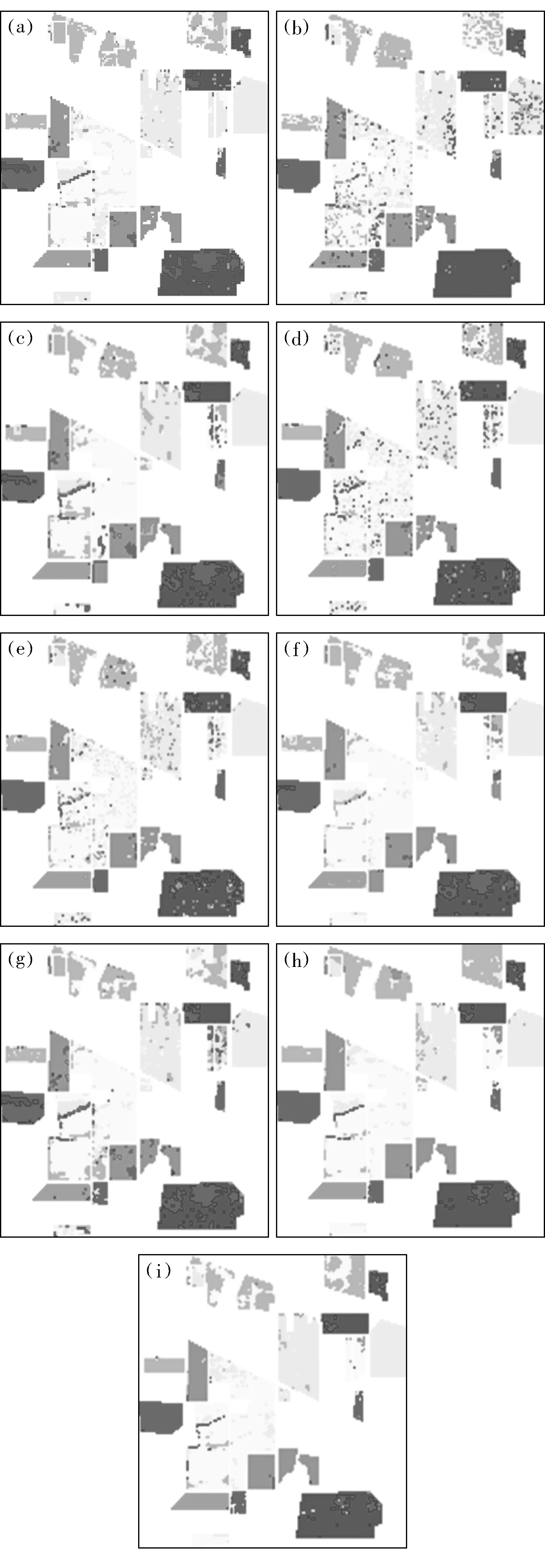
图4 不同特征提取算法对应的最高总体分类精度的分类图Fig.4 The classification map of different feature extraction algorithms corresponding highest overall classification accuracy(a)—PCA;(b)—LDA;(c)—MFA;(d)—NPE;(e)—LLTSA;(f)—SPP;(g)—SELDNPE;(h)—SELDLLTSA;(i)—SELSE.
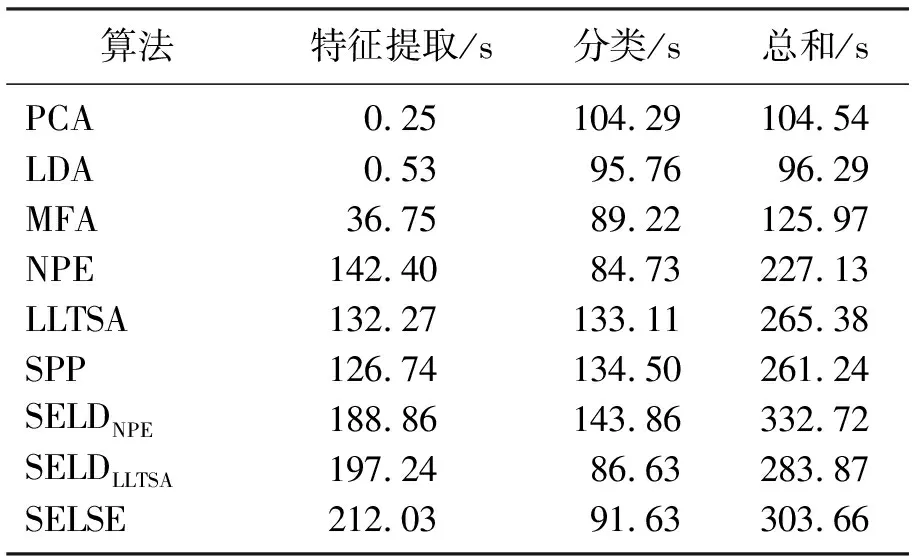
表3 不同特征提取算法降维和分类的平均运算时间Table 3 The average operation time of different feature extraction algorithm for dimensionality reduction and classification
4 结 论
高光谱图像数据具有维数高,信息量大以及信息相关性强等特点,若不进行处理直接分类,不仅会影响整体分类精度,而且增加计算复杂度.本文提出了一种半监督局部稀疏嵌入降维算法,利用少量的有标签样本最大化类间鉴别信息,并且通过求解范数优化问题获得稀疏系数向量构图,无需考虑近邻参数选择的问题,在样本点数远远大于数据维数的情况下,计算复杂度会有所减少.在Indian Pine高光谱数据集上的实验结果表明,本文提出的算法能够有效提升分类性能,并且不会以牺牲计算复杂度作为代价.
参考文献:
[1] He X F,Cai D,Yan S C,et al.Neighborhood Preserving Embedding[C].Tenth IEEE International Conference on Computer Vision,Volume 2,2005:1208-1213.
[2] He X F,Niyogi P.Locality Preserving Projections[C].Proceedings of Neural Information Processing Systems.Cambridge,Mass: MIT Press,2004:153-160.
[3] Zhang T,Yang J,Zhao D,et al.Linear Local Tangent Space Alignment and Application to Face Recognition[J].Neurocomput,2007,70(7/8/9):1547-1553.
[4] Cai D,He X F,Han J W.Semi-Supervised Discriminant Analysis[C].IEEE 11th International Conference on Computer Vision,2007:1-7.
[5] Du Q.Modified Fisher’s Linear Discriminant Analysis for Hyperspectral Imagery[J].IEEE Geoscience and Remote Sensing Letters,2007,4(4):503-507.
[6] Sugiyama M,Ide T,Nakajima S,Sese J.Semisupervised Local Fisher Discriminant Analysis for Dimensionality Reduction[J].Machine Learning,2010,78(2):35-61.
[7] Liao W Z,Pizurica A,Scheunders P.Semisupervised Local Discriminant Analysis for Feature Extraction in Hyperspectral Images[J].IEEE Transactions on Geoscience and Remote Sensing,2013,51(1):184-198.
[8] Yi Chen,Nasrabadi N M,Tran T D.Hyperspectral Image Classification Using Dictionary-Based Sparse Representation [J].IEEE Transactions on Geoscience and Remote Sensing,2011,49(10):3973-3985.
[9] Bachmann C M,Ainsworth T L,Fusina R A.Exploiting Manifold Geometry in Hyperspectral Imagery[J].IEEE Transactions on Geoscience and Remote Sensing,2005,43(3):441-454.
[10] Ma L,Crawford M M,Tian J.Local Manifold Learning-Based K-Nearest-Neighbor for Hyperspectral Image Classification[J].IEEE Transactions on Geoscience and Remote Sensing,2010,48(11):4099-4109.
[11] Camps-Valls G,Bandos T,Zhou D.Semisupervised Graph-Based Hyperspectral Image Classification[J].IEEE Transactions on Geoscience and Remote Sensing,2007,45(10):3044-3054.
[12] Belkin M,Niyogi P.Laplacia Eigenmaps and Spectral Techniques for Embedding and Clustering[C].Proceedings of Neural Information Processing Systems.Vancouver,BC,Canada,2002:585-591.
